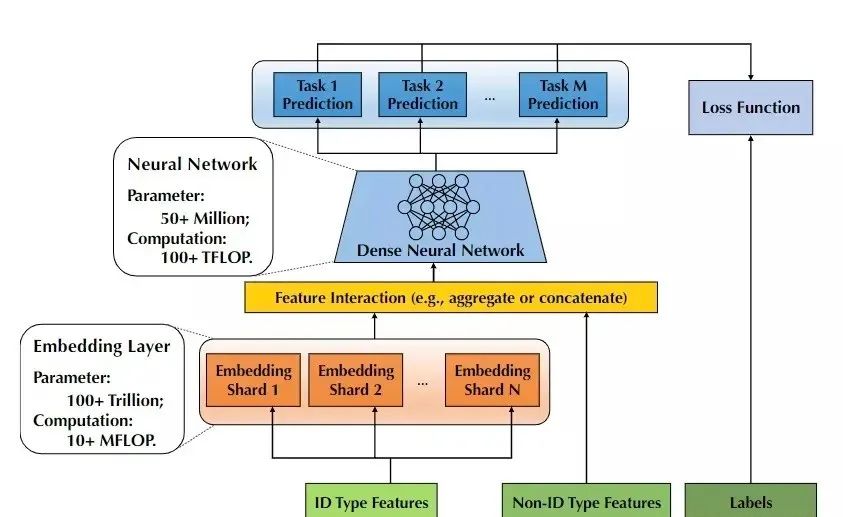
苏生不惑第
431篇原创文章,将本公众号设为星标,第一时间看最新文章。
4年来苏生不惑这个公众号已经写了400多篇原创文章,去年分享过文章更新版:整理下苏生不惑开发过的那些工具和脚本 ,今年再更新下我开发过的原创工具和脚本。
公众号分享过的上千个软件都同步到我的知识星球了加入我的知识星球 ,这个星球运营一年多了,星球内可以提问,交流,而且搜索方便,比微信群好用多了,欢迎加入。
公众号文章/音频/视频下载
首先在公众号苏生不惑后台回复 公众号 获取工具下载地址,这次增加了下载文件里的公众号文章,打开wechat_down.exe输入文章地址即可下载文章和文章里的文章,比如这篇文章链接视频更新版:批量下载公众号文章内容/话题/图片/封面/音频/视频,导出html,pdf,excel包含阅读数/点赞数/留言数 https://mp.weixin.qq.com/s/c-jpCXxUtZpzxTCSx0Fu_w ,下载效果如图: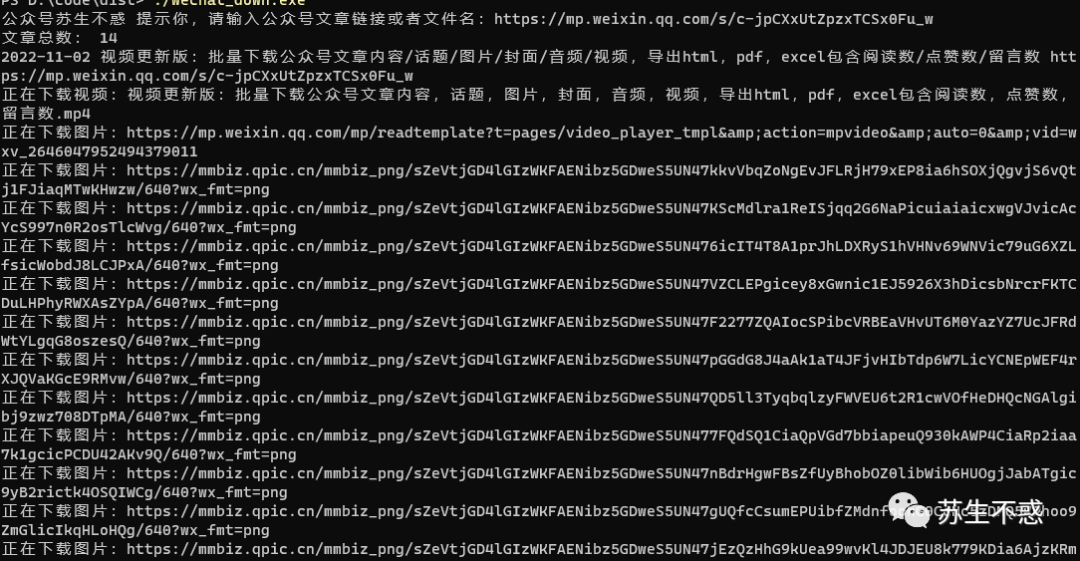
输入文件名下载文件里的公众号文章,每行一个链接:
我之前还录制了个视频视频更新版:批量下载公众号文章内容/话题/图片/封面/音频/视频,导出html,pdf,excel包含阅读数/点赞数/留言数 :
下载的音频保存在audio目录,视频保存在video目录,封面保存在cover目录,图片保存在images目录,文章内容保存在html目录。
文章里引用的腾讯视频直接下载比较麻烦,所以保存视频链接到excel文件了,可以再复制视频链接用lux之类的工具下载。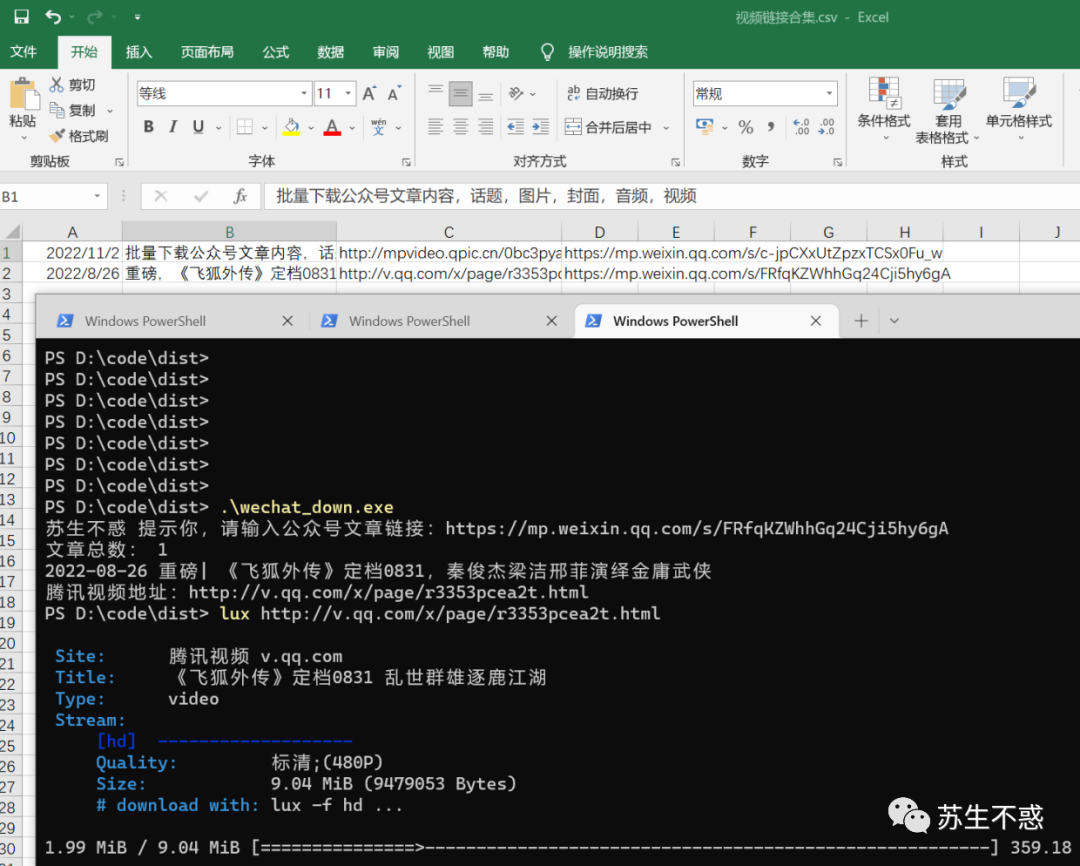
下载过的文章链接在文件wechat_list.txt,第2次下载会跳过已经下载过的文章,如果有什么问题可以向我反馈。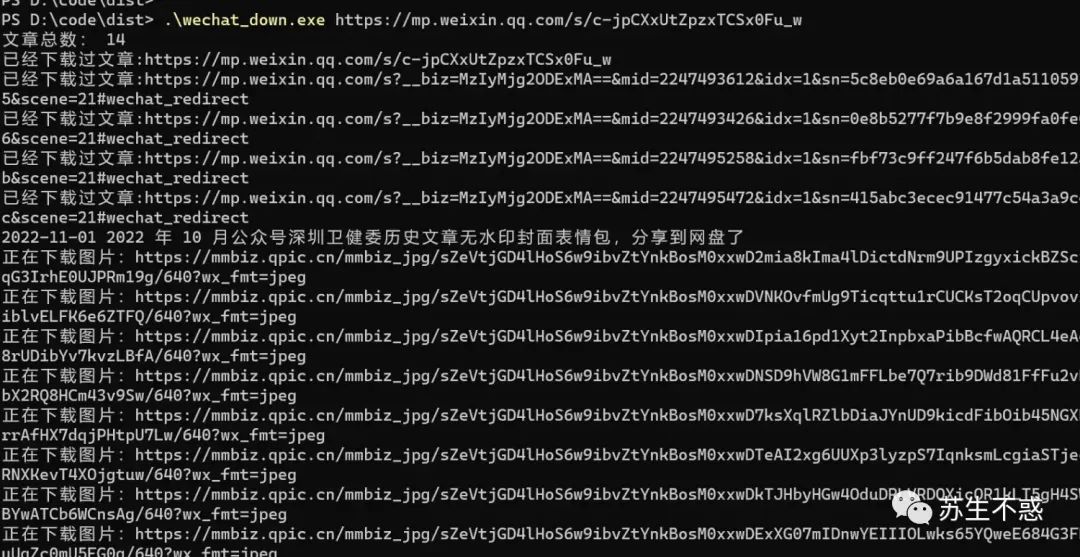
公众号话题文章/音频/视频下载
还是在公众号苏生不惑后台回复 公众号 获取工具下载地址,比如这个话题:
打开wechat_topic_down.exe输入话题链接下载话题里的文章,下载效果如图: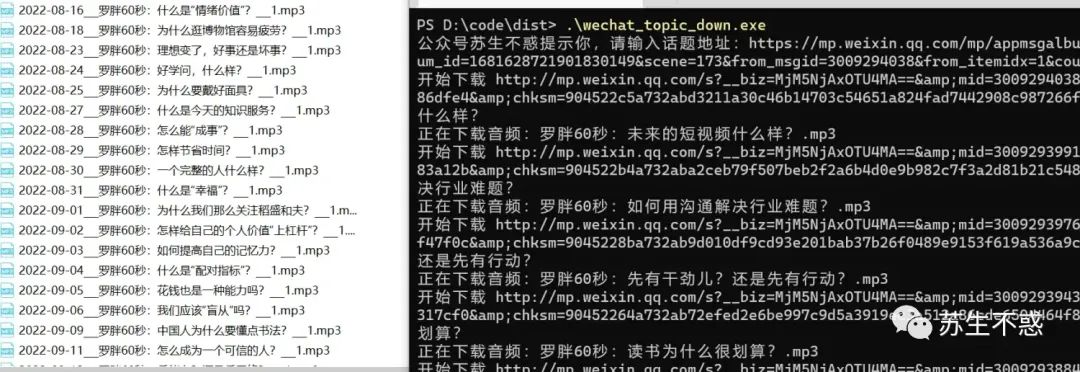
音频/视频和文章html都下载了:

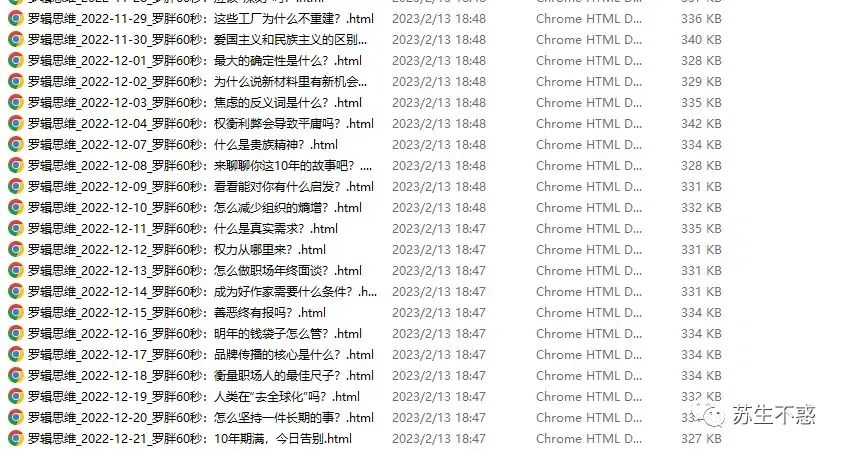
下载过的文章链接在文件wechat_topic_list.txt,第2次下载会跳过已经下载过的文章,效果: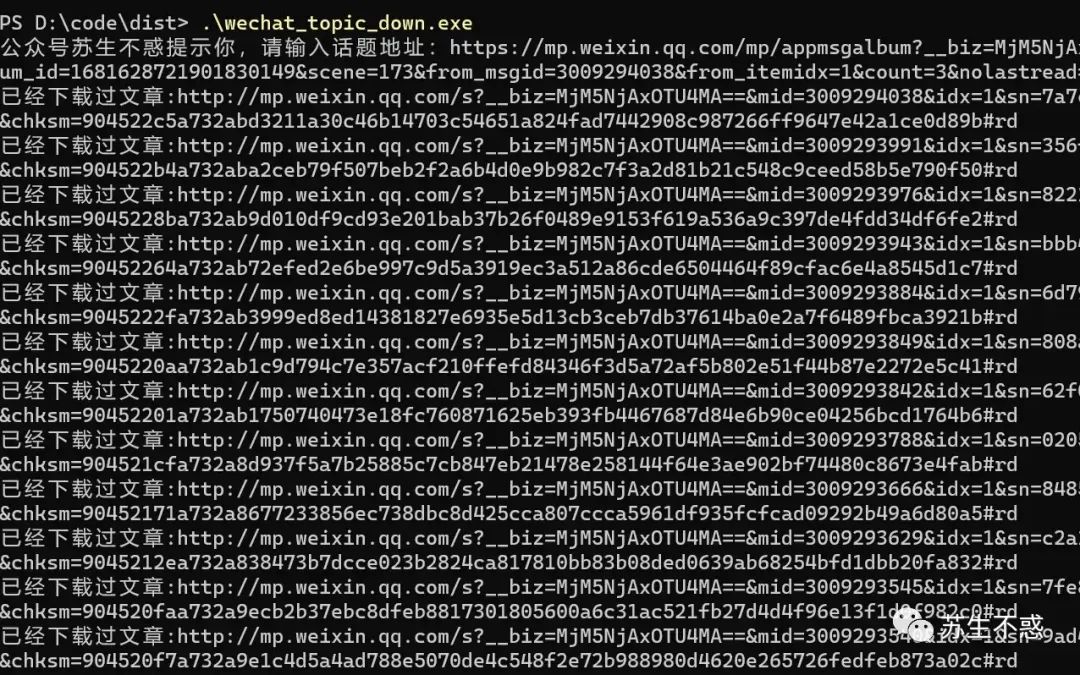
纯音频话题也支持: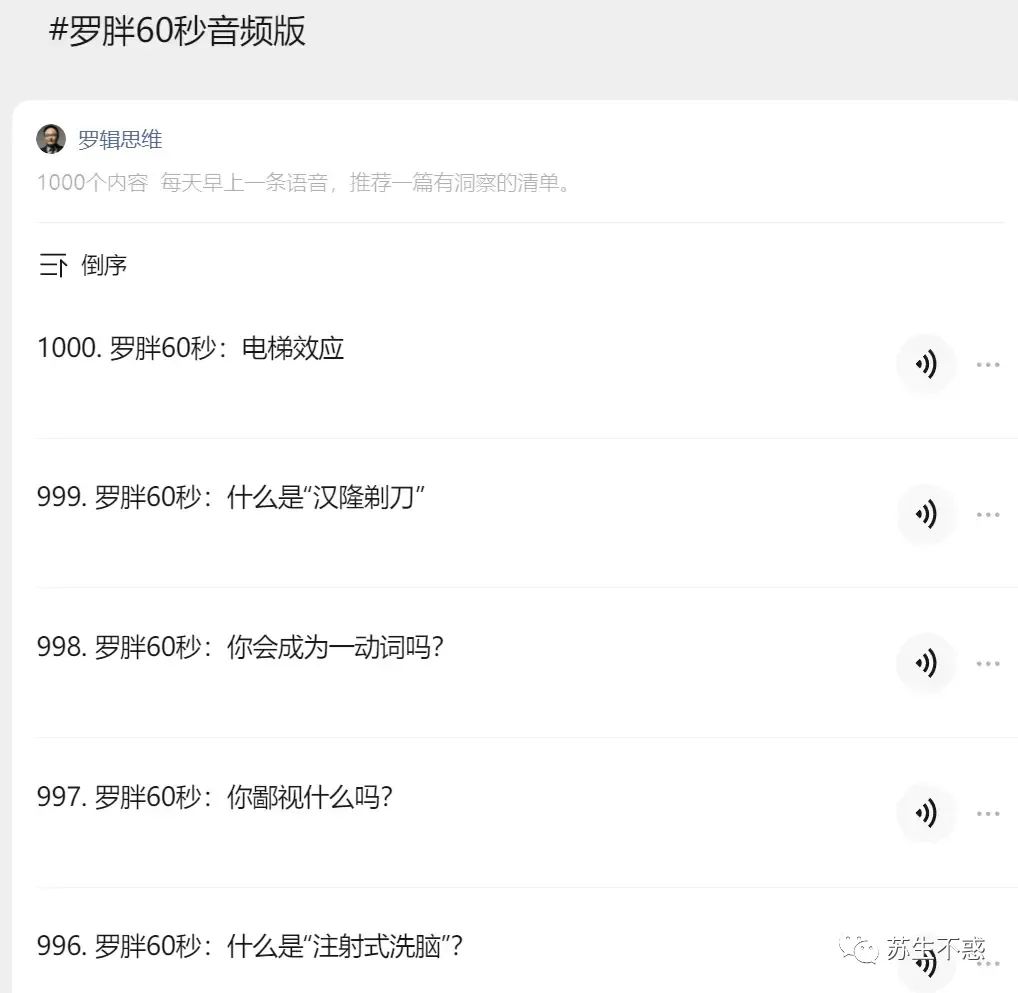
1000个音频很快就下载完了。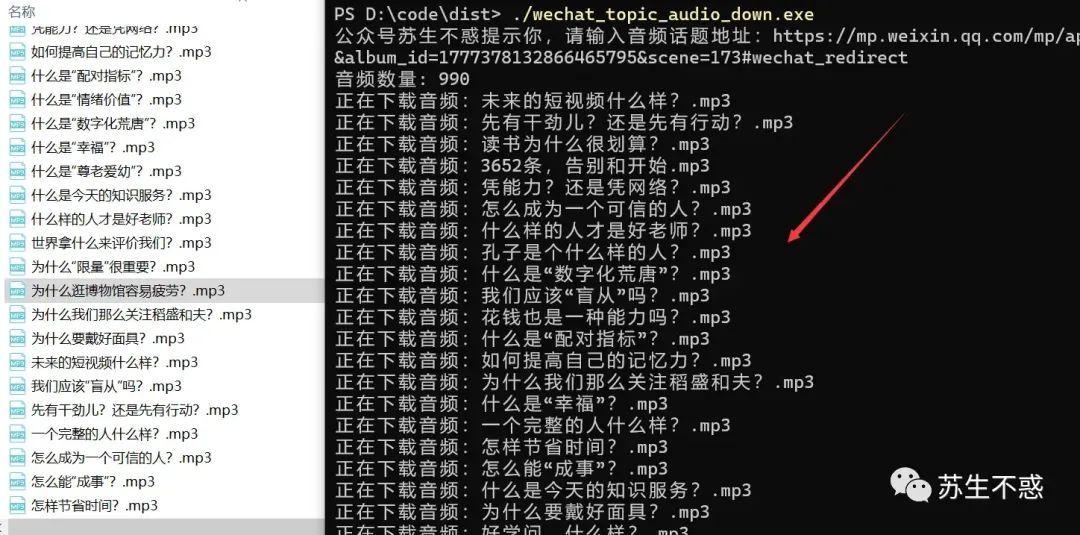
