这里写目录标题
- cuda层次结构
- 程序架构
- 层次结构
- cuda程序调用
- cuda 内置变量
- GPU内存模型
- 内存结构
- 可编程内存
- 内存作用域
- 寄存器
- 本地内存
- 共享内存
- 共享内存访问冲突
- 常量内存
- 全局内存
- gpu缓存
cuda层次结构

程序架构
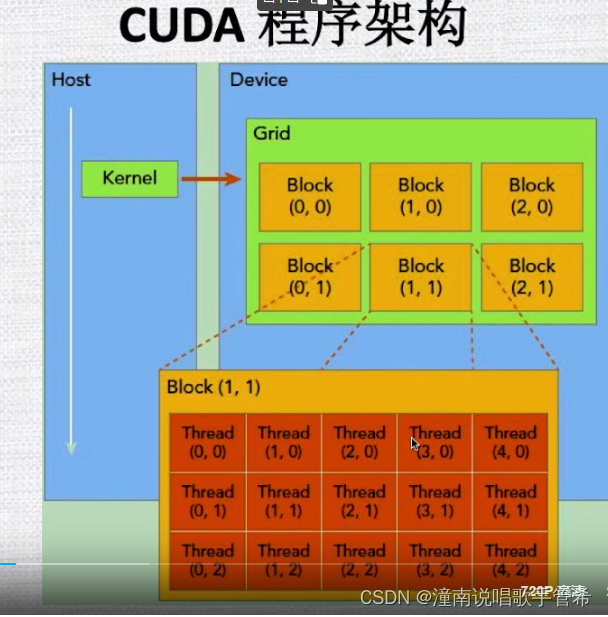
申请内存时是线性的内存,需要知道是按行还是按列排列
设计的好的话内存是对齐的
我们希望线程和内存都是线性排列对齐,效果就会很好。
层次结构

grid每个维度有多少block
block则是定义每个维度有多少线程
cuda程序调用

cuda 内置变量

建立全局一维排序,从而建立宏
从而按照逻辑顺序处理整个向量
处理矩阵的话可以用二维的网格和块
在使用 CUDA 进行矩阵乘法等大规模矩阵计算时,通常需要将输入矩阵按照块的形式划分为多个子矩阵,然后分配到不同的线程块中去计算,以充分利用GPU并行计算的优势。
对于二维的网格和块而言,其可以很好地描述矩阵的结构,这样可以方便地对每个块做相对应的操作。比如,我们可以定义一个2D线程块,其中每个线程块由多个2D线程组成,每个线程处理一个小块或者一个小行/列。然后,我们可以按行、列或元素交错地访问内存,使所有线程能更加高效地并行访问主机内存。
在处理一维向量时,可以考虑将其作为一个一维数组,在代码中可以从全局索引映射到局部索引。在这种情况下,通常需要对齐内存以提升访问速度和性能。具体来说,可以使用 __align__(n) 修饰符来对变量进行对齐处理,将其地址对齐到 n 的倍数上。例如,使用 __align__(16) 可以将变量地址对齐到16字节边界上。
对于单个块的情况,可以使用共享内存来提高访问速度,以便线程块中的所有线程都可以快速、有效地访问它。同时,在使用共享内存时,需要确保线程块中的线程都能够正常读写,以避免竞争条件的发生。
总之,在 CUDA 中处理矩阵和向量时,需要根据任务的具体特点进行灵活选择和处理,以充分发挥GPU并行计算的优势。
GPU内存模型
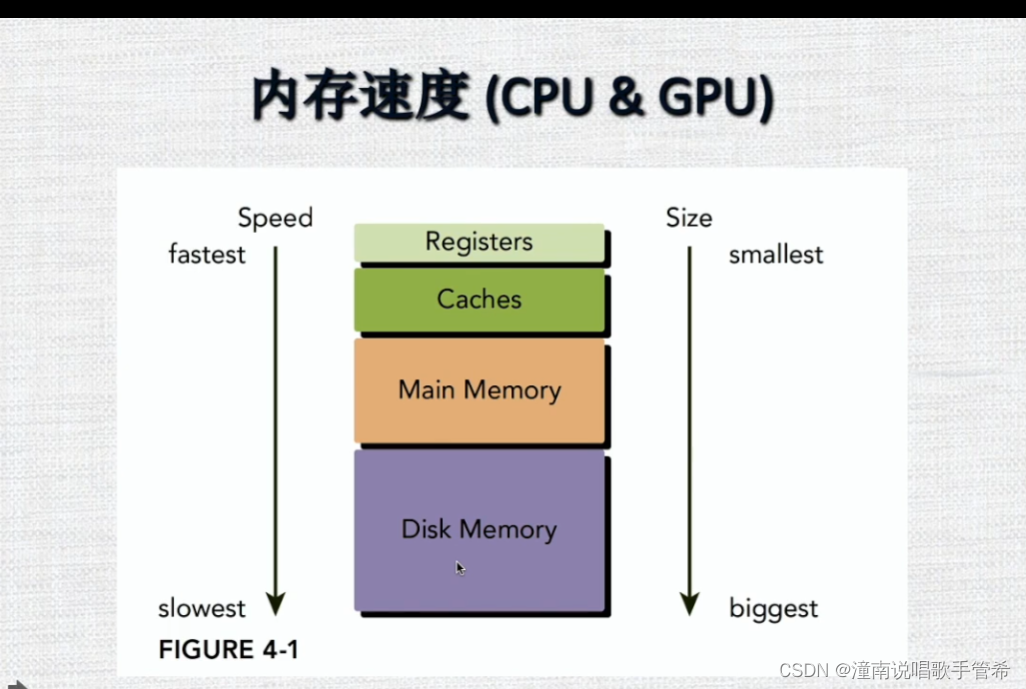
内存结构


