官方概念:副本集是一组 MongoDB 的进程去维持同样的一份数据集,通过 MongoDB 的复制协议保证主备之间的数据一致性。
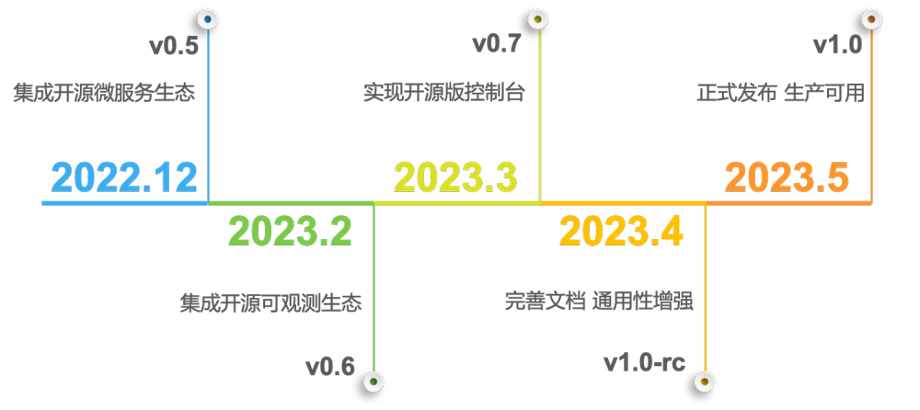
如上图所示,MongoDB 有两种部署方式,一个是 Standalone 部署模式;另外一个是副本集,有不同角色的节点,像 Primary 节点和 Secondary 节点。
生产环境不建议部署 Standalone 模式。
使用副本集的原因
- 可用性:额外的副本结合高可用机制提升 MongoDB 实例的可用性;
- 扩展性:通过 Secondary 节点配合 Driver 扩展 MongoDB 实例的读能力;
- 维护性:通过滚动的方式对 MongoDB 实例进行维护,尽量减少业务所受到的影响,比如版本升级与可能会影响用户流量的 Compact 操作(压缩和优化数据库中的空洞或碎片,以提高数据库性能并减少磁盘空间的使用)
副本集成员角色
副本集里面有多个节点,每个节点拥有不同的职责。在了解成员角色之前,先了解两个重要属性。
- Priority = 0
当 Priority 等于 0 时,它不可以被副本集选举为主节点,Priority 的值越高,则它被选举为主节点的概率更大。 - Vote = 0
不可以参与选举投票,此时该节点的 Priority 也必须为 0,即它也不能被选举为主节点。

成员角色:
- Primary:主节点,可以接受读写,整个副本集某个时刻只有一个;
- Secondary:只读节点,可分为以下三个不同类型:
- Hidden = False:正常的只读节点,是否可选为主节点 & 是否可投票,取决于 Priority & Votes 的值;
- Hidden = True:隐藏节点,对客户端不可见,可以参与选举,但是 Priority 必须为 0,即不能被提升为主节点;
- Delayed Secondary:延迟只读节点,会延迟一定的时间(由 SlaveDelay 配置决定)从上游复制增量,常用于快速回滚
- Arbiter:仲裁节点,只用于参与选举投票,本身不承载任何数据,只作为投票角色
副本集状态查看
- 查看副本集整体状态:rs.status()
可查看各成员当前状态,包括是否健康,是否在全量同步,心跳信息,增量同步信息, 选举信息,上一次的心跳时间等; - 查看当前节点角色:db.isMaster()
除了当前节点角色信息是一个更精简化的信息,也返回整个副本集的成员列表,真正的 Primary 是谁,协议相关的配置信息等,Driver 在首次连接副本集时会发送该命令; - 查看同步进度/oplog信息:rs.printSlaveReplicationInfo()/rs.printReplicationInfo()
第一个命令返回一个汇总的各 Secondary 同步延迟信息,第二个命令返回 Oplog 大小、保留时长、 起始时间等信息。
注意:当用客户端,比如 Mongo Shell,通过 Mongodb Uri 连接副本集实例,来执行例如 Insert,Find,Delete 等命令时,和 Standalone 模式无差异。
