🎁2021第十二届蓝桥杯python组国赛真题

🏆国赛真题目录
文章目录
- 🎁2021第十二届蓝桥杯python组国赛真题
- 试题A.带宽⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题B.纯质数⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题C.完全日期⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题D.最小权值⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题E.大写⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题F.123⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题G.冰山⭐️⭐️⭐️⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题H.和与乘积⭐️⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题I.二进制问题⭐️⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
- 试题J.翻转括号序列⭐️⭐️⭐️⭐️⭐️
- 🍰1.题目
- 👑2.思路分析
- 💯3.代码实现
试题A.带宽⭐️
🍰1.题目
带宽

👑2.思路分析
难度:⭐️
标签:单位换算
🎇思路:计算机常识
🔱思路分析:
本题考查的是简单的单位换算,但需要对计算机知识有基本的了解
1. M B MB MB 与 M b Mb Mb
M B MB MB 和 M b Mb Mb 是计算机中的储存单位,即为数据大小,可以简写为 M M M 和 m m m,其中, M B MB MB 表示兆字节( B y t e Byte Byte), M b Mb Mb 表示兆比特( b i t bit bit),所以有换算公式: 1 M B = 8 M b 1MB=8Mb 1MB=8Mb
2. M B p s MBps MBps 与 M b p s Mbps Mbps
M B p s MBps MBps 和 M b p s Mbps Mbps 表示的是速率,用于反映下载速度或数据读写速度,可以简写为 M B / s MB/s MB/s 和 M b / s Mb/s Mb/s,其中, M B p s MBps MBps 表示兆字节每秒, M b p s Mbps Mbps 表示兆比特每秒,则有换算公式: 1 M B p s = 8 M b p s 1MBps=8Mbps 1MBps=8Mbps
英文巧记:
M B → M i l l i o n B y t e MB→Million\ Byte MB→Million Byte
M b → M i l l i o n b i t Mb→Million\ bit Mb→Million bit
M B p s → M i l l i o n B y t e p e r s e c o n d MBps→Million\ Byte\ per\ second MBps→Million Byte per second
M b p s → M i l l i o n b i t p e r s e c o n d Mbps→Million\ bit\ per\ second Mbps→Million bit per second
💯3.代码实现
单位换算实现:
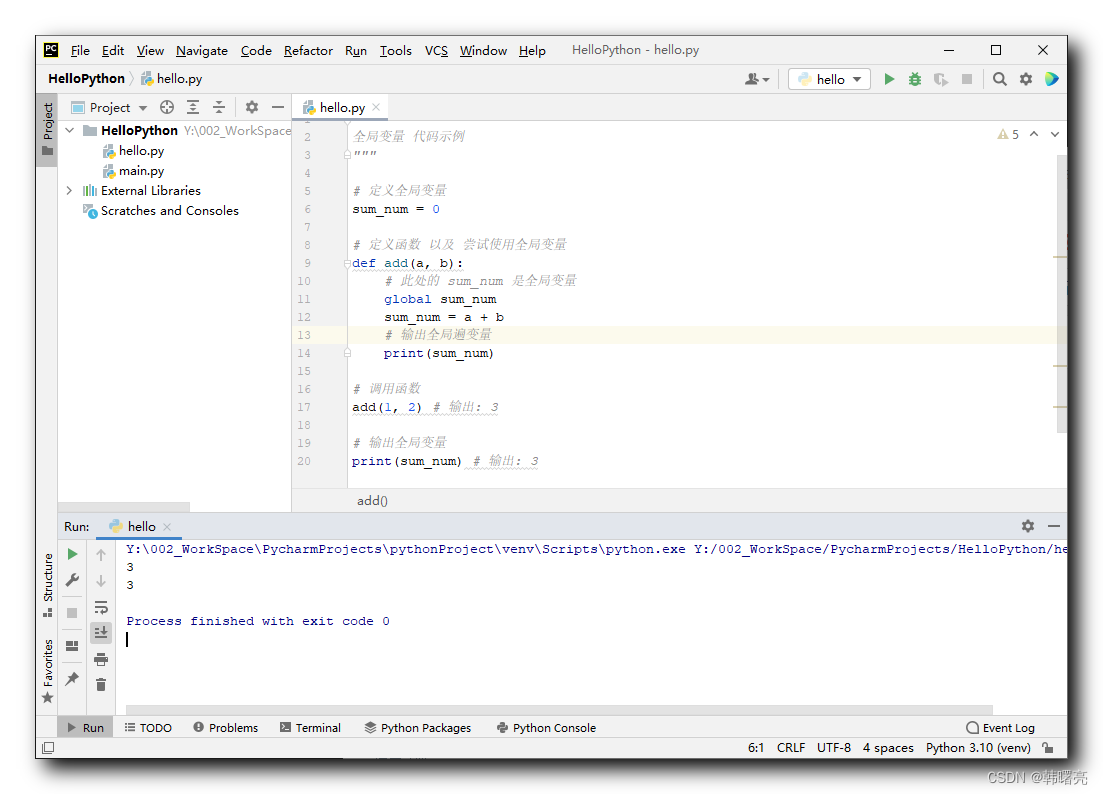
print(200//8)
# 25
输出结果:

