设计思想
- 此系列文章非本人原创,是学习笔记。
下面讲一些常见的设计思想
基于接口而非实现编程
这个原则非常重要,是一种非常有效的提高代码质量的手段,在平时的开发中特别经常被用到。
如何解读原则中的“接口”二字?
- “基于接口而非实现编程”这条原则的英文描述是:“Program to an interface, not an implementation”。我们理解这条原则的时候,千万不要一开始就与具体的编程语言挂钩,局限在编程语言的“接口”语法中(比如 Java 中的 interface 接口语法)。这条原则最早出现于 1994 年 GoF 的《设计模式》这本书,它先于很多编程语言而诞生(比如 Java 语言),是一条比较抽象、泛化的设计思想。
- 实际上,理解这条原则的关键,就是理解其中的“接口”两个字。还记得我们上一节课讲的“接口”的定义吗?从本质上来看,“接口”就是一组“协议”或者“约定”,是功能提供者提供给使用者的一个“功能列表”。“接口”在不同的应用场景下会有不同的解读,比如服务端与客户端之间的“接口”,类库提供的“接口”,甚至是一组通信的协议都可以叫作“接口”。刚刚对“接口”的理解,都比较偏上层、偏抽象,与实际的写代码离得有点远。如果落实到具体的编码,“基于接口而非实现编程”这条原则中的“接口”,可以理解为编程语言中的接口或者抽象类。
- 前面我们提到,这条原则能非常有效地提高代码质量,之所以这么说,那是因为,应用这条原则,可以将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性。
- 实际上,“基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。后者的表述方式其实更能体现这条原则的设计初衷。在软件开发中,最大的挑战之一就是需求的不断变化,这也是考验代码设计好坏的一个标准。越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对。而抽象就是提高代码扩展性、灵活性、可维护性最有效的手段之一。
如何将这条原则应用到实战中?
假设我们的系统中有很多涉及图片处理和存储的业务逻辑。图片经过处理之后被上传到阿里云上。为了代码复用,我们封装了图片存储相关的代码逻辑,提供了一个统一的 AliyunImageStore 类,供整个系统来使用。具体的代码实现如下所示:
public class AliyunImageStore {
//...省略属性、构造函数等...
public void createBucketIfNotExisting(String bucketName) {
// ...创建bucket代码逻辑...
// ...失败会抛出异常..
}
public String generateAccessToken() {
// ...根据accesskey/secrectkey等生成access token
}
public String uploadToAliyun(Image image, String bucketName, String accessToken) {
//...上传图片到阿里云...
//...返回图片存储在阿里云上的地址(url)...
}
public Image downloadFromAliyun(String url, String accessToken) {
//...从阿里云下载图片...
}
}
// AliyunImageStore类的使用举例
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
//...省略其他无关代码...
public void process() {
Image image = ...; //处理图片,并封装为Image对象
AliyunImageStore imageStore = new AliyunImageStore(/*省略参数*/);
imageStore.createBucketIfNotExisting(BUCKET_NAME);
String accessToken = imageStore.generateAccessToken();
imagestore.uploadToAliyun(image, BUCKET_NAME, accessToken);
}
}
- 整个上传流程包含三个步骤:创建 bucket(你可以简单理解为存储目录)、生成 access token 访问凭证、携带 access token 上传图片到指定的 bucket 中。代码实现非常简单,类中的几个方法定义得都很干净,用起来也很清晰,乍看起来没有太大问题,完全能满足我们将图片存储在阿里云的业务需求。
- 不过,软件开发中唯一不变的就是变化。过了一段时间后,我们自建了私有云,不再将图片存储到阿里云了,而是将图片存储到自建私有云上。为了满足这样一个需求的变化,我们该如何修改代码呢?
