第三十二课 分布式训练

这个是15年的时候沐神在 CMU 装的一个小机群,里面有30台机器,各机群有大概60块 GPU , 60块 GPU一共花了三四万美金的样子,就是大概20万人民币。沐神表示最亏的是当年他们跑了太多深度学习的实验,没有去挖矿,以至于错过了一个亿。少写点paper的话现在也就财务自由了。。。。
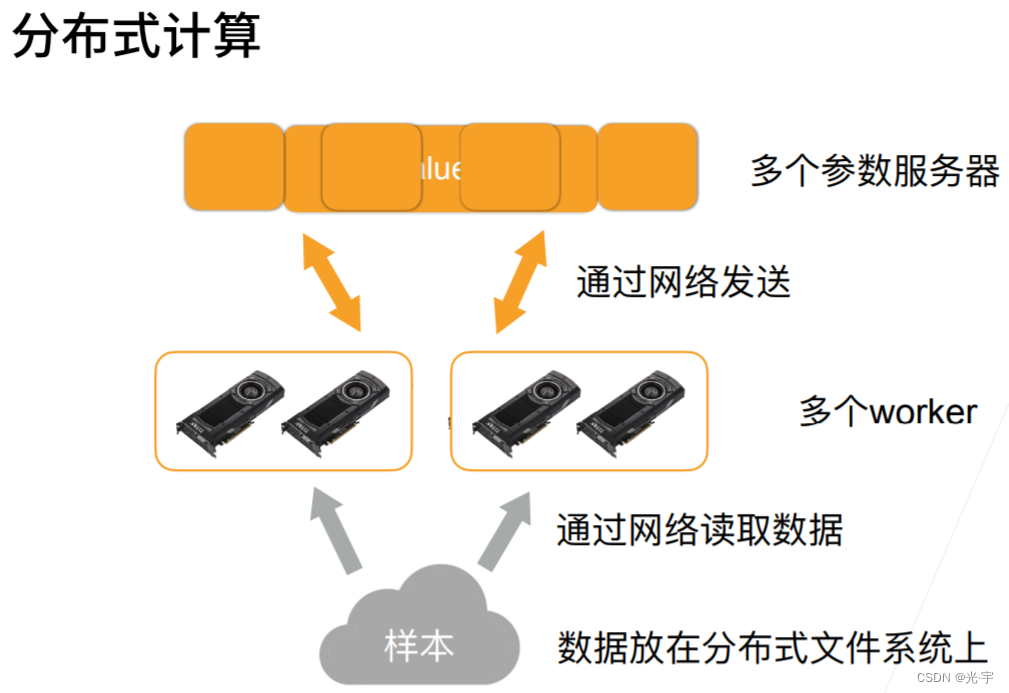
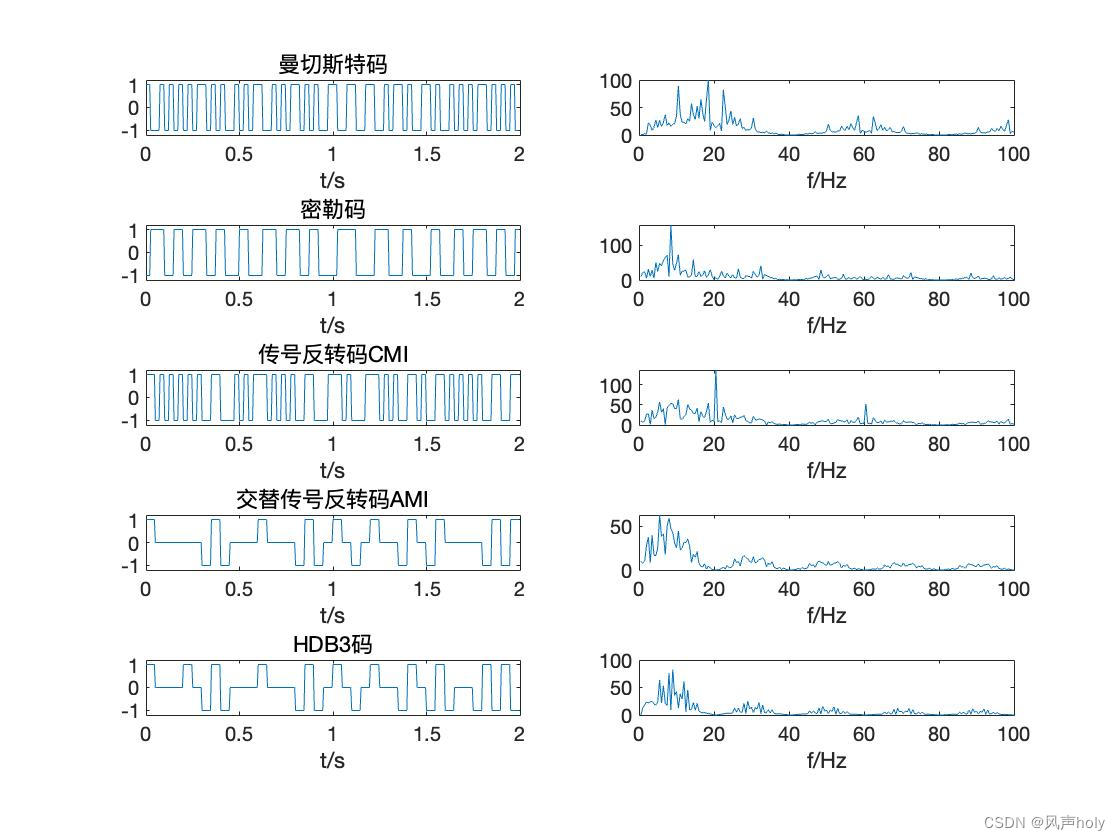
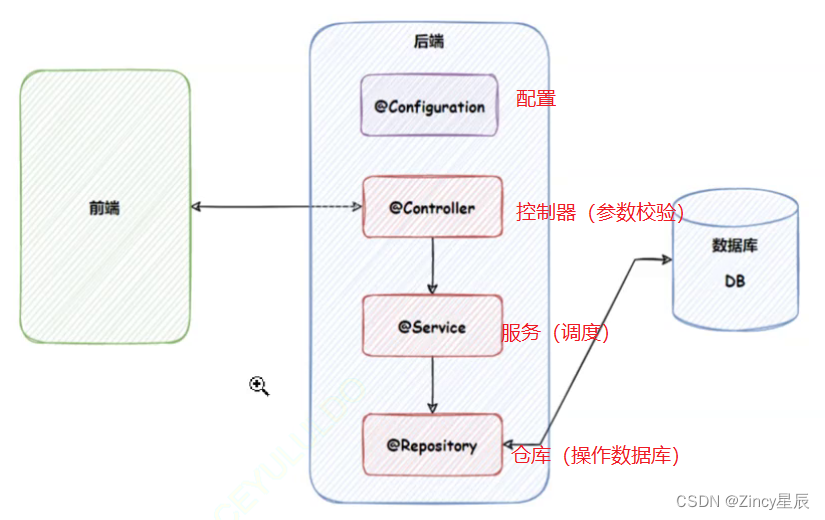
我们给大家看一看。就是说在分布式的情况下,从之前的单机多卡拓展到分布式是什么样子,其实本质上是没任何区别的。首先假设有个样本在这个地方,有四块 GPU , 我们这还是抽象出了一个 key value store 的东西在里面用来存我的参数的。首先分布式第一个不同是说我的数据可能是放在一个分布式的文件系统上,而不是放在机器本地的硬盘上面。所以就是说所有的机器都能够去读取这个样本,这个样本一般是被分开存在不同的磁盘上面。第二个是通常来说有多台机器,每台机器里面有多个 GPU 那么这个机器就叫做 worker 也就是工作站。这里我们假设两台机器,然后有两个GPU每台机要两个GPU那么接下来就是说存参数的地方,通常你来说会放在多个server 上面。那么其实在计算上来说根本就没区别。