试题B.纯质数⭐️
🍰1.题目
纯质数

👑2.思路分析
难度:⭐️
标签:素数筛
🎇思路:素数筛
🔱思路分析:
纯质数:在素数条件的基础上,还要满足每一个数位上的数都是质数
而个位为质数的数只有: p r i m e = [ 2 , 3 , 5 , 7 ] prime=[2,3,5,7] prime=[2,3,5,7]
因此,本质还是判断为素数之后再依次判断每一个数位上是否为素数,而判断素数最快的方法就是 素数筛:
step:
素数筛:对于任意一个素数,它的正整数倍 ( ≥ 2 ) (≥2) (≥2)一定是合数
- 构造 v i s vis vis数组,先初始化 v i s vis vis为 1 1 1( 1 1 1为素数, 0 0 0为合数)
- 遍历 2 → 20210605 2→20210605 2→20210605,若当前的数 x x x为 v i s [ x ] = 1 vis[x]=1 vis[x]=1(未被标记),且为素数,对他进行处理:
①遍历 x x x的倍数 i = 2 x , 3 x , . . . i=2x,3x,... i=2x,3x,...
②如果 i i i未被标记过(防止合数重复标记,如2的3倍为6,3的2倍也为6,则统计的合数个数会增多),则标记vis[i]=0
③进一步对该素数进行判断,依次得到其数位上的每一个数,如果均在数组 p r i m e = [ 2 , 3 , 5 , 7 ] prime=[2,3,5,7] prime=[2,3,5,7]中,则为纯质数,cnt+=1
图解:

💯3.代码实现
素数筛实现:
from math import *
def is_Prime(x): # 判定为素数
for i in range(2,int(sqrt(x))+1):
if x%i==0:
return False # 合数
return True # 素数
def allPrime(x): # 判定为纯素数
while x != 0:
a = x % 10
x = x // 10
if a not in prime:
return False # 是素数,但不是纯素数
return True
prime=[2,3,5,7] # 个位的纯质数列表
vis=[1]*(20210605+1)
cnt=0
for num in range(2,20210605+1):
if vis[num]==1 and is_Prime(num): # 如果是素数
for i in range(2,20210605//num+1): # 素数的整数倍一定不是素数
vis[i*num] = 0 # 标记为合数
if allPrime(num): # 每一位都是素数
cnt+=1 # num为纯素数
print(cnt) #1903
输出结果:

试题C.完全日期⭐️
🍰1.题目
完全日期

👑2.思路分析
难度:⭐️
标签:闰年的判断
🎇思路:模拟
🔱思路分析:
本题需要将所有的年月日都遍历一遍,寻找完全平方数,而遍历日期的难点就在于闰年中2月的判断
step:
-
得到年月日之和:
我们先设置一般年份中每月的天数: m = [ 0 , 31 , 28 , 31 , 30 , 31 , 30 , 31 , 31 , 30 , 31 , 30 , 31 ] m=[0,31,28,31,30,31,30,31,31,30,31,30,31] m=[0,31,28,31,30,31,30,31,31,30,31,30,31]
闰年的判断:
- 世纪闰年:能被 400 400 400整除的 y e a r year year
- 普通闰年:能被 4 4 4整除但不能被 100 100 100整除的 y e a r year year
在判断年份之后,如果为闰年,则修改 m [ 2 ] = 29 m[2]=29 m[2]=29,在对该年的遍历结束之后再修改回 28 28 28
-
判断为完全平方数:
对所求的sum,可以通过:
if sum==int(sqrt(sum))**2进行判断,因为 i n t ( s q r t ( s u m ) ) int(sqrt(sum)) int(sqrt(sum)) 得到的是对 s u m sum sum开方后得到的浮点数向下取整的结果,如果 s u m sum sum不为完全平方数,则结果应该为sum>int(sqrt(sum))**2
💯3.代码实现
模拟实现:
from math import *
def leapyear(y):
# 1.世纪闰年:能被400整除
# 2.普通闰年:能被4整除但不能被100整除
if y%400==0 or (y%100!=0 and y%4==0):
return True
return False
def get(x):
res=0
while x!=0:
res+=x%10
x=x//10
return res
m=[0,31,28,31,30,31,30,31,31,30,31,30,31] # 每月的天数 0位置不存
cnt=0
for year in range(2001,2022):
if leapyear(year): # 如果是闰年 修改2月的天数
m[2]=29
for month in range(1,13):
for day in range(1,m[month]+1):
sum=get(year)+get(month)+get(day)
if sum==pow(int(sqrt(sum)),2):
cnt+=1
m[2]=28 # 此轮循环结束 还原2月的天数
print(cnt) # 977
输出结果:

试题D.最小权值⭐️⭐️⭐️
🍰1.题目
最小权值

👑2.思路分析
难度:⭐️⭐️⭐️
标签: d p dp dp 动态规划
🎇思路: d p dp dp 动态规划
🔱思路分析:
要求2021个结点时树的最小权值,而权值是按照特定方式计算的,我们无法直接得到,因此,可以由小规模问题逐渐递推到大规模问题—— d p dp dp 动态规划
step:
-
确定 d p dp dp数组:
首先要知道 d p dp dp 数组的状态:由当前状态到下一个状态时,状态变化的只有树的结点数,由 i → i + 1 i→i+1 i→i+1,因此,我们定义 d p [ i ] dp[i] dp[i]:表示有 i i i 个结点时,树的最小权值为 d p [ i ] dp[i] dp[i]
-
状态转移:
由于树的权值与左、右子树的权值以及左、右子树的结点数均有关,而又因为确定了一棵树的结点,就确定了该结点下的最小权值( d p [ x ] dp[x] dp[x]),所以,我们该树左子树的结点数为 j j j,则右子树的结点数为 i − j − 1 i-j-1 i−j−1 (除去根节点),则左子树的最小权值为 d p [ j ] dp[j] dp[j],右子树的最小权值为 d p [ i − j − 1 ] dp[i-j-1] dp[i−j−1] ,暴力枚举每一种 j j j 的情况,最后得到权值最小的解,即为 d p [ i ] dp[i] dp[i]
状态转移方程为:
dp[i]=min(dp[i],1+2*dp[j]+3*dp[i-j-1]+(j**2)*(i-j-1)
-
最终结果: 即为结点数为2021时的 d p [ 2021 ] dp[2021] dp[2021]
💯3.代码实现
模拟实现:
dp=[float('inf')]*2022 # dp[i]表示结点数为i的树的最小权值
dp[0]=0
dp[1]=1 # 只有一个结点时 权值为1
for i in range(2,2022): # i∈[2,2021]
for j in range(1,i): # j表示结点数为i的树的左子树的结点个数 j∈[1,i-1]
dp[i]=min(dp[i],1+2*dp[j]+3*dp[i-j-1]+(j**2)*(i-j-1)) # 遍历左子树的结点数 找到最小值
print(dp[2021]) # 2653631372
输出结果:

试题E.大写⭐️
🍰1.题目
大写

👑2.思路分析
难度:⭐️
标签: p y t h o n python python语法
🎇思路①: A S C I I ASCII ASCII码转化
🔱思路分析:
根据 A S C I I ASCII ASCII码,我们知道 ′ A ′ = 65 , ′ Z ′ = 90 ; ′ a ′ = 97 , ′ z ′ = 122 'A'=65,'Z'=90;'a'=97,'z'=122 ′A′=65,′Z′=90;′a′=97,′z′=122,因此:
大写的 A S C I I ASCII ASCII码 + 32 +32 +32 = = =小写字母的 A S C I I ASCII ASCII码
这里再补充两个 p y t h o n python python中的语法:
ord(str):返回 s t r str str 对应的 A S C I I ASCII ASCII码chr(num):返回 A S C I I ASCII ASCII 码为 n u m num num的字符
🎇思路②:语法
🔱思路分析:
这里也有更为简单粗暴的方法:
利用
p
y
t
h
o
n
python
python中的函数:str.upper()
如果为小写字母,则将其转化为大写;遇到其他字符则不变
补充:对应大写转为小写的函数为:
str.lower()
💯3.代码实现
1. A S C I I ASCII ASCII实现:
s=input()
res=''
for i in s:
if ord(i)>=97 and ord(i)<=122: # 如果为小写
a=chr(ord(i)-32)
res=res+a
elif ord(i)>=65 and ord(i)<=90:
res+=i
else:
print("输入的不是字母!")
break
print(res)
2.语法实现:
print(input().upper())
输出结果:

试题F.123⭐️⭐️⭐️
🍰1.题目
123

👑2.思路分析
难度:⭐️⭐️⭐️
标签:二分 + 思维
🎇思路:二分
🔱思路分析:
要求区间 [ L , R ] [L,R] [L,R] 中数的和,如果每一轮都先求解前缀和数组,那时间复杂度为 O ( T r ) O(Tr) O(Tr),肯定无法通过所有100%,所以,我们应该抓住题目所给数列的特殊性
我们先简单列举几项:

我们对这些数按组进行分类,其组内元素个数依次递增
对于该数列,有如下性质:
-
第 k k k 组数的和 = = == == 前 k k k 组数的总个数: k ∗ ( k + 1 ) 2 \frac{k*(k+1)}{2} 2k∗(k+1)
可以看到,由于组号为 k k k 的数组是等于它的长度的,且其中最大的元素 a k = k a_k=k ak=k,所以每增加一个长度为 k k k 的数组 k k k 时,改组数的变化范围为 1 → k 1→k 1→k,则正好等于第一组到第k组元素的总个数,即为在数组中的位置
-
前 k k k 组数的总和为: k ∗ ( k + 1 ) ∗ ( k + 2 ) 6 \frac{k*(k+1)*(k+2)}{6} 6k∗(k+1)∗(k+2)
d e f def def:由于 S n = s u m 1 + s u m 2 + . . . + s u m k S_n=sum_1+sum_2+...+sum_k Sn=sum1+sum2+...+sumk,而 s u m k = k ∗ ( k + 1 ) 2 sum_k=\frac{k*(k+1)}{2} sumk=2k∗(k+1)
因此,可以将其拆分为: S n = S n 1 + S n 2 = 1 2 ∗ [ 1 2 + 2 2 + . . . + k 2 ] + 1 2 ∗ [ 1 + 2 + . . . + k ] S_n=S_{n1}+S_{n2}=\frac{1}{2}*[1^2+2^2+...+k^2]\ + \frac{1}{2}*[1+2+...+k] Sn=Sn1+Sn2=21∗[12+22+...+k2] +21∗[1+2+...+k]
根据公式 ∑ i = 1 n n 2 = n ∗ ( n + 1 ) ∗ ( 2 n + 1 ) 6 ∑_{i=1}^{n}n^2=\frac{n*(n+1)*(2n+1)}{6} ∑i=1nn2=6n∗(n+1)∗(2n+1), ∑ i = 1 n n = n ∗ ( n + 1 ) 2 ∑_{i=1}^{n}n=\frac{n*(n+1)}{2} ∑i=1nn=2n∗(n+1)
解得: S n = k ∗ ( k + 1 ) ∗ ( k + 2 ) 6 S_n=\frac{k*(k+1)*(k+2)}{6} Sn=6k∗(k+1)∗(k+2)
回到正题,根据上面两个性质,我们现在最重要的就是确定 L , R L,R L,R 在数组 a a a中的位置,也就是在第 x x x 组第 y y y 个,因此,我们定义 两个映射:
①映射 f 1 f1 f1:区间序号 k k k → → → 元素个数(对应 a a a 数组中下标)
若已知区间序号为 k k k,则可以确定数组下标 i i i 的范围为: k ∗ ( k − 1 ) 2 < i ≤ k ∗ ( k + 1 ) 2 \frac{k*(k-1)}{2}<i≤\frac{k*(k+1)}{2} 2k∗(k−1)<i≤2k∗(k+1)
def getk(k): # 映射1:区间序号k->元素个数
return k*(k+1)//2 # k表示第k个区间,返回结果为前k个区间所含元素的个数
②映射 f 2 f2 f2:区间序号 k k k → → → 前缀和
若已知区间序号为 k k k,则可以确定下标元素 a [ i ] a[i] a[i] 的 s u m [ x ] sum[x] sum[x] 满足: k ∗ ( k − 1 ) ∗ ( k + 1 ) 6 < s u m [ i ] ≤ k ∗ ( k + 1 ) ∗ ( k + 2 ) 6 \frac{k*(k-1)*(k+1)}{6}<sum[i]≤\frac{k*(k+1)*(k+2)}{6} 6k∗(k−1)∗(k+1)<sum[i]≤6k∗(k+1)∗(k+2)
def getsum(k): # 映射2:区间序号k->前缀和
return k*(k+1)*(k+2)//6 # 表示前k个区间的元素总和
于是,我们再结合二分查找,先找到 L , R L,R L,R 的具体位置,再根据映射 f 2 f2 f2,将位置 k k k映射为前缀和,就可以得到区间 [ L , R ] [L,R] [L,R] 的和了
step:
-
确定下标 x x x 所在的数组区间 k k k:
如要找下标为 5 的元素所在的区间,我们对区间 k k k 进行二分查找