- 我们需要重新设计实现一个存储图片到私有云的 PrivateImageStore 类,并用它替换掉项目中所有的 AliyunImageStore 类对象。这样的修改听起来并不复杂,只是简单替换而已,对整个代码的改动并不大。不过,我们经常说,“细节是魔鬼”。这句话在软件开发中特别适用。实际上,刚刚的设计实现方式,就隐藏了很多容易出问题的“魔鬼细节”,我们一块来看看都有哪些。
- 新的 PrivateImageStore 类需要设计实现哪些方法,才能在尽量最小化代码修改的情况下,替换掉 AliyunImageStore 类呢?这就要求我们必须将 AliyunImageStore 类中所定义的所有 public 方法,在 PrivateImageStore 类中都逐一定义并重新实现一遍。而这样做就会存在一些问题,我总结了下面两点。
- 首先,AliyunImageStore 类中有些函数命名暴露了实现细节,比如,uploadToAliyun() 和 downloadFromAliyun()。如果开发这个功能的同事没有接口意识、抽象思维,那这种暴露实现细节的命名方式就不足为奇了,毕竟最初我们只考虑将图片存储在阿里云上。而我们把这种包含“aliyun”字眼的方法,照抄到 PrivateImageStore 类中,显然是不合适的。如果我们在新类中重新命名 uploadToAliyun()、downloadFromAliyun() 这些方法,那就意味着,我们要修改项目中所有使用到这两个方法的代码,代码修改量可能就会很大。
- 其次,将图片存储到阿里云的流程,跟存储到私有云的流程,可能并不是完全一致的。比如,阿里云的图片上传和下载的过程中,需要生产 access token,而私有云不需要 access token。一方面,AliyunImageStore 中定义的 generateAccessToken() 方法不能照抄到 PrivateImageStore 中;另一方面,我们在使用 AliyunImageStore 上传、下载图片的时候,代码中用到了 generateAccessToken() 方法,如果要改为私有云的上传下载流程,这些代码都需要做调整。
- 那这两个问题该如何解决呢?解决这个问题的根本方法就是,在编写代码的时候,要遵从“基于接口而非实现编程”的原则,具体来讲,我们需要做到下面这 3 点。
1. 函数的命名不能暴露任何实现细节。比如,前面提到的 uploadToAliyun() 就不符合要求,应该改为去掉 aliyun 这样的字眼,改为更加抽象的命名方式,比如:upload()。
2. 封装具体的实现细节。比如,跟阿里云相关的特殊上传(或下载)流程不应该暴露给调用者。我们对上传(或下载)流程进行封装,对外提供一个包裹所有上传(或下载)细节的方法,给调用者使用。
3. 为实现类定义抽象的接口。具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议。使用者依赖接口,而不是具体的实现类来编程。 - 我们按照这个思路,把代码重构一下。重构后的代码如下所示:
public interface ImageStore {
String upload(Image image, String bucketName);
Image download(String url);
}
public class AliyunImageStore implements ImageStore {
//...省略属性、构造函数等...
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
String accessToken = generateAccessToken();
//...上传图片到阿里云...
//...返回图片在阿里云上的地址(url)...
}
public Image download(String url) {
String accessToken = generateAccessToken();
//...从阿里云下载图片...
}
private void createBucketIfNotExisting(String bucketName) {
// ...创建bucket...
// ...失败会抛出异常..
}
private String generateAccessToken() {
// ...根据accesskey/secrectkey等生成access token
}
}
// 上传下载流程改变:私有云不需要支持access token
public class PrivateImageStore implements ImageStore {
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
//...上传图片到私有云...
//...返回图片的url...
}
public Image download(String url) {
//...从私有云下载图片...
}
private void createBucketIfNotExisting(String bucketName) {
// ...创建bucket...
// ...失败会抛出异常..
}
}
// ImageStore的使用举例
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
//...省略其他无关代码...
public void process() {
Image image = ...;//处理图片,并封装为Image对象
ImageStore imageStore = new PrivateImageStore(...);
imagestore.upload(image, BUCKET_NAME);
}
}
- 除此之外,很多人在定义接口的时候,希望通过实现类来反推接口的定义。先把实现类写好,然后看实现类中有哪些方法,照抄到接口定义中。如果按照这种思考方式,就有可能导致接口定义不够抽象,依赖具体的实现。这样的接口设计就没有意义了。不过,如果你觉得这种思考方式更加顺畅,那也没问题,只是将实现类的方法搬移到接口定义中的时候,要有选择性的搬移,不要将跟具体实现相关的方法搬移到接口中,比如 AliyunImageStore 中的 generateAccessToken() 方法。
- 总结一下,我们在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动。
是否需要为每个类定义接口?
- 看了刚刚的讲解,你可能会有这样的疑问:为了满足这条原则,我是不是需要给每个实现类都定义对应的接口呢?在开发的时候,是不是任何代码都要只依赖接口,完全不依赖实现编程呢?