下载过的音频保存在文件wechat_topic_audio_list.txt ,如果第2次下载也会跳过已经下载过的音频,效果: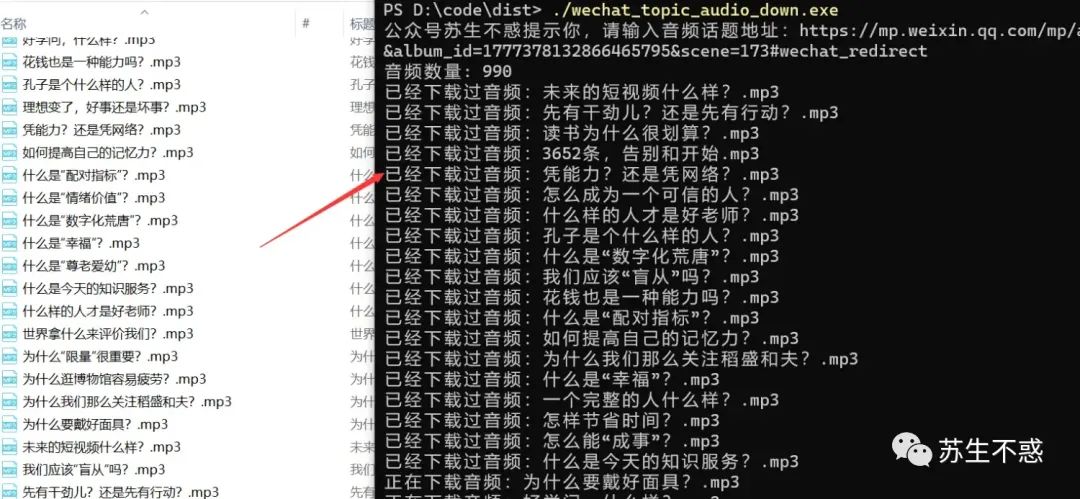
公众号模板文章/音频/视频下载
还是在公众号苏生不惑后台回复 公众号 获取工具下载地址,以支付宝这个模板页面为例: 打开wechat_homepage.exe输入地址,下载效果:
打开wechat_homepage.exe输入地址,下载效果: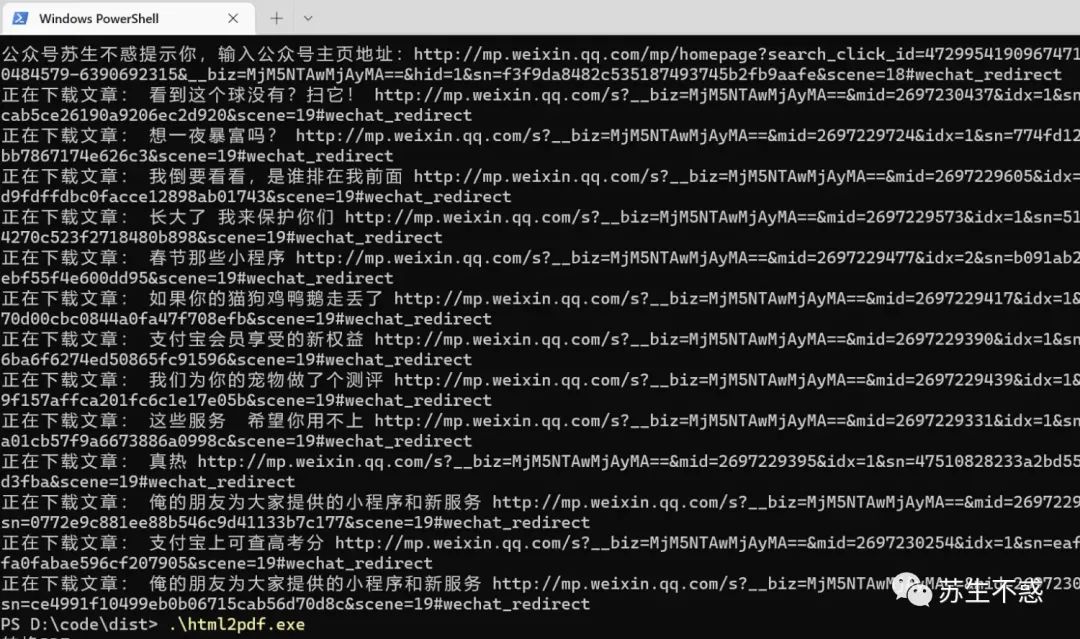
 还生成了一个文章列表excel文件,包含文章日期,文章标题,文章链接和文章封面。
还生成了一个文章列表excel文件,包含文章日期,文章标题,文章链接和文章封面。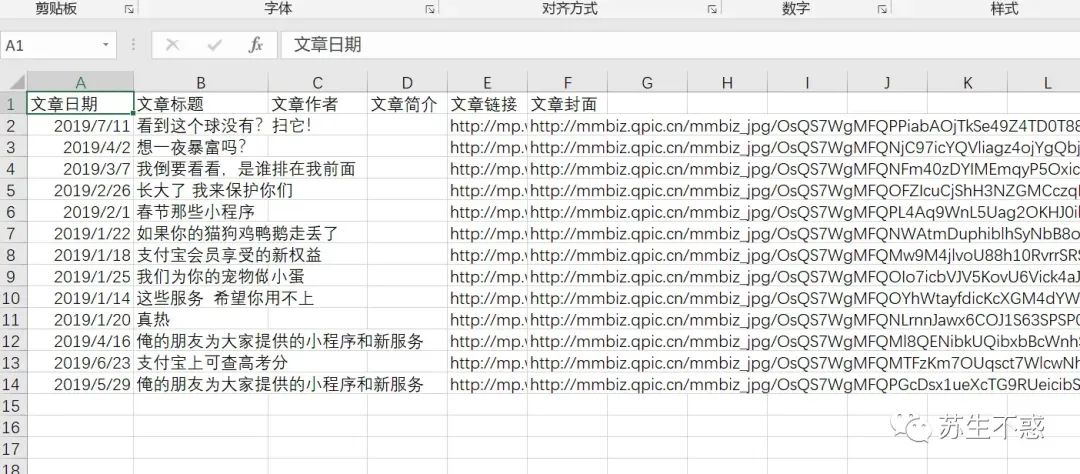 第2次下载会跳过已经下载过的文章:
第2次下载会跳过已经下载过的文章: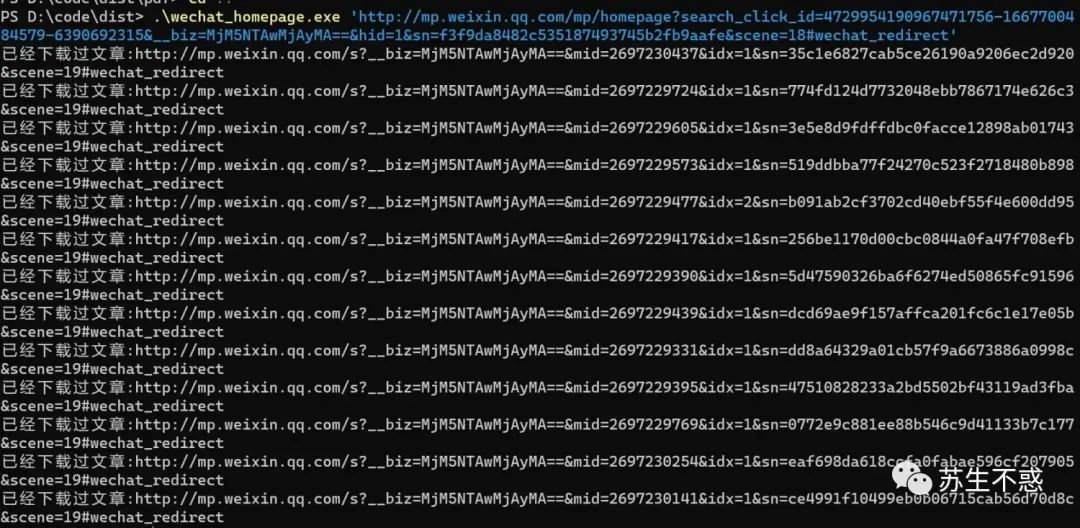
html和pdf转换
上面的工具只下载了文章html,如果想转pdf用我开发的html2pdf.exe可以将html批量转换为pdf,先打开https://wkhtmltopdf.org/downloads.html 下载安装再添加到环境变量,运行html2pdf.exe就可以了,批量转换后的pdf文件保存在pdf目录。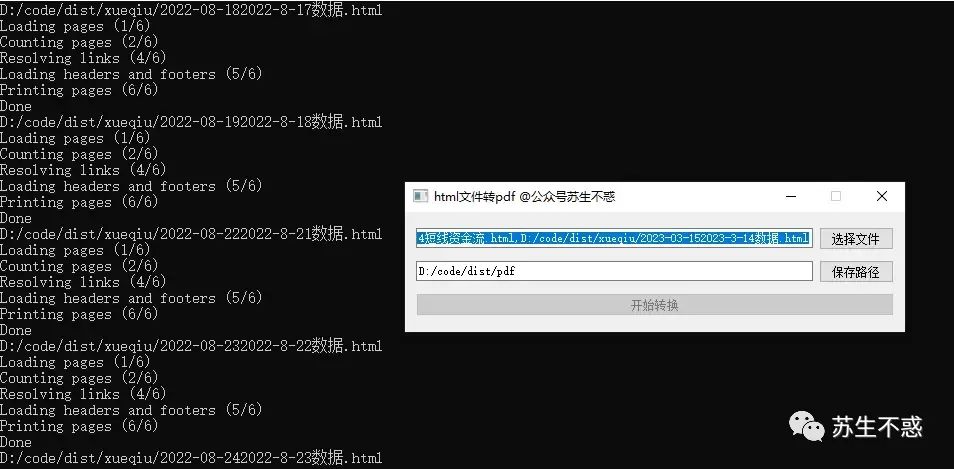 不过现在公众号网页改为动态加载,用这个转换生成的pdf是空白的
不过现在公众号网页改为动态加载,用这个转换生成的pdf是空白的wkhtmltopdf.exe https://mp.weixin.qq.com/s/c-jpCXxUtZpzxTCSx0Fu_w 视频更新版:批量下载公众号文章内容/话题/图片/封面/音频/视频,导出html,pdf,excel包含阅读数/点赞数/留言数.pdf转换生成的pdf是空白的,所以之前我用python写的html2pdf.exe也失效了。
现在是用pyppeteer 转换,不过它依赖chromium:
import pyppeteer.chromium_downloader
print('默认版本:{}'.format(pyppeteer.__chromium_revision__))
print('可执行文件默认路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64')))
print('win64平台下载链接为:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))在可执行文件默认路径新建目录588429,手动下载输出的chrome-win32.zip解压后放进去。