如此时
mid=3,我们将区间为 k = 3 k=3 k=3 时映射到元素个数:getk(k)=6:表示区间为3时,对应的数组下标最多为 6,返回函数值, 6 > 5 6>5 6>5,r=3,继续二分过程,结束时l=r=3,则可以确定,下标为 5 的元素在区间为 3 的数列中
最后用下标: 5 − g e t k ( k − 1 ) 5-getk(k-1) 5−getk(k−1) 即得到该元素在区间 k 的数列中的位序
-
求解前缀和
确定了 L , R L,R L,R 的位置后,则可以求得 [ L , R ] [L,R] [L,R] 的区间和了:
假设 L L L 所在区间为 l k lk lk, R R R 所在区间为 r k rk rk

由图可知,
sum[rk]-sum[lk-1]为蓝色 + + +红色部分的长度,但是实际上,蓝色部分并不在区间 [ L , R ] [L,R] [L,R] 内,所以还要根据位置关系减去这两部分,但为了方便计算,这里选择的是用: s u m [ r k − 1 ] − s u m [ l k − 1 ] sum[rk-1]-sum[lk-1] sum[rk−1]−sum[lk−1] − - − 左边蓝色部分 + + + 黄色部分
💯3.代码实现
二分 + 前缀和实现:
def getk(k): # 映射1:区间序号k->元素个数
return k*(k+1)//2 # k表示第k个区间,返回结果为前k个区间所含元素的个数
def getsum(k): # 映射2:区间序号k->前缀和
return k*(k+1)*(k+2)//6 # 表示前k个区间的元素总和
def position(x):
l,r=1,int(2e6) # 二分区间
while l<r:
mid=(l+r)>>1
if getk(mid)<x: # getk相当于k的一个映射,映射:组数->元素个数
l=mid+1
else:
r=mid
return l,x-getk(l-1) # x在第l组中的第x-getk(l-1)个
def solve(l,r):
lk,pos_l=position(l) # 确定l的具体位置
rk,pos_r=position(r) # 确定r的具体位置
sum=getsum(rk-1)-getsum(lk-1)-getk(pos_l-1)+getk(pos_r) # 画图模拟一下
return sum
T=int(input())
for _ in range(T):
l,r=map(int,input().split())
print(solve(l,r))
输出结果:
试题G.冰山⭐️⭐️⭐️⭐️⭐️⭐️
🍰1.题目
冰山