- 做任何事情都要讲求一个“度”,过度使用这条原则,非得给每个类都定义接口,接口满天飞,也会导致不必要的开发负担。至于什么时候,该为某个类定义接口,实现基于接口的编程,什么时候不需要定义接口,直接使用实现类编程,我们做权衡的根本依据,还是要回归到设计原则诞生的初衷上来。只要搞清楚了这条原则是为了解决什么样的问题而产生的,你就会发现,很多之前模棱两可的问题,都会变得豁然开朗。
- 前面我们也提到,这条原则的设计初衷是,将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性。
- 从这个设计初衷上来看,如果在我们的业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那我们就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了。
- 除此之外,越是不稳定的系统,我们越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那我们就没有必要为其扩展性,投入不必要的开发时间。
多用组合少用继承
在面向对象编程中,有一条非常经典的设计原则,那就是:组合优于继承,多用组合少用继承。为什么不推荐使用继承?组合相比继承有哪些优势?如何判断该用组合还是继承?今天,我们就围绕着这三个问题,来详细讲解一下这条设计原则。
为什么不推荐使用继承?
- 继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在项目中使用继承,网上有很多争议。很多人觉得继承是一种反模式,应该尽量少用,甚至不用。为什么会有这样的争议?我们通过一个例子来解释一下。
- 假设我们要设计一个关于鸟的类。我们将“鸟类”这样一个抽象的事物概念,定义为一个抽象类 AbstractBird。所有更细分的鸟,比如麻雀、鸽子、乌鸦等,都继承这个抽象类。
- 我们知道,大部分鸟都会飞,那我们可不可以在 AbstractBird 抽象类中,定义一个 fly() 方法呢?答案是否定的。尽管大部分鸟都会飞,但也有特例,比如鸵鸟就不会飞。鸵鸟继承具有 fly() 方法的父类,那鸵鸟就具有“飞”这样的行为,这显然不符合我们对现实世界中事物的认识。当然,你可能会说,我在鸵鸟这个子类中重写(override)fly() 方法,让它抛出 UnSupportedMethodException 异常不就可以了吗?具体的代码实现如下所示:
public class AbstractBird {
//...省略其他属性和方法...
public void fly() { //... }
}
public class Ostrich extends AbstractBird { //鸵鸟
//...省略其他属性和方法...
public void fly() {
throw new UnSupportedMethodException("I can't fly.'");
}
}
-
这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,我们都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了我们之后要讲的最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率。
-
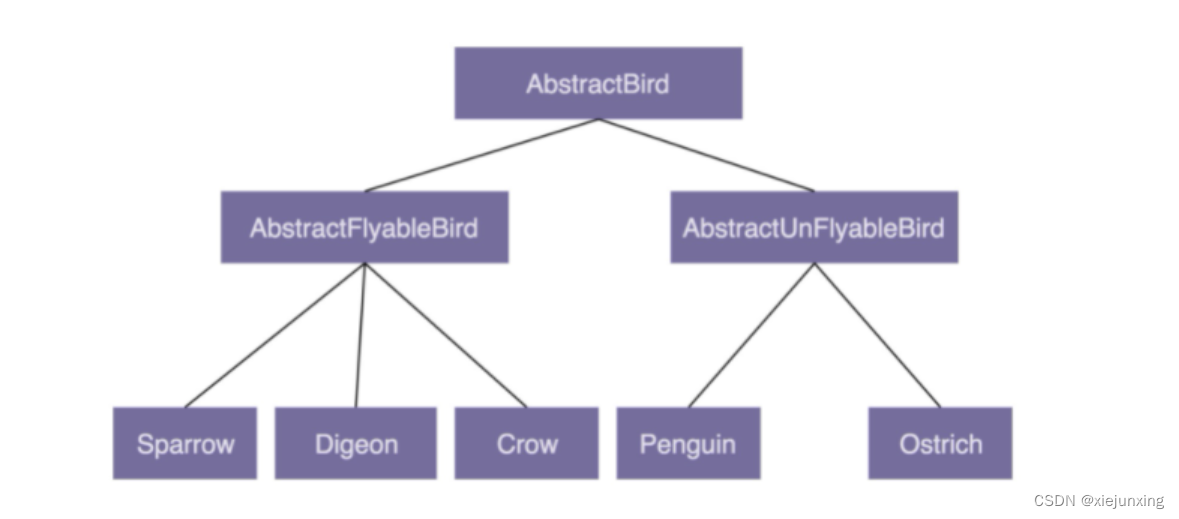
你可能又会说,那我们再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类,不就可以了吗?具体的继承关系如下图所示:
-
从图中我们可以看出,继承关系变成了三层。不过,整体上来讲,目前的继承关系还比较简单,层次比较浅,也算是一种可以接受的设计思路。我们再继续加点难度。在刚刚这个场景中,我们只关注“鸟会不会飞”,但如果我们还关注“鸟会不会叫”,那这个时候,我们又该如何设计类之间的继承关系呢?