如左图所示:
首先假设一台机器有四个 GPU 那么 GPU 之间比如说用 pcie协议交换的话,那么GPU 到GPU的通讯其实不错的。这个地方我们是63 GB per second。那么如果要 GPU 去 CPU 的话,也是要通过一个 pcie 到 CPU 到主内存,这里通常是一根线在这个地方。所以 GPU 到 CPU 的话带宽其实不大,就16 GB 。然后如果要去到一个别的机器的话,那就通过一个交换机。那么比如说我用10个 gbit 的话,那就是1.25 gb/s的带宽,你能看到这里的问题是说 GPU 到 GPU 的通讯是很快的。然后 GPU 到 CPU 通讯会降个5倍或者10倍;然后跨机器的话,通讯就会降得更多。所以就是说你需要去意识到这里面是有个层次化的结构的。所以尽量本地多通讯,实在不行,可以去内存走一走,尽量的少在机器之间做通讯,这就是整个性能的关键。
如右图所示:可以采用这种架构进行本地通讯。

首先我们样本读进来,就假设两台机器的话,如果你的样本批量大小是100的话,那每台机器拿到是50。
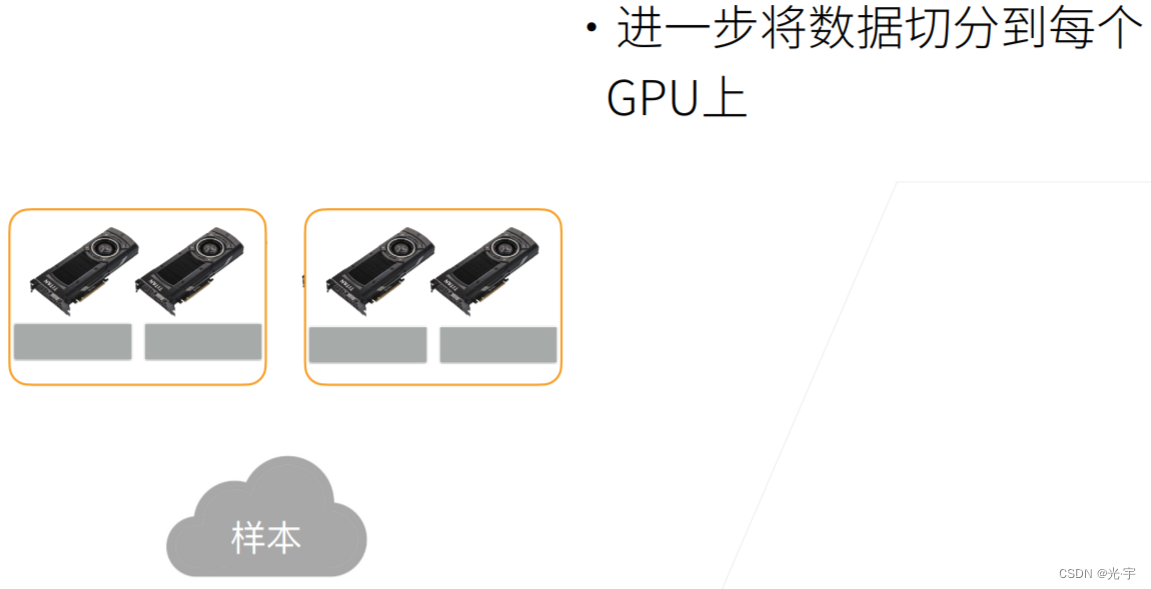
然后接下来就是说我每台机器拿到50,每个卡拿到的是25,我就再拿就是说先复制到每台机器的内存内存里面,再把它分两块复制到你的 GPU 内存上面。
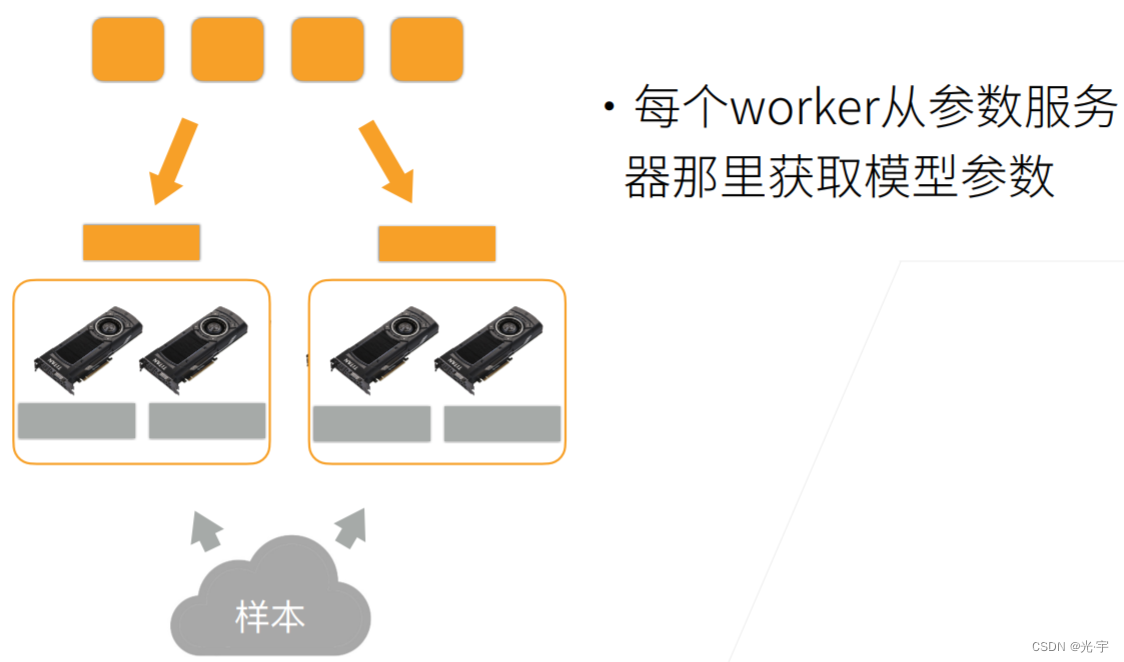
接下来就是说你的参数服务器里面,就是说那每个机器要去拿到你的新的那个模型,就从网络那边拿过来。

