今天做了一个从list的内容取出一个与指定内容尽可能相似的内容,做完之后抽个几分钟记录下
difflib的作用
比对2个文件的差异.
使用的时候直接 import difflib 即可
get_close_matches 作用
匹配最大相似的内容返回结果
list1 = ["abc", "acd", "adf", "bcd", "buff"]
str1 = "abc"
result = difflib.get_close_matches(str1, list1)
print(result)打印结果:
['abc', 'bcd', 'acd']
difflib里面还有一些其他的函数如下
context_diff 的作用
返回一个差异文本行,由于返回的是一个list看不到内容,下面的转成了string
import difflib
text1 = "abc"
text2 = "bcde"
res1 = difflib.context_diff(text1, text2)
print("".join(res1))打印结果
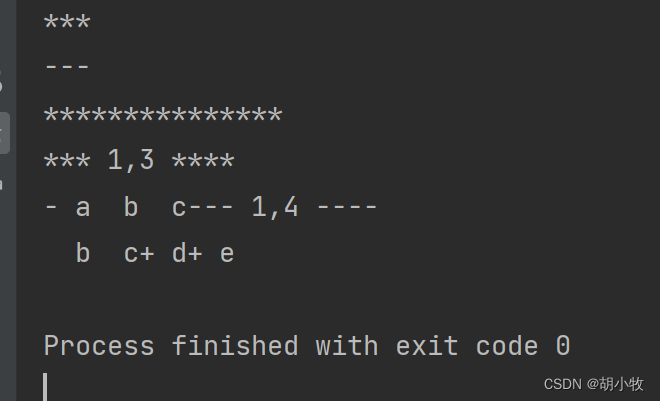
ndiff的作用
返回2个文件的差异点
import difflib
text1 = "abc"
text2 = "bcde"
res1 = difflib.ndiff(text1, text2)
print("".join(res1))
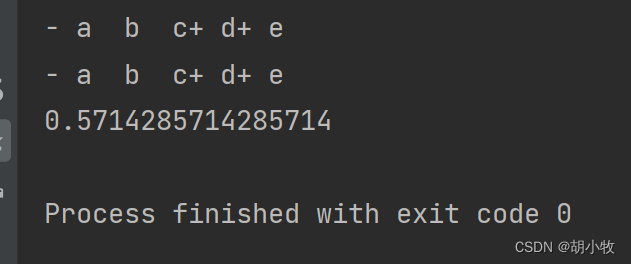
可能看到- 和+ 感觉有点蒙,不用慌,他们的作用在下面
| 符号 | 含义 |
|---|---|
| ‘-’ | 包含在第一个系列行中,但不包含第二个。 |
| ‘+’ | 包含在第二个系列行中,但不包含第一个。 |
| ’ ’ | 两个系列行一致。 |
| ‘?’ | 存在增量差异。 |
| ‘^’ | 存在差异字符。 |
对比这个就能明白-a 表示text1中有,text2 中没有, +d,+e 表示text2中有text1中没有
ndiff 和difflib的compare作用是一样的
下面说下difflib.Differ()的compare方法
difflib的Differ 的使用
import difflib
text1 = "abc"
text2 = "bcde"
res1 = difflib.ndiff(text1, text2)
print("".join(res1))
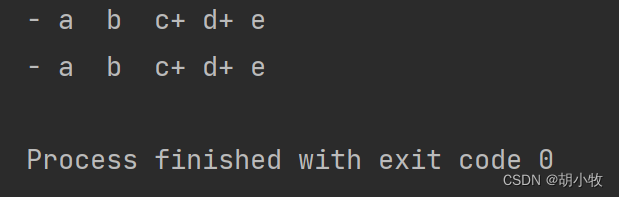
d = difflib.Differ()
result = d.compare(text1, text2)
print("".join(result))打印结果
difflib的HtmlDiff方法
import difflib
text1 = "abc"
text2 = "bcde"
res1 = difflib.ndiff(text1, text2)
print("".join(res1))
# Differ 比较差异
d = difflib.Differ()
result = d.compare(text1, text2)
print("".join(result))
# HtmlDiff 统计差异
d1 = difflib.HtmlDiff()
res2 = d1.make_file(text1, text2)
# 把比对结果写入到html中
with open("diff.html", "w") as f:
f.write(res2)在代码的同目录下找到diff.html 用浏览器代码

很明显的就能看到差异了
difflib的SequenceMatcher 方法
import difflib
text1 = "abc"
text2 = "bcde"
res1 = difflib.ndiff(text1, text2)
print("".join(res1))
# Differ 比较差异
d = difflib.Differ()
result = d.compare(text1, text2)
print("".join(result))
# HtmlDiff 统计差异
d1 = difflib.HtmlDiff()
res2 = d1.make_file(text1, text2)
# 把比对结果写入到html中
with open("diff.html", "w") as f:
f.write(res2)
# 2个文件的相似对
res3 = difflib.SequenceMatcher(None, text1, text2).quick_ratio()
print(res3)
打印结果