可执行文件默认路径:C:\Users\xxx\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429\chrome-win32\chrome.exe
win64平台下载链接为:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip写代码转换效果如图,速度比较慢,暂时没什么好办法: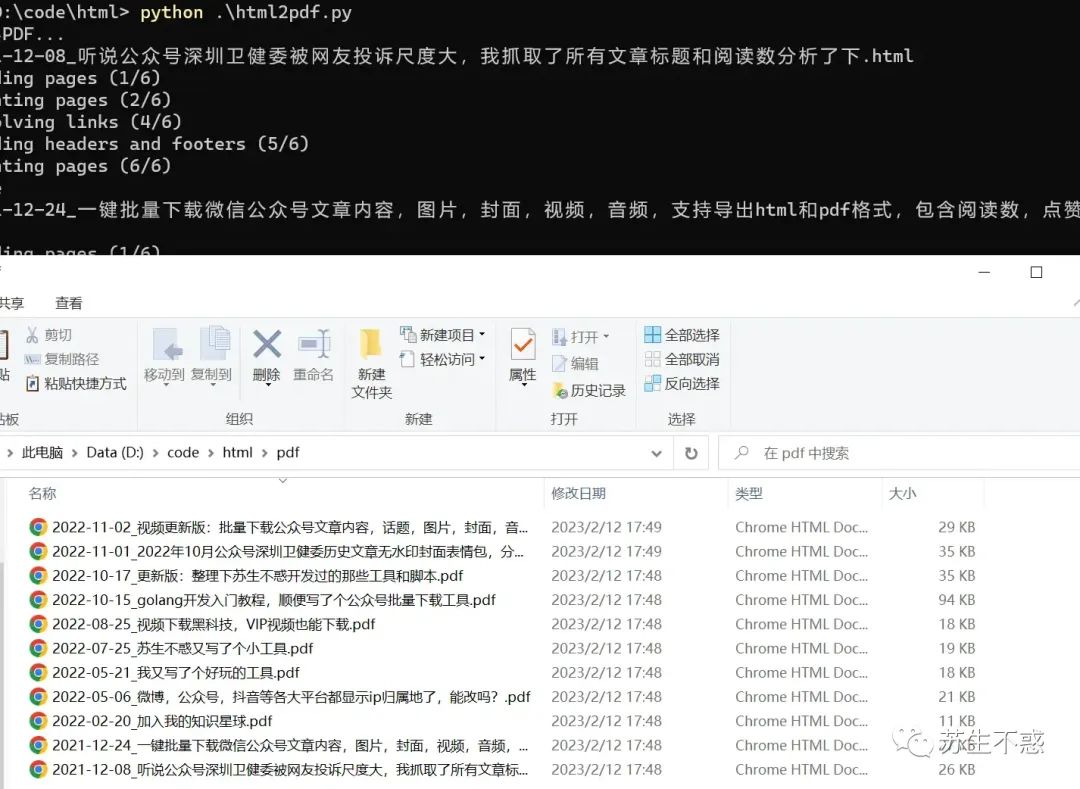
转换后的pdf就可以用我开发的这个pdf_merge.exe合成一个pdf文件苏生不惑又写了个pdf合并带书签小工具 ,效果: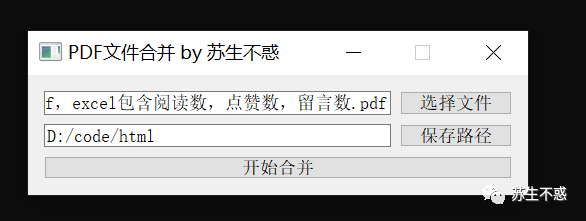
合成的pdf文件带书签,点击会跳转对应文章。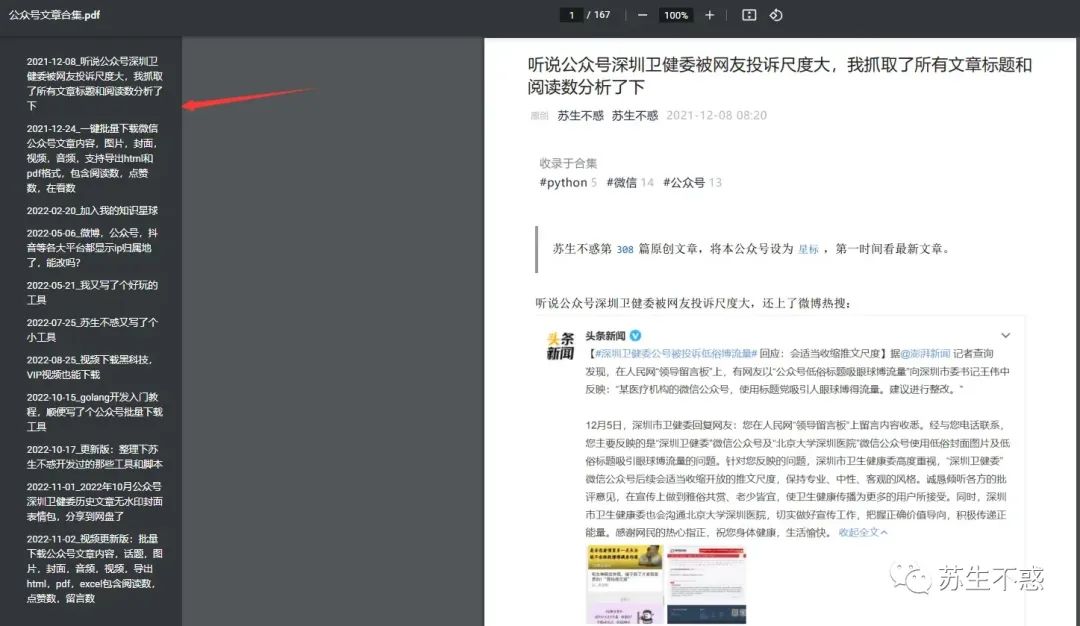
批量下载公众号历史文章内容和数据
上面的工具只能下载部分文章,为了下载一个号的所有文章,我写了个脚本批量下载某个公众号的所有历史文章批量下载公众号文章内容/话题/图片/封面/音频/视频,导出html,pdf,excel包含阅读数/点赞数/在看数/留言数/赞赏数 ,下载效果如图: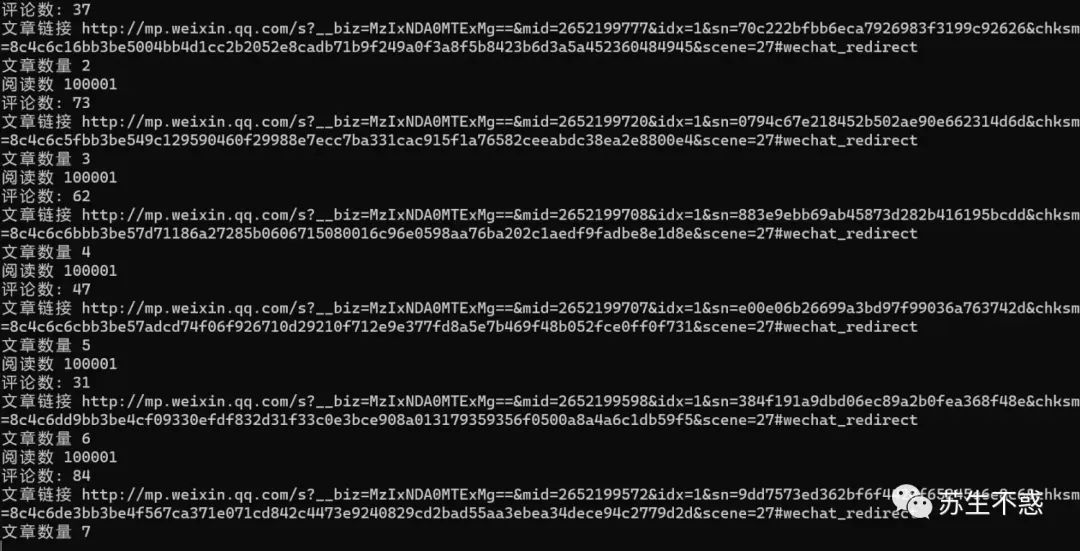 下载的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,IP归属地,阅读数,在看数,点赞数,留言数,赞赏次数,视频数,音频数等,比如深圳卫健委2022年的1000多篇文章阅读数都是10万+,excel数据分析见这篇文章2022年过去,抓取公众号阅读数点赞数在看数留言数做数据分析, 以深圳卫健委这个号为例 。
下载的excel文章数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,IP归属地,阅读数,在看数,点赞数,留言数,赞赏次数,视频数,音频数等,比如深圳卫健委2022年的1000多篇文章阅读数都是10万+,excel数据分析见这篇文章2022年过去,抓取公众号阅读数点赞数在看数留言数做数据分析, 以深圳卫健委这个号为例 。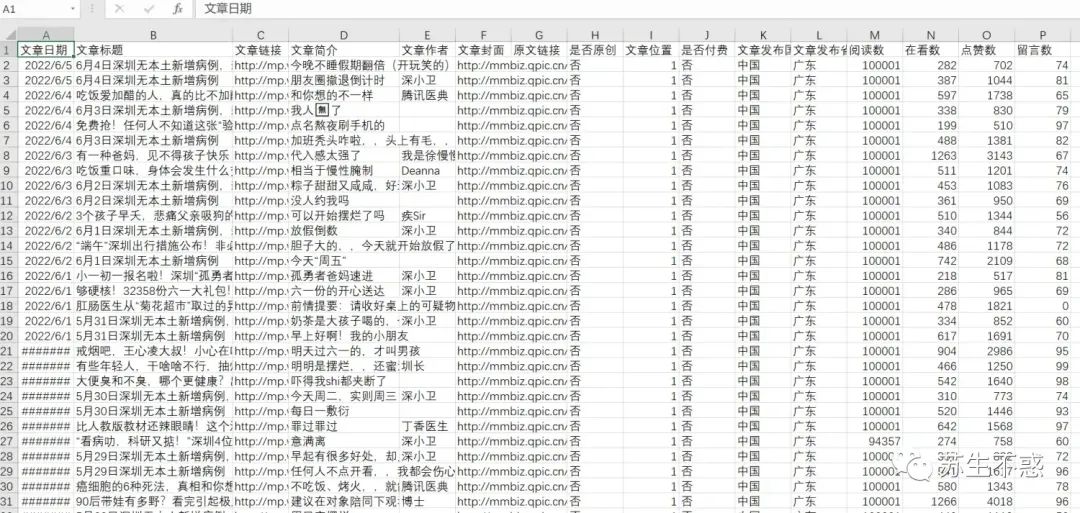
为了方便找文章,部分公众号的历史文章同步到了我的博客https://sushengbuhuo.github.io/blog ,会持续更新,不用在手机上下拉翻历史文章了 ,比如深圳卫健委从2014到2023发布了1万多篇文章,第一篇文章是这个: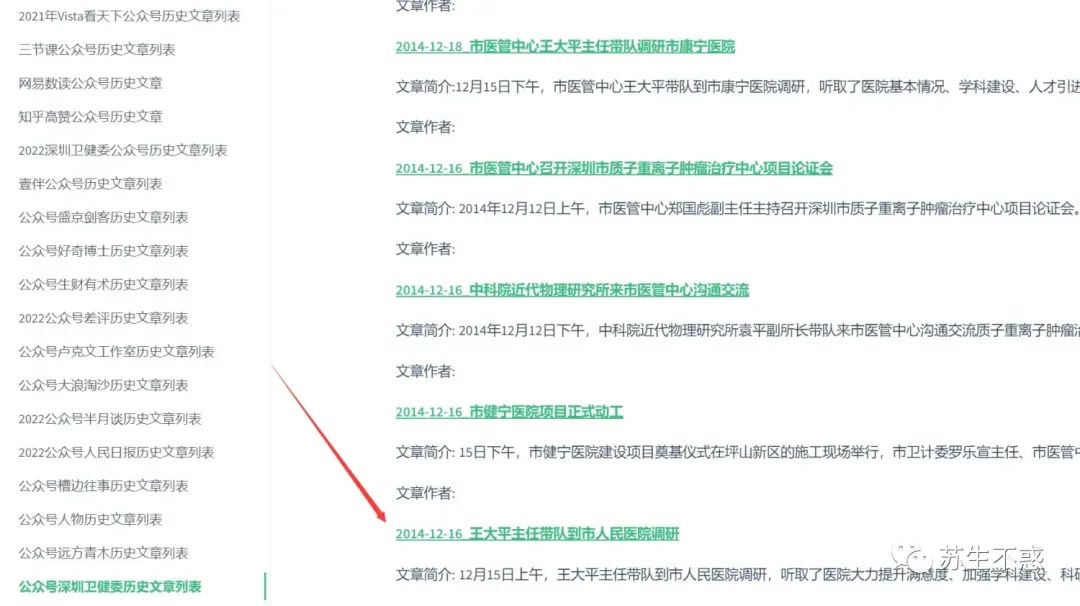
