在讲gcc/g++使用之前我们先讲一下背景,编译链接
编译链接我们之前讲过一次,但是这里在深入理解一下编译链接,以及我们看一下现象
编译链接
首先,编译链接可以分为四步:
1.预处理
2.编译
3.汇编
4.链接
预处理
我们可以回忆一下之前说的预处理的作用,预处理的作用有下面几点
1.去注释
2.头文件展开
3.宏替换
4.条件编译
我们下面演示一下预处理后的程序
![]()
我们通过这条指令让code.c文件生成code.i文件,这条 指令后面会说到的,现在先看现象
头文件展开
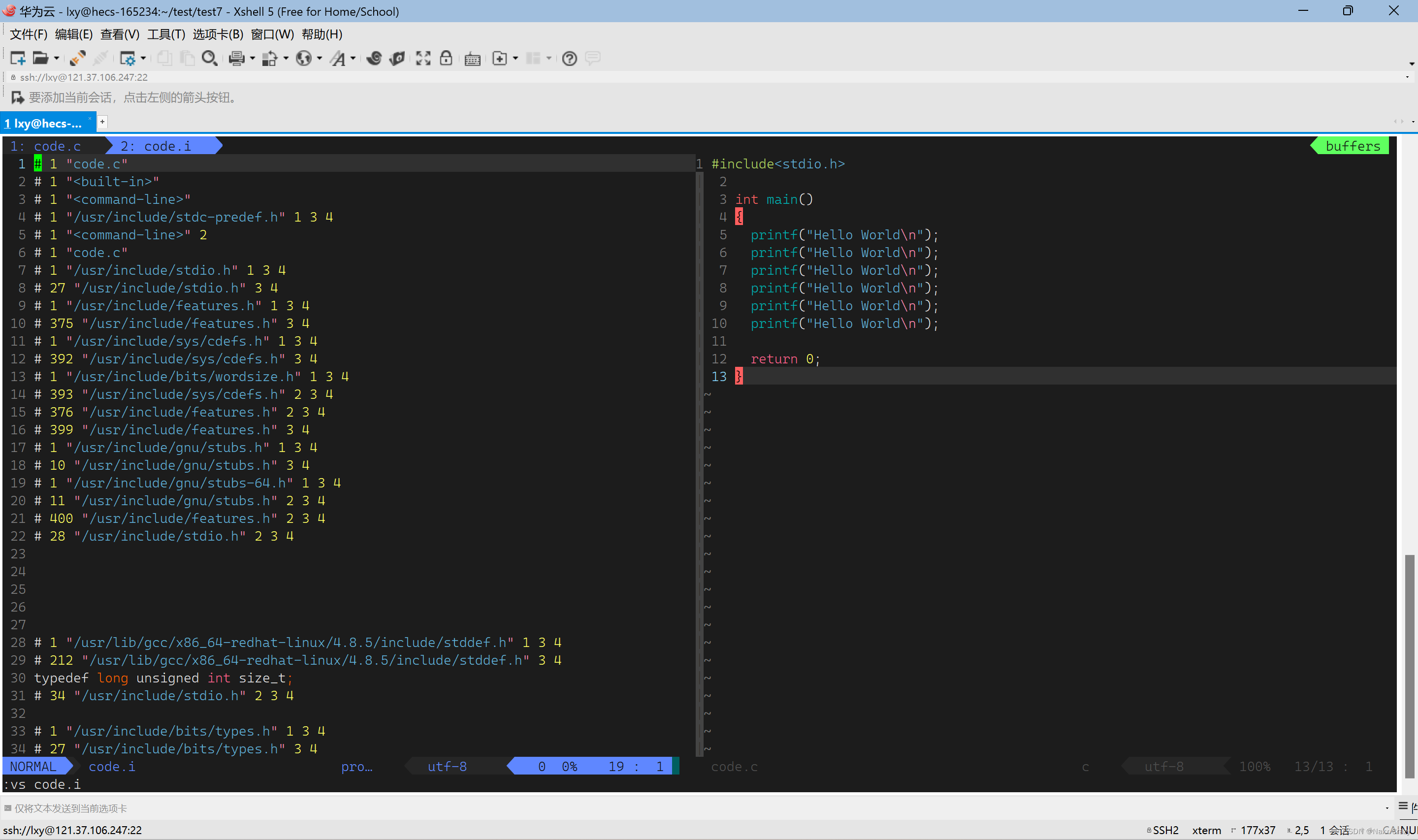
我们前面的这个就是code.i文件,我们看到最开始是一些其他的代码,而这个就是头文件的展开,我们还可以看一下其他的代码
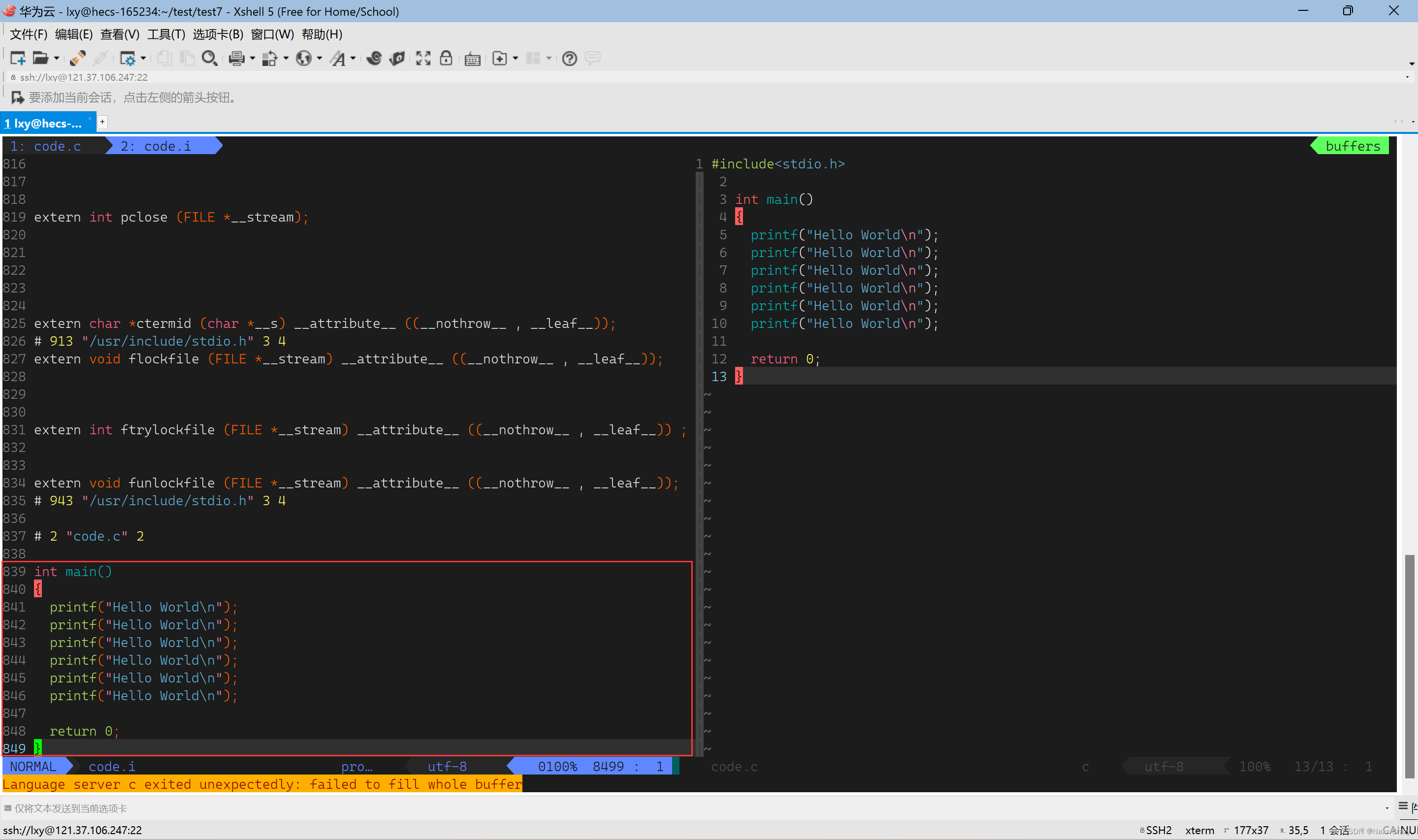
code.i文件件现在又八百多行,而前面就是头文件展开后的效果,剩下的就是原本的代码
那么我们现在看到了头文件的展开,我们还可以看一下宏的替换和去注释
