一、下载对应的spark包
https://archive.apache.org/dist/spark/spark-3.0.0/
我这里下载的是spark-3.0.0-bin-hadoop3.2.tgz
二、解压
tar -zvxf spark-3.0.0-bin-hadoop3.2.tgz
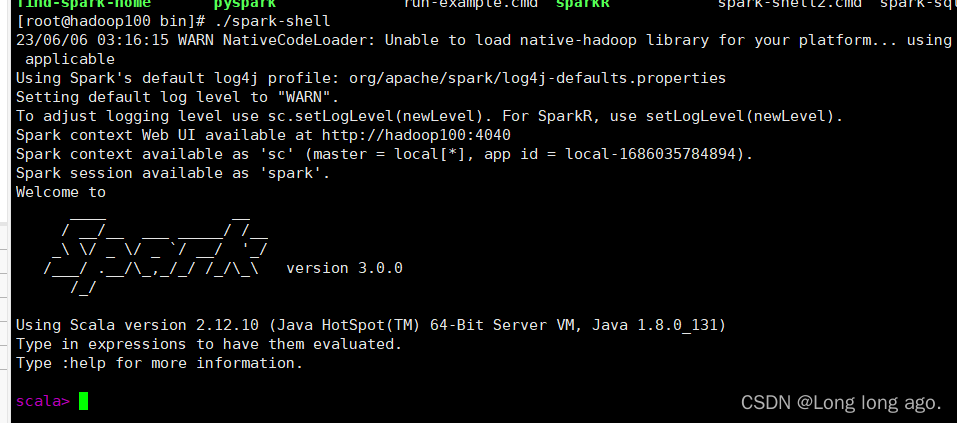
三、启动
再解压路径的bin目录执行下
./spark-shell
四、测试
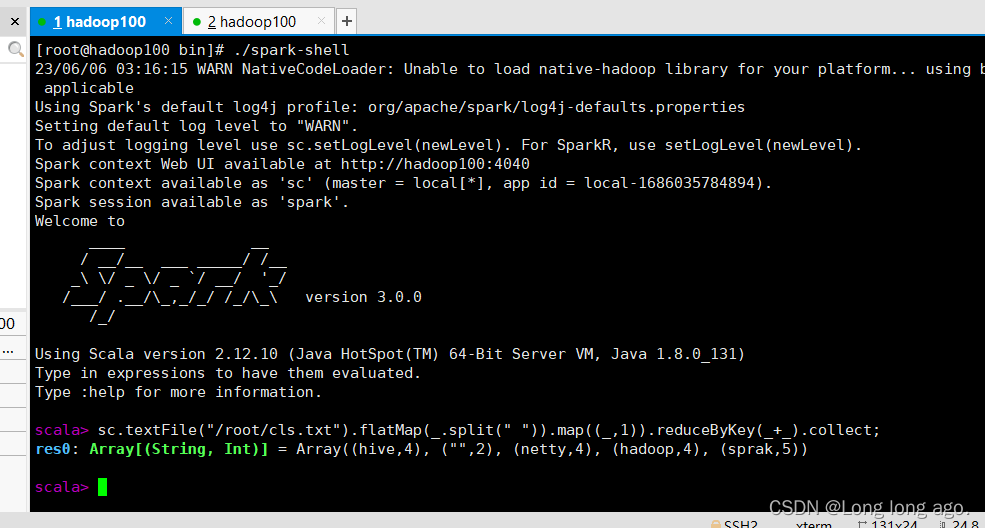
WordCount代码例子
sc.textFile("/root/cls.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect;
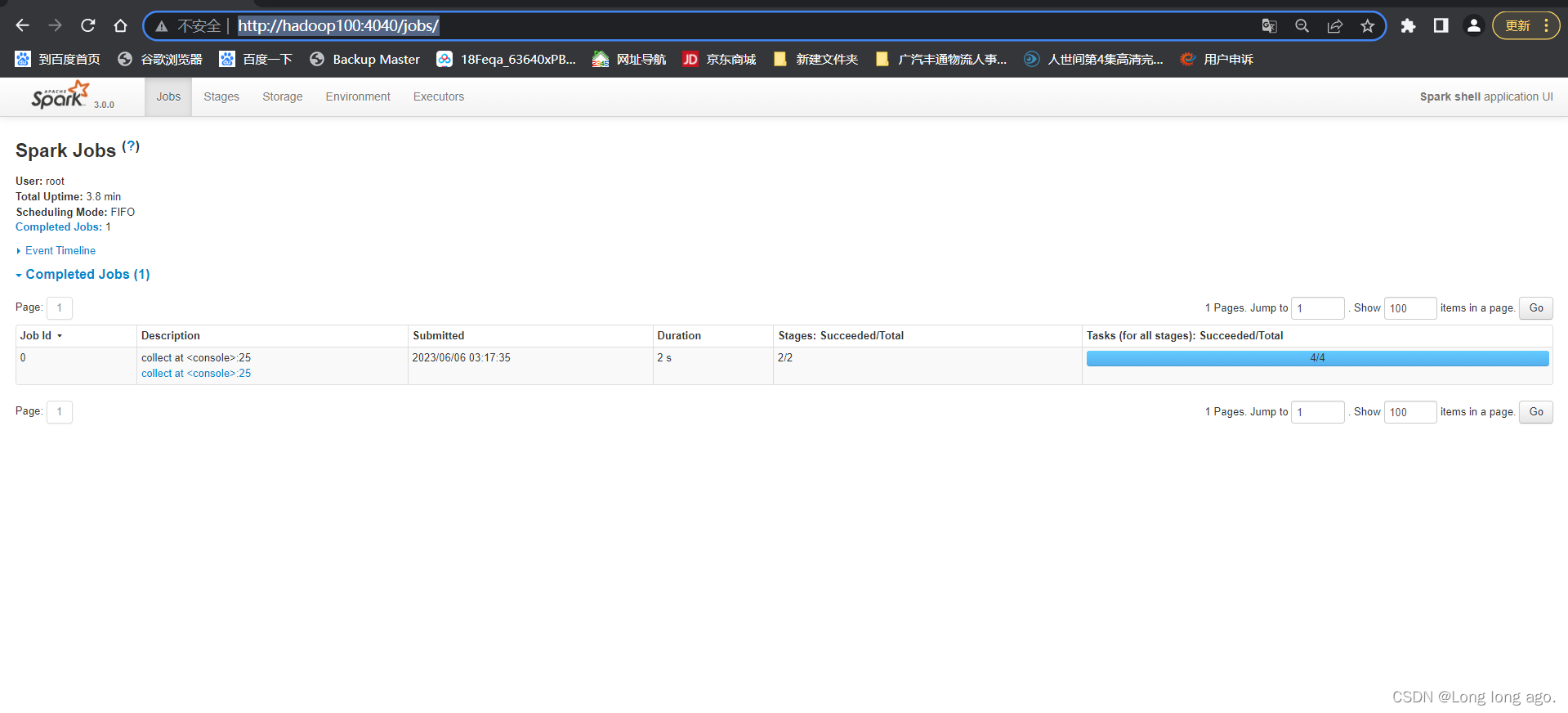
访问可看到下面例子就成功了
http://hadoop100:4040/jobs/
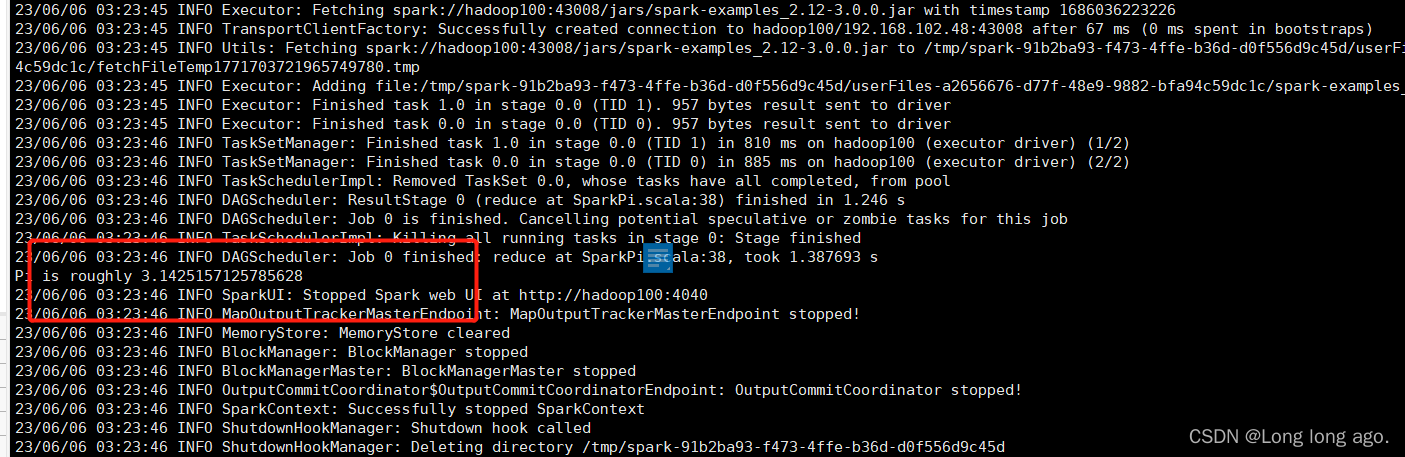
五、提交应用
在解压bin路径下执行
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-exa.12-3.0.0.jar
参数解析
./spark-submit --class 表示要执行程序的主类 --master local[cpu核数] jar包路径