另外每个月我还会更新一次公众号深圳卫健委的封面表情包图,无水印,欢迎收藏 2022 年公众号深圳卫健委所有历史文章无水印封面表情包合集,分享到网盘了,所有封面图的文件名为文章发布日期加标题,方便搜索,在公众号苏生不惑后台回复 封面 获取这个号2019-2022年的所有封面图,2023年结束的时候我再下载2023封面图。 每篇文章下的留言内容也可以单独导出excel,包含文章日期,文章标题文章链接,留言昵称,留言内容,点赞数,回复和留言时间,比如深圳卫健委在2月份就有1万6千多条留言,如果你有需要下载的公众号或抓取数据可以微信sushengbuhuo联系我。
每篇文章下的留言内容也可以单独导出excel,包含文章日期,文章标题文章链接,留言昵称,留言内容,点赞数,回复和留言时间,比如深圳卫健委在2月份就有1万6千多条留言,如果你有需要下载的公众号或抓取数据可以微信sushengbuhuo联系我。
顺便分析下留言区的ip归属地,我的公众号留言区广东的小伙伴最多微博/公众号/抖音等各大平台都显示 ip 归属地了,能改吗?
import requests,re,csv,time,random,pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Pie
import pandas as pd
wechat=pd.read_csv('2023公众号苏生不惑留言数据.csv',encoding='utf-8')
#print(wechat.留言昵称.value_counts().sort_values(ascending=False).head(10))
def data(df):
df2=df.省份.value_counts().sort_values(ascending=False).head(10)
ip = df2.index.tolist()
counts = df2.values.tolist()
bar = (
Bar()
.add_xaxis(ip)
.add_yaxis("", counts)
)
pie = (
Pie()
.add("", [list(z) for z in zip(ip, counts)],radius=["40%", "75%"], )
.set_global_opts(title_opts=opts.TitleOpts(title="饼图",pos_left="center",pos_top="20"))
.set_global_opts(legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"), )
)
pie.render('统计数据.html')
data(wechat)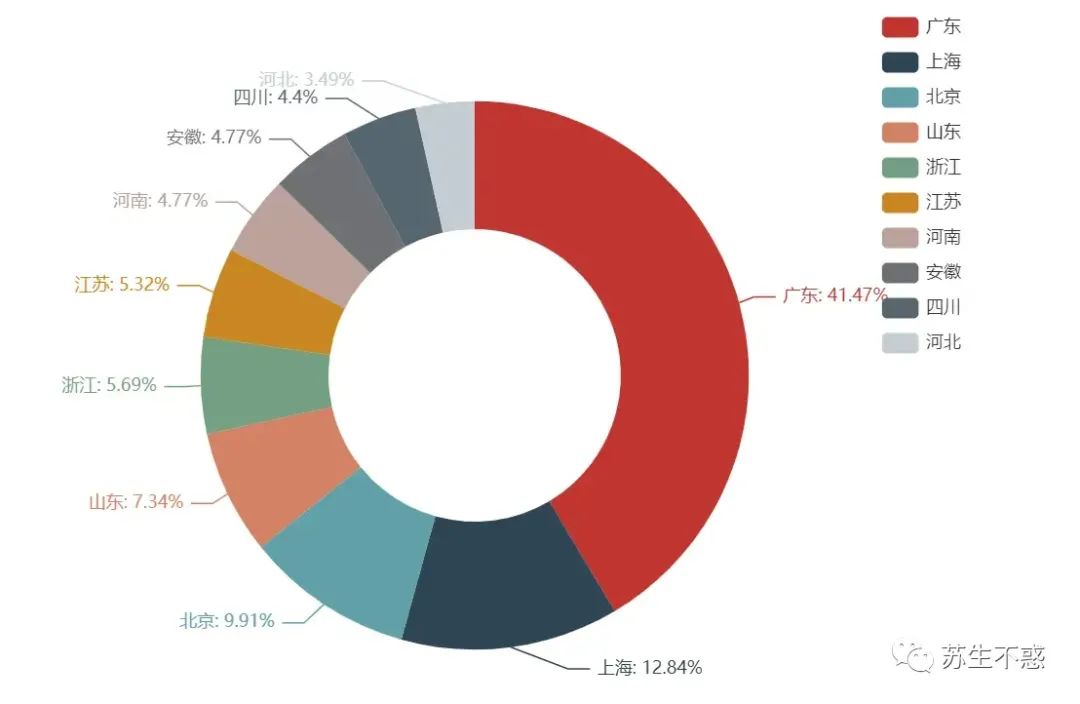
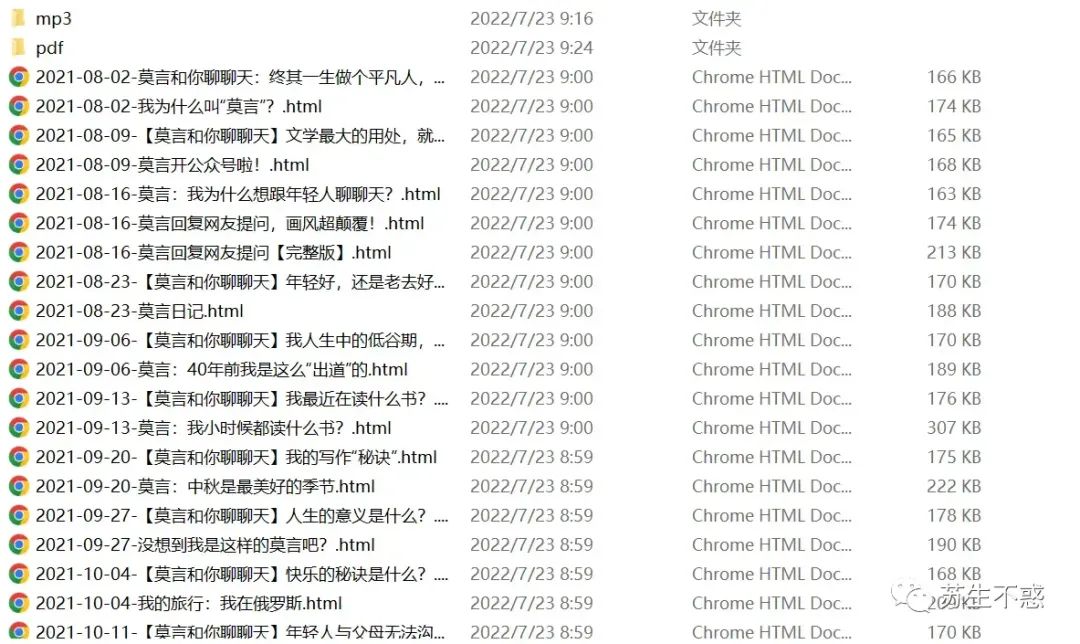
下载所有文章以莫言老师的公众号为例,包括文章内容(含留言),音频和视频 :
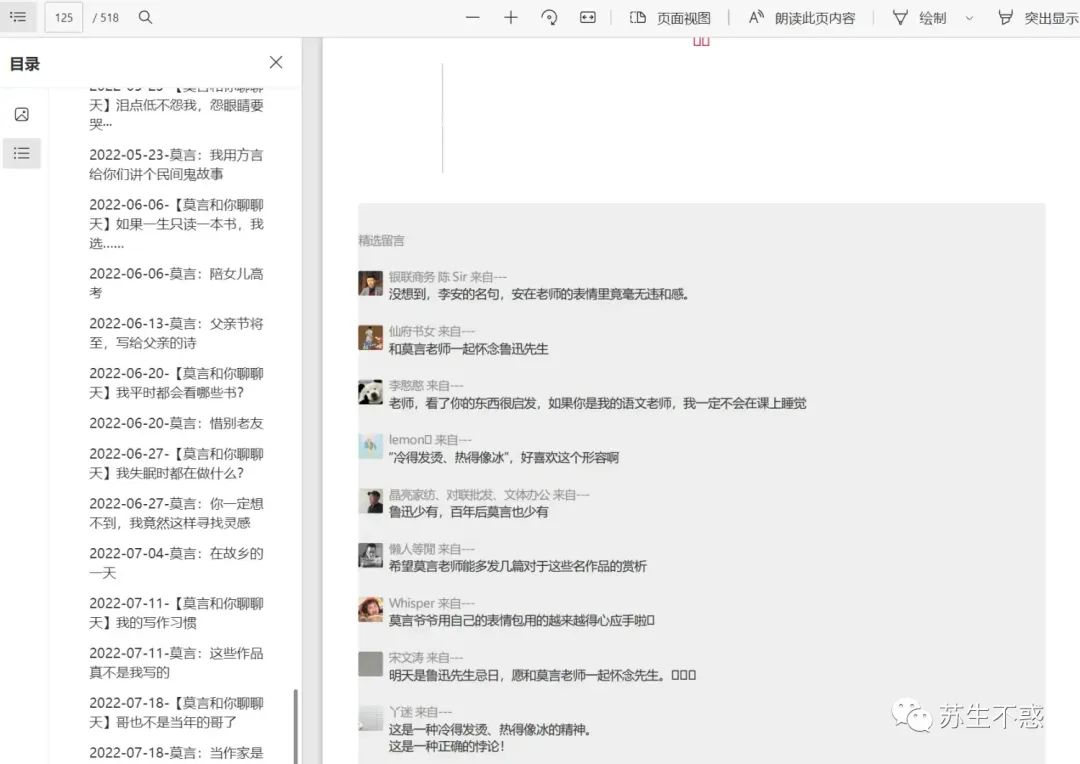