ReadPreference(扩展读)
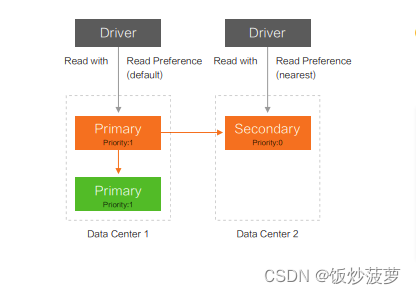
上图为一个三节点的副本集,它部署在两个数据中心,Primary 和其中一个 Secondary 部署在 Data Center 1(上图有误),另一个 Secondary 部署在
Data Center 2。当用默认的 ReadPreference 时,直接读写 Primary 节点;如果在 DataCenter2 也有业务进程存在,也需要读取 MongoDB时,则需要用 ReadPreference 模式自动识别节点的远近,读取 Data Center 2 的 Secondary。
ReadPreference 共有以下五种模式:
- Primary
默认模式,直接读取主节点,更好地保持一致性; - PrimaryPreferred
当主节点不可用时,选择从从节点读取; - Secondary
只从从节点读取; - SecondaryPreferred
尽力从从节点读取,如果找不到可用的从节点,再从主节点读取; - Nearest
根据客户端对节点的 Ping 值判断节点的远近,从而选择最近的节点读取。
Read Preference 决定了读请求会访问什么角色的节点,合理的 ReadPreference 可以极大地扩展副本集的读性能,降低访问延迟。
WriteConcern(写操作持久化)
{ w: value, j: boolean, wtimeout: number }
- w:决定了写操作返回前需要等待多少个副本集节点的确认;
- j:决定了写操作产生的日志是否已经落盘;
- wtimeout:决定了写操作等待的超时时间,避免客户端一直阻塞。
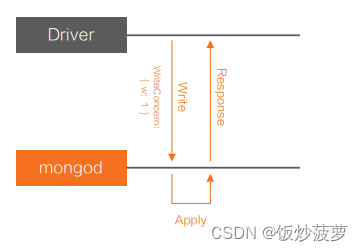
如上图,当 W: 1 时,写操作在本地执行完成后,直接向客户端返回成功,无需等待日志(Journal)刷盘。
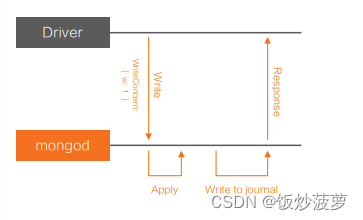
如上图(上图有误),当 W: 1 & J: true 时,区别于 W: 1,写操作在本地执行完成后,还需要等待日志(Journal)刷盘,会增加额外延迟。
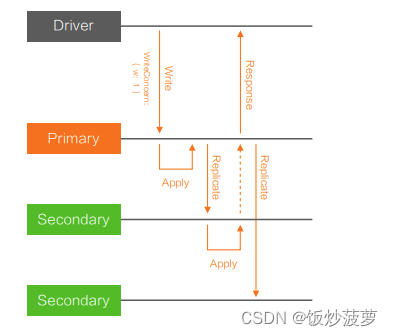
如上图(上图有误),当 W: “Majority” 时,下发这个写操作之后,除了需要在 Primary 节点 Apply 完成,还需要复制到其中一个 Secondary 节点去 Apply 完成,才能向 Driver 反馈写操作成功。在三节点副本集的场景下,Majority 相当于两个节点,等同于 W: 2。
ReadConcern(读操作一致性)
- Local:读操作直接读取本地最新提交的数据,但返回的数据可能被回滚;
- Available:含义和 Local 类似,但是用于 Sharding 场景可能会返回孤儿文档(即不再被任何文档引用的文档);