去注释
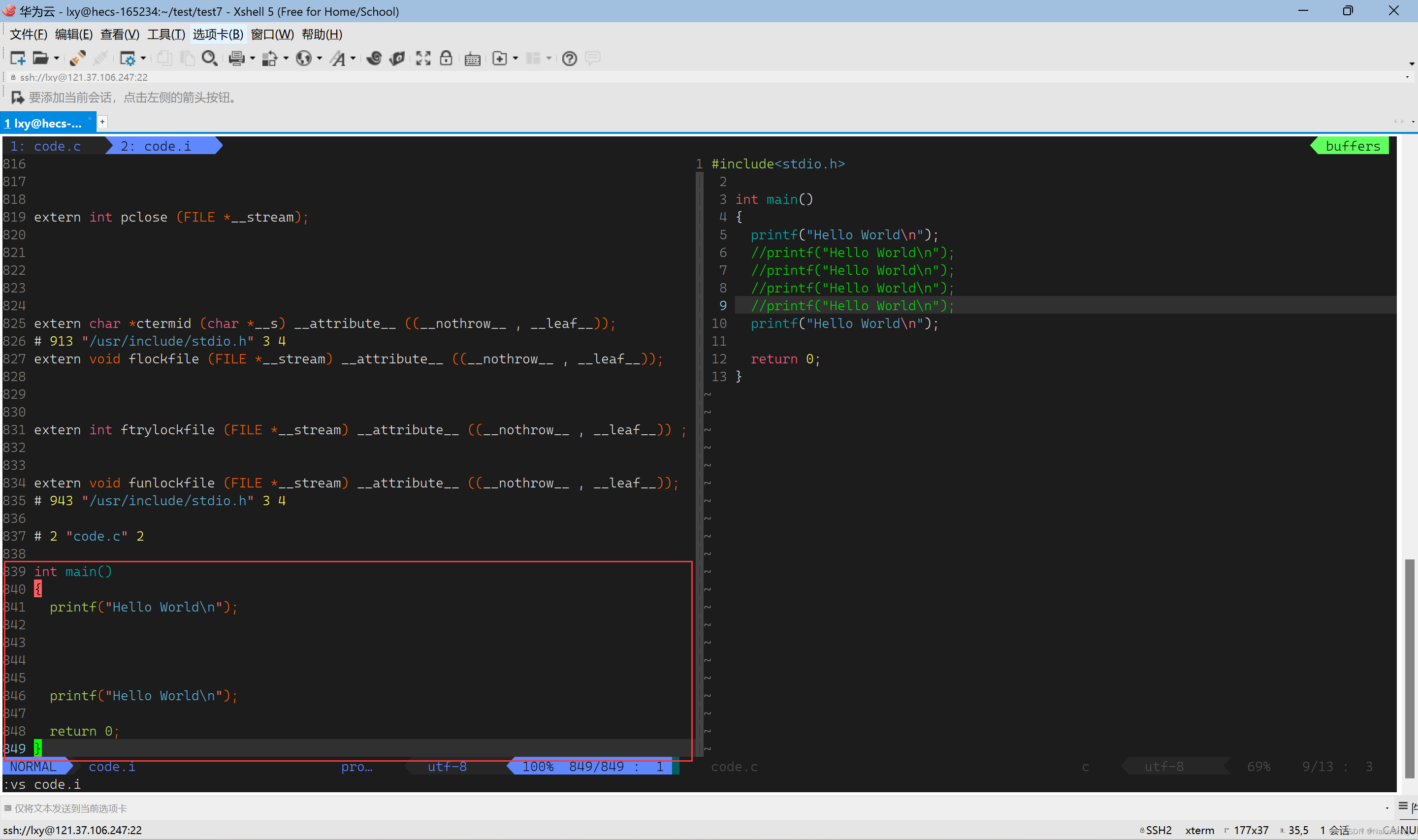
这时候我们在源代码上注释了一些内容,我们预处理后的代码就没有了注释掉的内容,这个就是去注释,我们下面在看一下宏替换
宏替换
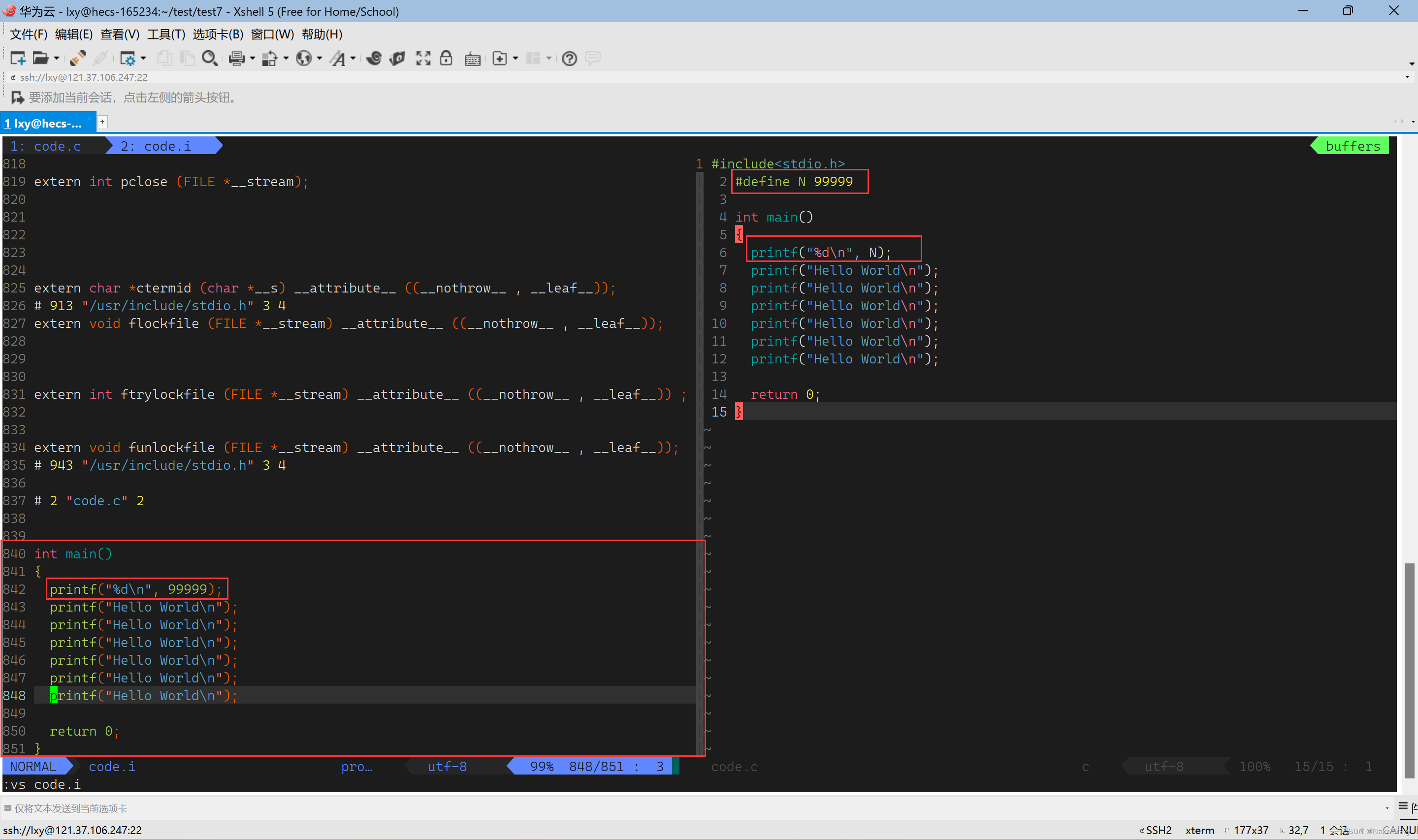
这次我们在源代码上加了#define N 99999,然后我们打印N,但是在我们的编译链接后,我们就是直接打印的是99999,这个就是宏替换,我们左后看一下条件编译
