DaViT: Dual Attention Vision Transformers, ECCV2022
解读:【ECCV2022】DaViT: Dual Attention Vision Transformers - 高峰OUC - 博客园 (cnblogs.com)
DaViT:双注意力Vision Transformer - 知乎 (zhihu.com)
DaViT: Dual Attention Vision Transformers - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2204.03645
代码:https://github.com/dingmyu/davit
动机
以往的工作一般是,在分辨率、全局上下文和计算复杂度之间权衡:像素级和patch级的self-attention要么是有二次计算成本,要么损失全局上下文信息。除了像素级和patch级的self-attention的变化之外,是否可以设计一个图像级的self-attention机制来捕获全局信息?
作者提出了Dual Attention Vision Transformers (DaViT),能够在保持计算效率的同时捕获全局上下文。提出的方法具有层次结构和细粒度局部注意的优点,同时采用 group channel attention,有效地建模全局环境。
创新点:
- 提出 Dual Attention Vision Transformers(DaViT),它交替地应用spatial window attention和channel group attention来捕获长短依赖关系。
- 提出 channel group attention,将特征通道划分为几个组,并在每个组内进行图像级别的交互。通过group attention,作者将空间和通道维度的复杂性降低到线性。
方法
dual attention
双attention机制是从两个正交的角度来进行self-attention:
一是对spatial tokens进行self-attention,此时空间维度(HW)定义了tokens的数量,而channel维度(C)定义了tokens的特征大小,这其实也是ViT最常采用的方式;
二是对channel tokens进行self-attention,这和前面的处理完全相反,此时channel维度(C)定义了tokens的数量,而空间维度(HW)定义了tokens的特征大小。
可以看出两种self-attention完全是相反的思路。为了减少计算量,两种self-attention均采用分组的attention:对于spatial token而言,就是在空间维度上划分成不同的windows,这就是Swin中所提出的window attention,论文称之为spatial window attention;而对于channel tokens,同样地可以在channel维度上划分成不同的groups,论文称之为channel group attention。
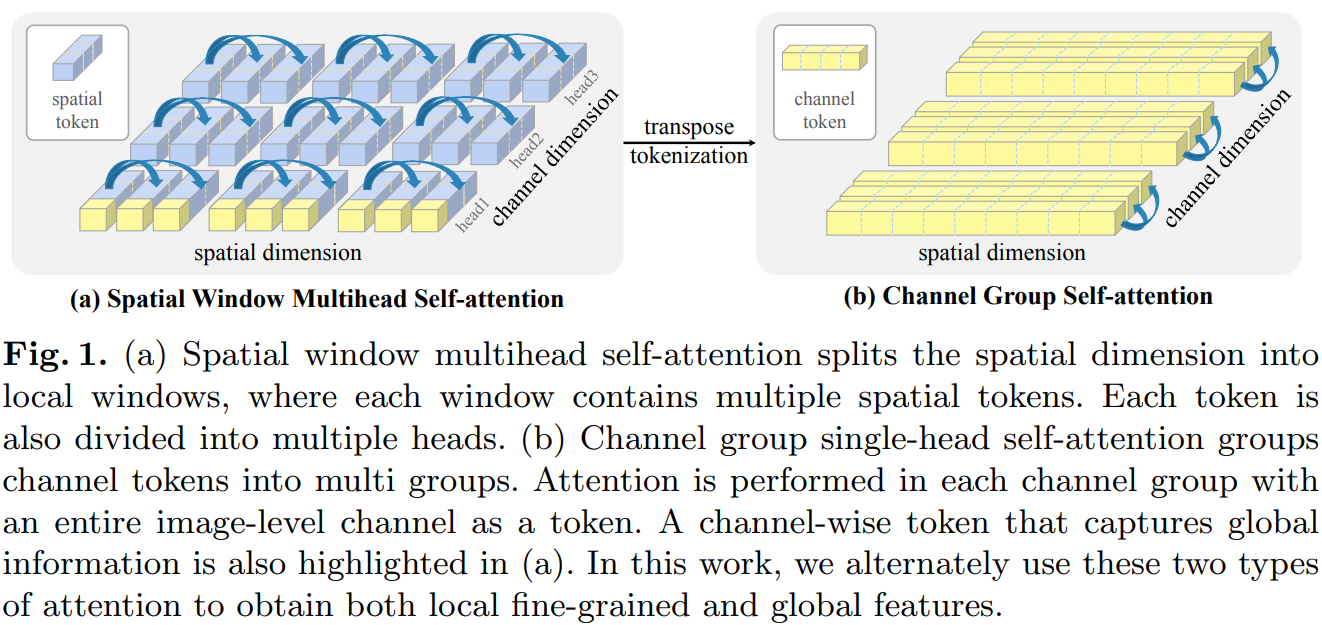
(a)空间窗口多头自注意将空间维度分割为局部窗口,其中每个窗口包含多个空间token。每个token也被分成多个头。(b)通道组单自注意组将token分成多组。在每个通道组中使用整个图像级通道作为token进行Attention。在(a)中也突出显示了捕获全局信息的通道级token。交替地使用这两种类型的注意力机制来获得局部的细粒度,以及全局特征。