- Majority:读操作返回已经在大多数节点确认应用完成的数据,返回的数据不会被回滚,但可能会读到历史数据;
- Linearizable:读取最新的数据,并且能够保证数据不会被回滚,即所谓的线性一致性,是最高的一致性级别;
- Snapshot:只用于多文档事务中,和 Majority 语义类似,但会额外提供真正的一致性快照语义
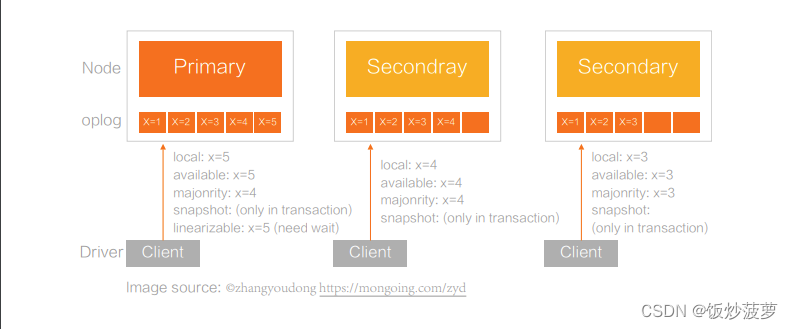
上图为一个三节点副本集,每个 Secondary 节点的复制进度各不相同,用 Oplog 来表示,比如 Primary 最新节点写到 5,第一个 Secondary 节点复制到 4,第二个Secondary 节点复制到 3。
在不同的 ReadConcern 值下,Client 从不同节点读的时候,读到的是不同版本的数据。
对于 Local 来说,总是读取最新的数据,Available 也是读取最新数据,但在分片集群场景下两者不太一样。
在 Majority 情况下,只有 4 是复制到多数节点,也就是其中两个节点。所以当用 Majority 读的时候,在 Primary 上只能读到 4,在第一个 Secondary 上也能读到 4,但在第二个 Secondary 只能读到 3。
Linearizable 也比较特殊,只能在 Primary 节点上使用,因此能读取到 5,但 5 其实并没有复制到多数节点,MongoDB 的解决方法是,当使用 Linearizable 时,在读到 5 之后,会等 5 复制到多数节点,才会向客户端返回成功。
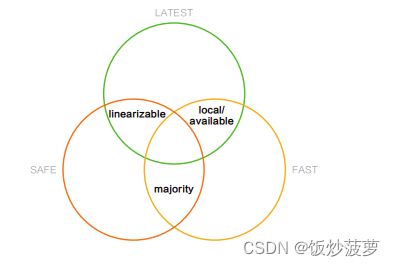
-
LATEST:能读到多新的数据;
-
FAST:能多快地返回数据;
-
SAFE:读的数据是否会发生回滚
-
Local/available:能够最快返回数据,同时读取最新数据,但数据可能会回滚
-
Majority:能够保证 FAST,也就是数据不会被回滚;
-
Linearizable:能够保证数据不被回滚,同时读取最新数据,但牺牲了延迟
ReadConcern Level 越高,一致性保证越好,但相对的访问延迟也更高。
Rollover Compact(维护性操作)
集合频繁的插入和删除会导致"碎片率"上升,浪费存储空间。
在 MongoDB 中,可以使用 compact 命令来进行压缩(Compact)操作,以优化集合所占的存储空间。
- 进入 MongoDB 的 shell 中,选择相应的数据库;
- 切换到需要进行压缩的集合下,使用 compact 命令进行压缩操作:
db.collection.compact(); - 可以使用 stats 命令查看集合的状态信息,包括文档数、存储空间、索引数量等信息:
db.collection.stats() - 注意:进行 compact 操作需要在没有客户端访问集合的情况下才能完成。如果集合正在被读或写,操作会失败并返回错误信息。因此,在进行压缩操作之前,应该先停止对该集合的所有访问,否则可能会导致数据丢失等问题