条件编译
我们先说一下什么是条件编译,我们经常听到说有些程序可以在64/32位下运行,或者是在windows/linux下跑,那么是什么原因呢? 就是条件编译,条件编译就是选择性的屏蔽或者是跳过或是执行某些代码,我们下面就来看一下条件编译
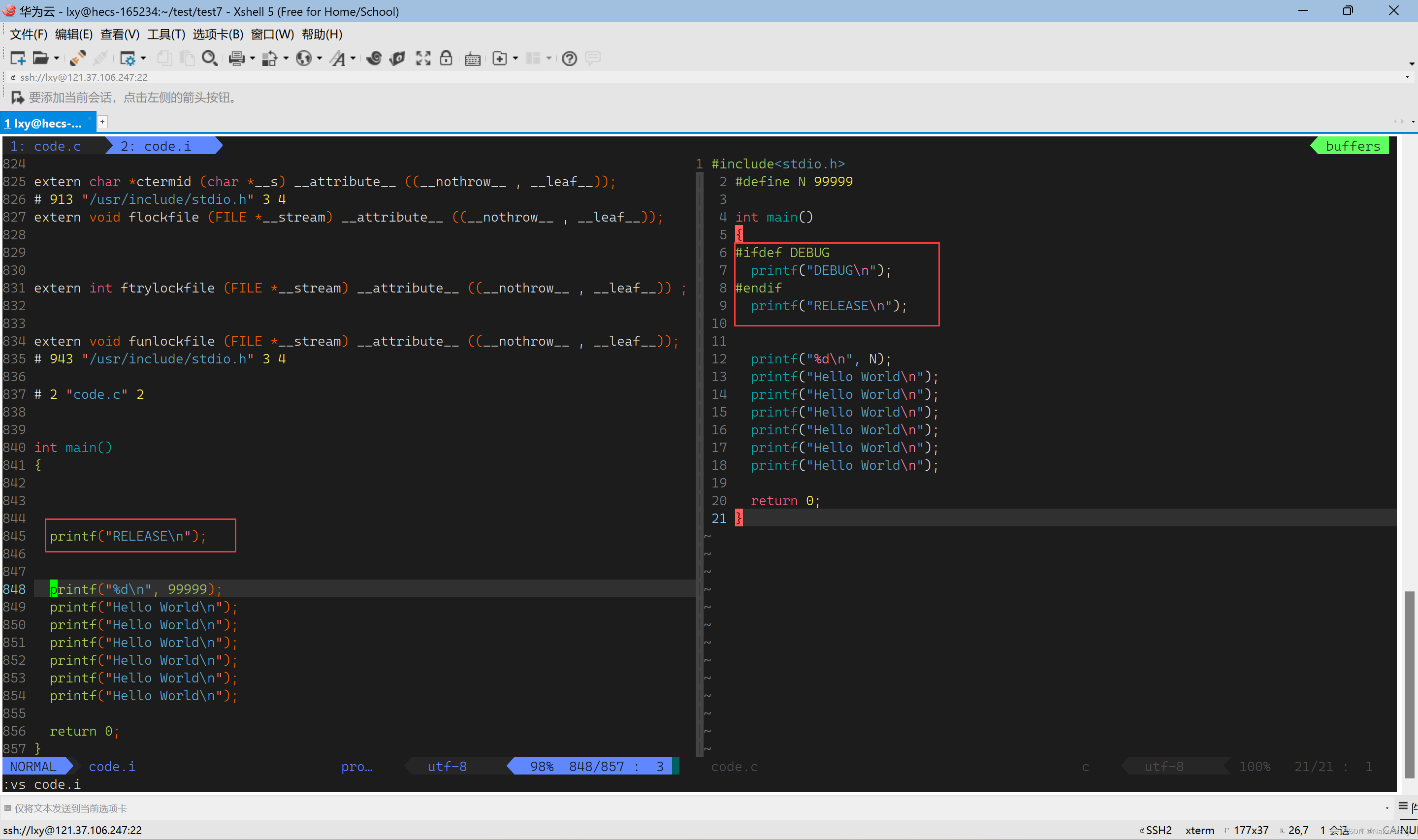
这个就是预处理做的事情,头文件展开 ,去注释,宏替换,条件编译
编译