-
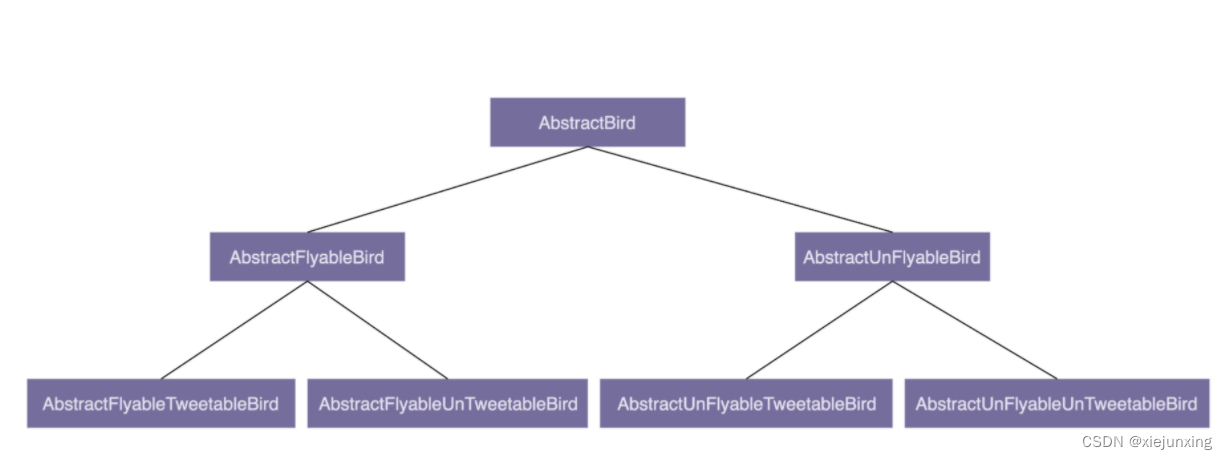
是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果我们继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)。
-
如果我们还需要考虑“是否会下蛋”这样一个行为,那估计就要组合爆炸了。类的继承层次会越来越深、继承关系会越来越复杂。而这种层次很深、很复杂的继承关系,一方面,会导致代码的可读性变差。因为我们要搞清楚某个类具有哪些方法、属性,必须阅读父类的代码、父类的父类的代码……一直追溯到最顶层父类的代码。另一方面,这也破坏了类的封装特性,将父类的实现细节暴露给了子类。子类的实现依赖父类的实现,两者高度耦合,一旦父类代码修改,就会影响所有子类的逻辑。
-
总之,继承最大的问题就在于:继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。这也是为什么我们不推荐使用继承。那刚刚例子中继承存在的问题,我们又该如何来解决呢?你可以先自己思考一下,再听我下面的讲解。
组合相比继承有哪些优势?
1. 实际上,我们可以利用组合(composition)、接口、委托(delegation)三个技术手段,一块儿来解决刚刚继承存在的问题。 2. 接口表示具有某种行为特性。针对“会飞”这样一个行为特性,我们可以定义一个 Flyable 接口,只让会飞的鸟去实现这个接口。对于会叫、会下蛋这些行为特性,我们可以类似地定义 Tweetable 接口、EggLayable 接口。我们将这个设计思路翻译成 Java 代码的话,就是下面这个样子:public interface Flyable {
void fly();
}
public interface Tweetable {
void tweet();
}
public interface EggLayable {
void layEgg();
}
public class Ostrich implements Tweetable, EggLayable {//鸵鸟
//... 省略其他属性和方法...