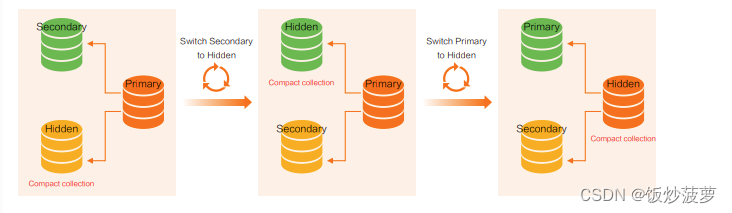
上图为一个三节点副本集,在最左边的副本集中,用户可以在 Hidden 节点完成 Compact Collection 操作。因为 Hidden 对客户端不可见,因而对业务没有影响;当 Hidden 节点操作完成后,可以把 Secondary 节点切换成 Hidden 节点,然后在新的节点上做 Compact Collection 操作(如上图中间部分所示);最后将 Primary 节点也切换成 Hidden 节点(如上图右边所示),最终完成 Compact Collection 操作。
切换节点会对业务产生些许影响,但 Driver 能够自动 Handle,避免直接在 Primary 节点完成 Compact Collection 操作,导致业务对 DB 不可访问。
MongoDB Oplog
MongoDB Oplog 是 Local 库下的一个集合,用来保存写操作所产生的增量日志(类似于 MySQL 中的 Binlog)。
它是一个 Capped Collection,即超出配置的最大值后,会自动删除最老的历史数据,MongoDB 针对 Oplog 的删除有特殊优化,以提升删除效率。
主节点产生新的 Oplog Entry,从节点通过复制 Oplog 并应用来保持和主节点的状态一致。
Oplog 中包含的有:
- O:插入或更新的内容;
- Op:操作类型;
- Ns:操作执行的 DB 和集合;
- Ts:操作发生的时间等
MongoDB 提供 Compact 命令来回收碎片,但会阻塞读写,对业务有影响,在副本集模式下,通过滚动的方式来进行 Compact 操作,避免影响业务(指逐步对集合的碎片进行压缩,每次只压缩一部分,避免一次性压缩整个集合而造成的阻塞)。
具体实现方法大致如下:
- 选定一个较小的时间窗口,比如 1 小时;
- 每次在这个时间段内选择一个分片进行 Compact 操作,操作完成后等待一段时间;
- 重复进行 Compact 操作,选择下一个时间段内的分片进行压缩,直到整个集合中的所有碎片都进行了压缩操作
通过这种方式进行 Compact 操作,可以避免由于一次性压缩占用资源过多而造成的阻塞和影响业务的问题,同时也保证了集合的数据完整性和一致性,并优化了存储、提升了整体性能。
Oplog 保留策略
- 4.4 版本之前
根据 Replication.OplogSizeMB 的配置值来决定 Oplog 集合的大小上限,默认为磁盘空间的 5%。如果是单机多实例的部署形态,需要调整默认值。
当 Oplog 集合大小超过上限时,会自动删除最老的 Oplog Entry。 - 4.4 版本增强了删除策略
MongoDB 提供了按时间段来保留 Oplog,由参数 Storage.OplogMinRetentionHours 来控制,方便更好地完成定期维护的操作。
删除时,即使 Oplog 集合大小超过了配置的最大值,但最老的 Oplog 仍然在 Storage.OplogMinRetentionHours 范围内,那么 Oplog 也不会删除。