然后就是说模型是被复制到每个 GPU 上。所以就不能把这个 GPU 当做每一个实际样例,不能每个 GPU 去要一个模型过来,因为你就要了两次一样的模型。所以具体做法是说假设还有一个 server 跑在内存里面。那么每拿过来一个东西之后,把东西拿到主内存,再复制到GPU 上。
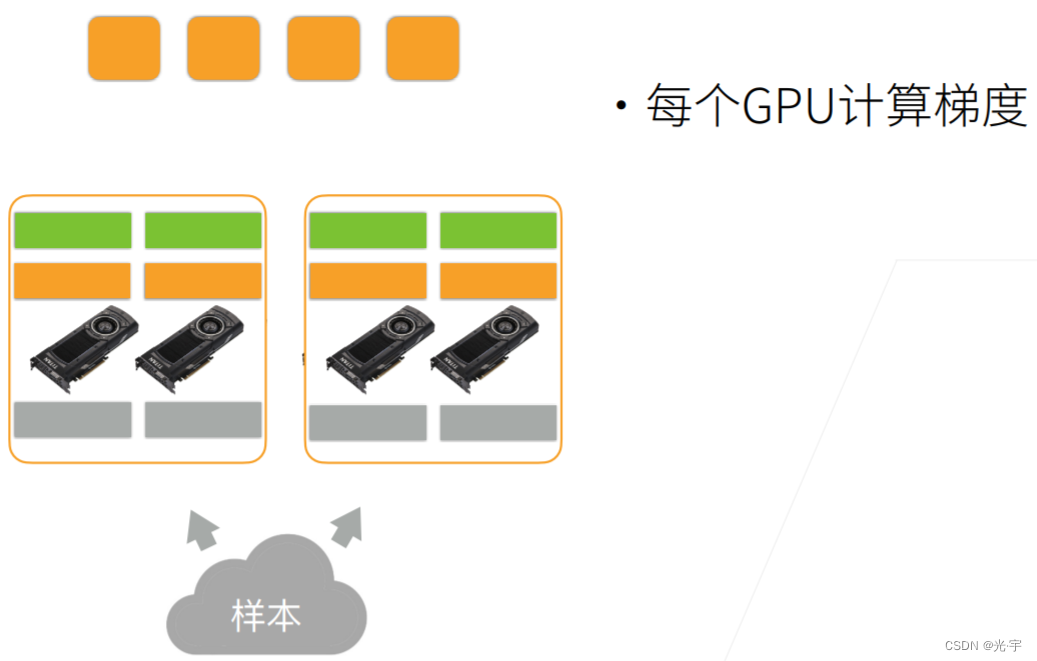
每个 GPU 算自己的梯度。

先在主内存里面把GPU的梯度加起来,就跟之前实现单机多卡是一样的,因为在本地做 all reduce 就是把每个GPU的梯度给加起来。

把梯度加起来之后再发送出去

之后的话参数服务器就是可以做自己的更新。更新完之后就是可以进行下一轮的计算了。所以可以看到本地GPU 之间的通讯还可以,然后GPU的内存也还不错,所以我们尽量在本地做一下聚合,把梯度加起来。


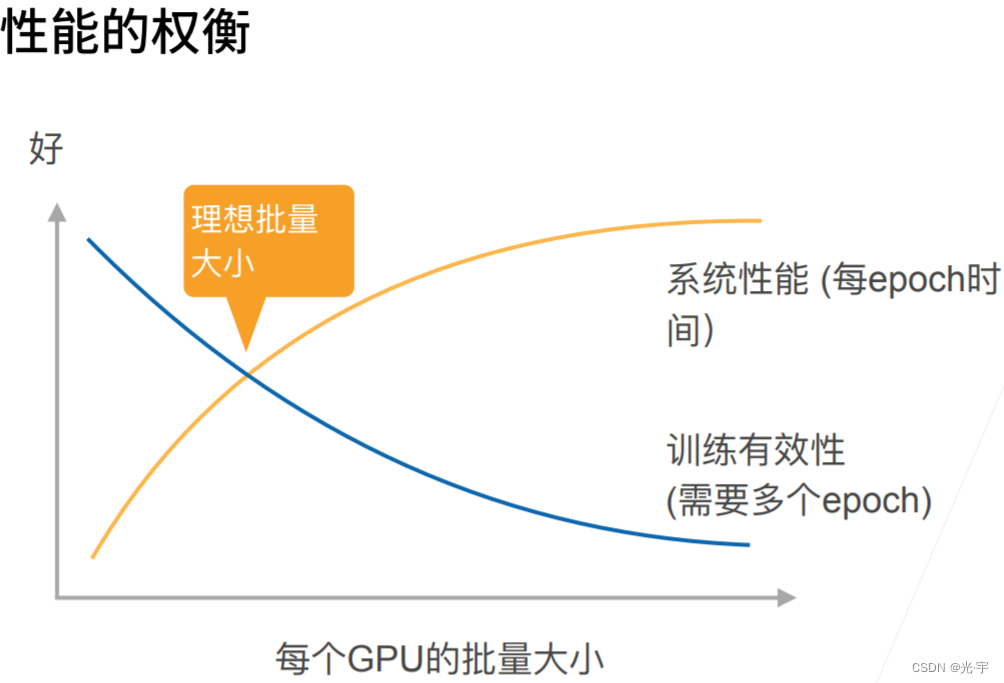
上图可见:每个 epoch 的耗时或者每秒钟能处理的样本数是随着GPU的批量大小而增加的。反过来讲增大批量大小会导致你的训练的有效性变低,就是你的收敛会变慢,这样子你会需要更多的epoch来得达到你要的精度。




![[附源码]Python计算机毕业设计Django汽车租赁管理系统](https://img-blog.csdnimg.cn/0331c370a7234ab093e85295dae75ce2.png)