最后将所有文章合并成一个pdf文件(含留言),点击左侧书签跳转到对应文章,在电脑和手机上看方便多了: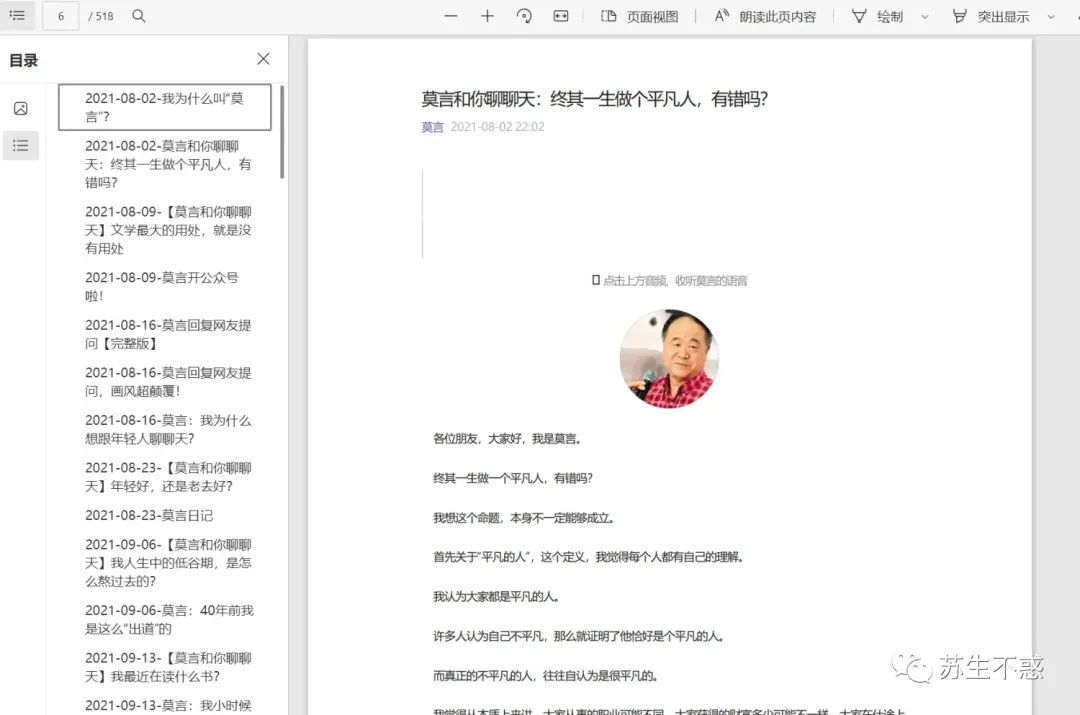
 知乎专栏下载
知乎专栏下载
工具下载地址在公众号苏生不惑后台回复 知乎,输入知乎专栏id即可批量下载知乎专栏所有文章为pdf 这个元宵节,苏生不惑又更新了下知乎专栏文章下载脚本,比如这个专栏 https://www.zhihu.com/column/c_1492085411900530689 ,下载效果: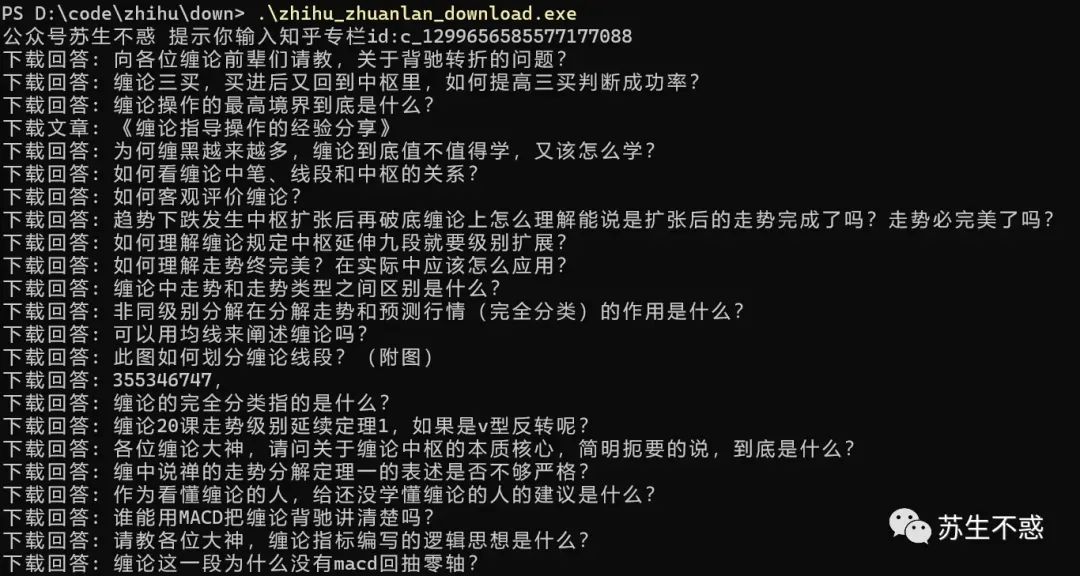 文章和回答保存到html目录,文件名是时间+标题。
文章和回答保存到html目录,文件名是时间+标题。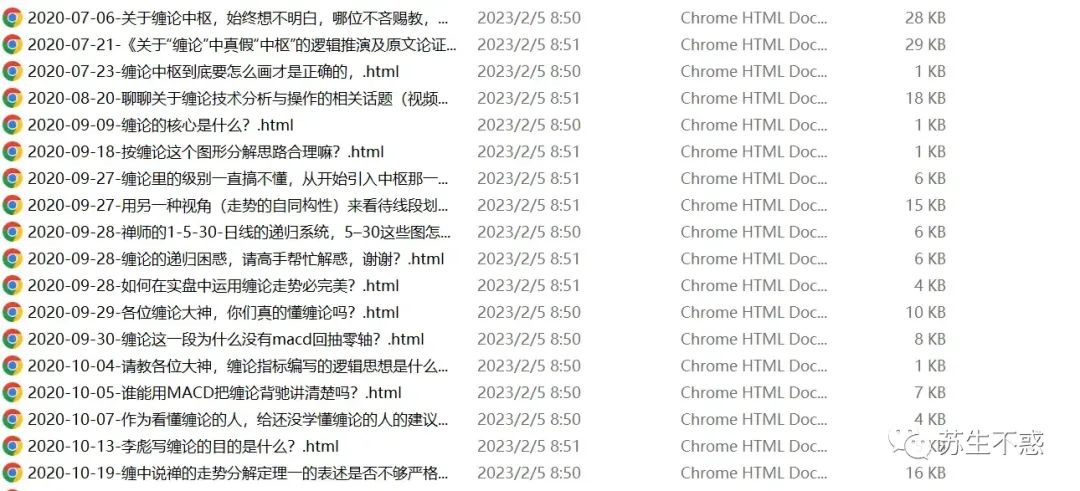 所有文章合成一个pdf文件。
所有文章合成一个pdf文件。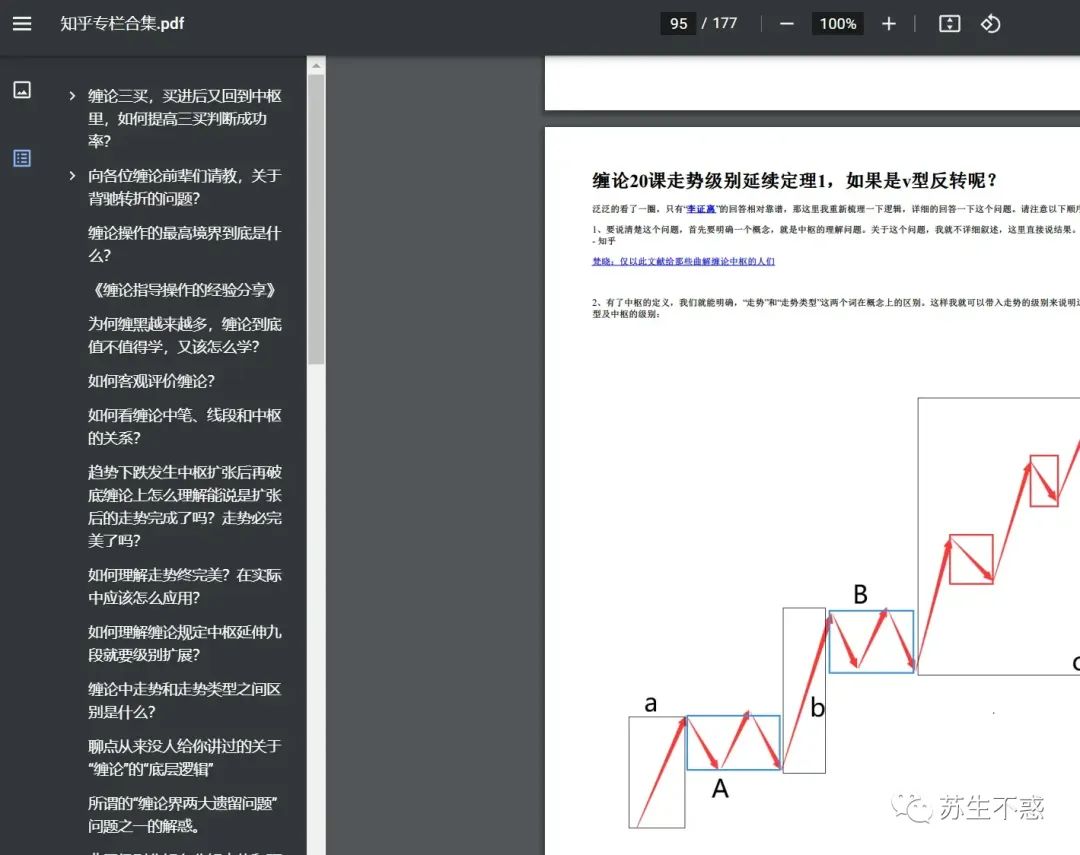 视频保存到video目录。
视频保存到video目录。
微博内容/图片/视频/评论下载
工具下载地址在公众号后台对话框回复 微博,打开工具输入微博uid 一键批量下微博内容/图片/视频,获取博主最受欢迎微博,图片查找微博博主 ,是否下载图片和视频,1为是,0为否,如果想全部下载时间就输入2010-01-01。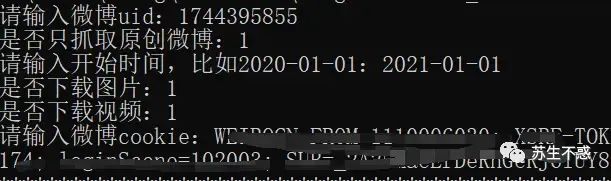
cookie需要登陆网页版微博 https://m.weibo.cn/ 在控制台获取。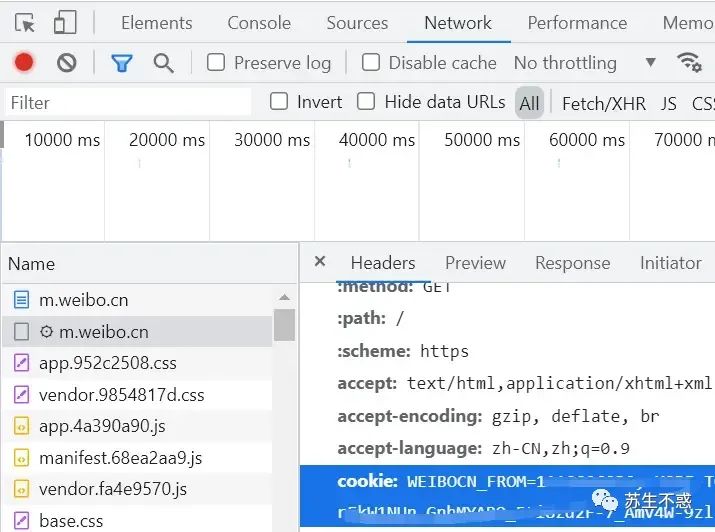 我录制了个视频国庆节假期学了2个新东西,分享下我的学习成果
我录制了个视频国庆节假期学了2个新东西,分享下我的学习成果
下载效果 微博图床又搞事情不能用了,盘它,我顺便写了个微博图片/视频/内容/文章批量下载工具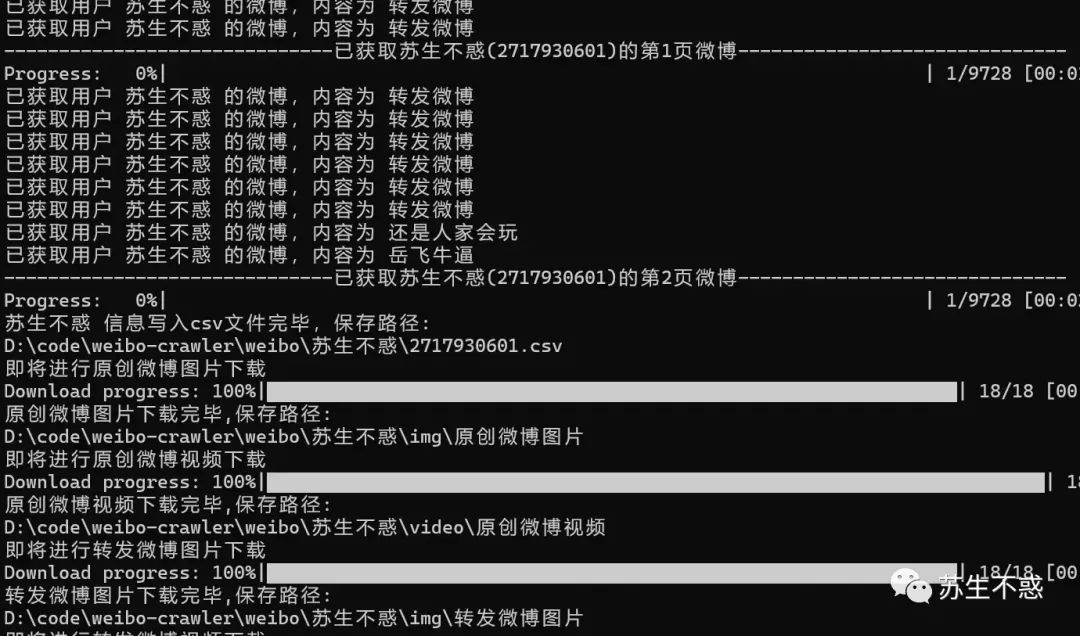 下载的图片和视频如图,图片为高清大图,视频也是高清。
下载的图片和视频如图,图片为高清大图,视频也是高清。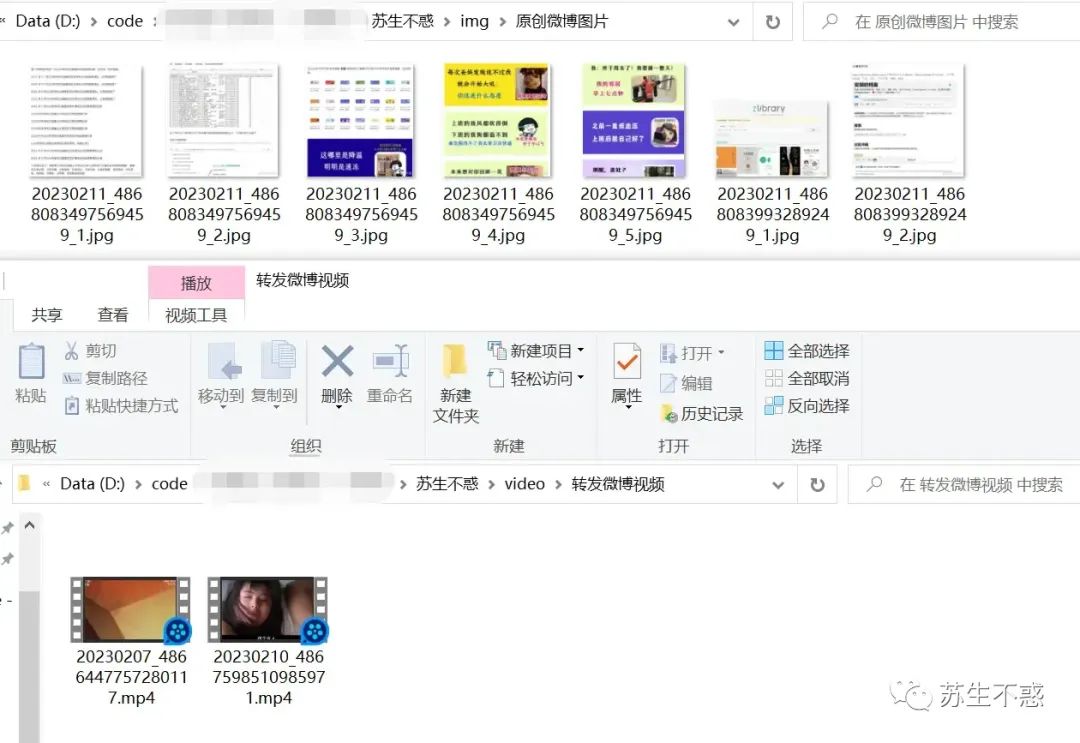
下载的微博评论点赞转发数据和图片视频保存在weibo目录,下载的所有微博图片: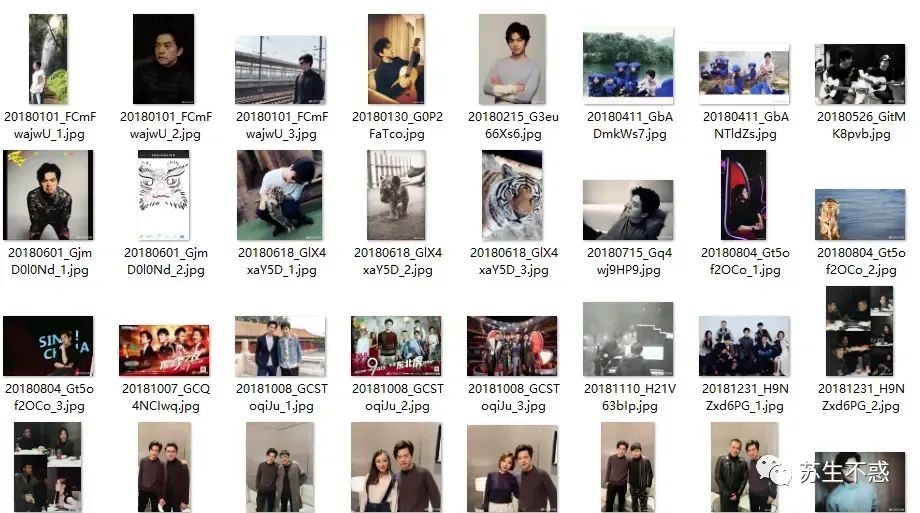 下载的所有微博视频:
下载的所有微博视频: 导出的微博数据excel文件包含微博地址,微博内容,头条文章地址,图片地址,视频地址,发布时间,点赞数,评论数,转发数,阅读数,发布地区,是否原创,其中阅读数只有下载自己的号才有。
导出的微博数据excel文件包含微博地址,微博内容,头条文章地址,图片地址,视频地址,发布时间,点赞数,评论数,转发数,阅读数,发布地区,是否原创,其中阅读数只有下载自己的号才有。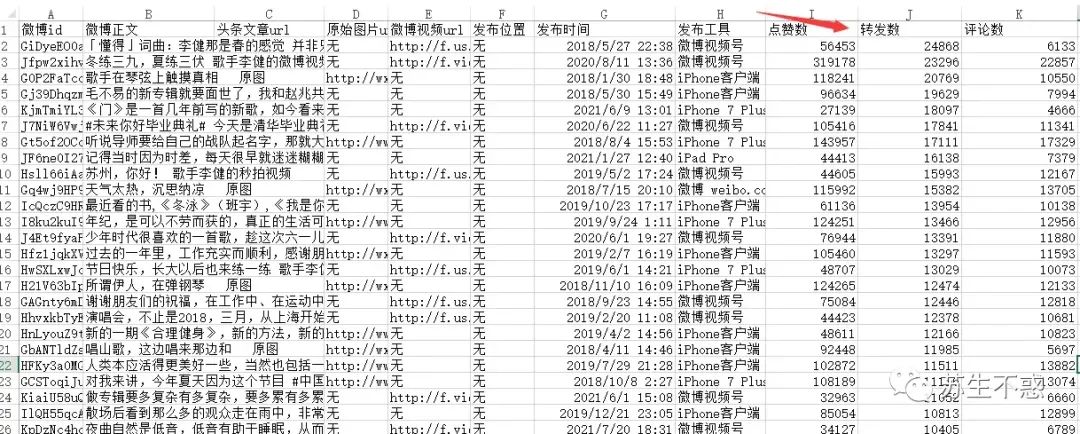