每个MP都有L1,还有通过L2共享,和全局相连
可编程内存
可读可写
不可编程内存 cpu和gpu自己管理的内存

内存作用域
线程自己的内存一般都是用完了就释放了

寄存器

本地内存

共享内存

比方共享32k L1自己的16k

共享内存访问冲突


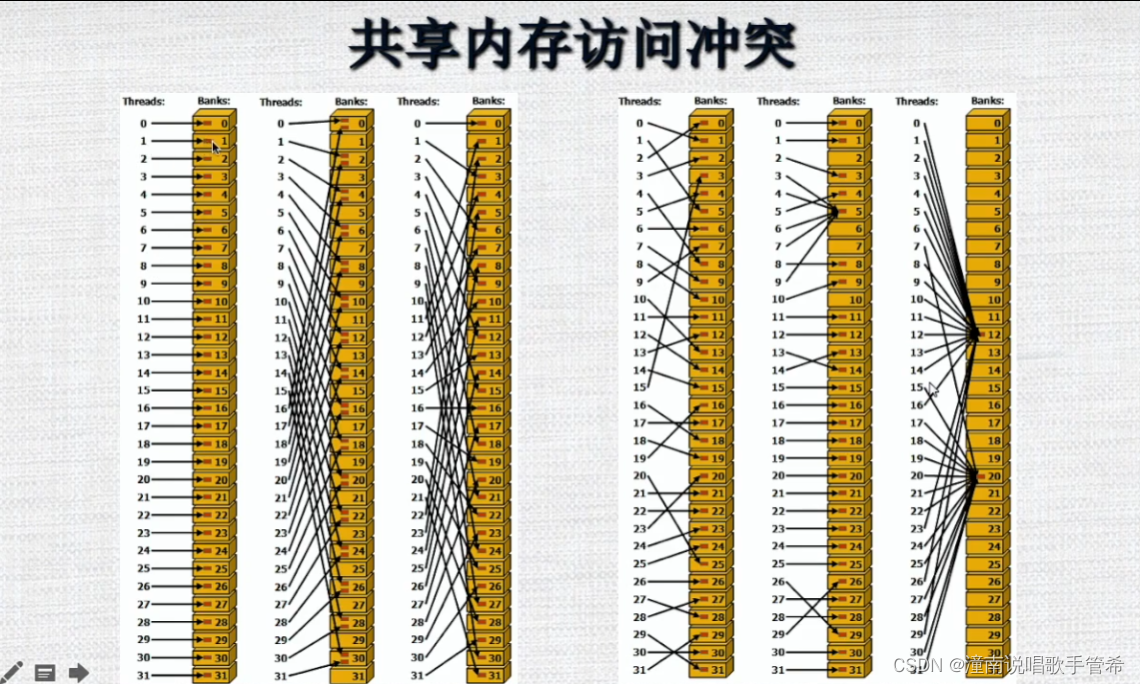
有一些优化机制,比如说广播
常量内存


全局内存
常说的显存,比方说8g 16g
延迟最高,通过l2和mp相连
读的时候有cache 写的时候没有 GPU通过cache大幅度提高效率


有些数据用不到会降低吞吐量
gpu缓存

因为这些缓存的存在提前将要读的数据 load, 极大提高效率