分类目录:《深入理解深度学习》总目录
Dropout供了正则化一大类模型的方法,计算方便且功能强大。在第一种近似下,Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。Bagging涉及训练多个模型,并在每个测试样本上评估多个模型。当每个模型都是一个很大的神经网络时,这似乎是不切实际的,因为训练和评估这样的网络需要花费很多运行时间和内存。通常我们只能集成五至十个神经网络,如Szegedy集成了六个神经网络赢得ILSVRC,超过这个数量就会迅速变得难以处理。Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。
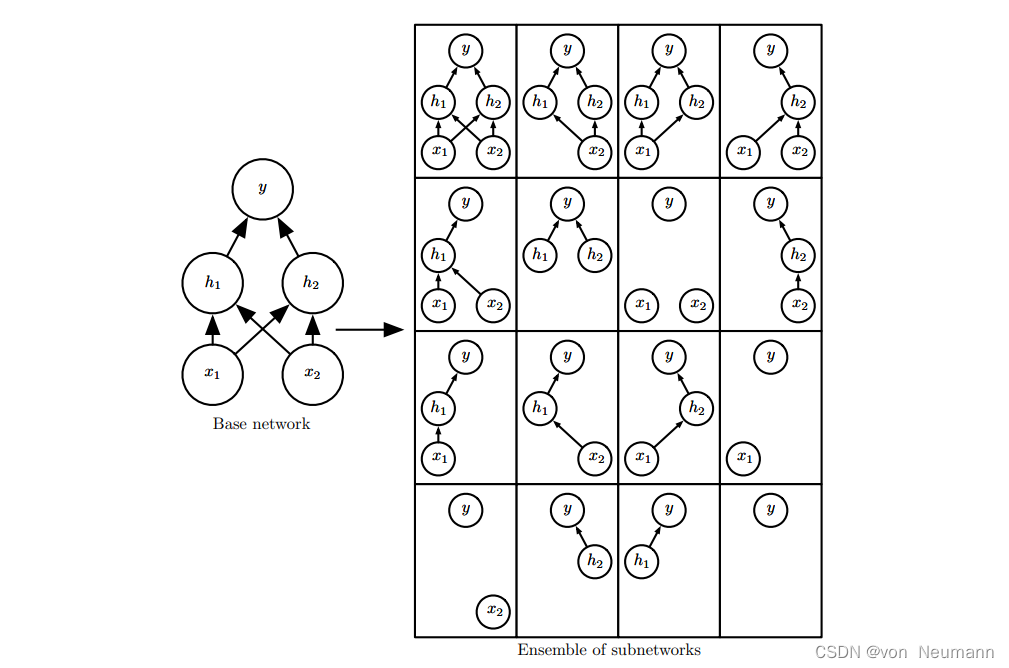
具体而言,Dropout训练的集成包括所有从基础网络除去非输出单元后形成的子网络,如下图所示。最先进的神经网络基于一系列仿射变换和非线性变换,我们只需将一些单元的输出乘零就能有效地删除一个单元。这个过程需要对模型(如径向基函数网络,单元的状态和参考值之间存在一定区别)进行一些修改。为了简单起见,我们在这里提出乘零的简单Dropout算法,但是它被简单修改后,可以与从网络中移除单元的其他操作结合使用。回想一下Bagging学习,我们定义
k
k
k个不同的模型,从训练集有放回采样构造
k
k
k个不同的数据集,然后在训练集 i 上训练模型 i。Dropout的目标是在指数级数量的神经网络上近似这个过程。具体来说,在训练中使用Dropout时,我们会使用基于小批量产生较小步长的学习算法,如随机梯度下降等。我们每次在小批量中加载一个样本,然后随机抽样应用于网络中所有输入和隐藏单元的不同二值掩码。对于每个单元,掩码是独立采样的。掩码值为1的采样概率(导致包含一个单元)是训练开始前一个固定的超参数。它不是模型当前参数值或输入样本的函数。通常在每一个小批量训练的神经网络中,一个输入单元被包括的概率为0.8,一个隐藏单元被包括的概率为0.5。然后,我们运行和之前一样的前向传播、反向传播以及学习更新。
更正式地说,假设一个掩码向量
μ
\mu
μ指定被包括的单元,
J
(
θ
,
μ
)
J(\theta, \mu)
J(θ,μ)是由参数
θ
,
\theta,
θ,和掩码
μ
\mu
μ定义的模型代价。那么Dropout训练的目标是最小化
E
μ
J
(
θ
,
μ
)
E_\mu J(\theta, \mu)
EμJ(θ,μ)。这个期望包含多达指数级的项,但我们可以通过抽样
μ
\mu
μ获得梯度的无偏估计。Dropout训练与Bagging训练不太一样。在Bagging的情况下,所有模型都是独立的。在Dropout的情况下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集。参数共享使得在有限可用的内存下表示指数级数量的模型变得可能。
在Bagging的情况下,每一个模型在其相应训练集上训练到收敛。在Dropout的情况下,通常大部分模型都没有显式地被训练,因为通常父神经网络会很大,以致于到宇宙毁灭都不可能采样完所有的子网络。取而代之的是,在单个步骤中我们训练一小部分的子网络,参数共享会使得剩余的子网络也能有好的参数设定。这些是仅有的区别。除了这些,Dropout与Bagging算法一样。例如,每个子网络中遇到的训练集确实是有放回采样的原始训练集的一个子集。Bagging集成必须根据所有成员的累积投票做一个预测。在这种背景下,我们将这个过程称为推断(Inference)。目前为止,我们在介绍Bagging和Dropout时没有要求模型具有明确的概率。现在,我们假定该模型的作用是输出一个概率分布。在Bagging的情况下,每个模型
i
i
i产生一个概率分布
p
(
i
)
(
y
∣
x
)
p^{(i)}(y|x)
p(i)(y∣x)。集成的预测由这些分布的算术平均值给出:
1
k
∑
i
=
1
k
p
(
i
)
(
y
∣
x
)