👑2.思路分析
难度:⭐️⭐️⭐️⭐️⭐️⭐️
标签: F H Q − t r e a p FHQ-treap FHQ−treap
🎇思路①:双字典
🔱思路分析:
本题难点就是每一天都要对冰山的体积进行整体修改,区间修改可能会想到线段树,但是这里要不断修改线段树的值,十分繁琐
算法思路:由于是整体修改,我们则可以对体积相同的冰山归为一类进行操作,所以,不难想到构造两个字典 a , b a,b a,b,只需记录:{冰山的体积:对应的冰山数量}, a a a 用于表示这一天开始时的冰山状态, b b b 用于表示这一天结束时的冰山状态
step:
-
字典操作:
g e t ( k e y , 0 ) get(key,0) get(key,0): 对于体积 v v v 的冰山,假设有 c n t cnt cnt 个,我们可以通过:
a[v]=a.get(v,0)+cnt,实现键值对的更新操作,其等价于:先判断是否存在键值对v,如果存在,则将其值 + c n t +cnt +cnt;如果不存在,则先构造一个键: v v v,再将其值 + c n t +cnt +cnt
-
对冰山的体积进行分类判断:
①变化后体积 v i + x i > k vi+xi>k vi+xi>k:则这些冰山之后分解为 a [ v i + x i ] a[vi+xi] a[vi+xi] 个体积为 k k k 的冰山和 ( v i + x i − k ) ∗ a [ v i + x i ] (vi+xi-k)* a[vi+xi] (vi+xi−k)∗a[vi+xi] (该冰山数量 x 一个这样的冰山分解为体积为1的冰山的个数)个体积为 1 1 1 的冰山,放入空字典 b b b中;
②变化后体积: 1 < v i + x i ≤ k 1<vi+xi≤k 1<vi+xi≤k :这些冰山既不会分解,也不会消失,则直接修改键为
vi+xi,而对应的值不变,放入空字典 b b b中:
③变化后体积: v i + x i ≤ 0 vi+xi≤0 vi+xi≤0 :冰山消失,跳过此轮,不放入 b b b 中
- 如果飘来的冰山体积
y!=0,则对应的字典中的键:b[y]+=1
- 把原本的 a a a字典清空,将 b b b 赋值给 a a a,对 a a a中的键值对遍历求和即可
注意: 这里的 g e t n u m getnum getnum 函数用于求字典 a a a 中该键 k e y key key对应的值,如果存在该键则
+a[key];否则+0
🎇思路②: F H Q − t r e a p FHQ-treap FHQ−treap
🔱思路分析:
暂时没有写出来…
💯3.代码实现
双字典实现:(通过 70 %)
def getnum(x): # 判断a中有没有这个键值对
if x in a.keys():
return a[x]
else:
return 0
n,m,k=map(int,input().split())
l=list(map(int,input().split()))
a={} # 定义字典:{体积:对应的冰山个数}
for i in l:
a[i]=a.get(i,0)+1
for _ in range(m):
x,y=map(int,input().split())
b={} # 辅助字典
for i in a.keys(): # 取出键
if i+x>k:
b[1]=b.get(1,0)+(i+x-k)*getnum(i) # 分解后体积为1的冰山
b[k]=b.get(k,0)+getnum(i)
elif i+x>0:
b[i+x]=b.get(i+x,0)+getnum(i) # 当前体积为i+x的冰山数量加上原本体积为i的冰山数量
else: # 修改后消失的冰山 略过
continue
if y!=0:
b[y]=b.get(y,0)+1 # 加上体积为y的冰山
a.clear()
a=b
sum=0
for v,cnt in a.items():
sum+=(v*cnt)%998244353
print(sum%998244353)
输出结果:

试题H.和与乘积⭐️⭐️⭐️⭐️
🍰1.题目
和与乘积

👑2.思路分析
难度:⭐️⭐️⭐️⭐️
标签:二分 +前缀和 +思维
🎇思路:二分查找+前缀和
🔱思路分析:
首先,要确定这道题的模型,对于求某一个区间的和与乘积,我们首先可以想到用前缀和数组,但是,题目要求的是所有满足条件的区间而非单独查询某一个区间,所以就算构造出了前缀和数组,还是需要用两层循环暴力地遍历每一个区间(双指针)进行判断,结果肯定是超时,那么,我们就必须 另辟蹊径——利用本题最为特殊的 1 1 1
step:
💫1. 思维
问题规模分析:如果一个合法区间内,大于 1 1 1 的数的个数为 t o t a l total total,则有: t o t a l < 40 total<40 total<40
d e f def def:假设合法区间为: [ l , r ] [l,r] [l,r],在其中含有 t o t a l total total 个大于 1 1 1的数,则有 r − l + 1 − t o t a l r-l+1-total r−l+1−total 个数等于 1 1 1,由于 1 1 1对于乘积的结果没有贡献,所以乘积结果: m u l t i p l y > 2 t o t a l multiply>2^{total} multiply>2total (因为这 t o t a l total total 个数 ≥ 2 ≥2 ≥2),又根据区间长度: n ≤ 2 n≤2 n≤2 x 1 0 5 10^5 105,元素值: a i ≤ 2 a_i≤2 ai≤2 x 1 0 5 10^5 105,则最大区间和 = = = 最大区间长度 x 最大元素值 : : : s u m = 4 sum=4 sum=4 x 1 0 10 10^{10} 1010,而 4 4 4 x 1 0 10 < 2 40 10^{10}<2^{40} 1010<240 所以要使 m u l t i p l y = = s u m multiply==sum multiply==sum, t o t a l total total 一定小于 40 40 40
推论:换句话说,当区间乘积: m u l t i p l y ≥ 4 multiply≥4 multiply≥4 x 1 0 10 10^{10} 1010 时,一定不可能是合法区间
有了这个推论,我们便可以利用它在遍历时进行 剪枝
💥2. 特殊的 ′ 1 ′ '1' ′1′
本题中数组内的 ‘1’ 是操作性最强的地方,因为 ‘1’ 不会影响某一个区间的乘积,而只会影响到某一区间的和
所以,对于乘积来说,我们只需要着眼于 > 1 >1 >1 的数即可,因此,在暴力搜索区间 [ l , r ] [l,r] [l,r] 时,我们可以遍历: r > l a n d r > 1 r>l\ and\ r>1 r>l and r>1 的数作为区间的右边界,再进一步对覆盖区间内的 ′ 1 ′ '1' ′1′ 判断即可,这样,便减小了时间复杂度
算法具体实现:
以数组 a = [ 1 , 2 , 4 , 1 , 1 , 3 , 1 ] a=[1,2,4,1,1,3,1] a=[1,2,4,1,1,3,1] 为例:
-
求解前缀和数组 s u m sum sum
我们选择舍弃下标为 0 0 0 的位置不存