@Override
public void tweet() { //... }
@Override
public void layEgg() { //... }
}
public class Sparrow impelents Flyable, Tweetable, EggLayable {//麻雀
//... 省略其他属性和方法...
@Override
public void fly() { //... }
@Override
public void tweet() { //... }
@Override
public void layEgg() { //... }
}
public interface Flyable {
void fly();
}
public class FlyAbility implements Flyable {
@Override
public void fly() { //... }
}
//省略Tweetable/TweetAbility/EggLayable/EggLayAbility
public class Ostrich implements Tweetable, EggLayable {//鸵鸟
private TweetAbility tweetAbility = new TweetAbility(); //组合
private EggLayAbility eggLayAbility = new EggLayAbility(); //组合
//... 省略其他属性和方法...
@Override
public void tweet() {
tweetAbility.tweet(); // 委托
}
@Override
public void layEgg() {
eggLayAbility.layEgg(); // 委托
}
}
我们知道继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过其他技术手段来达成。比如 is-a 关系,我们可以通过组合和接口的 has-a 关系来替代;多态特性我们可以利用接口来实现;代码复用我们可以通过组合和委托来实现。所以,从理论上讲,通过组合、接口、委托三个技术手段,我们完全可以替换掉继承,在项目中不用或者少用继承关系,特别是一些复杂的继承关系。
如何判断该用组合还是继承?
- 尽管我们鼓励多用组合少用继承,但组合也并不是完美的,继承也并非一无是处。从上面的例子来看,继承改写成组合意味着要做更细粒度的类的拆分。这也就意味着,我们要定义更多的类和接口。类和接口的增多也就或多或少地增加代码的复杂程度和维护成本。所以,在实际的项目开发中,我们还是要根据具体的情况,来具体选择该用继承还是组合。
- 如果类之间的继承结构稳定(不会轻易改变),继承层次比较浅(比如,最多有两层继承关系),继承关系不复杂,我们就可以大胆地使用继承。反之,系统越不稳定,继承层次很深,继承关系复杂,我们就尽量使用组合来替代继承。
- 除此之外,还有一些设计模式会固定使用继承或者组合。比如,装饰者模式(decorator pattern)、策略模式(strategy pattern)、组合模式(composite pattern)等都使用了组合关系,而模板模式(template pattern)使用了继承关系。
4. 前面我们讲到继承可以实现代码复用。利用继承特性,我们把相同的属性和方法,抽取出来,定义到父类中。子类复用父类中的属性和方法,达到代码复用的目的。但是,有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系。比如,Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。仅仅为了代码复用,生硬地抽象出一个父类出来,会影响到代码的可读性。如果不熟悉背后设计思路的同事,发现 Crawler 类和 PageAnalyzer 类继承同一个父类,而父类中定义的却只是 URL 相关的操作,会觉得这个代码写得莫名其妙,理解不了。这个时候,使用组合就更加合理、更加灵活。具体的代码实现如下所示:
public class Url {
//...省略属性和方法
}
public class Crawler {
private Url url; // 组合
public Crawler() {
this.url = new Url();
}
//...
}
public class PageAnalyzer {
private Url url; // 组合
public PageAnalyzer() {
this.url = new Url();
}
//..
}
还有一些特殊的场景要求我们必须使用继承。如果你不能改变一个函数的入参类型,而入参又非接口,为了支持多态,只能采用继承来实现。比如下面这样一段代码,其中 FeignClient 是一个外部类,我们没有权限去修改这部分代码,但是我们希望能重写这个类在运行时执行的 encode() 函数。这个时候,我们只能采用继承来实现了。
public class FeignClient { // Feign Client框架代码
//...省略其他代码...
public void encode(String url) { //... }
}
public void demofunction(FeignClient feignClient) {
//...
feignClient.encode(url);
//...
}
public class CustomizedFeignClient extends FeignClient {
@Override
public void encode(String url) { //...重写encode的实现...}
}
// 调用
FeignClient client = new CustomizedFeignClient();
demofunction(client);
尽管有些人说,要杜绝继承,100% 用组合代替继承,但是我的观点没那么极端!之所以“多用组合少用继承”这个口号喊得这么响,只是因为,长期以来,我们过度使用继承。还是那句话,组合并不完美,继承也不是一无是处。只要我们控制好它们的副作用、发挥它们各自的优势,在不同的场合下,恰当地选择使用继承还是组合,这才是我们所追求的境界。
如何通过封装、抽象、模块化、中间层等解耦代码?
“解耦”为何如此重要?
- 软件设计与开发最重要的工作之一就是应对复杂性。人处理复杂性的能力是有限的。过于复杂的代码往往在可读性、可维护性上都不友好。那如何来控制代码的复杂性呢?手段有很多,我个人认为,最关键的就是解耦,保证代码松耦合、高内聚。如果说重构是保证代码质量不至于腐化到无可救药地步的有效手段,那么利用解耦的方法对代码重构,就是保证代码不至于复杂到无法控制的有效手段。
- 后文迪米特法则有介绍,什么是“高内聚、松耦合”。。实际上,“高内聚、松耦合”是一个比较通用的设计思想,不仅可以指导细粒度的类和类之间关系的设计,还能指导粗粒度的系统、架构、模块的设计。相对于编码规范,它能够在更高层次上提高代码的可读性和可维护性。
- 不管是阅读代码还是修改代码,“高内聚、松耦合”的特性可以让我们聚焦在某一模块或类中,不需要了解太多其他模块或类的代码,让我们的焦点不至于过于发散,降低了阅读和修改代码的难度。而且,因为依赖关系简单,耦合小,修改代码不至于牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多。同时,“高内聚、松耦合”的代码可测试性也更加好,容易 mock 或者很少需要 mock 外部依赖的模块或者类。
- 除此之外,代码“高内聚、松耦合”,也就意味着,代码结构清晰、分层和模块化合理、依赖关系简单、模块或类之间的耦合小,那代码整体的质量就不会差。即便某个具体的类或者模块设计得不怎么合理,代码质量不怎么高,影响的范围是非常有限的。我们可以聚焦于这个模块或者类,做相应的小型重构。而相对于代码结构的调整,这种改动范围比较集中的小型重构的难度就容易多了。
代码是否需要“解耦”?
- 那现在问题来了,我们该怎么判断代码的耦合程度呢?或者说,怎么判断代码是否符合“高内聚、松耦合”呢?再或者说,如何判断系统是否需要解耦重构呢?
- 间接的衡量标准有很多,前面我们讲到了一些,比如,看修改代码会不会牵一发而动全身。除此之外,还有一个直接的衡量标准,也是我在阅读源码的时候经常会用到的,那就是把模块与模块之间、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
- 如果依赖关系复杂、混乱,那从代码结构上来讲,可读性和可维护性肯定不是太好,那我们就需要考虑是否可以通过解耦的方法,让依赖关系变得清晰、简单。当然,这种判断还是有比较强的主观色彩,但是可以作为一种参考和梳理依赖的手段,配合间接的衡量标准一块来使用。
如何给代码“解耦”?
封装与抽象
封装和抽象作为两个非常通用的设计思想,可以应用在很多设计场景中,比如系统、模块、lib、组件、接口、类等等的设计。封装和抽象可以有效地隐藏实现的复杂性,隔离实现的易变性,给依赖的模块提供稳定且易用的抽象接口
中间层
引入中间层能简化模块或类之间的依赖关系。下面这张图是引入中间层前后的依赖关系对比图。在引入数据存储中间层之前,A、B、C 三个模块都要依赖内存一级缓存、Redis 二级缓存、DB 持久化存储三个模块。在引入中间层之后,三个模块只需要依赖数据存储一个模块即可。从图上可以看出,中间层的引入明显地简化了依赖关系,让代码结构更加清晰
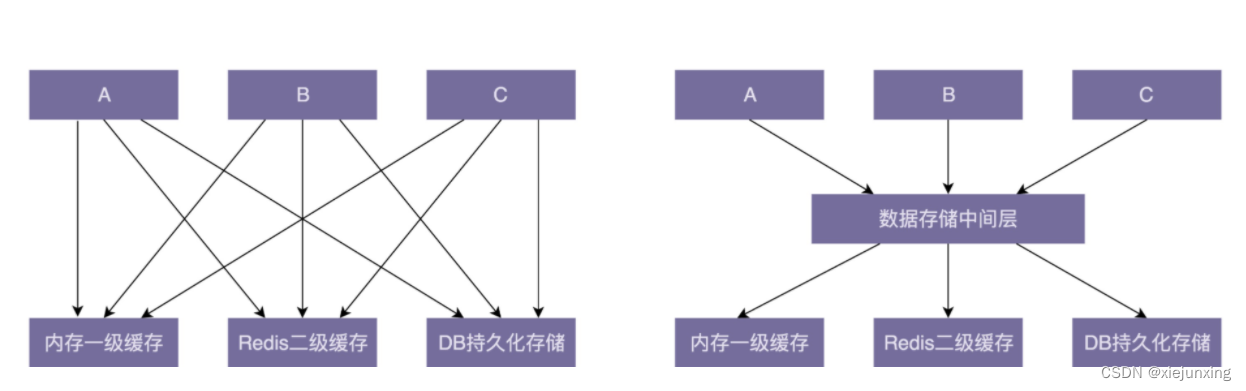