\frac{1}{k}\sum_{i=1}^k p^{(i)}(y|x)
k1i=1∑kp(i)(y∣x)
在Dropout的情况下,通过掩码
μ
\mu
μ定义每个子模型的概率分布
p
(
y
∣
x
,
μ
)
p(y | x, \mu)
p(y∣x,μ)。所有掩码的算术平均值由下式给出:
∑
p
(
μ
)
p
(
y
∣
x
,
μ
)
\sum p(\mu)p(y | x, \mu)
∑p(μ)p(y∣x,μ)
其中 p ( μ ) p(\mu) p(μ)是训练时采样 μ \mu μ的概率分布。
因为这个求和包含多达指数级的项,除非该模型的结构允许某种形式的简化,否则是不可能计算的。目前为止,无法得知深度神经网络是否允许某种可行的简化。相反,我们可以通过采样近似推断,即平均许多掩码的输出。即使是10 − 20个掩码就足以获得不错的表现。然而,一个更好的方法能不错地近似整个集成的预测,且只需一个前向传播的代价。要做到这一点,我们改用集成成员预测分布的几何平均而不是算术平均。Warde-Farley提出的论点和经验证据表明,在这个情况下几何平均与算术平均表现得差不多。多个概率分布的几何平均不能保证是一个概率分布。为了保证结果是一个概率分布,我们要求没有子模型给某一事件分配概率0,并重新标准化所得分布。通过几何平均直接定义的非标准化概率分布由下式给出:
p
~
ensemble
(
y
∣
x
)
=
∏
μ
p
(
y
∣
x
,
μ
)
2
d
\tilde{p}_{\text{ensemble}}(y|x) = \sqrt[2^d]{\prod_\mu p(y|x, \mu)}
p~ensemble(y∣x)=2dμ∏p(y∣x,μ)
其中
d
d
d是可被丢弃的单元数。这里为简化介绍,我们使用均匀分布的
μ
\mu
μ,但非均匀分布也是可以的。为了作出预测,我们必须重新标准化集成:
p
ensemble
(
y
∣
x
)
=
p
~
ensemble
(
y
∣
x
)
∑
y
′
p
~
ensemble
(
y
′
∣
x
)
p_{\text{ensemble}}(y|x) = \frac{\tilde{p}_{\text{ensemble}}(y|x)}{\sum_{y'}\tilde{p}_{\text{ensemble}}(y'|x)}
pensemble(y∣x)=∑y′p~ensemble(y′∣x)p~ensemble(y∣x)
涉及Dropout的一个重要观点是我们可以通过评估模型中 p ( y ∣ x ) p(y | x) p(y∣x)来近似 p ensemble p_{\text{ensemble}} pensemble:该模型具有所有单元,但我们将单元 i i i的输出的权重乘以单元 i i i的被包含概率。这个修改的动机是得到从该单元输出的正确期望值。我们把这种方法称为权重比例推断规则(Weight Scaling Inference Rule)。目前还没有在深度非线性网络上对这种近似推断规则的准确性作任何理论分析,但经验上表现得很好。
因为我们通常使用
1
2
\frac{1}{2}
21的包含概率,权重比例规则一般相当于在训练结束后将权重除2,然后像平常一样使用模型。实现相同结果的另一种方法是在训练期间将单元的状态乘 2。无论哪种方式,我们的目标是确保在测试时一个单元的期望总输入与在训练时该单元的期望总输入是大致相同的(即使近半单位在训练时丢失)。对许多不具有非线性隐藏单元的模型族而言,权重比例推断规则是精确的。举个简单的例子,考虑Softmax函数回归分类,其中由向量
v
v
v表示
n
n
n个输入变量:
P
(
Y
=
y
∣
v
)
=
Softmax
(
W
T
v
+
b
)
P(Y = y|v) = \text{Softmax}(W^Tv + b)
P(Y=y∣v)=Softmax(WTv+b)
我们可以根据二值向量
d
d
d逐元素的乘法将一类子模型进行索引:
P
(
Y
=
y
∣
v
;
d
)
=
Softmax
(
W
T
(
d
⊙
v
)
+
b
)
y
P(Y = y|v; d) = \text{Softmax}(W^T(d\odot v) + b)_y
P(Y=y∣v;d)=Softmax(WT(d⊙v)+b)y
权重比例推断规则在其他设定下也是精确的,包括条件正态输出的回归网络以及那些隐藏层不包含非线性的深度网络。然而,权重比例推断规则对具有非线性的深度模型仅仅是一个近似。虽然这个近似尚未有理论上的分析,但在实践中往往效果很好。Goodfellow实验发现,在对集成预测的近似方面,权重比例推断规则比蒙特卡罗近似更好(就分类精度而言)。即使允许蒙特卡罗近似采样多达1000 子网络时也比不过权重比例推断规则。Gal and Ghahramani发现一些模型可以通过二十个样本和蒙特卡罗近似获得更好的分类精度。似乎推断近似的最佳选择是与问题相关的。Srivastava显示,Dropout比其他标准的计算开销小的正则化方法(如权重衰减、过滤器范数约束和稀疏激活的正则化)更有效。Dropout也可以与其他形式的正则化合并,得到进一步的提升。计算方便是Dropout的一个优点。训练过程中使用Dropout产生 n n n个随机二进制数与状态相乘,每个样本每次更新只需 O ( n ) O(n) O(n)的计算复杂度。根据实现,也可能需要 O ( n ) O(n) O(n)的存储空间来持续保存这些二进制数(直到反向传播阶段)。使用训练好的模型推断时,计算每个样本的代价与不使用Dropout是一样的,尽管我们必须在开始运行推断前将权重除以2。
Dropout的另一个显著优点是不怎么限制适用的模型或训练过程。几乎在所有使用分布式表示且可以用随机梯度下降训练的模型上都表现很好。包括前馈神经网络、概率模型,如受限玻尔兹曼机,以及循环神经网络。许多效果差不多的其他正则化策略对模型结构的限制更严格。
虽然Dropout在特定模型上每一步的代价是微不足道的,但在一个完整的系统上使用Dropout的代价可能非常显著。因为Dropout是一个正则化技术,它减少了模型的有效容量。为了抵消这种影响,我们必须增大模型规模。不出意外的话,使用Dropout时最佳验证集的误差会低很多,但这是以更大的模型和更多训练算法的迭代次数为代价换来的。对于非常大的数据集,正则化带来的泛化误差减少得很小。在这些情况下,使用Dropout和更大模型的计算代价可能超过正则化带来的好处。只有极少的训练样本可用时,Dropout不会很有效。在只有不到5000的样本的Alternative Splicing数据集上 ,贝叶斯神经网络比Dropout表现得更好。当有其他未分类的数据可用时,无监督特征学习也比Dropout更有优势。Wager表明,当Dropout作用于线性回归时,相当于每个输入特征具有不同权重衰减系数的 L 2 L^2 L2权重衰减。每个特征的权重衰减系数的大小是由其方差来确定的。其他线性模型也有类似的结果。而对于深度模型而言,Dropout与权重衰减是不等同的。
使用Dropout训练时的随机性不是这个方法成功的必要条件。它仅仅是近似所有子模型总和的一个方法。Wang and Manning导出了近似这种边缘分布的解析解。他们的近似被称为快速 Dropout,减小梯度计算中的随机性而获得更快的收敛速度。这种方法也可以在测试时应用,能够比权重比例推断规则更合理地(但计算也更昂贵)近似所有子网络的平均。快速 Dropout在小神经网络上的性能几乎与标准的Dropout相当,但在大问题上尚未产生显著改善或尚未应用。随机性对实现Dropout的正则化效果不是必要的,同时也不是充分的。为了证明这一点,Warde-Farley使用一种被称为Dropout Boosting的方法设计了一个对照实验,具有与传统Dropout方法完全相同的噪声掩码,但缺乏正则化效果。Dropout Boosting训练整个集成以最大化训练集上的似然。从传统Dropout类似于Bagging的角度来看,这种方式类似于Boosting。如预期一样,和单一模型训练整个网络相比,Dropout Boosting几乎没有正则化效果。这表明,使用Bagging解释Dropout比使用稳健性噪声解释Dropout更好。只有当随机抽样的集成成员相互独立地训练好后,才能达到Bagging集成的正则化效果。
Dropout启发其他以随机方法训练指数量级的共享权重的集成。DropConnect是Dropout的一个特殊情况,其中一个标量权重和单个隐藏单元状态之间的每个乘积被认为是可以丢弃的一个单元。随机池化是构造卷积神经网络集成的一种随机化池化的形式,其中每个卷积网络参与每个特征图的不同空间位置。目前为止,Dropout仍然是最广泛使用的隐式集成方法。
一个关于Dropout的重要见解是,通过随机行为训练网络并平均多个随机决定进行预测,实现了一种参数共享的Bagging形式。早些时候,我们将Dropout描述为通过包括或排除单元形成模型集成的Bagging。然而,这种参数共享策略不一定要基于包括和排除。原则上,任何一种随机的修改都是可接受的。在实践中,我们必须选择让神经网络能够学习对抗的修改类型。在理想情况下,我们也应该使用可以快速近似推断的模型族。我们可以认为由向量 μ \mu μ参数化的任何形式的修改,是对 μ \mu μ所有可能的值训练 p ( y ∣ x , μ ) p(y | x, \mu) p(y∣x,μ)的集成。注意,这里不要求 μ \mu μ具有有限数量的值。例如, μ \mu μ可以是实值。Srivastava表明,权重乘以 μ ∼ N ( 1 , l ) \mu\sim N(1, l) μ∼N(1,l)比基于二值掩码Dropout表现得更好。由于 E [ μ ] = 1 E[\mu] = 1 E[μ]=1,标准网络自动实现集成的近似推断,而不需要权重比例推断规则。
目前为止,我们将Dropout介绍为一种纯粹高效近似Bagging的方法。然而,还有比这更进一步的Dropout观点。Dropout不仅仅是训练一个Bagging的集成模型,并且是共享隐藏单元的集成模型。这意味着无论其他隐藏单元是否在模型中,每个隐藏单元必须都能够表现良好。隐藏单元必须准备好进行模型之间的交换和互换。Hinton由生物学的想法受到启发:有性繁殖涉及到两个不同生物体之间交换基因,进化产生的压力使得基因不仅是良好的而且要准备好不同有机体之间的交换。这样的基因和这些特点对环境的变化是非常稳健的,因为它们一定会正确适应任何一个有机体或模型不寻常的特性。因此Dropout正则化每个隐藏单元不仅是一个很好的特征,更要在许多情况下是良好的特征。Warde-Farley将Dropout与大集成的训练相比并得出结论:相比独立模型集成获得泛化误差改进,Dropout会带来额外的改进。
Dropout强大的大部分原因来自施加到隐藏单元的掩码噪声,了解这一事实是重要的。这可以看作是对输入内容的信息高度智能化、自适应破坏的一种形式,而不是对输入原始值的破坏。例如,如果模型学得通过鼻检测脸的隐藏单元 h i h_i hi,那么丢失 h i h_i hi对应于擦除图像中有鼻子的信息。模型必须学习另一种 h i h_i hi,要么是鼻子存在的冗余编码,要么是像嘴这样的脸部的另一特征。传统的噪声注入技术,在输入端加非结构化的噪声不能够随机地从脸部图像中抹去关于鼻子的信息,除非噪声的幅度大到几乎能抹去图像中所有的信息。破坏提取的特征而不是原始值,让破坏过程充分利用该模型迄今获得的关于输入分布的所有知识。
Dropout的另一个重要方面是噪声是乘性的。如果是固定规模的加性噪声,那么加了噪声 ϵ \epsilon ϵ的整流线性隐藏单元可以简单地学会使 h i h_i hi变得很大(使增加的噪声 ϵ \epsilon ϵ变得不显著)。乘性噪声不允许这样病态地解决噪声鲁棒性问题。另一种深度学习算法——批标准化,在训练时向隐藏单元引入加性和乘性噪声重新参数化模型。批标准化的主要目的是改善优化,但噪声具有正则化的效果,有时没必要再使用Dropout。批标准化将会在后面的文章中被更详细地讨论。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.