编译:将预处理后的程序生成汇编代码
我们来看一下
![]()
这条指令就是将预处理后的code.i文件生成汇编代码,汇编代码我们一般用.s做后缀,这条指令也是后面会说到,现在只是看 现象
我们下面看一下生成的汇编代码
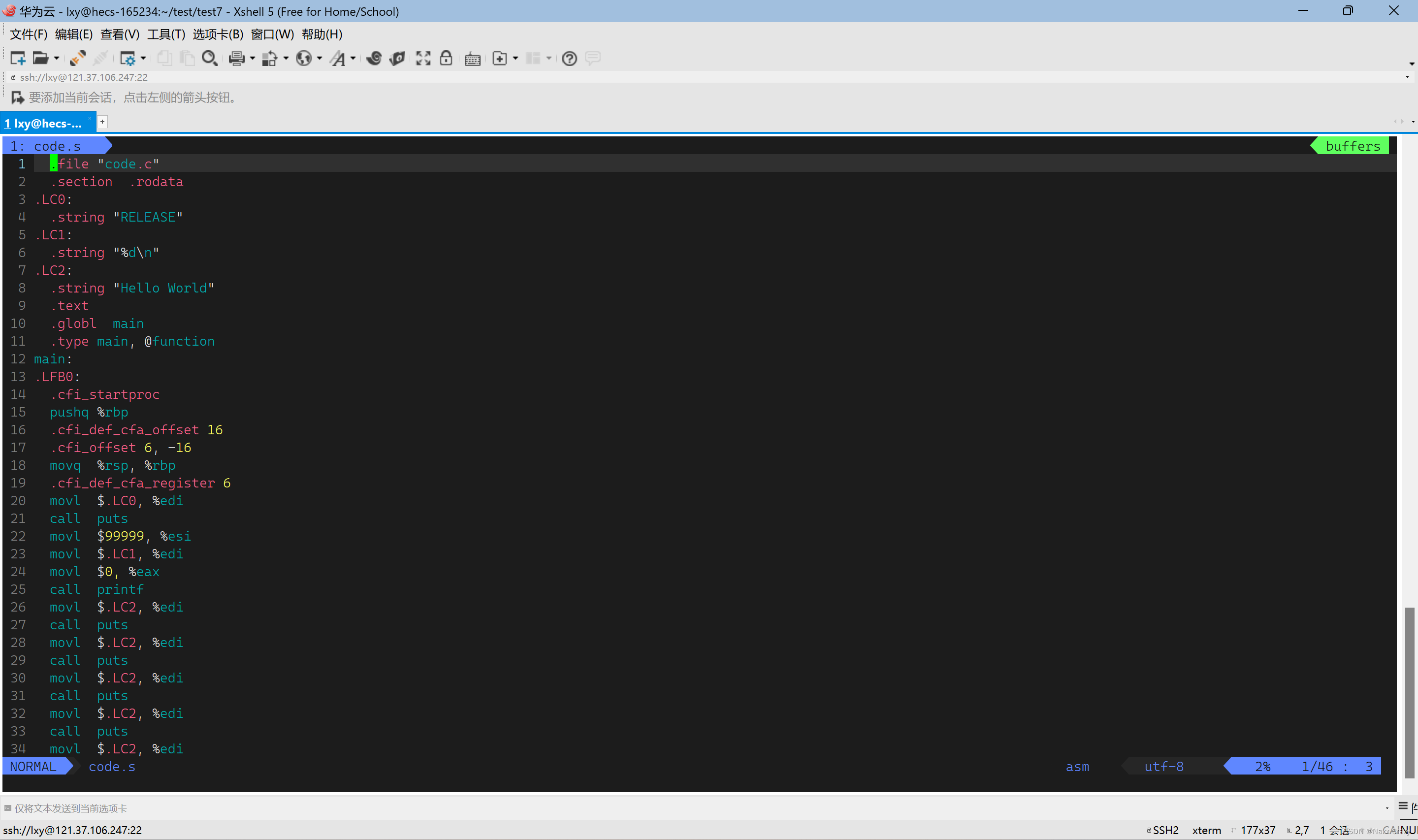
我们看到这就汇编代码,我们多少还是可以看明白一点的
编译
编译:将汇编代码编译为二进制机器码
![]()
上面的指令是将汇编编译为二进制机器码
我们看一下,编译生成的二进制机器码
上面的code.o是二进制文件,所以我们需要用二进制的工具查看
二进制文本查看工具 od file_name
但是我们还是看不懂
在讲链接之前,我们先讲一下我们刚才的所有的指令
gcc-g++ 指令
1.预处理指令
我们在看预处理后的文件我们是怎们看的?
![]()
就是这条指令,但是这条指令又什么作用呢?
首先我们先看一下gcc,其实gcc和g++的使用方法时一样的,都是gcc [可选项] file_name [可选项]...