两种attention能够实现互补:spatial window attention能够提取windows内的局部特征,而channel group attention能学习到全局特征,这是因为每个channel token在图像空间上都是全局的。
dual attention block
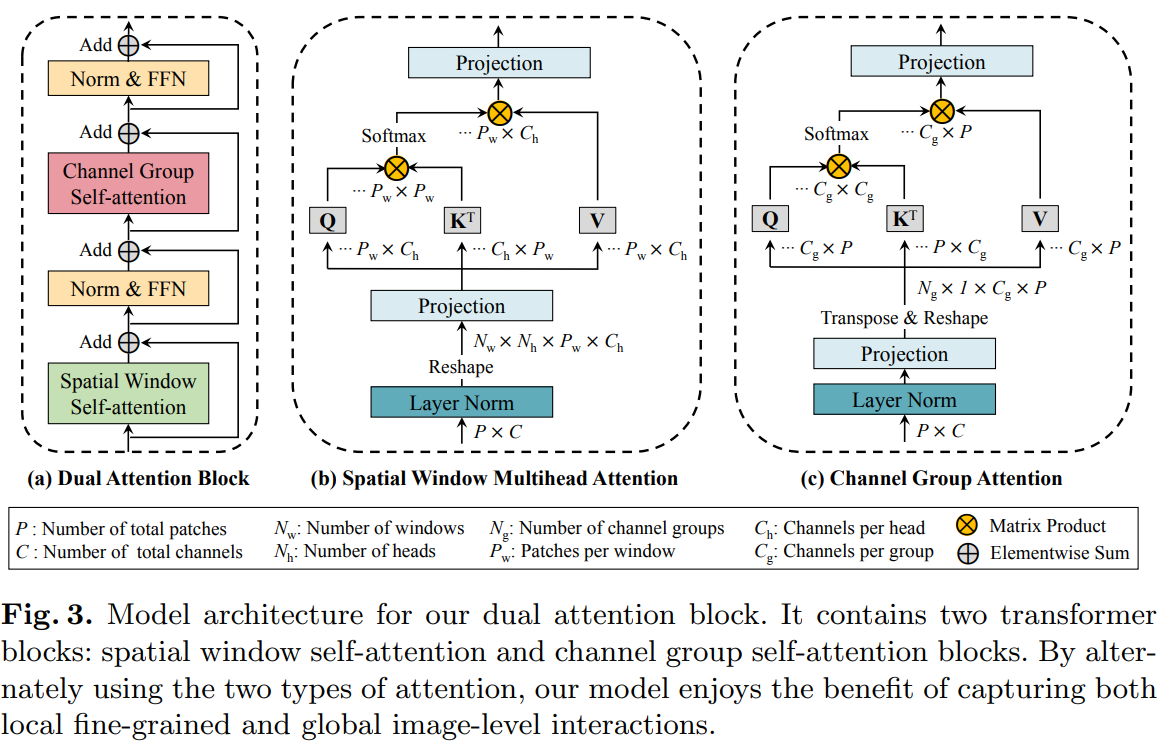
dual attention block的模型架构,它包含两个transformer block:空间window self-attention block和通道group self-attention block。通过交替使用这两种类型的attention机制,作者的模型能实现局部细粒度和全局图像级交互。图3(a)展示了作者的dual attention block的体系结构,包括一个空间window attention block和一个通道group attention block。
Spatial Window Attention
将patchs按照空间结构划分为Nw个window,每个window 里的patchs(Pw)单独计算self-attention:(P=Nw*Pw)
![]()
Channel Group Attention
将channels分为Ng个group,每个group的channel数量为Cg,有C=Ng*Cg,计算如下:
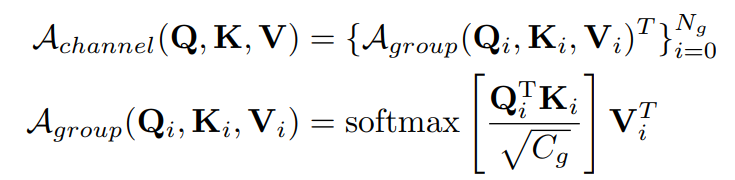
关键代码
class SpatialBlock(nn.Module):
r""" Windows Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
ffn=True, cpe_act=False):
super().__init__()
self.dim = dim
