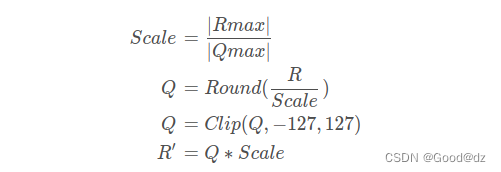BERT相关面试题(不定期更新) - 知乎 (zhihu.com)
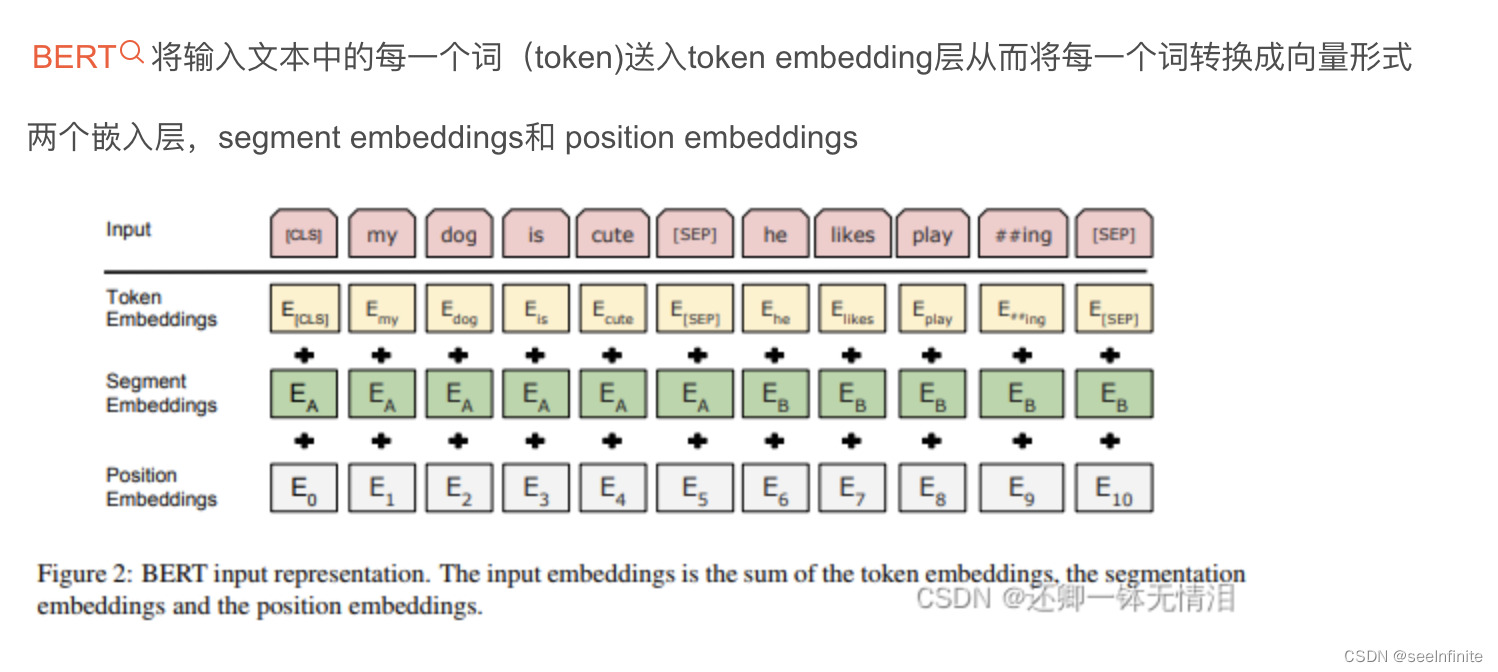
Bert输入
3个输入:
1. token embedding
token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示
两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内
2. segment embedding
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0
3. position Embedding
Transformers无法编码输入的序列的顺序性,加入position embeddings会让BERT理解下面下面这种情况, I think, therefore I am,第一个 “I” 和第二个 “I”应该有着不同的向量表示
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置
使用BERT时,输入的最大长度为什么不能超过512?
因为BERT模型的位置向量采用绝对位置向量,通过训练得到训练得到的,在模型训练时,只训练了512个位置向量,所以模型的最大输入长度为512。为什么不不训练更多的位置向量,因为复杂度的问题,self-attention计算时的复杂度为O(seq^2,d),其中 seq为句子长度, d为向量的维度。句子变长,计算量急剧增加。
如何优化BERT性能
1 压缩层数,然后蒸馏,直接复用12层bert的前4层或者前6层,效果能和12层基本持平,如果不蒸馏会差一些。
2 双塔模型(短文本匹配任务),将bert作为一个encoder,输入query编码成向量,输入title编码成向量,最后加一个DNN网络计算打分即可。离线缓存编码后的向量,在线计算只需要计算DNN网络。
3 int8预估,在保证模型精度的前提下,将Float32的模型转换成Int8的模型。
Bert本身在模型和方法角度有什么创新呢?
