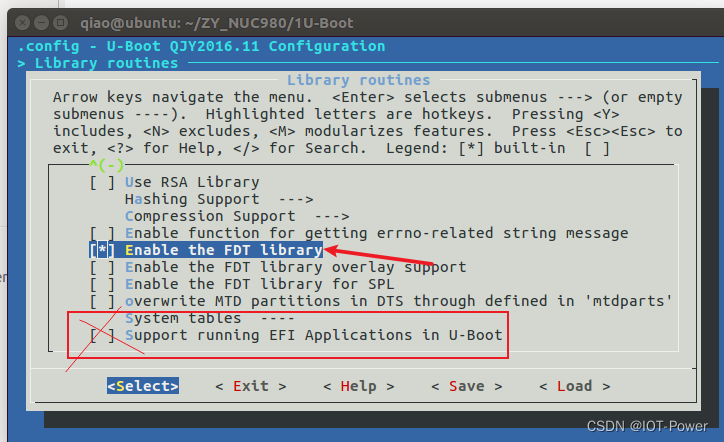
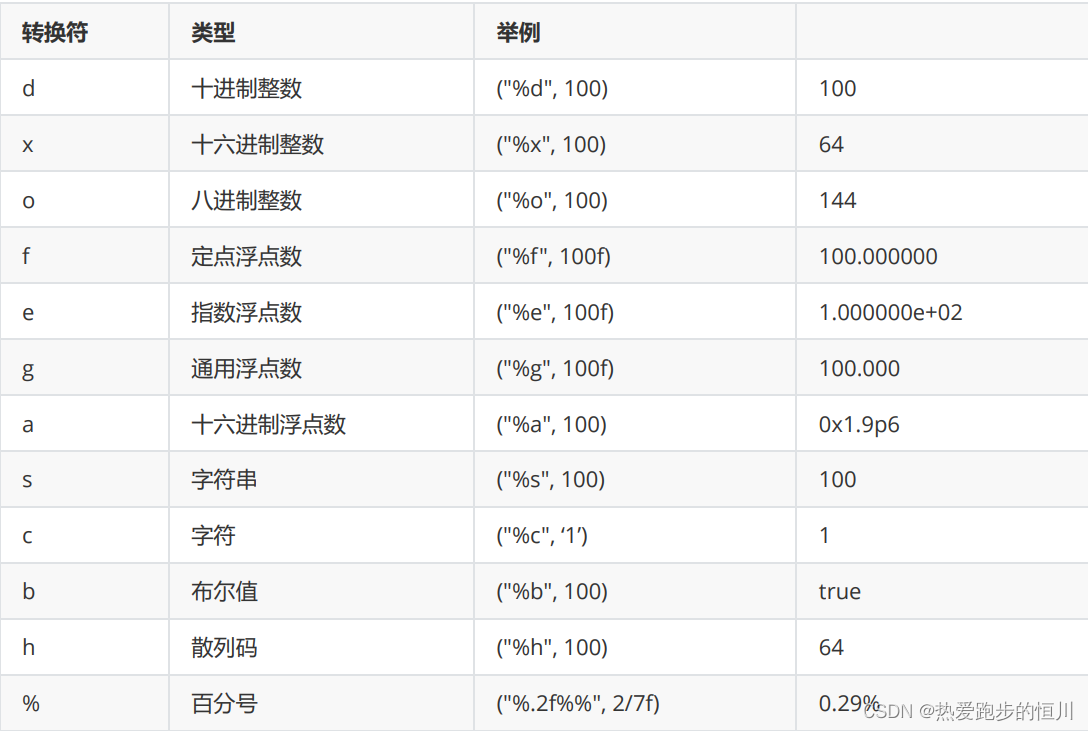
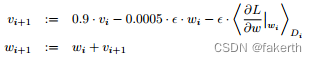目录
- 理论
- 框架
- text-to-imgae
- decoder
- generation model
- clip的原理
- FID指标:评估图像生成的好坏
- 数学原理
理论
框架
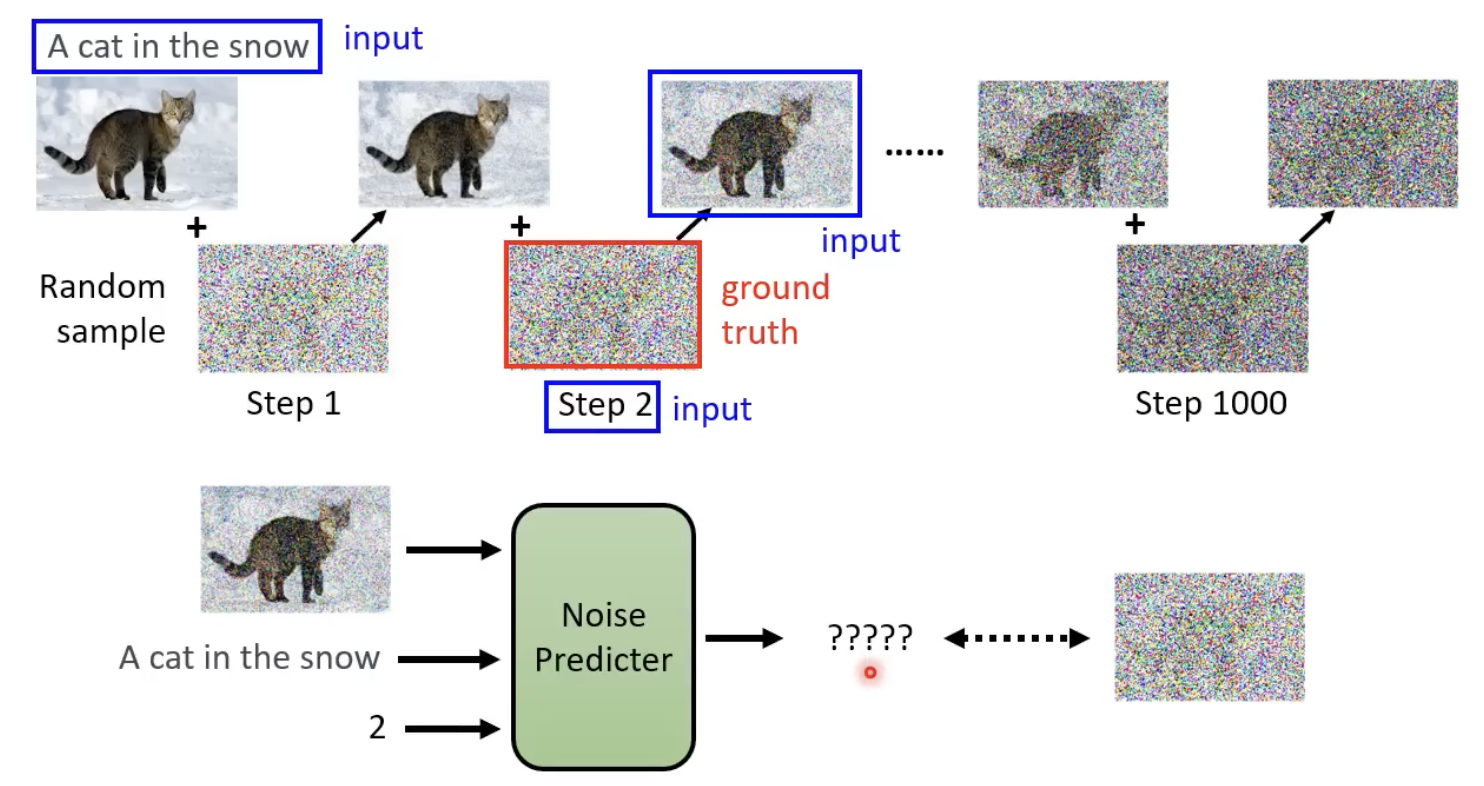
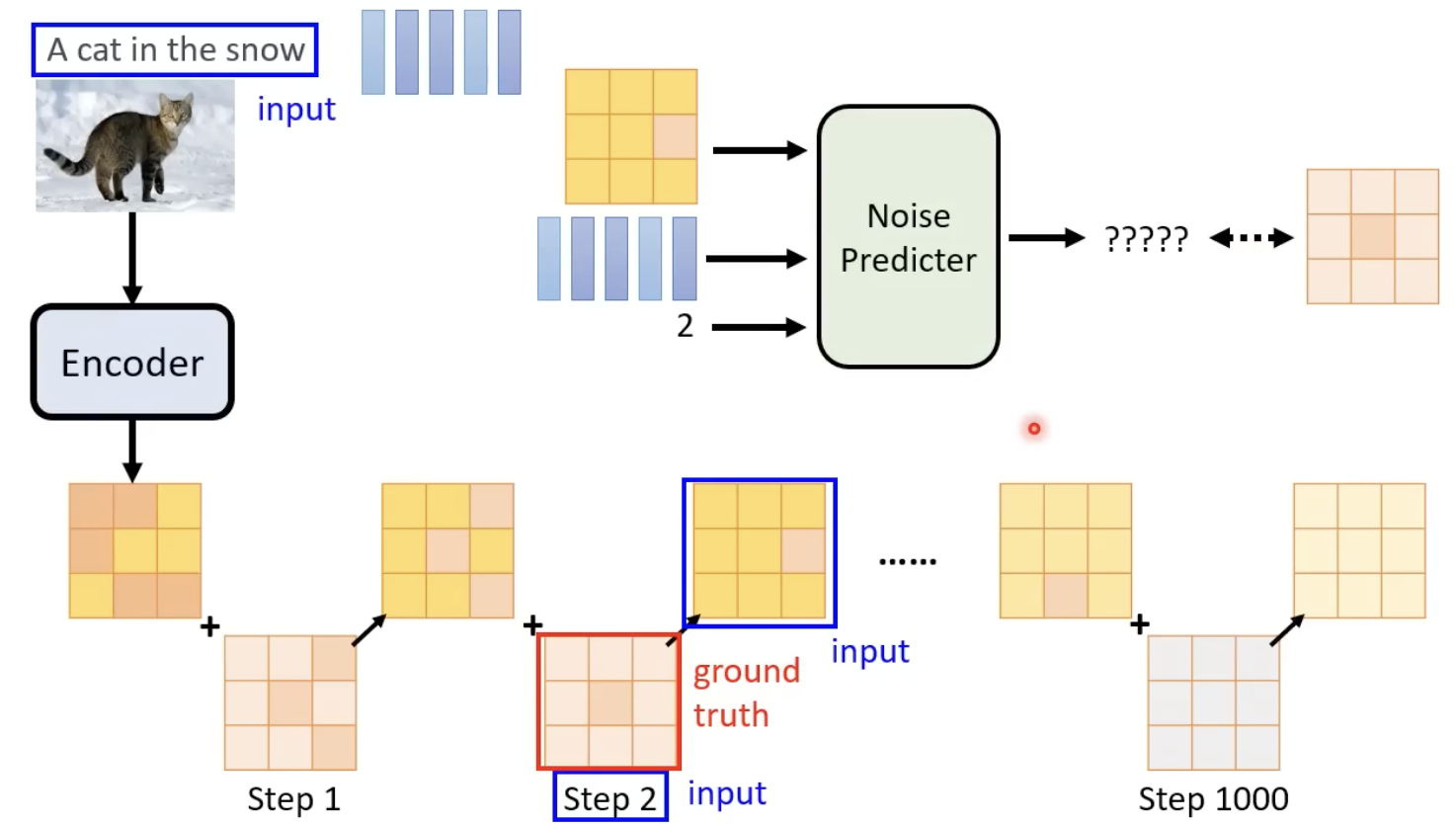
不断的进行去噪,并且在这个过程中,step也作为“去噪模型(其实就是扩散模型)”的输入:
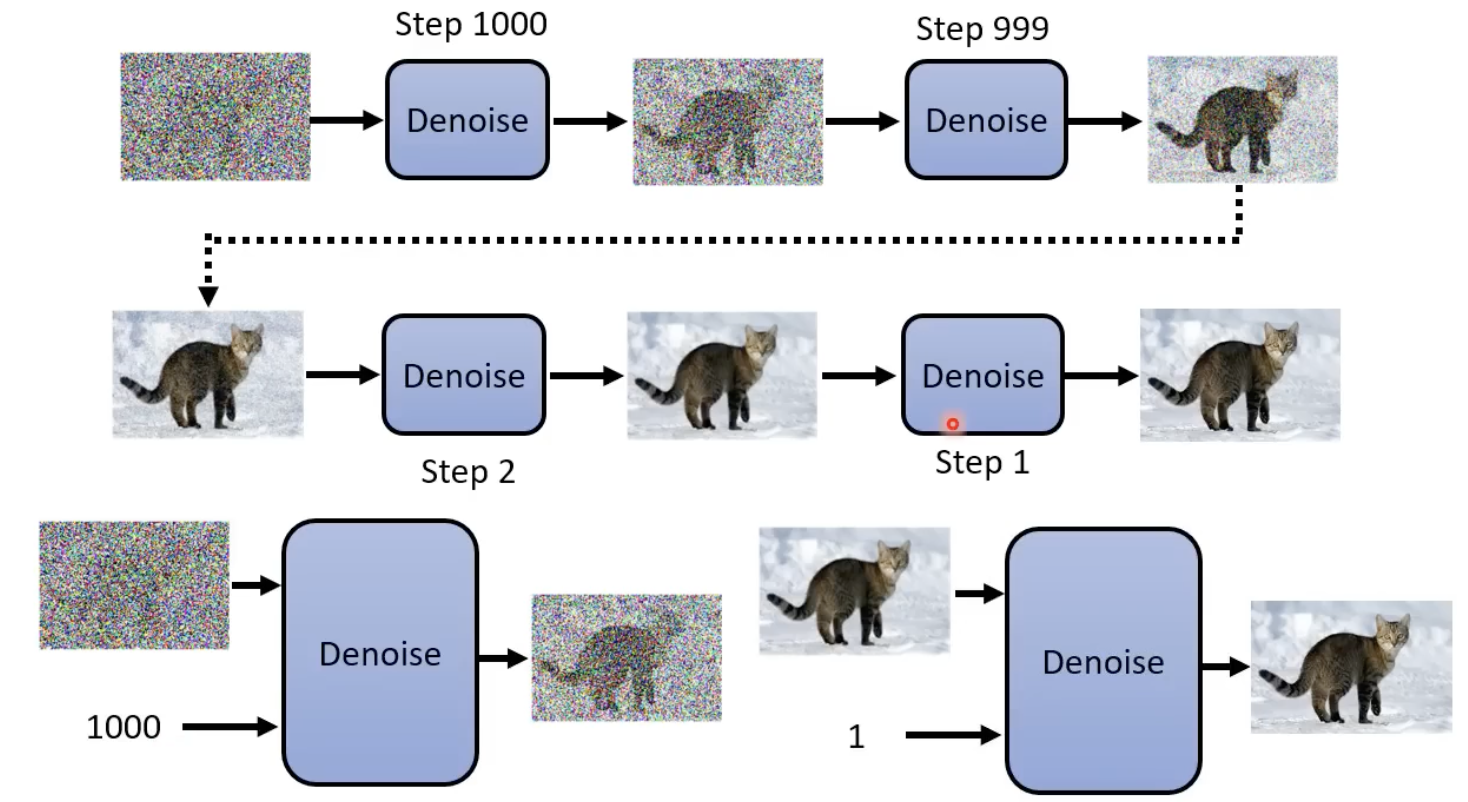
denoise 模型的内部结构长这样下图这样,他能够产生一张噪声,然后原始图像减去这个噪声,就能够得到更清楚的图像(去噪后的图像)了:
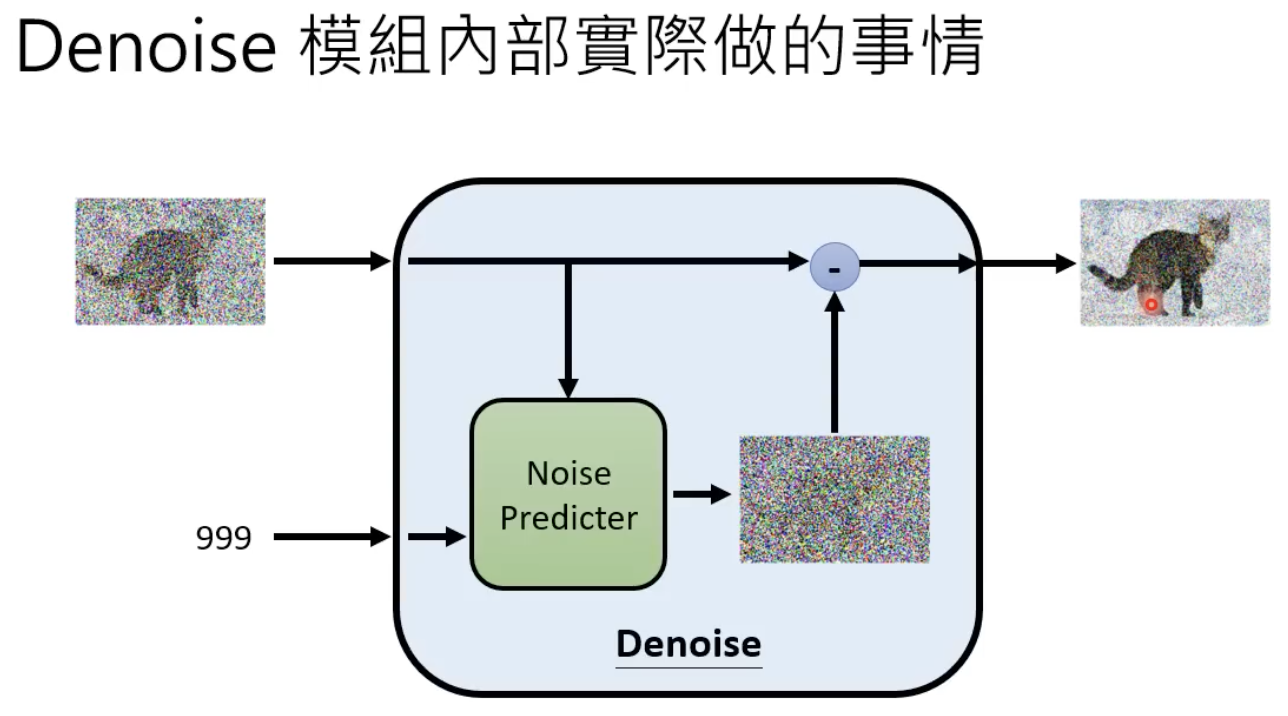
为什么denoise 模型不直接对图片进行去噪,而是其内部的 noise predicator产生一个噪声图片?因为难度不一样,产生一张噪声要容易得多。
既然要其生成的是一张噪声,那么也需要有ground truth 的噪声,来进行该模型的训练:
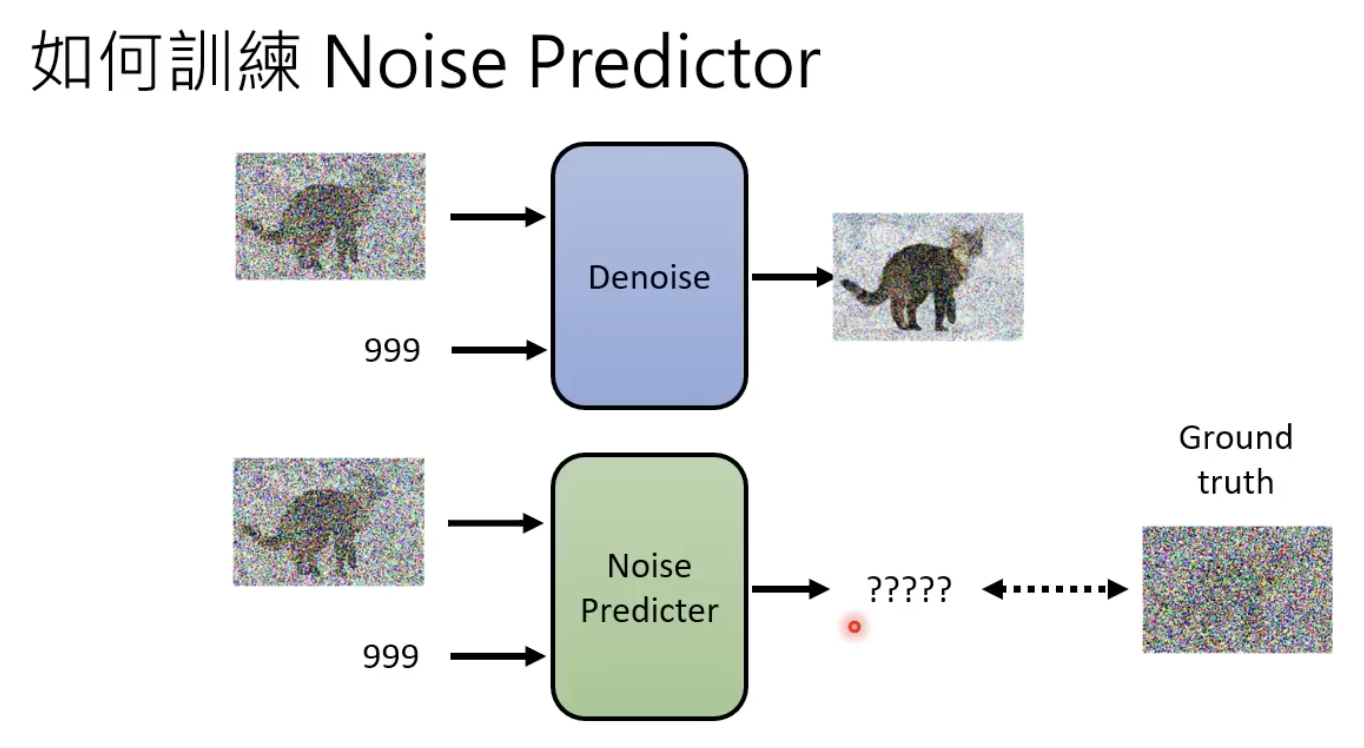
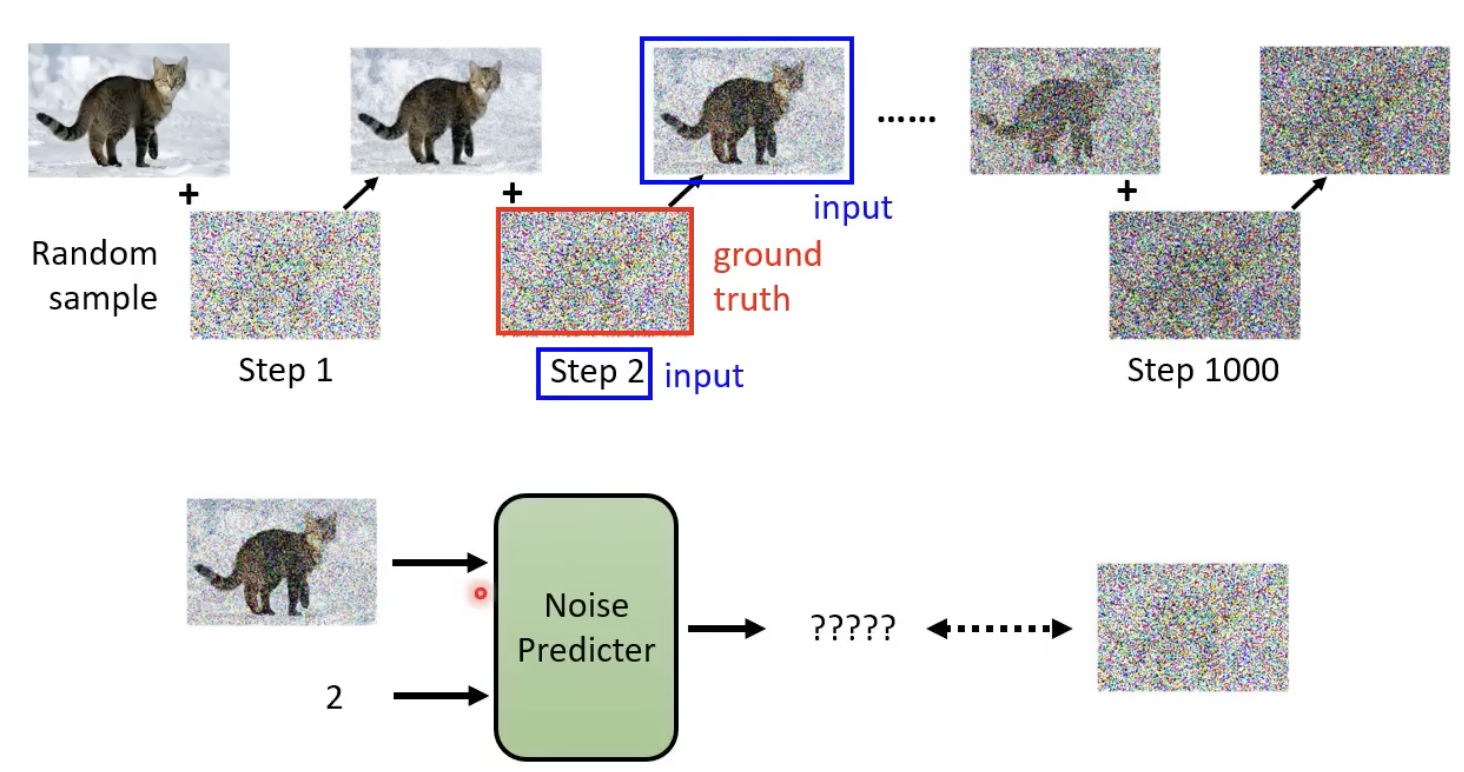
每一步的噪声的 ground truth 怎么来?——先加噪,然后记录下每个step所添加的噪声就是ground truth:
text-to-imgae
如果是这类模型,则每次noise predictor还需要添加一样的文字。
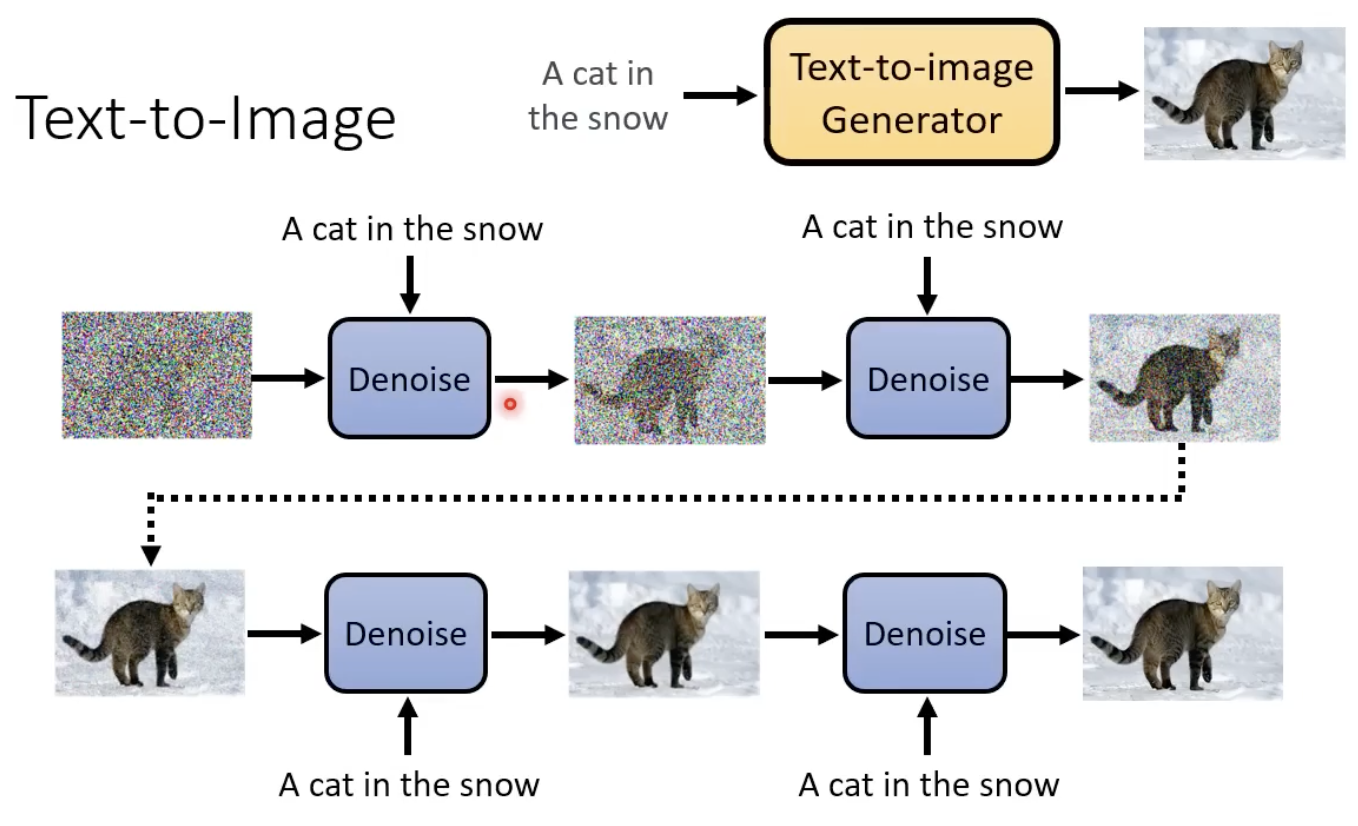
text-image DM模型的整体框架,需要依赖encoder、decoder等:
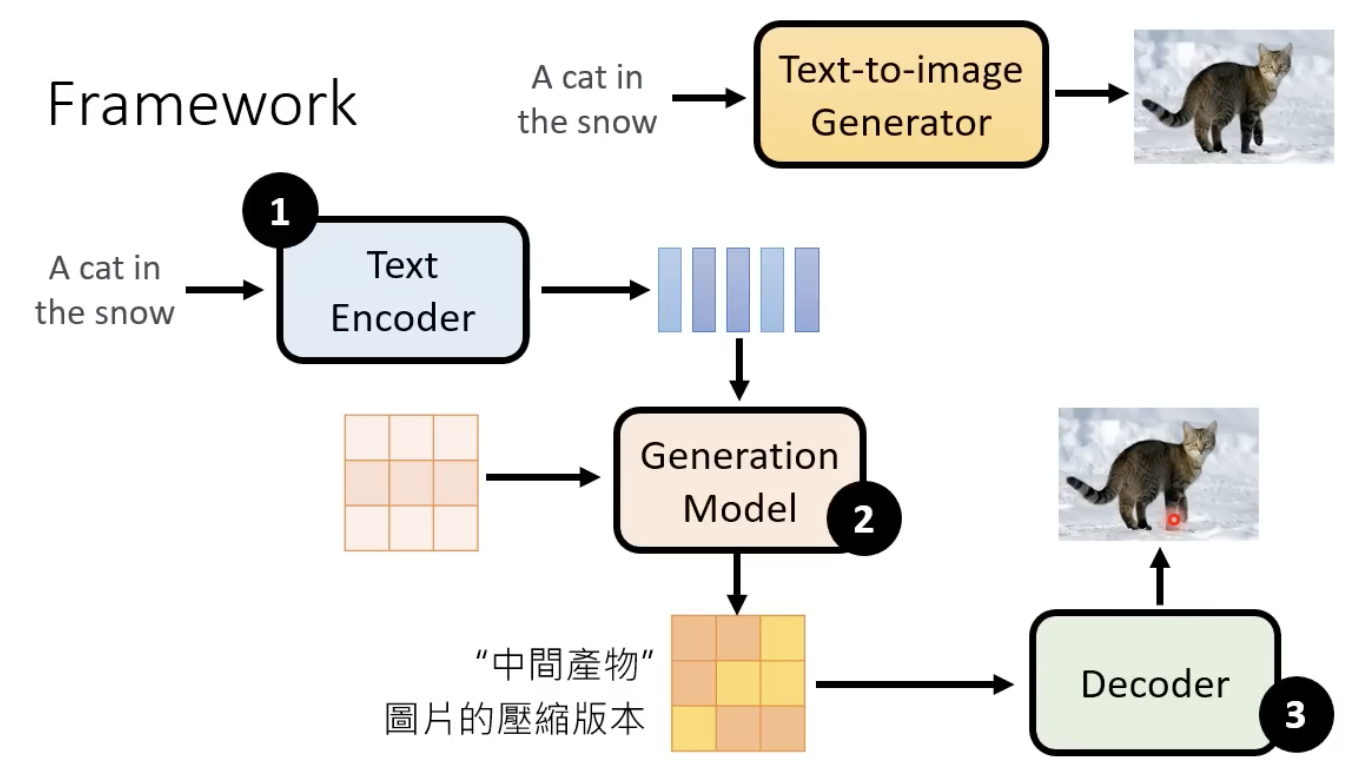
下面介绍encder、generation model、decoder,已经它们分别是怎么训练的。
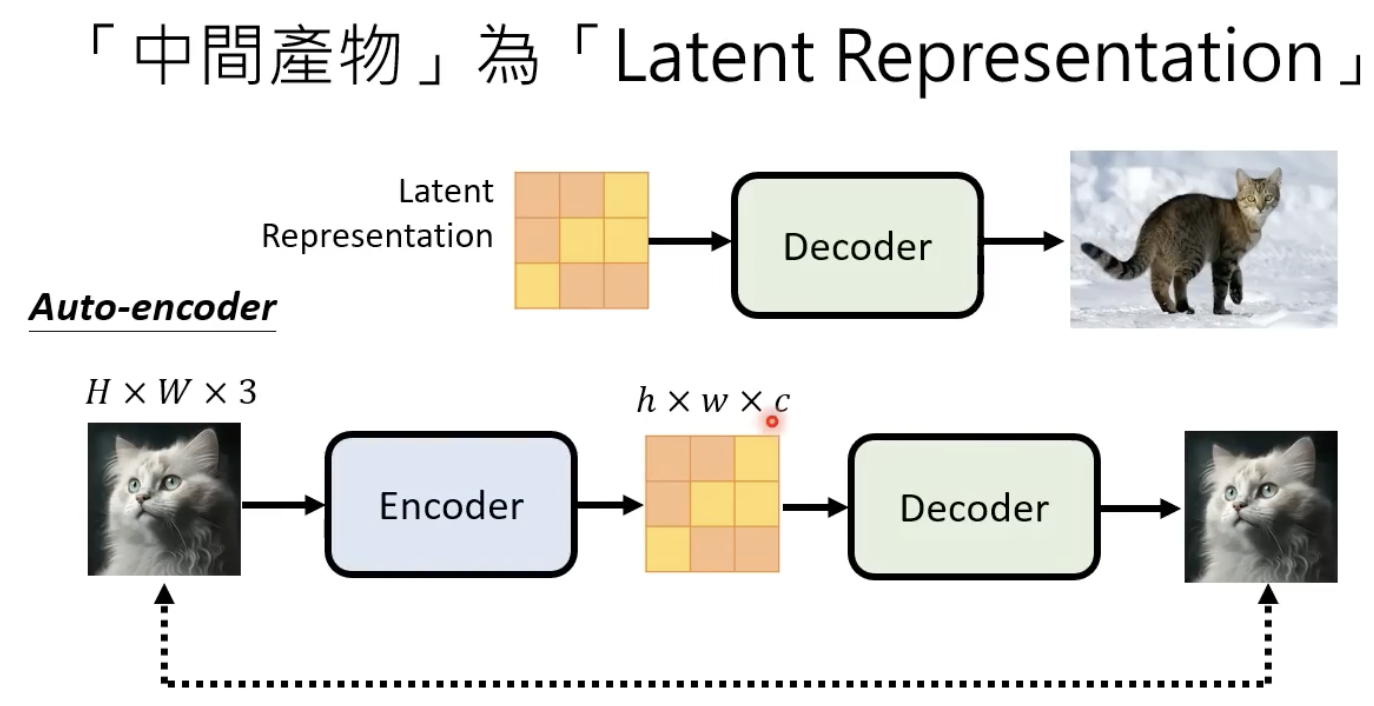
decoder
decoder的训练方法比较简单,中间一个缩小后的图片,然后用AE的训练方式即可。
generation model
generation model这里就类似扩散模型。
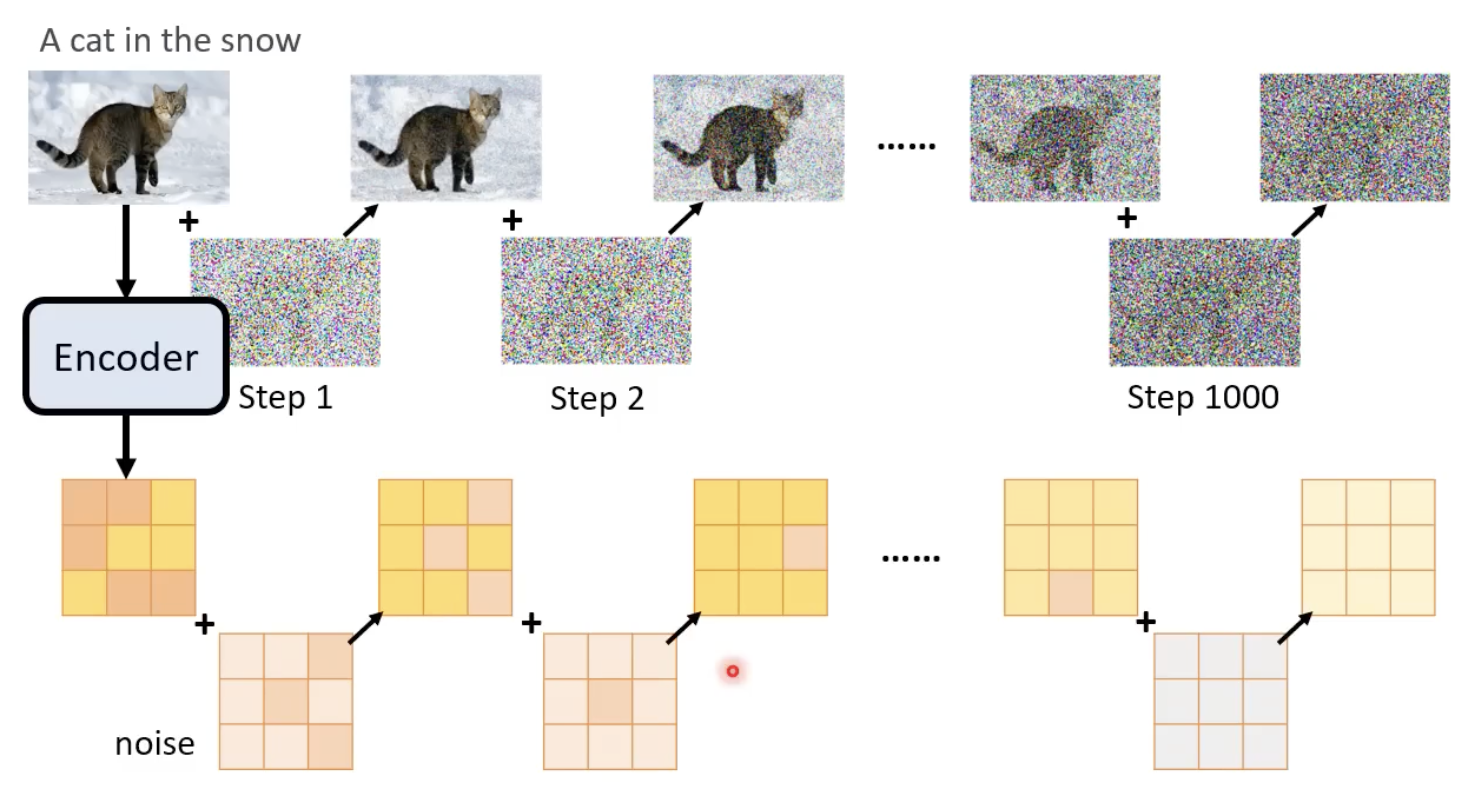
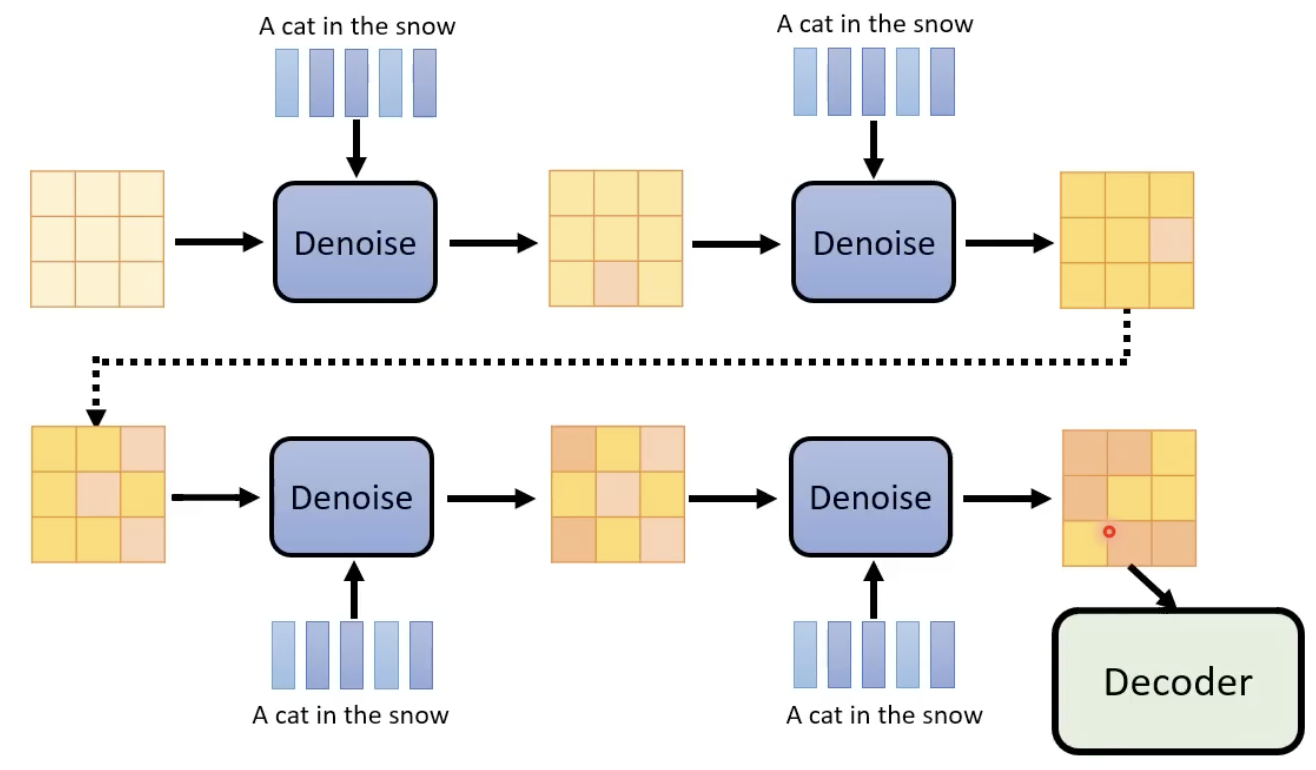
在每一个step中,noise predictor的输入是图像的representation、文字的represenation、当前step。输出得到该step添加的噪声。
经历若干个去噪步骤,再输入到decoder,基本就可以得到生成的大图了。
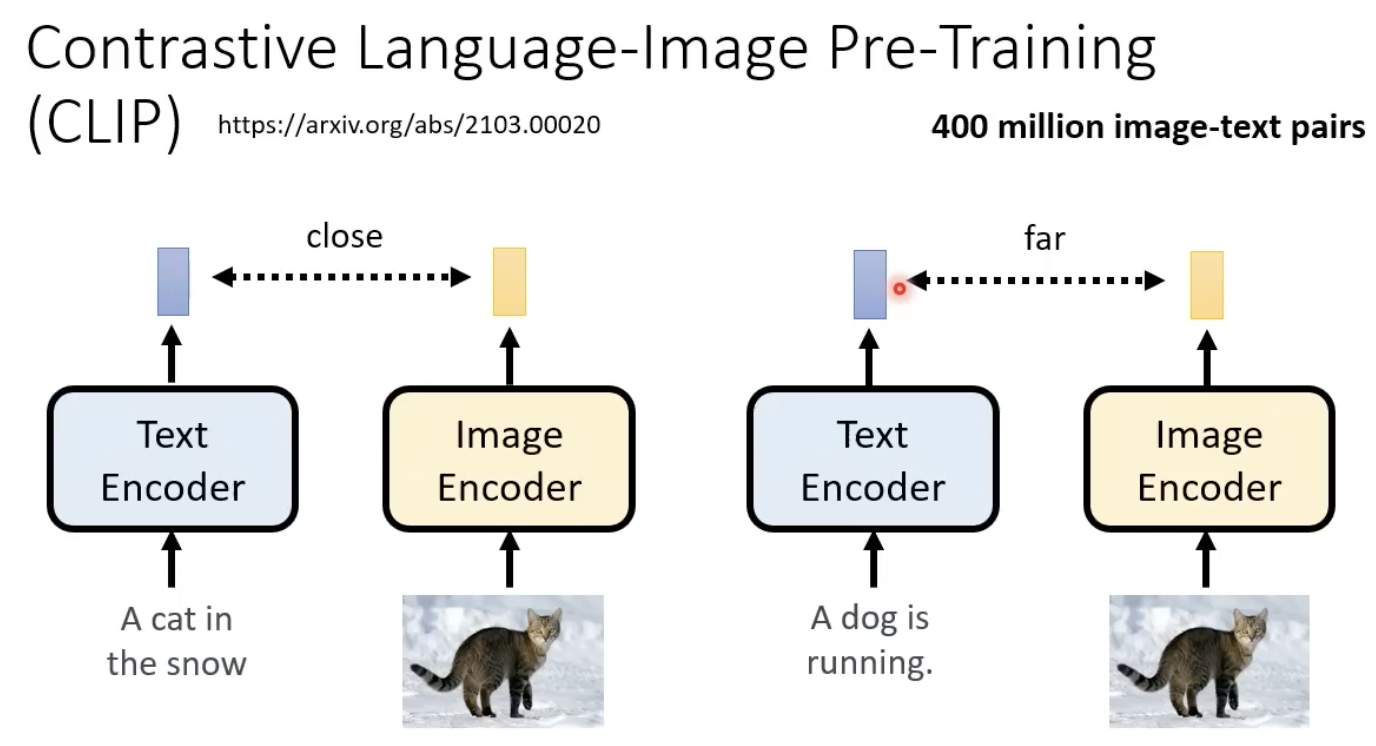
clip的原理
让两个encoder输出的向量相近:
FID指标:评估图像生成的好坏
依赖一个retrain好的CNN模型,输入一个生成的图片,得到representation,然后比较和真实影像的representation的进行比较:
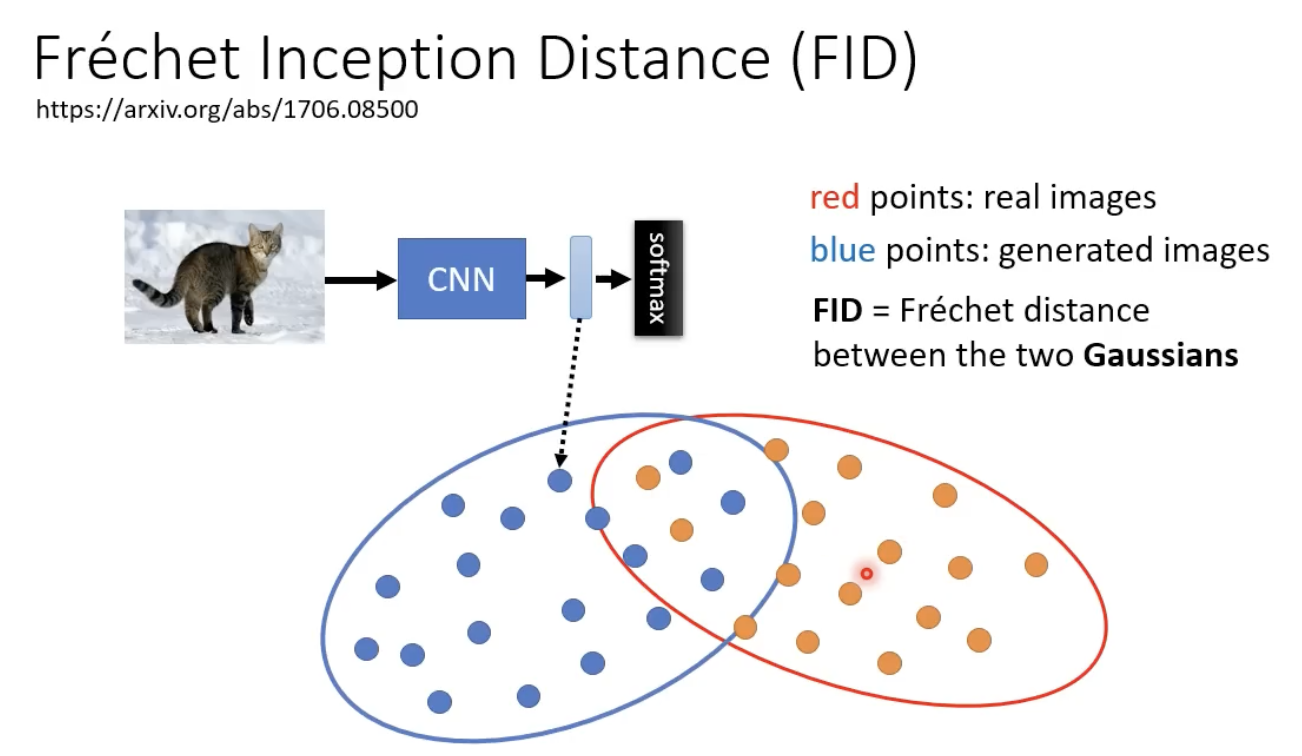
两个分布(假设是高斯分布)越接近越好。
数学原理
先区分下VAE和扩散模型的区别:
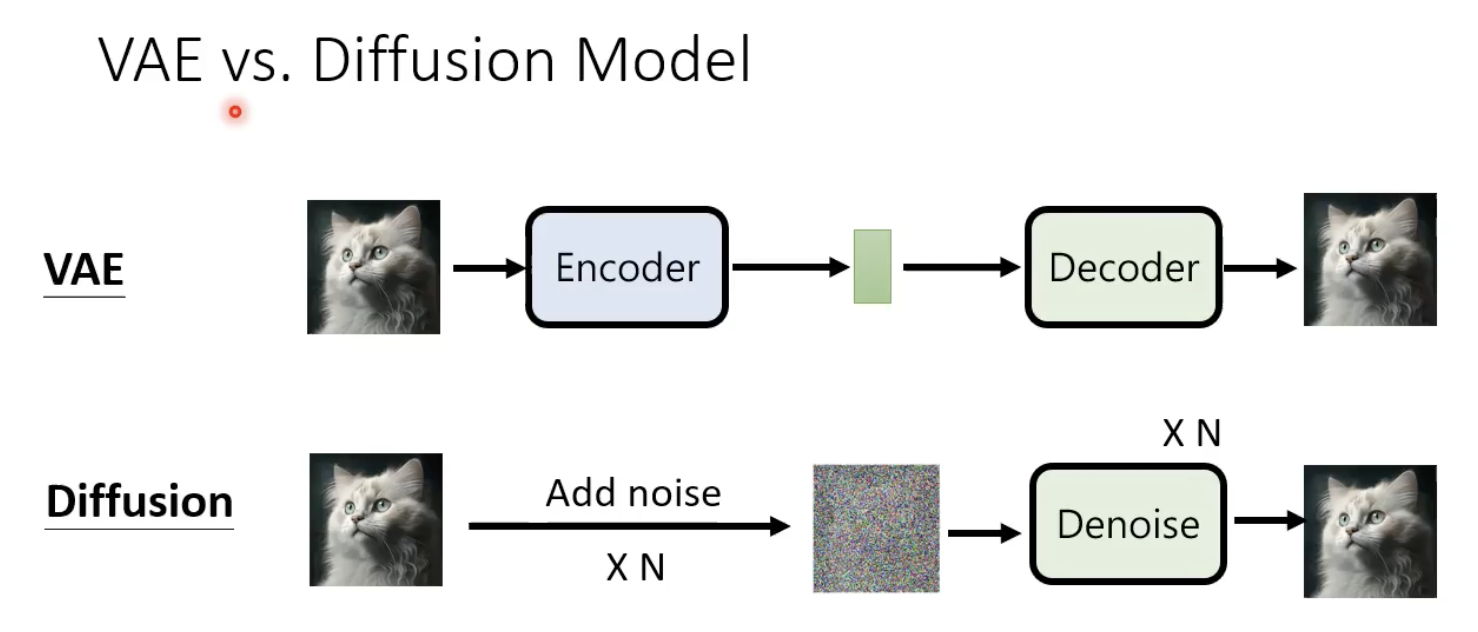
扩散模型加噪的过程中,不需要训练一个encoder。
算法如下:

红色框框做的是把原始图像和噪声进行加权相加,