MongoDB 提供在线修改 OplogMinRetentionHours 配置值的方式,用户无需重启实例。
// First, show current configured value\
db.getSiblingDB("admin").serverStatus().oplogTruncation.oplogMinRetentionHours
// Modify
db.adminCommand({
"replSetResizeOplog": 1,
"minRetentionHours": 2
})
副本集同步原理
- 全量同步
发生时机:
- 新节点刚加入副本集时;
- 老节点因为同步滞后而进入 Recovering 状态时
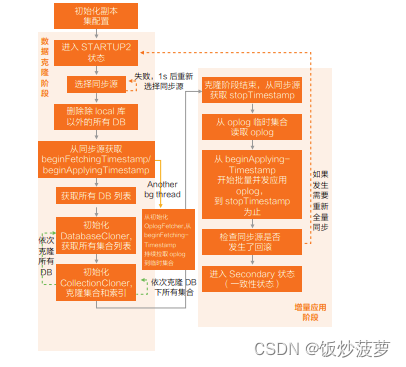
全量同步包含两个阶段:
- 数据克隆阶段:记录开始时间 T1,从源端拉取所有的集合数据,此时不保证数据和源的一致性,记录结束时间 T2;
- 增量应用阶段:应用从 T1 - T2 期间产生的 Oplog,从而达到一致性状态,全量同步结束
全量同步断电续传
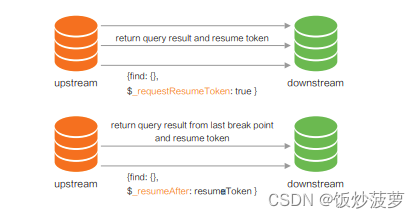
-
4.4 版本之前
全量同步期间,如果发生网络异常,导致同步中断,需要重头开始。当网络环境比较差时,大数据量很难完成全量同步,可用节点数变少,实例可用性存在隐患。 -
4.4 版本优化处理
基于 Resume Token 机制,记录全量拉取的位点,网络异常导致同步中断后,重连时带上 Resume Token。
Replication.initialSyncTransientErrorRetryPeriodSeconds 参数决定了同步中断后重试的超时时间,默认 24h。 -
增量同步
全量同步结束后,持续同步,保持和主节点数据一致。
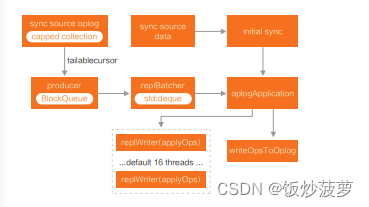
- Oplog Fetcher 线程负责拉取 Oplog Find 命令创建 Tailable Cursor,GetMore 命令批量从同步源拉取 Oplog,单个 Batch 最大 16MB;
- 拉取的 Oplog Batch 放到内存中的 Blocking Queue 中;
- ReplBatcher 线程负责从 Blocking Queue 中取出 Batch 生成新的可 Apply 的 Batch 放到 Deque 中(这里主要是因为需要控制并发,有些操作需要放到一个单独的 Batch);
- OplogApplier 线程负责从 Deque 中取出 Batch 写 Oplog, 然后把 Batch 拆分,分发到 Worker 线程进行并发 Apply;
- 为了保持一致性要求,中间需要保存多个不同的 Oplog 应用位点信息
副本集高可用原理
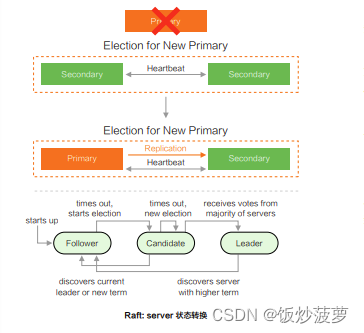
- 主备切换时机:
- 主节点不可用;
- 新增节点(更高的 Priority);
- 主动运维(更换 Primary 节点或修改节点优先级等),rs.stepDown() or rs.reconfig()
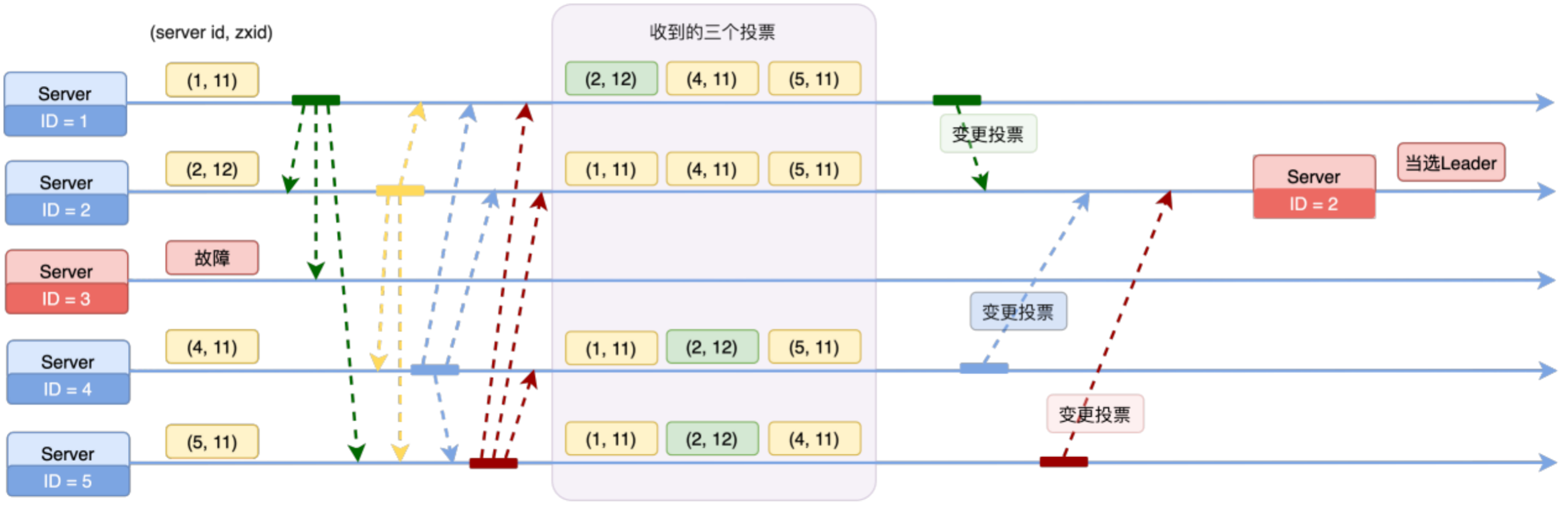
- MongoDB 基于 Raft 协议实现了自己的高可用机制;
- 副本集之间保持心跳(默认 2 秒探测一次);
- 如果超出 ElectionTimeoutMillis(默认 10 秒)没有探测到主节点,Secondary 节点将会发起选举,发起前检查自身条件:
- Priority 是否大于 0;
- 当前状态是否足够最新;
- 在真正选举前,会先进行一轮空投(Dry-Run),避免当前 Primary 无意义的降级(StepDown),因为 Primary 收到其他节点且 Term 更高的话则会降级(Term 可以理解为选票);
- Dry-Run 成功后,会增加自身的 Term 发起真正的选举,如果收到多数选票则选举成功,把新的拓扑信息通过心跳广播到整个副本
小结
- 副本集是可用性、扩展性、维护性的有效保证。中等业务规模、生产环境建议优先选择部署该形态;如果是大型业务规模,建议使用 Sharing 形态;
- 副本集使用务必使用高可用连接串的方式,避免业务访问单点;
- 默认情况下的 Read/Write Concern 可以满足绝大部分的业务需求,特殊情况需要在一致性和性能之间做出取舍;
- Oplog 是 MongoDB 的重要基础设施,除了用于同步(全量 + 增量),还可用于构建数据生态(ChangeStream);
- MongoDB 以 Raft 协议为指导实现了自己的高可用机制,大部分情况下,主节点故障 15 秒内即可选出新的主节点;
Raft 协议是一种分布式一致性算法,用于维护一个在多个节点之间复制的状态机。
Raft 协议的主要思想是将领导者选举和日志复制机制分开,将分布式系统的复杂性分解为两个相对独立的子问题。在具体实现中,Raft 协议将分布式系统的节点划分为三个角色:领导者(Leader)、跟随者(Follower)和候选人(Candidate)。当正常运行的领导者节点失效时,其他候选人会发起新一轮的选举,并通过互相投票来选出新的领导者节点。
通过领导者选举,Raft 确保了系统中只有一个节点拥有写入权限,从而避免出现数据写入冲突的问题。
同时,Raft 协议通过日志复制机制来确保数据在多个节点之间的一致性。具体实现中,一个节点会记录自己的日志,当其成为领导者后,会将新的日志条目追加到自己的日志末尾,并将日志的更新情况广播给其他节点。其他节点在收到并确认了这些更新之后,也会将这些日志条目复制到自己的日志记录中,从而确保节点之间的数据一致性。
在实际应用中,Raft 协议被广泛应用于各种分布式系统中,例如 Etcd、Consul、CockroachDB、TiDB 和 MongoDB 等,用于实现分布式系统的数据复制、切换和容错机制等。
参考资料
- 玩转 MongoDB 从入门到实战