-
找到所有 > 1 >1 >1 的数的位置:
用 i n d e x index index 数组储存大于 1 1 1 的数的位置,利于快速确定区间右边界
在找到大于 1 1 1的数后,我们定义映射 f f f: a → i n d e x a→index a→index,之后若要访问 a a a 中大于 1 1 1 的数,只需对 i n d e x index index数组中的下标 j j j进行映射:
a[index[j]]即可
-
找到每一个 > 1 >1 >1 的数后连续的 ′ 1 ′ '1' ′1′的个数:
对于 a a a中下标为 i i i 的数, n u m num num_ 1 [ i ] 1[i] 1[i] 表示 a [ i ] a[i] a[i] 后面连续的 ‘1’ 的个数

-
二分搜索 →得到位序大于当前左区间 i i i 且 值大于1的最小位置 R:
我们在固定了左区间 i i i 后,就需要找到一个 R R R,使得
R>i and a[R]>1,也就是说,我们要在所求得的 i n d e x index index数组中寻找这样的 R R R,使区间为 [ i , R ] [i,R] [i,R]为了降低时间复杂度,我们选择对 i n d e x index index数组进行二分查找搜索:
这里二分要注意一个问题,我们要找的不是 i i i,而是比 i i i大的数,所以应该是返回比 i i i 大的位置!
假设此时 i = 3 i=3 i=3,也就是左区间为: a [ 3 ] = 4 a[3]=4 a[3]=4
①定义
l=0,r=total(因为如果让r=total-1,则得到的不是 i i i的后继)此时,
mid=1,index[mid]==i,也就是将 m i d mid mid 映射到数组 a a a 中,其下标为 i i i,但是因为我们要找的不是 i i i,而是大于 i i i 的数,所以移动左指针:l=mid+1
②移动后,
index[mid]>i,则移动右指针:r=mid
③最后,
l=r,则结束二分查找,所求的 R R R 即为 i n d e x [ r ] index[r] index[r] (映射)
-
遍历区间
在二分搜索后,我们得到了区间 [ l , R ] [l,R] [l,R],其中 l ∈ [ 1 , n ] l∈[1,n] l∈[1,n], R R R 为大于 1 1 1的数 a [ R ] a[R] a[R],我们对其合法性进行判断:
①剪枝:如果在遍历过程中发现:
multiply>INF=4x10^{10},则直接结束遍历,遍历下一个左区间值(由推论)
这里剪枝很重要,加上可以通过60%的案例,但这也是基于推论得来的
②若此时区间内的 s u m > m u l t i p l y sum>multiply sum>multiply:则因为 R R R 到下一个大于1的数中间均为1,导致在这个区间上乘积将无法等于和,所以继续对下一个满足条件的右区间的搜索
图解:

此时, s u m sum sum 的值已经大于 m u l t i p l y multiply multiply 了,就算加上右区间之后连续的 ′ 1 ′ '1' ′1′,也无法改变乘积值,所以,此时只有遍历下一个满足条件的右区间,才有可能使其相等

③若此时区间内的 s u m < = m u l t i p l y < = s u m + n u m sum<=multiply<=sum+num sum<=multiply<=sum+num_ 1 [ R ] 1[R] 1[R]:则表明,可以通过一定范围内右边界的延伸实现和与乘积相等,则数量 + 1 +1 +1
图解:

💯3.代码实现
二分 + 前缀和 + 思维 + 剪枝实现:
def getsum(l,r): # 求l,r区间的前缀和
return sum[r]-sum[l-1]
INF = 40000000000
n=int(input())
a=[0]+list(map(int,input().split())) # 第一个不存
sum=[0]*(n+1) # 前缀和
index=[] # 数组中>1的数的索引
total=0 # 记录>1的数的个数
num_1=[0]*(n+1) # 数组中>1的数之后连续1的个数
# 1.前缀和+得到>1的数的索引
for i in range(1,n+1):
sum[i]=sum[i-1]+a[i]
if a[i]>1:
index.append(i)
total+=1
# 2.得到数组中>1的数之后连续1的个数
cnt=0
for i in range(n,0,-1): # 从后向前遍历
if a[i]==1:
cnt+=1
else:
num_1[i]=cnt # 记录a[i]之后连续1的个数
cnt=0 # cnt清零
# 3.找到合法区间
res=0
for i in range(1,n+1): # 固定左区间为 i
res+=1 # 每一个数都是一个合法区间
multiply=a[i] # 表示乘积
l,r=0,total # 查找i之后第一个大于1的数的位置,即对>1的数组进行二分
while l<r:
mid=(l+r)>>1
if index[mid]>i: # 这里一定是> 因为要找在它之后的
r=mid
else:
l=mid+1
j=r # j表示后一个位置
while j<total: # 以index数组中之后的值index[j]依次作为右区间
R=index[j] # 映射:index->a
multiply*=a[R] # 由于[i,R]区间内的其他数均为1,所以不影响乘积
if multiply>INF:
break
if getsum(i,R)<=multiply<=getsum(i,R)+num_1[R]:
res+=1
j+=1
print(res)
输出结果:

试题I.二进制问题⭐️⭐️⭐️⭐️
🍰1.题目
二进制问题

👑2.思路分析
难度:⭐️⭐️⭐️⭐️
标签:数位 d p dp dp
🎇思路:数位 d p dp dp + d f s dfs dfs
🔱思路分析:
这里很容易想到将 N N N拆分为二进制数,要满足二进制位上有 k k k个 1 1 1,即区间内满足某一条件的数是多少,用数位 d p dp dp求解
数位 d p dp dp 即是对每一位上的数进行操作,其常与 递归 ( d f s ) (dfs) (dfs) 结合,因为在递归中每次进行的操作都是一样的,刚好满足数位 d p dp dp的要求
接下来,我们详细讲一下数位 d p dp dp下 d f s dfs dfs的模板:
step:
-
首先,对于每一个数位而言,我们要 确定其数的取值范围:
假设我们要求比
N = 12345小且满足某一条件的数的个数,那么对于最高位而言,我们可以选择 [ 0 , 1 ] [0,1] [0,1],因为如果选择的数字大于该位置上的数(如有:2xxxx>12345),则后面不论取多少,这个数一定比 N N N大,已经不满足条件;对于第 2 2 2位上的数而言,我们就需要进行讨论了:
①最高位上为1:则第2位置上只能选择 [ 0 , 2 ] [0,2] [0,2],因为最高位已经抵满,若第二位置上取 > 3 >3 >3,则有
13xxx>12345,一定不满足小于 N N N②最高位上为0:则第2位置上可以选择 [ 0 , 9 ] [0,9] [0,9],为什么呢?因为比第二位置级别更高的位置上,比 N N N 在该位置上的数小,所以之后的位数上任意怎么取,都一定比 N N N小:
12345>0xxxx
其实这就是高位置数上的数对数的大小更能起决定性作用,我们受此启发,便可以得到如下结论:
(1) 如果x前面某一位已经小于对应位置上的上限数字(即 N N N在该位置上的数字),则这一位以及之后的每一位上都可以填入 [0,进位数-1] (如十进制进位数为10,二进制进位数为2)
(2) 如果x前面的每一位都等于对应位置上的上限数字,则这一位上的数的取值范围为 [0,该位置上的上限数]
-
数位 d p dp dp 与 d f s dfs dfs:
因此,我们可以通过 d f s dfs dfs得到所有满足条件的情况数:
定义一个函数:
dfs(pos,pre,flag)- p o s pos pos:表示当前访问的数的位数;
- p r e pre pre:表示 p o s pos pos之前数位上数的状态(如在本题中可以记录 p o s pos pos前有多少个 1 1 1)
- f l a g flag flag:代表是否前面每一位上的数都和对应位置的上限数相同
于是,我们对 N N N由高位向低位进行 d f s dfs dfs深搜:
以本题为例,假设数字 N = 7 = 111 ( 2 ) N=7=111(2) N=7=111(2), k = 2 k=2 k=2
每次如果选择 1 1 1,则
pre+=1,选择 0 0 0则pre不加;又因为 111 111 111的上限数字均为 1 1 1,所以某一位上选了0后,之后的每一位都可以任选 1 / 0 1/0 1/0, f l a g flag flag 标记为 0 0 0; p o s pos pos的值则逐层递减,由此,我们可以得到如下的递归二叉树其中,满足条件时:
pos==0 and pre==k
记忆化搜索:
而 d f s dfs dfs必然少不了 剪枝 操作,因为在递归时,会存在一些重复操作导致效率降低,如图所示,我们不难发现,这两棵子树完全一样,但我们进行了多次计算,所以这也就是数位 d p dp dp与 d f s dfs dfs结合的关键——记忆化搜索
我们还原它的状态,为
01x和10x(x为待定系数),而这两个状态都有一个共同特点,那就是flag==0,由于前面两个位置上的数并不全是上限数字,所以导致第三位置上的数可以任选(之后的位置也可以),也就是 x x x 的情况数是已知的,如:已经记录了状态01x要满足条件有0111 1 1 种情况,则10x要满足条件直接可以判断也只有 1 1 1 种情况101
所以如果对该状态 ( p o s , p r e , f l a g ) (pos,pre,flag) (pos,pre,flag)进行过记录,之后再遇到该状态时,我们就可以直接在当前递归层返回结果,而不需要递归到叶子结点上:

那么为什么一定要是 f l a g = = 0 flag==0 flag==0 的时候才要更新 d p dp dp 数组呢?
其实很简单,如果
flag==1,则该状态一定是唯一的,比如111xxx,难道还能找出flag==1,又有前三位数与它状态相同的数吗,flag==1就已经说明它之前位置上的数都是上限数,状态是确定的;但如果是flag==0,就意味着之后位置上的数可以任选了,而不用在意之前位置上的数具体是多少,反正肯定不全是上限数字,如1110xxx和0011xxx,1110也好,0011也罢,反正都不全是 1 1 1,于是后三位xxx就可以任选,那么这三位选择的方案个数就是确定的啦,所以用 d p dp dp数组记录!
如何实现上述记忆化搜索过程呢?
-
d p dp dp 数组
我们定义 d p dp dp数组:
d p [ p o s ] [ p r e ] = x dp[pos][pre]=x dp[pos][pre]=x,表示在当前数位为 p o s pos pos,且前面已经有 p r e pre pre个 1 1 1时,之后 p o s pos pos位能实现满足条件的选择为 x x x 种
举个例子就懂了:
①
dp[1][1]=1,表示当前数位为1,前面已经有1个1了,那么要满足条件,之后1位有1种选择,可以使该数满足条件,如10x,当前在pos=1,也就是对应 x x x,那么你这时候只要一种选择,就是x=1,才能使pre=k=2,记忆化为1
②
dp[1][0]=0,表示当前数位为1,前面已经有0个1了,若要满足条件,之后1位有0种选择,可以使pre==2,如00x,则不可能满足条件,记忆化为0
所以,如果当前
flag=0,我们就更新此状态下的 d p dp dp 数组,实现记忆化
💯3.代码实现
数位 d p dp dp + d f s dfs dfs实现:
import sys
sys.setrecursionlimit(1000000) # 设置递归深度 10^6
def dfs(pos,pre,flag):
global dp
if pre>k:
return 0
if pos<=0: # 递归结束
return 1 if pre==k else 0 # 如果1的个数等于k 则+1种情况;否则,返回0
if flag==0 and dp[pos][pre]!=-1: # 如果该状态被记录过 (剪枝)
return dp[pos][pre]
max_num=num[pos] if flag else 1 # 得到pos位可选的最大数
res=0
for i in range(0,max_num+1):
res+=dfs(pos-1,pre+i,flag and i==num[pos]) # 如果当前flag==1 并且下一位选择上限数 flag才继续==# 1
if flag==0:
dp[pos][pre]=res # 记录状态
return res
n,k=map(int,input().split())
num=[-1] # 1.用于存放二进制数 2.从低位到高位存 3.首位置不存 以保持位数与下标对齐
while n:
num.append(n&1)
n=n>>1
pos=len(num)-1 # n的二进制位数
# 1.bin(n)[2:]可以知道n最多有60位 2.K最大为50
dp=[[-1]*51 for _ in range(62)]
print(dfs(pos,0,1))
输出结果:

试题J.翻转括号序列⭐️⭐️⭐️⭐️⭐️
🍰1.题目
翻转括号序列

👑2.思路分析
难度:⭐️⭐️⭐️⭐️⭐️
标签:线段树
🎇思路:线段树
🔱思路分析:
这道题用暴力解的…线段树没想出来
step:
-
首先,构造前缀和数组 s u m sum sum
将 ′ ( ′ '(' ′(′ 视为 1 1 1, ′ ) ′ ')' ′)′ 视为 − 1 -1 −1
-
对于区间的查询:
由于满足条件的区间 [ L , R ] [L,R] [L,R]的要求为:
① s u m [ R ] = = s u m [ L − 1 ] sum[R]==sum[L-1] sum[R]==sum[L−1]
② ∀ i ∈ [ L , R ] ∀i∈[L,R] ∀i∈[L,R],有 s u m [ i ] − s u m [ L − 1 ] ≥ 0 sum[i]-sum[L-1]≥0 sum[i]−sum[L−1]≥0
所以,我们找到最长的且满足区间 [ L , R ] [L,R] [L,R]内的前缀和不小于 s u m [ L − 1 ] sum[L-1] sum[L−1]的 R R R,使
sum[R]==sum[L-1]即可
-
对于区间的翻转:
翻转对于数字来说就是取相反数,这里采取的是暴力的方法修改区间上的数
实际上,如果用线段树操作,我们可以用以下方法更快捷地对区间 [ L , R ] [L,R] [L,R]进行翻转:
翻转区间 [ L , R ] [L,R] [L,R] = = == == 先翻转 [ 1 , L − 1 ] [1,L-1] [1,L−1],再翻转 [ 1 , R ] [1,R] [1,R]
为什么要让翻转区间覆盖到 1 1 1呢?
由于前缀和数组是从
1
1
1 开始不断求和的,所以如果左区间为
1
1
1,那么修改区间
[
1
,
x
]
[1,x]
[1,x],相当于让
[
1
,
x
]
[1,x]
[1,x] 的
s
u
m
[
i
]
sum[i]
sum[i] 数组全部变为相反数:sum[i]=-sum[i];而对于
[
x
+
1
,
n
]
[x+1,n]
[x+1,n]的部分,假设翻转前:sum[x]=a,翻转之后:sum[x]=-a,由于对后面的前缀和造成影响的就是
s
u
m
[
x
]
sum[x]
sum[x],而
s
u
m
[
x
]
sum[x]
sum[x] 变化了:
2
s
u
m
[
x
]
=
−
2
a
2sum[x]=-2a
2sum[x]=−2a,所以对
[
x
+
1
,
n
]
[x+1,n]
[x+1,n] 的
s
u
m
[
i
]
sum[i]
sum[i] 数组全部变为:sum[i]+2sum[x] 即可
以 " ( ( ( ) ) ( ) " "(\ (\ (\ )\ )\ (\ )" "( ( ( ) ) ( )"为例,若要翻转区间 [ 3 , 5 ] [3,5] [3,5]:

则可以等效为修改区间 [ 1 , 2 ] [1,2] [1,2] 和区间 [ 1 , 5 ] [1,5] [1,5]:

💯3.代码实现
暴力法实现:(50%)
def query(L):
res=0
for i in range(L,n+1): # 暴力遍历
if sum[i]-sum[L-1]>=0: # 条件1:任意的sum[i]都要满足大于sum[L-1]
if sum[i]==sum[L-1]: # 条件2:sum[i]==sum[L-1],且i最大
res=max(i,res)
else: # 若小于0了,说明右括号多,直接退出
break
return res
def update(L,R):
for i in range(L,n+1):
if i<=R:
a[i]=-a[i]
sum[i]=sum[i-1]+a[i]
n,m=map(int,input().split())
s=input()
a=[0]
for i in s:
if i=='(':
a.append(1)
elif i==')':
a.append(-1)
sum=[0]*(n+1)
for i in range(1,n+1):
sum[i]=sum[i-1]+a[i]
ans=[]
for _ in range(m):
w=list(map(int,input().split()))
if len(w)==2: # 查询最长序列
L=w[1]
R=query(L)
ans.append(R)
elif len(w)==3: # 翻转括号
L,R=w[1],w[2]
update(L,R)
for k in ans:
print(k)
输出结果: