文章目录
- 一、软件开发整体介绍
- 1.1、软件开发流程
- 1.2、角色分工
- 1.3、软件环境
- 1.4、技术选型
- 1.5、功能架构
- 1.6、角色
- 二、环境搭建
- 2.1、数据库的创建
- 2.2、创建springboot项目并添加依赖
- 2.3、配置yml文件
- 2.4、将前端页面配置进resource目录
- 2.5、静态资源映射
- 三、后台登陆功能的开发
- 3.1、登录界面展示
- 3.2、查看登录请求信息
- 3.3、创建Controller层处理请求
- 3.4、创建结果类R
- 3.5、登录的逻辑
- 3.6、登录功能的代码实现
- 4、完善登录功能
- 4.1、问题分析
- 4.2、过滤器的处理逻辑
- 5、总结
一、软件开发整体介绍
1.1、软件开发流程

1.2、角色分工

1.3、软件环境

1.4、技术选型

1.5、功能架构

1.6、角色

二、环境搭建
2.1、数据库的创建
创建数据库并导入sql文件

2.2、创建springboot项目并添加依赖
略
2.3、配置yml文件
server:
port: 8080
spring:
application:
datasource:
druid:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/www?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
username: root
password: 1234
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
2.4、将前端页面配置进resource目录
2.5、静态资源映射
由于资源没有放在默认的static目录下 我们需要进行静态资源映射
@Slf4j
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始静态资源映射");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
}
这里语句的意思是将浏览器发送的/backend/**的请求定位到resource目录下的backend目录中front同理
三、后台登陆功能的开发
3.1、登录界面展示
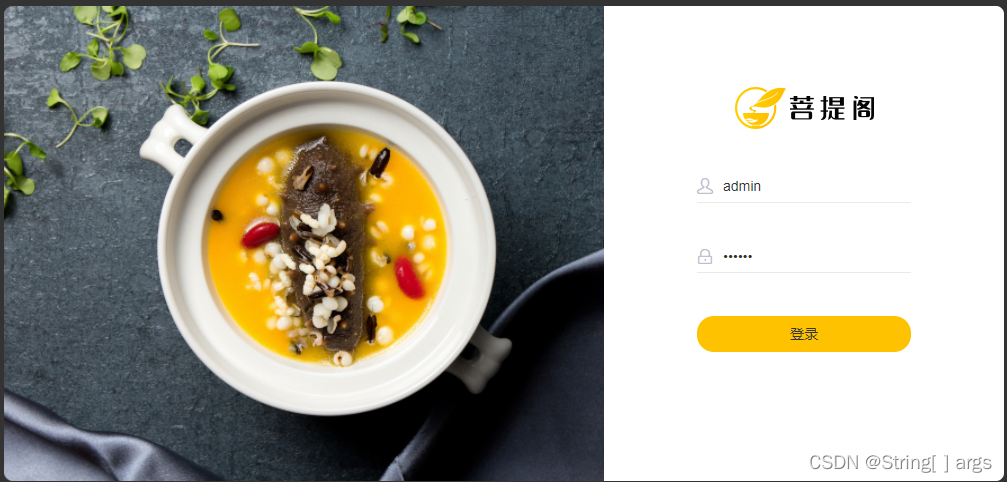
3.2、查看登录请求信息

3.3、创建Controller层处理请求
@Slf4j
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeServiceImpl employeeService;
}
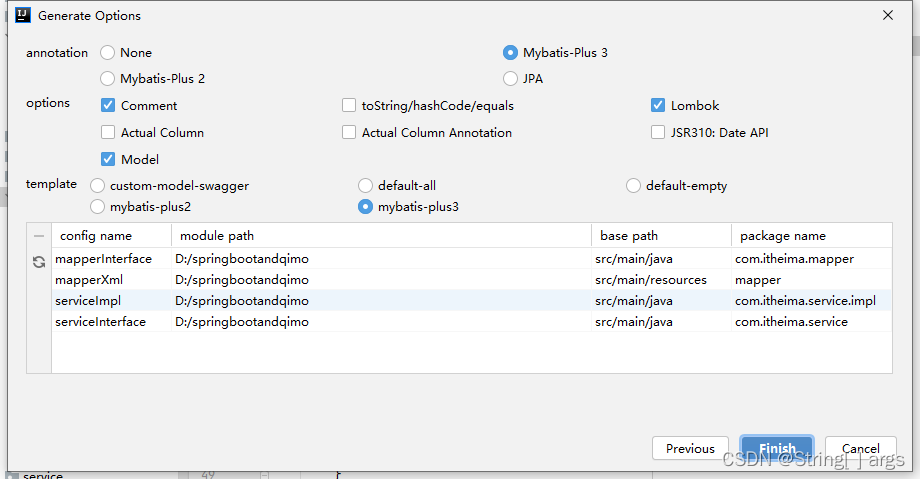
创建控制层的同时我们也需要创建对应的实体类对象以及mapper、service
使用mabatis-x插件进行代码快速生成
3.4、创建结果类R
本项目前端的格式已经固定,前端需要什么参数,后台接口就会返回什么,这时可以创建一个结果类R,服务端响应的所有结果最终都会包装成此种类型返回给前端页面.
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
3.5、登录的逻辑