顺便分析单条微博评论区数据及IP归属地分析一键批量下载微博评论数据,并分析ip归属地分布: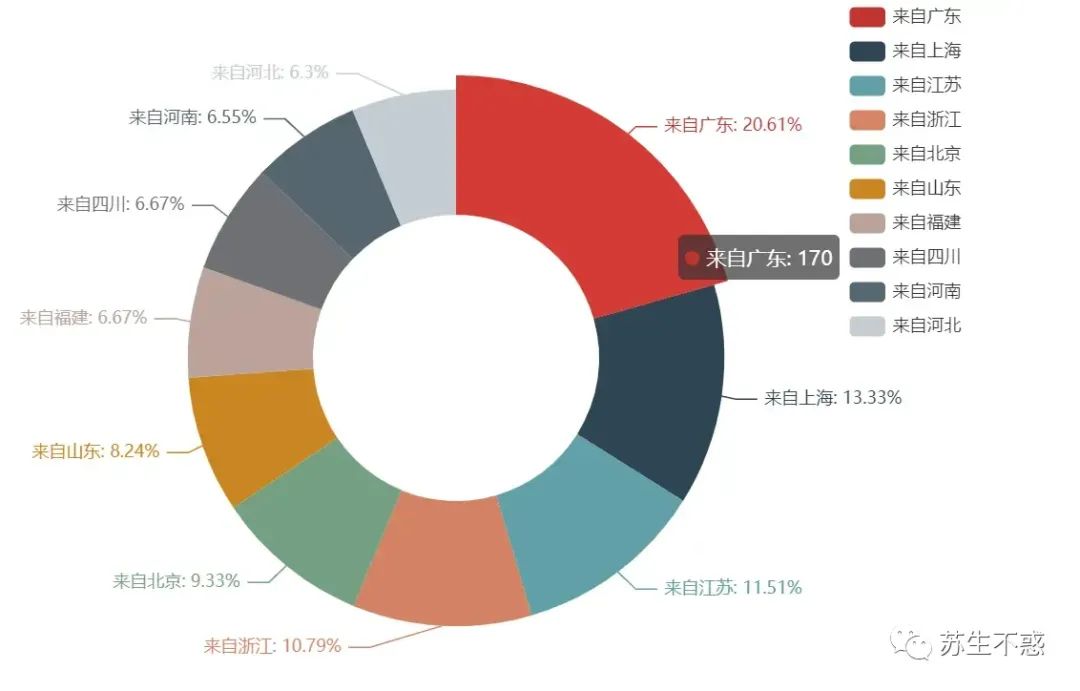 如果还想下载所有微博文章先用这个工具导出所有微博文章链接, 工具发布到我的知识星球了加入我的知识星球 :
如果还想下载所有微博文章先用这个工具导出所有微博文章链接, 工具发布到我的知识星球了加入我的知识星球 :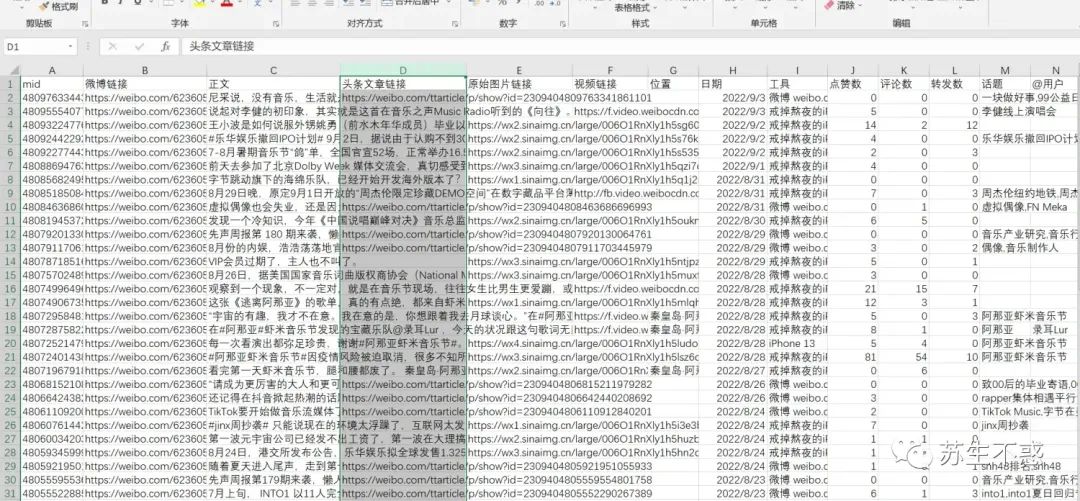 然后将excel里的微博头条文章链接下载为html,代码如下:
然后将excel里的微博头条文章链接下载为html,代码如下:
df = pandas.read_csv(f'{uid}.csv',encoding='utf_8_sig')
df = df[df['头条文章链接'].notnull()]
urls=df.头条文章链接.tolist()
# urls=[urls[0]]
for url in urls:
try:
res=requests.get(url,headers=headers, verify=False)
title = re.search(r'<title>(.*?)</title>',res.text).group(1)
weibo_time = re.search(r'<span class="time".*?>(.*?)</span>',res.text).group(1)
if not weibo_time.startswith('20'):
weibo_time=time.strftime('%Y')+'-'+weibo_time.strip().split(' ')[0]
with open('articles/'+weibo_time+'_'+trimName(title)+'.html', 'w+', encoding='utf-8') as f:
f.write(res.text.replace('"//','https://'))
print('下载微博文章',url)
except Exception as e:
print('错误信息',e,url)下载效果如图: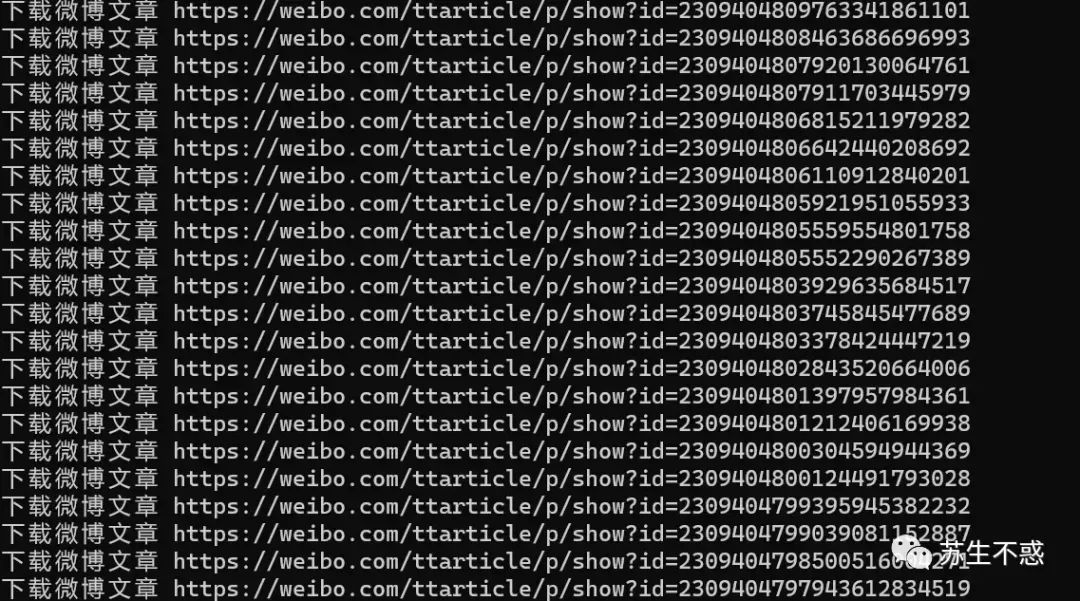 最后转换pdf并合成一个pdf文件,文章发布时间和标题作为书签。
最后转换pdf并合成一个pdf文件,文章发布时间和标题作为书签。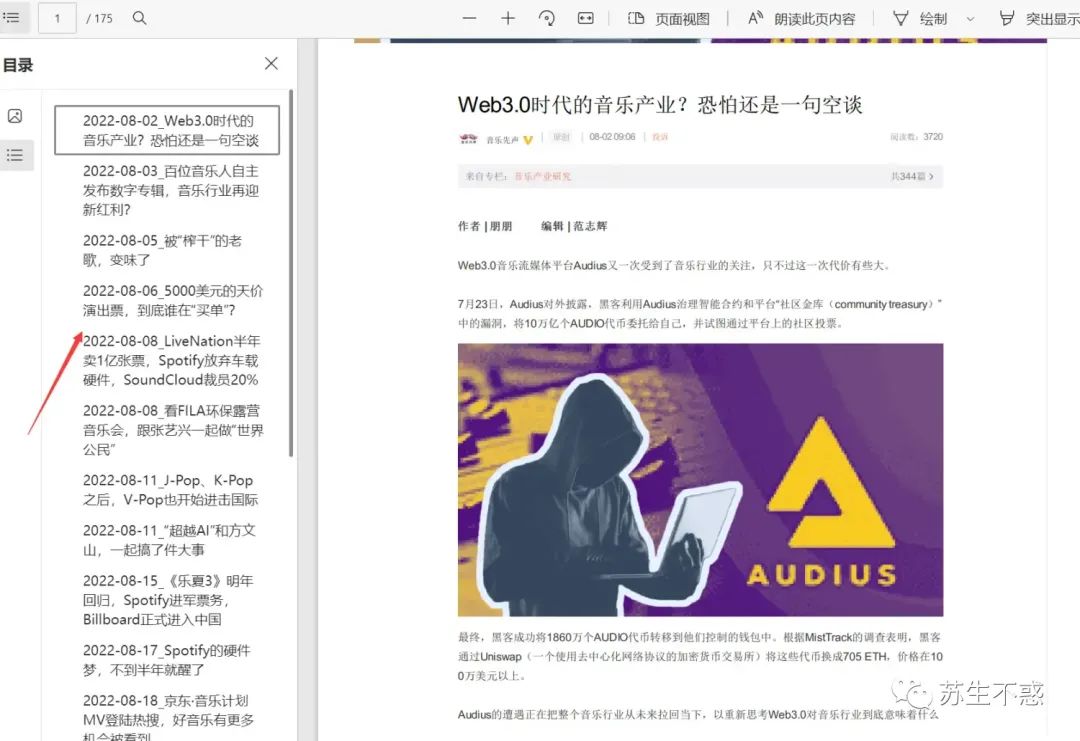
雪球文章批量下载
工具下载地址在公众号苏生不惑后台回复雪球 2023 年苏生不惑开发的第 1 个工具:雪球批量下载,打开软件提示输入雪球主页地址和浏览器cookie,比如爱在冰川这个号 https://xueqiu.com/u/4104161666,cookie 在浏览器控制台获取: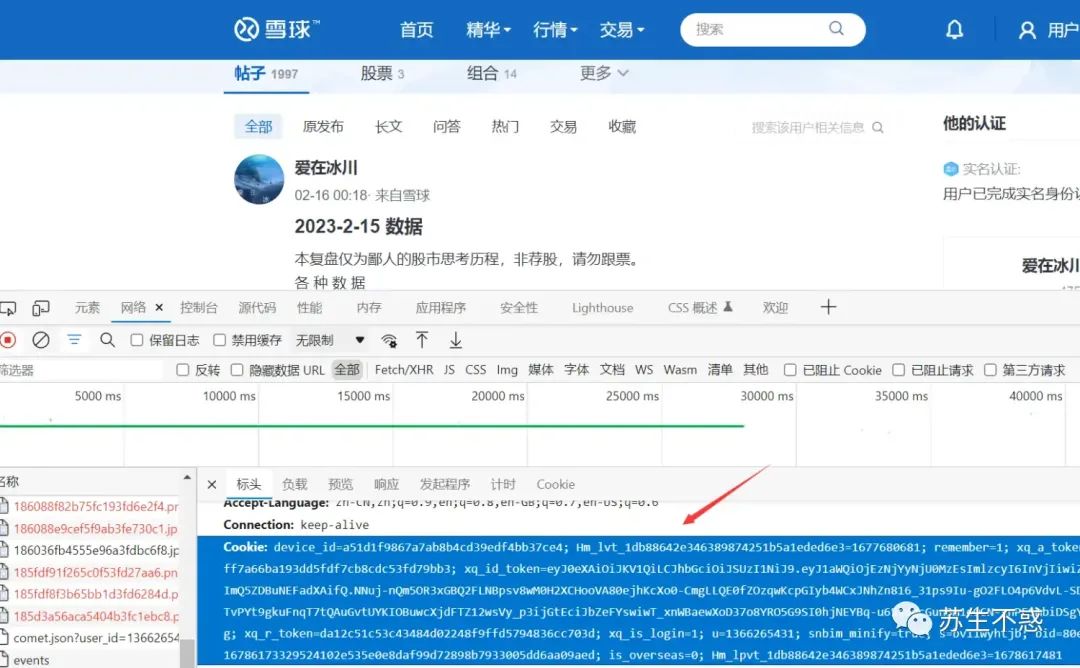 下载效果如图:
下载效果如图: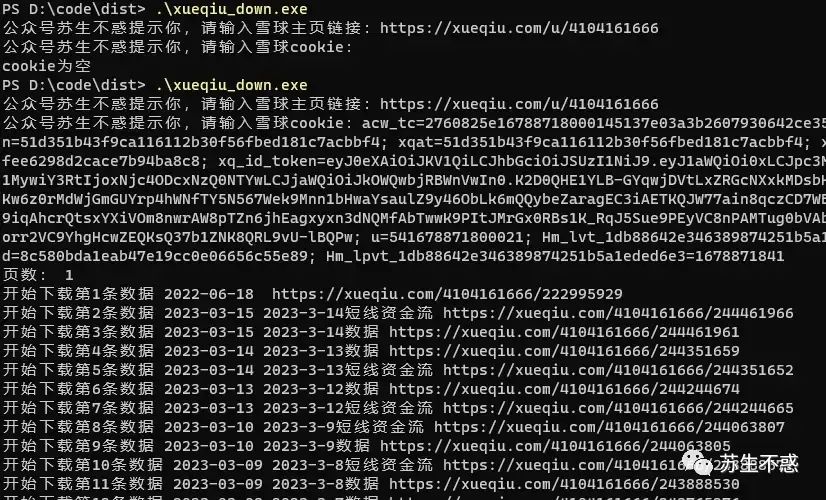
下载的文章html: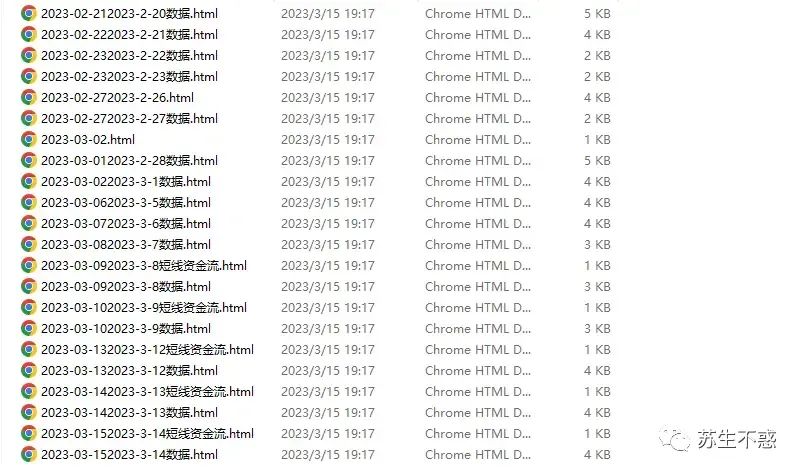 以及文章数据excel,包含文章日期,文章标题,文章链接,文章简介,点赞数,转发数,评论数:
以及文章数据excel,包含文章日期,文章标题,文章链接,文章简介,点赞数,转发数,评论数: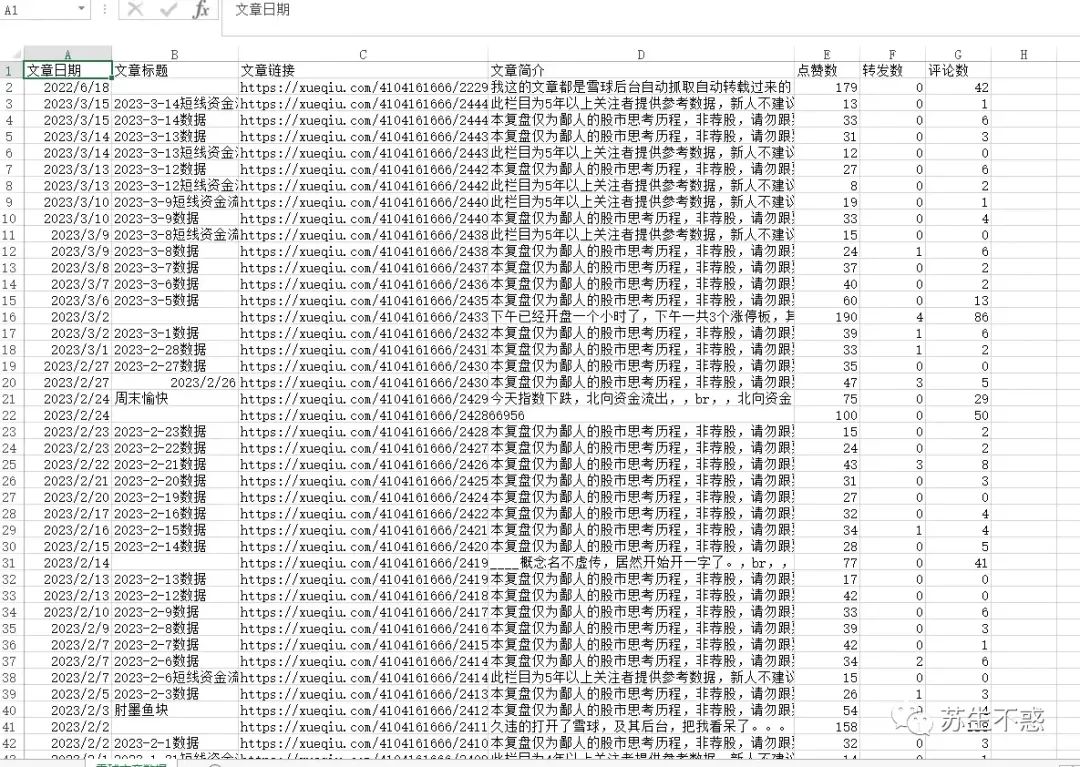
接着用我开发的这个工具将html批量转pdf ,由于工具依赖wkhtmltopdf,需要先下载安装这个 https://wkhtmltopdf.org/downloads.html 加入环境变量。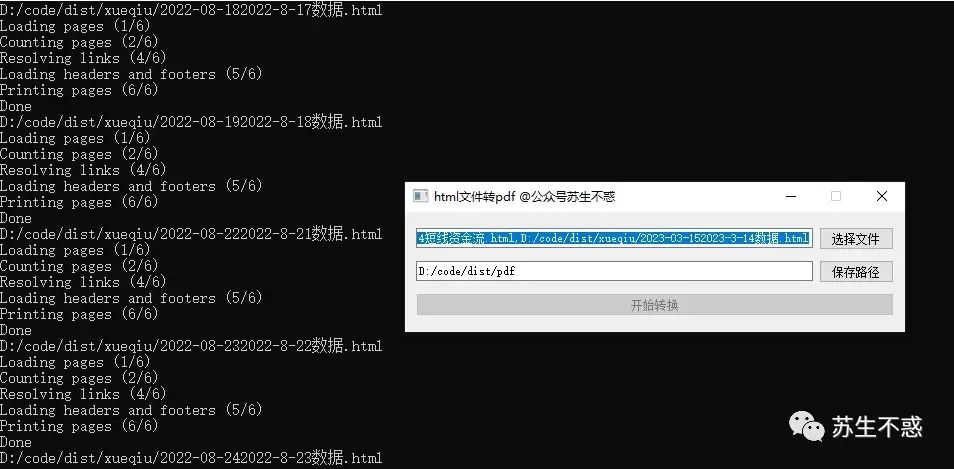 转换后的pdf:
转换后的pdf: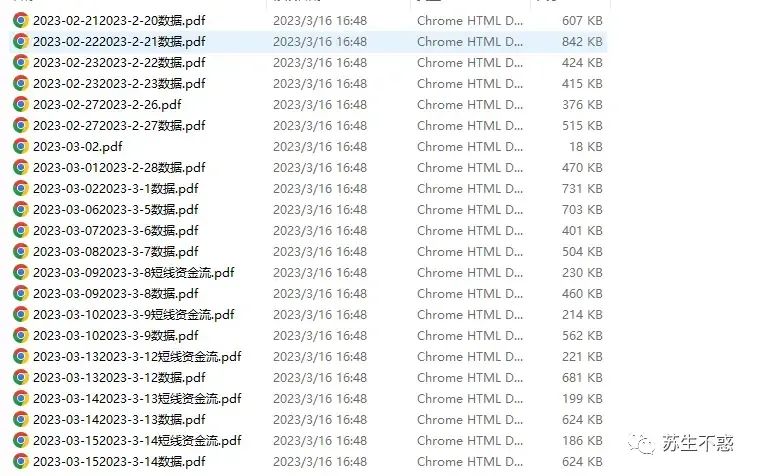
webscraper 数据抓取
webscraper 是个数据抓取神器扩展,如果你不会代码可以用它来抓取网站数据,我之前写过文章不用写代码,Chrome 扩展神器 web scraper 抓取知乎热榜/话题/回答/专栏,豆瓣电影,比如抓取b站上木鱼水心的所有视频https://space.bilibili.com/927587/video?tid=0&pn=1&keyword=&order=pubdate ,你可以直接导入我的代码抓取。
{"_id":"bilibili_videos","startUrl":["https://space.bilibili.com/927587/video?tid=0&pn=[1-42:1]&keyword=&order=pubdate"],"selectors":[{"id":"row","parentSelectors":["_root"],"type":"SelectorElement","selector":"li.small-item","multiple":true},{"id":"视频标题","parentSelectors":["row"],"type":"SelectorText","selector":"a.title","multiple":false,"regex":""},{"id":"视频链接","parentSelectors":["row"],"type":"SelectorElementAttribute","selector":"a.cover","multiple":false,"extractAttribute":"href"},{"id":"视频封面","parentSelectors":["row"],"type":"SelectorElementAttribute","selector":"a.cover