self.ffn = ffn
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
# conv位置编码
self.cpe = nn.ModuleList([ConvPosEnc(dim=dim, k=3, act=cpe_act),
ConvPosEnc(dim=dim, k=3, act=cpe_act)])
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim,
window_size=to_2tuple(self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.ffn:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x, size):
H, W = size
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = self.cpe[0](x, size) # depth-wise conv
x = self.norm1(shortcut)
x = x.view(B, H, W, C)
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
x_windows = window_partition(x, self.window_size)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows)
# merge windows
attn_windows = attn_windows.view(-1,
self.window_size,
self.window_size,
C)
x = window_reverse(attn_windows, self.window_size, Hp, Wp)
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = self.cpe[1](x, size) # 第2个depth-wise conv
if self.ffn:
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, size
class ChannelAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False):
super().__init__()
self.num_heads = num_heads # 这里的num_heads实际上是num_groups
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
def forward(self, x):
B, N, C = x.shape
# 得到query,key和value,是在channel维度上进行线性投射
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
k = k * self.scale
attention = k.transpose(-1, -2) @ v # 对维度进行反转
attention = attention.softmax(dim=-1)
x = (attention @ q.transpose(-1, -2)).transpose(-1, -2)
x = x.transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
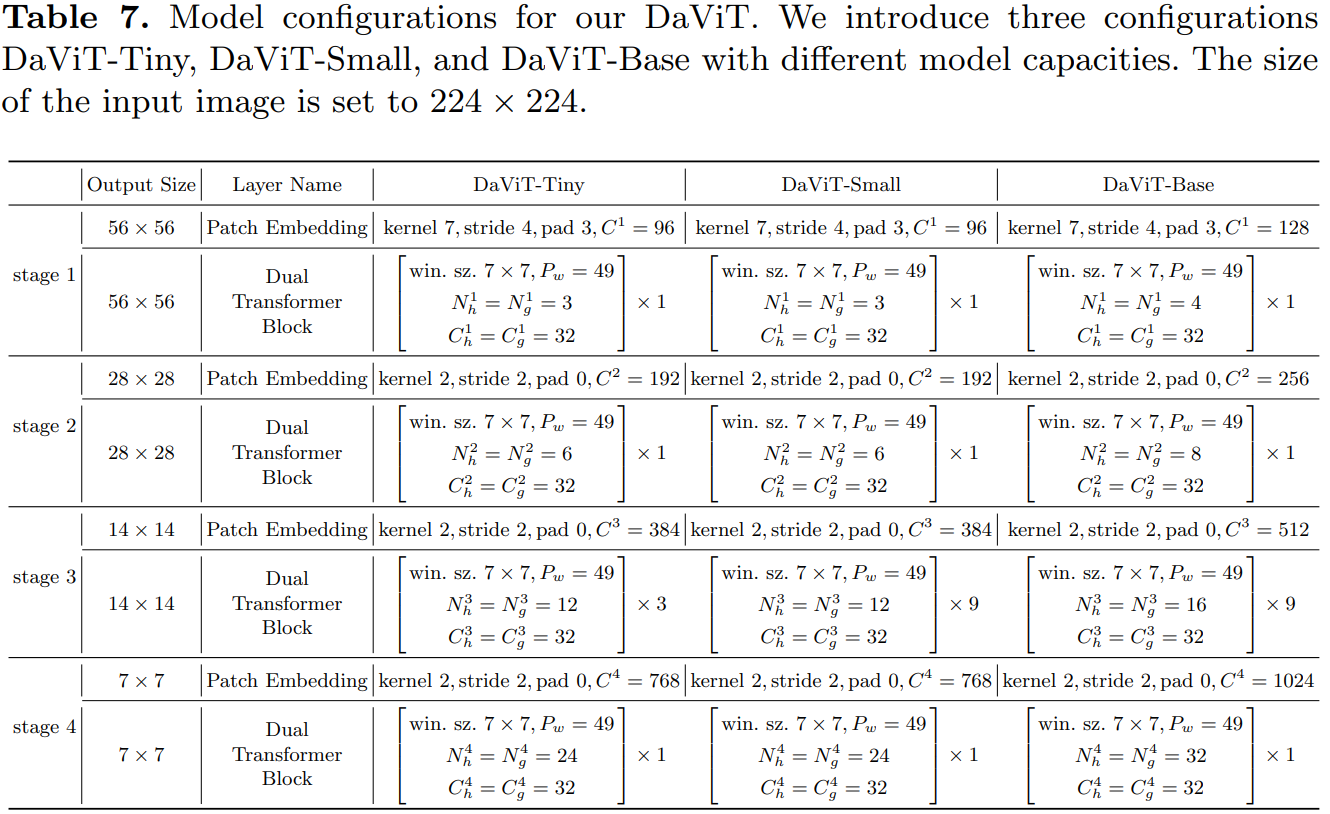
return xDaViT采用金字塔结构,共包含4个stages,每个stage的开始时都插入一个 patch embedding 层。作者在每个stage叠加dual attention block,这个block就是将两种attention(还包含FFN)交替地堆叠在一起,其分辨率和特征维度保持不变。
采用stride=4的7x7 conv,然后是4个stage,各stage通过stride=2的2x2 conv来进行降采样。其中DaViT-Tiny,DaViT-Small和DaViT-Base三个模型的配置如下所示:
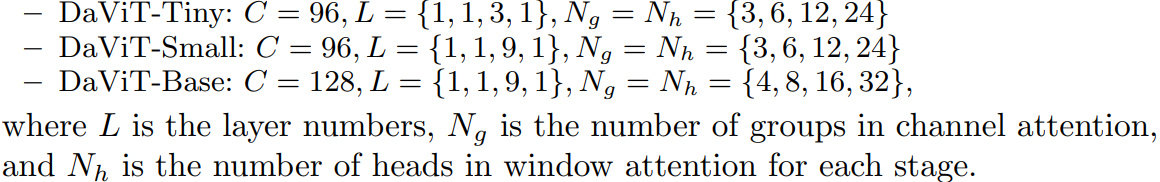
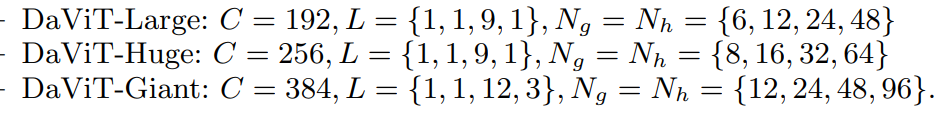
实验
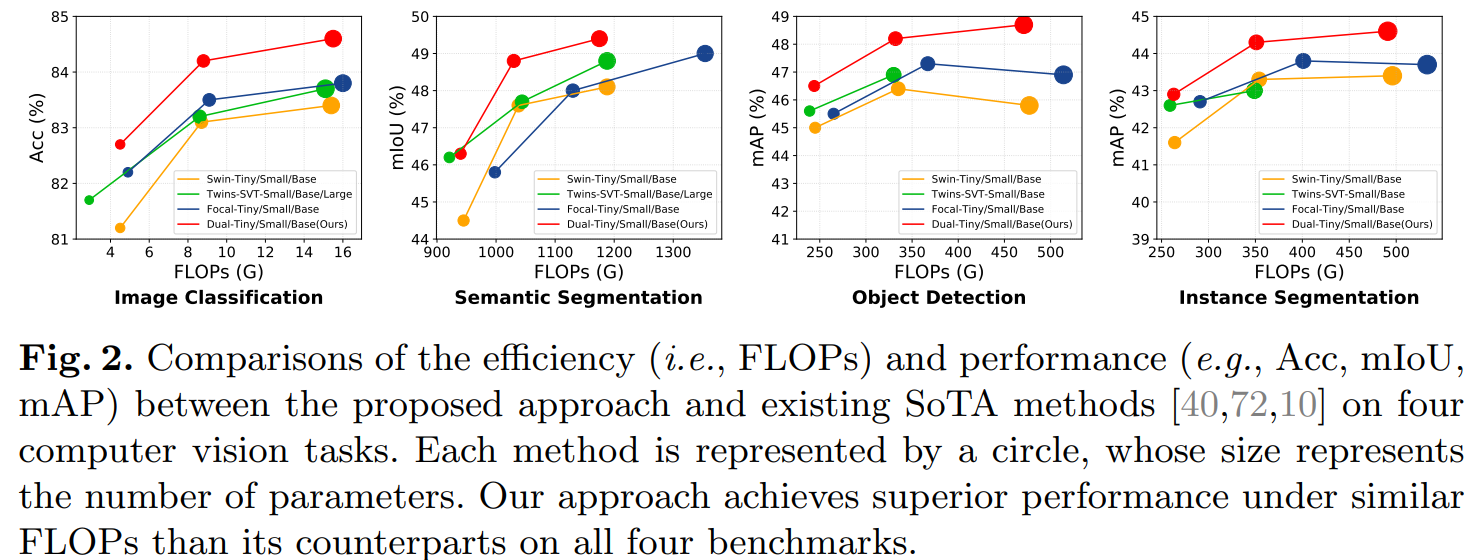
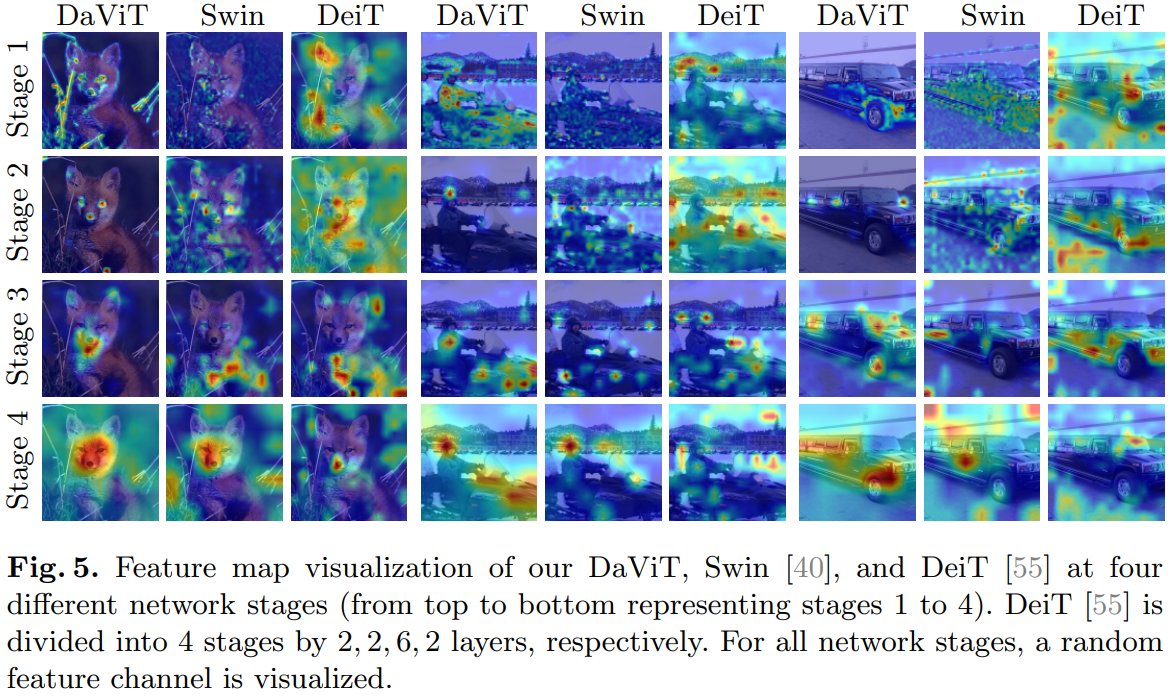


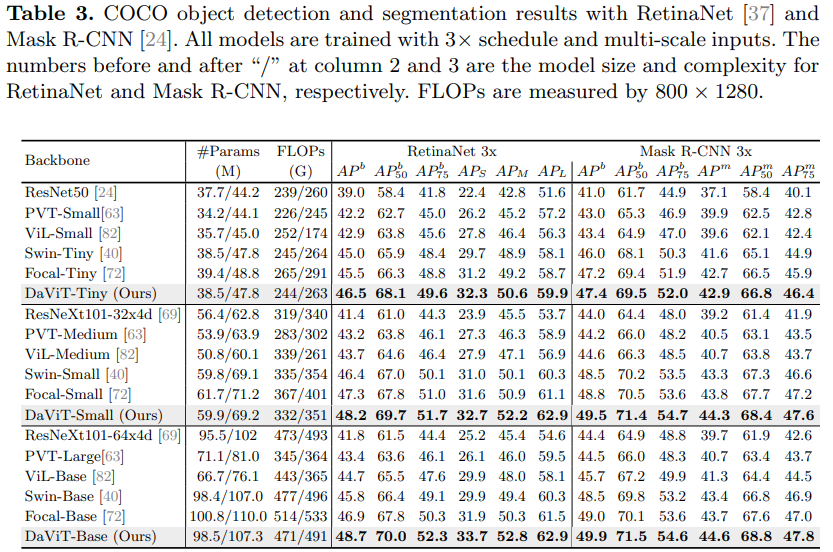
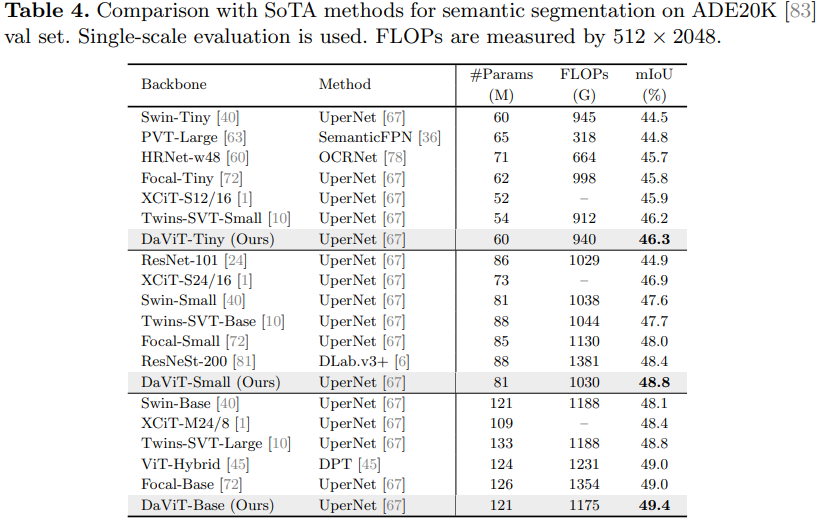
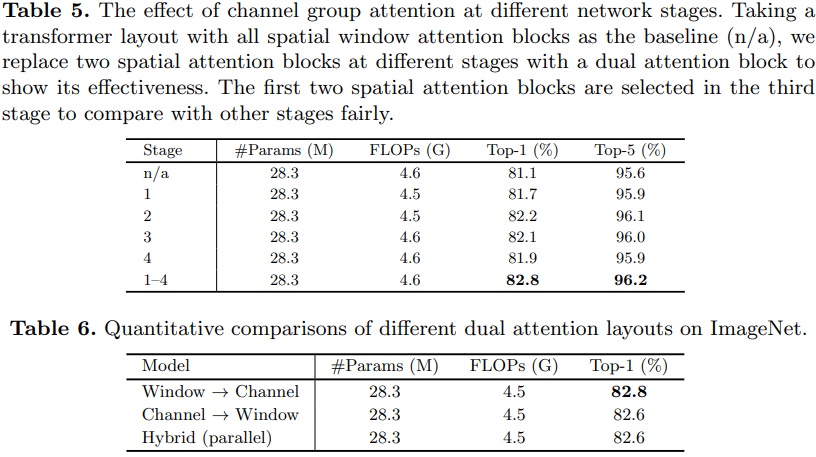
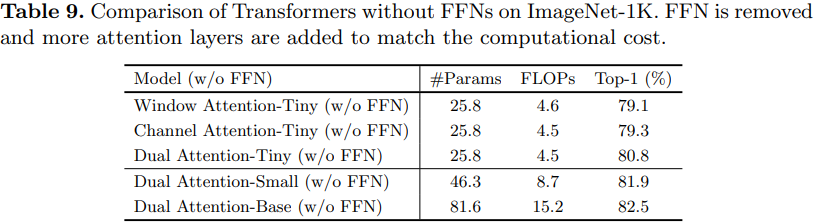








![[洛谷]P2960 [USACO09OCT]Invasion of the Milkweed G(BFS,坑点多多)](https://img-blog.csdnimg.cn/4aa9f0a62717496fb4f61a7f0a9e9f01.png)