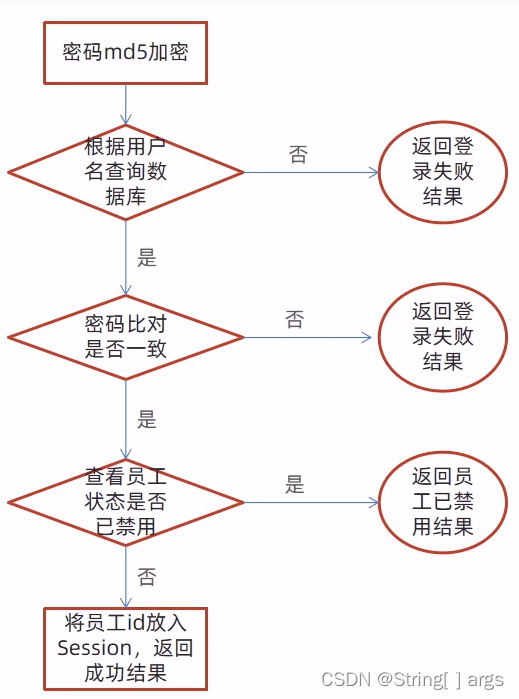
3.6、登录功能的代码实现
md5加密处理
通过@RequestBody 注解将前端传来的json数据转换为实体类employee
再使用employee的getpassword方法获取密码再将密码转为字节类型传入DigestUtils.md5DigestAsHex()中便可
根据用户名查询数据库
首先创建一个LambdaQueryWrappe对象,再使用其中的eq方法匹配数据库中的用户名并返回,如果没有查询到则返回登陆失败结果
密码比对与查看员工状态
获取数据库中对应数据再比对即可
登陆成功 将员工id传入session并返回登陆成功结果
创建session对象并通过session的setAttribute方法传入便可
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request, @RequestBody Employee employee)
{
//1.将页面提交的密码进行md5加密处理
String password=employee.getPassword();
password=DigestUtils.md5DigestAsHex(password.getBytes());
//2.根据用户名查询数据库
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Employee::getUsername,employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//3.如果没有查询到则返回登陆失败结果
if(emp==null)
{
return R.error("用户名不存在,登陆失败!");
}
//4.密码比对
if(!emp.getPassword().equals(password))
{
return R.error("密码错误,登陆失败!");
}
//5.查看员工状态
if(emp.getStatus()==0)
{
return R.error("该账号已被禁用!");
}
//6.登陆成功 将员工id传入session并返回登陆成功结果
HttpSession session = request.getSession();
session.setAttribute("employee",emp.getId());
return R.success(emp);
}
4、完善登录功能
4.1、问题分析
前面我们已经完成了后台系统的员工登录功能开发,但是还存在一个问题:用户如果不登录,直接访问系统首页面,照样可以正常访问。
这种设计并不合理,我们希望看到的效果应该是,只有登录成功后才可以访问系统中的页面,如果没有登录则跳转到登录页面。
那么,具体应该怎么实现呢?
答案就是使用过滤器或者拦截器,在过滤器或者拦截器中判断用户是否已经完成登录,如果没有登录则跳转到登录页面
4.2、过滤器的处理逻辑
过滤器具体的处理逻辑如下:
1、获取本次请求的URI
2、判断本次请求是否需要处理
3、如果不需要处理,则直接放行
4、判断登录状态,如果已登录,则直接放行
5、如果未登录则返回未登录结果

获取本次请求的URI
通过request的getRequestURI()方法便可获取
定义不需要处理的请求路径
定义一个字符串数组,把路径放入其中
判断本次请求是否需要处理
首先创建一个路径匹配器,再创建check方法,其中PATH_MATCHER.match(url, requestURI);即可比较两个路径是否匹配
@WebFilter(filterName = "LoginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
//路径匹配器,支持通配符
public static final AntPathMatcher PATH_MATCHER=new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request=(HttpServletRequest) servletRequest;
HttpServletResponse response=(HttpServletResponse) servletResponse;
// 1、获取本次请求的URI
String requestURI = request.getRequestURI();
log.info("拦截到请求:{}",requestURI);
// 定义不需要处理的请求路径
String[] urls=new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
// 2、判断本次请求是否需要处理
boolean check = check(urls, requestURI);
// 3、如果不需要处理,则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
// 4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee")!=null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;
}
log.info("用户未登录");
// 5、如果未登录则返回未登录结果,通过输出流向客户端页面响应数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
//路径匹配,检查本次请求是否需要放行
public boolean check(String[] urls,String requestURI){
for (String url : urls) {
boolean match = PATH_MATCHER.match(url, requestURI);
if(match==true){
return true;
}
}
return false;
}
}
5、总结
day1完成的便是项目的搭建和其中的登录功能,其中前端页面以及数据库数据都是已经准备好的,主要学习到的有
1、如果静态资源未放置默认的static目录下该如何处理
2、如何将服务器响应的结果包装成特定的类型返回给前端页面
3、如何进行密码加密
4、如何使用过滤器