div.b-img picture img","multiple":false,"extractAttribute":"src"},{"id":"视频播放量","parentSelectors":["row"],"type":"SelectorText","selector":".play span","multiple":false,"regex":""},{"id":"视频长度","parentSelectors":["row"],"type":"SelectorText","selector":" a.cover span.length","multiple":false,"regex":""},{"id":"发布时间","parentSelectors":["row"],"type":"SelectorText","selector":"span.time","multiple":false,"regex":""}]}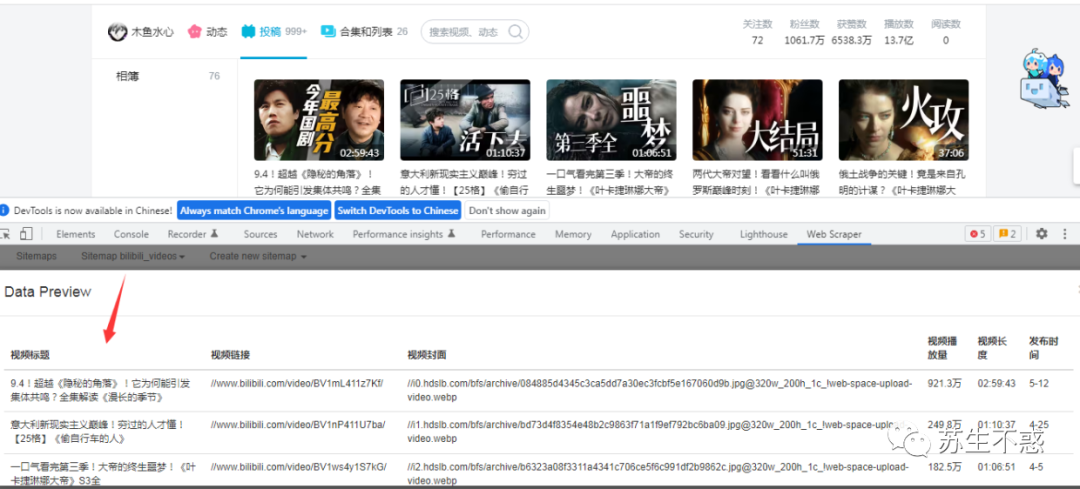
导出的excel数据包含视频标题,链接,封面,播放量,长度,时间等,从2013到2023年发布视频1200多个。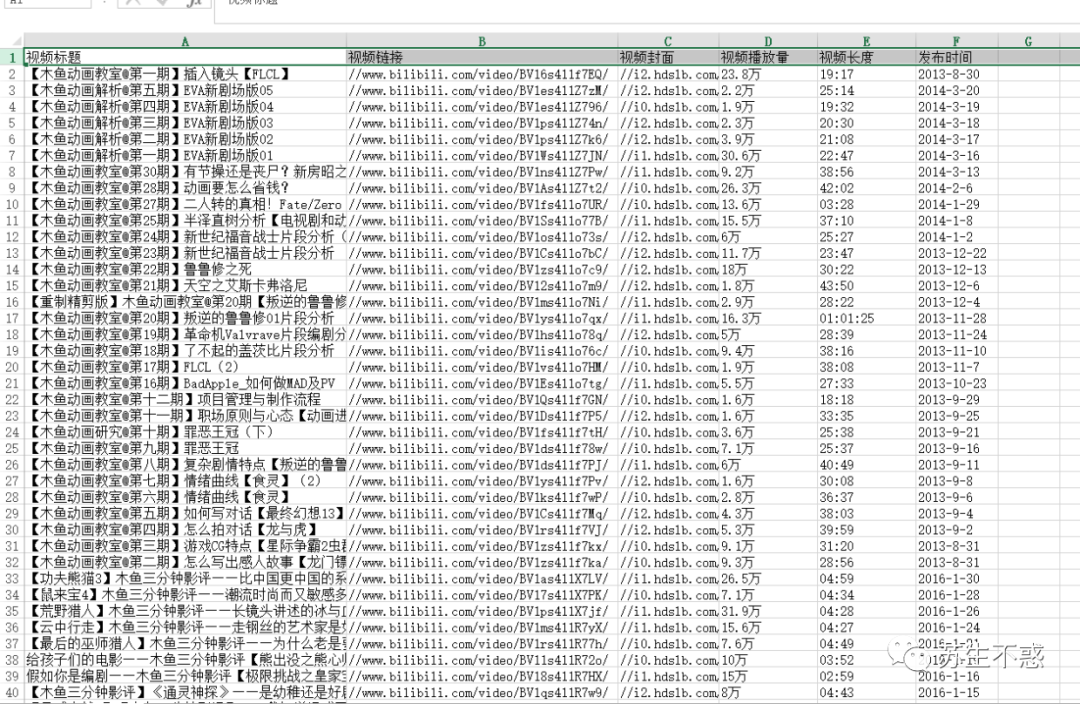 知乎回答和文章也一样,理论上能在网页上看到的数据都可以抓取,之后我会发布各大知名网站的抓取脚本。
知乎回答和文章也一样,理论上能在网页上看到的数据都可以抓取,之后我会发布各大知名网站的抓取脚本。
{"_id":"zhihu_zhuanlan","startUrl":["https://www.zhihu.com/people/zhi-shi-ku-21-42/posts?page=[1-4]"],"selectors":[{"id":"row","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":0},{"id":"知乎标题","type":"SelectorText","parentSelectors":["row"],"selector":"h2.ContentItem-title","multiple":false,"regex":"","delay":0},{"id":"知乎链接","type":"SelectorElementAttribute","parentSelectors":["row"],"selector":"h2.ContentItem-title span a ","multiple":false,"extractAttribute":"href","delay":0}]}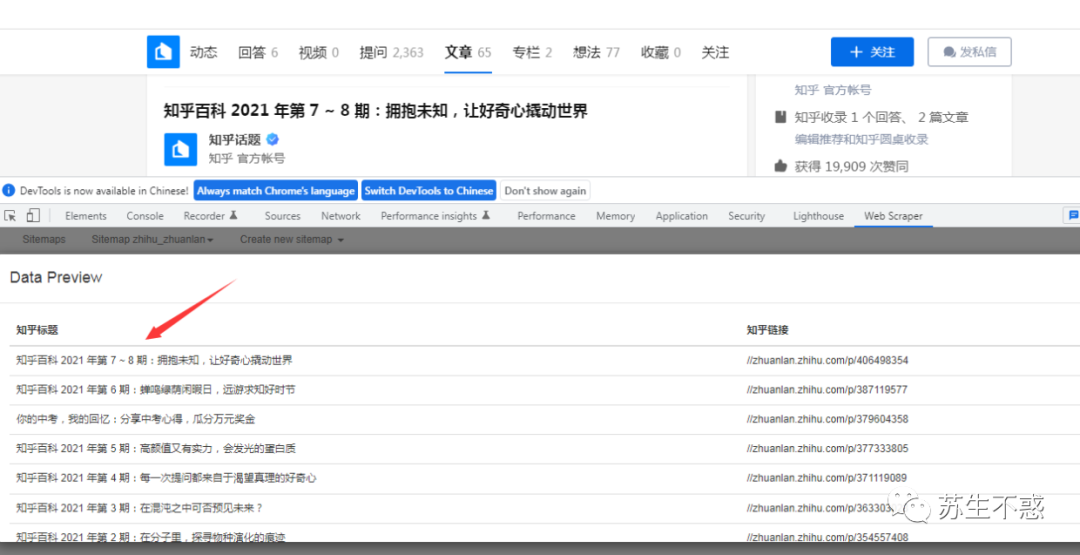
如果文章对你有帮助还请
点赞/在看/分享三连支持下, 感谢各位!
公众号苏生不惑