现在我们在来看一下这条指令,后面的指令也基本都是这样
1.gcc:就是使用的工具gcc/g++,也可以说时命令
2.-E:-E就是可选项,而-E的意思就是将该代码做完预处理就停止的意思
3.code.c:当然是文件名了,就是被编译的文件
4.-o:-o时可选项,意思是重命名,也有就是将预处理后的内容放在code.i的文件里面,而我们一般把预处理后的文件后缀叫.i文件
2.编译指令
![]()
这条命令就是编译的命令
我们这里只介绍一下-S的作用
1.-S: 就是编译的指令,告诉编译器,让编译器把该代码做完编译就可以了,也就是将该文件形成汇编代码就停止
所以-S,就是把文件形成汇编代码,而汇编代码一般的文件后缀为.s
3.汇编指令
![]()
这条指令就是形成二进制代码的指令
1.-c:意思就是告诉编译器,让编译器做完汇编就停止,也就是形成二进制机器码
而我们后面形成的文件是二进制文件,该文件叫做可重定向二进制目标文件,也叫做目标文件,虽然该文件时二进制文件,但是计算机并不可以执行,而该文件在windows里面也就是我们常见的.obj文件
链接
链接:就是把目标文件链接起来,形成可执行程序
链接的指令
我知道这样说并不能明白链接时什么,所以这里我先介绍一下形成可执行程序的指令
![]()
这条指令我们没有带除了-o外的可选项,因为只要我们直接编译,我们就会生成可执行程序
![]()
我们看到我们形成了可执行程序,那么如果我们步带-o呢?
![]()
我们不带-o就是没有重命名,所以给我们默认名字a.out
所以我们平时编译程序只需要
gcc/g++ file_name -o/non -o(不带-o)新名称(不带-o当然不需要重命名)
链接的理解
我们刚才只是大概的说了一下什么时链接,就是将目标文件链接起来,形成对应的可执行程序,以及说了关于链接的指令
我们下面说一下关于链接的理解,当然现在也只是浅浅的谈一下
链接:
我们现在有一个程序,该程序里面又一个printf()函数,那么既然printf是函数,所以printf这个函数一定要有声明和定义,那么我们自己没有声明和定义该函数,是谁给我们做的呢?当然是写C语言的工程师了,那么我们也没有看到我们该函数定义在那里了
我们在想一下,我们C语言的程序时,我们会写什么#include<stdio.h>这个就是头文件,所以C语言的声明一定在这里面,但是只有C语言的声明有用吗?没有用,因为我们还需要定义,那么它的定义在那里呢?——库 里面
而我们用的C语言,所以我们用的库当然是C语言的库了,那么这个库又在那里呢?
在linux下,我们的C语言的库在/lib路劲下
所以我们的可执行程序都是需要链接的,我们需要把头文件和我们自己的文件链接起来,这样才可以形成可执行程序
查看程序连接库的指令 ldd

我们现在可以看一下我们刚才的代码链接的库

库的名字
我们看到我们上面的链接的这么长,但是并不是这样子的,我们库的实际名字是去掉前缀,去掉后缀, libc.so.6....拿这个举例说明
libc.so.6.... lib:就是前缀
libc.so.6.... .so:说明该库是动态链接的库(还有静态链接的库)也需要去掉
libc.so.6.... .6...:版本号也要去掉
libc.so.6.... 所以我们库的真正的名字的 c
这个就是库的名词
动态库
我们刚才说了动态库和静态库,那么什么是动态库和静态库呢?
动态库:又称共享库,在链接后运行时需要库函数的时候去库里面找,所以我们一个动态库可能又多个程序使用
静态库
静态库:在编译链接的时候,将库里面的内容拷贝到自己的程序中,所以即使是将该可执行程序放在没有库的其他环境也可以运行
但是我们的云服务器一般是默认没有静态库的,所以我们需要自己yum安装静态库
安装静态库
sudo yum -y install glibc-static :C语言静态库
sudo yum install -y libstdc++-static :C++静态库
动静态库编译
我们的gcc/g++一般都是默认动态库编译,因为动态库编译需要耗费的资源少,所以我们的编译器都是默认动态
那么我们怎们样静态编译呢?