除此之外,我们在进行重构的时候,引入中间层可以起到过渡的作用,能够让开发和重构同步进行,不互相干扰。比如,某个接口设计得有问题,我们需要修改它的定义,同时,所有调用这个接口的代码都要做相应的改动。如果新开发的代码也用到这个接口,那开发就跟重构冲突了。为了让重构能小步快跑,我们可以分下面四个阶段来完成接口的修改。
- 第一阶段:引入一个中间层,包裹老的接口,提供新的接口定义。
- 第二阶段:新开发的代码依赖中间层提供的新接口。
- 第三阶段:将依赖老接口的代码改为调用新接口。
- 第四阶段:确保所有的代码都调用新接口之后,删除掉老的接口。
这样,每个阶段的开发工作量都不会很大,都可以在很短的时间内完成。重构跟开发冲突的概率也变小了。
模块化
模块化是构建复杂系统常用的手段。不仅在软件行业,在建筑、机械制造等行业,这个手段也非常有用。对于一个大型复杂系统来说,没有人能掌控所有的细节。之所以我们能搭建出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独立的模块,让不同的人负责不同的模块,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转。
其他设计思想和原则
“高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。实际上,在前面的章节中,我们已经多次提到过这个设计思想。很多设计原则都以实现代码的“高内聚、松耦合”为目的。我们来一块总结回顾一下都有哪些原则。
(这里没有讲的,在后面文章里)
- 单一职责原则
我们前面提到,内聚性和耦合性并非独立的。高内聚会让代码更加松耦合,而实现高内聚的重要指导原则就是单一职责原则。模块或者类的职责设计得单一,而不是大而全,那依赖它的类和它依赖的类就会比较少,代码耦合也就相应的降低了。
- 基于接口而非实现编程
基于接口而非实现编程能通过接口这样一个中间层,隔离变化和具体的实现。这样做的好处是,在有依赖关系的两个模块或类之间,一个模块或者类的改动,不会影响到另一个模块或类。实际上,这就相当于将一种强依赖关系(强耦合)解耦为了弱依赖关系(弱耦合)。依赖注入
- 依赖注入
跟基于接口而非实现编程思想类似,依赖注入也是将代码之间的强耦合变为弱耦合。尽管依赖注入无法将本应该有依赖关系的两个类,解耦为没有依赖关系,但可以让耦合关系没那么紧密,容易做到插拔替换
- 多用组合少用继承
我们知道,继承是一种强依赖关系,父类与子类高度耦合,且这种耦合关系非常脆弱,牵一发而动全身,父类的每一次改动都会影响所有的子类。相反,组合关系是一种弱依赖关系,这种关系更加灵活,所以,对于继承结构比较复杂的代码,利用组合来替换继承,也是一种解耦的有效手段。
- 迪米特法则
迪米特法则讲的是,不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。从定义上,我们明显可以看出,这条原则的目的就是为了实现代码的松耦合。至于如何应用这条原则来解耦代码,你可以回过头去阅读一下第 22 讲,这里我就不赘述了。除了上面讲到的这些设计思想和原则之外,还有一些设计模式也是为了解耦依赖,比如观察者模式,有关这一部分的内容,我们留在设计模式模块中慢慢讲解。


![[MAUI程序设计] 用Handler实现自定义跨平台控件](https://img-blog.csdnimg.cn/0436623e1b9d4b6f817f0045c69a6668.png)