预训练两个很重要:目标函数和训练数据
任务一:Masked LM(掩码的语言模型)
而Masked语言模型上面讲了,本质思想其实是CBOW,但是细节方面有改进。
mask(词语级别增强)CBOW类似
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。
但是这里有个问题:微调的时候没有[MASK]这个标签会导致微调和预训练的不匹配
为了避免这个问题,Bert改造了一下:
- 15%的被上天选中要执行[mask]替身这项光荣任务的单词中:
- 只有80%真正被替换成[mask]标记
- 10%被狸猫换太子随机替换成另外一个单词
- 10%情况这个单词还待在原地不做改动。
那么为啥要以一定的概率使用随机词呢?
这是因为transformer要`保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"`。
至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
任务二:Next Sentence Prediction
做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的`预训练是个多任务过程`。
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在[CLS]符号中。
Masked Language Model这个任务有哪些缺点,如何改进?
问题:
最大的缺点在于Bert中随机mask 15%的语料这个事情 在不同的epoch是固定的。那么极有可能有些单词因为被mask掉了而在训练过程中没有见过,导致微调阶段的语料分布和训练阶段的语料分布不相同。
改进方式1:参考roberta的动态mask,也就是不同epoch随机mask的15%是不同的,这样就可以保证微调阶段和训练阶段的语料分布相差不大了,代价当然是速度会稍微慢一点。
改进方式2: 参考XLNet的单向训练。利用乱序语言模型可以将auto-encoding模型转化成auto-regressive模型。这样就可以抛弃MASK这个token了。当然能保证随便打乱顺序的原因还在于bert的输入还有position-embeding 位置编码。
改进方式3: 中文的全词覆盖。中文环境下,原始bert是只mask一个字的,如果改成全词覆盖,任务难度和精准度会提升。
学习率warm-up策略
针对学习率的一种优化方式,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
原因:
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
BERT的一些改进
Albert
- Factorized Embedding Parameterization,矩阵分解降低embedding参数量。
- Cross-layer Parameter Sharing,不同层之间共享参数。
- Sentence Order Prediction(SOP),next sentence任务的负样本增强。
个人感觉降低参数量相对于优化效果以及计算速度来说,并不是特别重要。
Roberta
Bert/Albert/Roberta系列论文阅读对比笔记 - 知乎 (zhihu.com)
与bert比较:
- 训练从静态掩码转变为动态掩码
- 去掉NSP(下一个句子预测)任务模型的表现是提升了的。并且只采用同一文章的句子做序列输入效果优于混杂不同文章
- 增大批数据的规模通常有利于模型的收敛速度和下游表现。BERT里以256个序列输入作为一批预训练数据,RoBERTa将这个数字扩大到了8000个序列输入,并且观测到了同样的提升效果
- 训练数据的多元,于是采用了和GPT2一样的字节级别的BPE分词方式。该编码方式虽然使模型表现略微下降,但显著减少了未登陆词。故仍受到采用。
XLM
(177条消息) 文献阅读笔记:Cross-lingual Language Model Pretraining_JasonLiu1919的博客-CSDN博客
两种学习跨语言语言模型(XLM)的方法:一种是无监督方式,只依赖于单语言数据;另一种是监督,在平行语料数据上利用一个新的跨语言语言模型目标函数。我们获得了关于跨语言分类(cross-lingual classification)
将并行的翻译句子拼接起来,在source 句子和 target 句子中都随机mask掉words。当要预测英文句子中被masked的word时,该模型不仅能够注意到英文words还能够注意到法语的翻译内容。这就引导模型将英语和法语的表征进行对齐。特别地,该模型在英文句子不足以推断出被masked的英文单词时,能够利用法语上下文信息。为了方便对齐,在target句子部分,位置编码需要重置。
Turing V5
Electra: ELECTRA: 超越BERT, 19年最佳NLP预训练模型 - 知乎 (zhihu.com)
把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
生成器和鉴别器任务
- 生成器:对mask词进行预测,如果预测为原词,则是正例,否则为负例
- 鉴别器:序列标注任务,对每个词判断是否被替换过
与传统bert训练目标不同的是,不止专注于mask词,而是对出现的词都进行了loss计算,这可能是这样训练方式效果好的原因
训练细节:
生成器的训练目标还是MLM,判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器,目标函数如下:
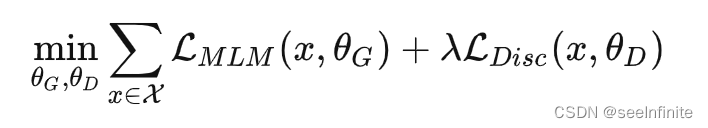
因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。
另外要注意的一点是,在优化判别器时计算了所有token上的loss,而以往计算BERT的MLM loss时会忽略没被mask的token。作者在后来的实验中也验证了在所有token上进行loss计算会提升效率和效果。
GPT
预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎 (zhihu.com)