文章目录
- 前言
- 一、Hive的压缩方式
- (一) 概念
- (二) 简介
- (三) 数据分层的压缩方式选择
- (四)开启Map输出阶段压缩
- (五)开启Reduce输出阶段压缩
- 二、 Hive的数据存储格式
- (一)行存储的特点
- (二)列存储的特点
- (三)列式存储的特性
- 总结
前言
#博学谷IT学习技术支持#
由于大数据需要存储的数据较多,如果直接存储原始数据,将会占用较多的硬盘空间,于是就诞生了存储方式和压缩方式,以一定的算法降低数据占用的空间,并且保证数据不丢失,从而提高空间的利用率。
一、Hive的压缩方式
(一) 概念
(1)Hive底层为MapReduce,所以Hive的压缩实际就是MapReduce的压缩
(2)MapRedece的压缩分为Map端结果文件压缩和Reduce端结果文件压缩
(二) 简介
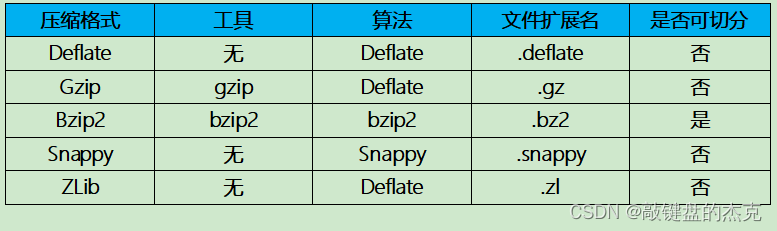
压缩方式常用的有Deflate,Snappy,ZLib,Gzip和Bzip2,不同的压缩方式效率不同;
(1) 从压缩比来说,Bzip2 > ZLib > Gzip > deflate > Snappy,除了Snappy之外的压缩方式可以保证最小的压缩,但是在运算过程中时间消耗较大;
(2)从压缩性能上来说, Snappy > Deflate > Gzip > Bzip2,其中,Snappy压缩和解压缩速度快,压缩比低。
所以一般在生产环境中,经常会采用snappy压缩,以保证运算效率
(三) 数据分层的压缩方式选择
根据每个数据分层的作用,选择不同的压缩方式,从而提高执行的效率;
(1)ODS层适合Zlib,Gz和Bzip2的压缩方式,该层需要存储较多的数据,所以选择压缩比较高的压缩方式,可以节省空间,从而存储更多的数据
(2)DW层和DA层适合Snappy压缩方式,这两层数据的查询较为频繁,数据存储量不大,所以适合压缩和解压缩效率较高的Snappy压缩方式

(四)开启Map输出阶段压缩
开启Map输出阶段压缩可以减少job中map和Reduce task间数据传输量
实操:
1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4)执行查询语句
select count(1) from score;
(五)开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
实操:
-- 1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
-- 2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
-- 3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
-- 4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
-- 5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/export/data/compress'
select * from score distribute by sid sort by sscore desc;
二、 Hive的数据存储格式
Hive支持的存储方式主要有列式存储和行式存储,其中行式存储有TEXTFILE和SEQUENCEFILE,列式存储有ORC和PARQUET,不同需求下使用不同的存储方式可以提高数据查询效率。
(一)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
(二)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法
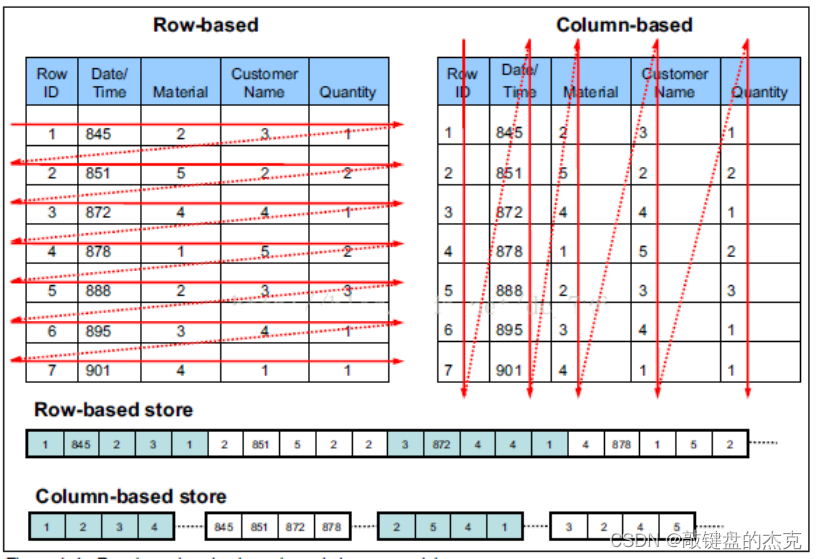
(三)列式存储的特性
相比于行式存储,列式存储在分析场景下有着许多优良的特性:
1)分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO开销,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存储往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的数据空间,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
总结
压缩方式结合数据存储格式可以更好的提高数据查询效率,以及降低数据的空间占用率,相同的磁盘空间存储更多的数据,从而提高磁盘空间的利用率。








![[附源码]Python计算机毕业设计SSM金牛社区疫情防控系统(程序+LW)](https://img-blog.csdnimg.cn/417db15b077449b8b45f4073bfec11b4.png)
![[附源码]JAVA毕业设计老年人健康饮食管理系统(系统+LW)](https://img-blog.csdnimg.cn/47bec3a52da948c0b5e07b9a18165cf7.png)