例如:![]()
后面加 -static就是 默认静态编译

我们可以看到静态库编译后,占用的资源比动态库大好多倍
动静态库的优缺点
动态库:编译后占用资源少[优点],需要依赖库,一旦库被删除,或者丢失程序就无法运行[缺点]
静态库:并不依赖库,即使库丢失程序也可以运行[优点],占用资源多[缺点]
动静态库各有有缺点
debug和release
我们的程序在编译后,可能出现一些问题,所以这时候我们需要调试,但是我们直接编译时不可以调试的,我们需要加入调试信息
加入调试信息 -g
指令
![]()
我们后面加-g就可以加入调试信息

所以我们加入调试信息后编译后的内容又大了一点
查看debug信息 readelf -S
readelf -S file.exe_name(可执行程序的文件名)可以查看debug信息
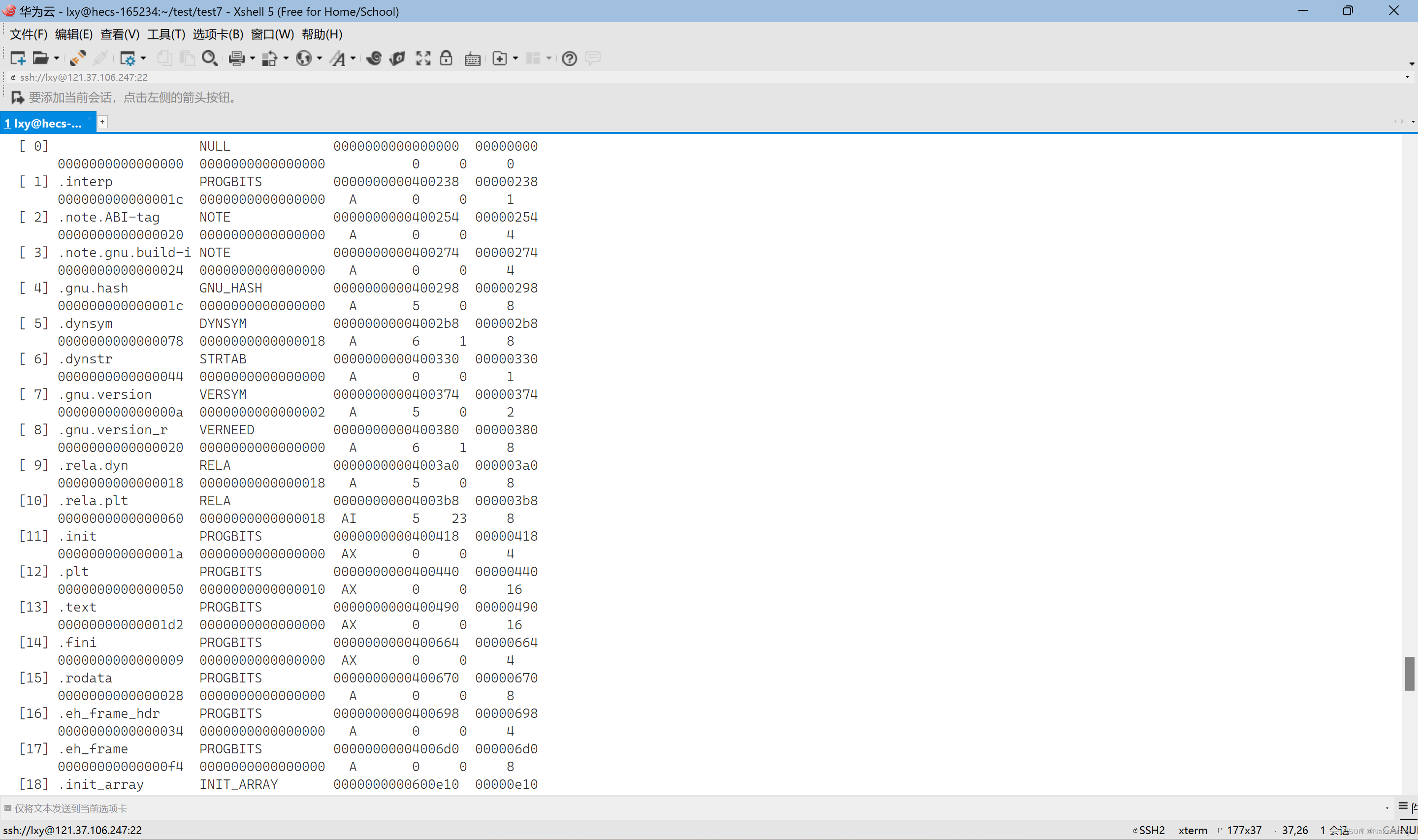
这里面就有调试信息
今天的gcc/g++的使用就到这里,gcc/g++的使用其实是一样的,但是gcc只能用来编译C语言,但是g++不仅可以编译C++还可以编译C语言,但是建议编译C++