前言
在大量的并发任务中,频繁的创建和销毁线程对系统的开销是非常大的,多个任务执行的速度也是非常慢的。因此,设计出一个好的 Java 线程池就可以减少系统的开销、使程序运行速度提升。在这篇博文中,我将介绍 Java 线程池概念以及使用方法的详解。
目录
1. 什么是 Java 线程池?
2. Java标准库中的线程池
2.1 工厂模式
2.2 创建线程池的方式
3. ThreadPoolExecutor类
3.1 线程池的拒绝策略
4. 模拟实现线程池

1. 什么是 Java 线程池?
线程池是一种管理和重用线程的机制。使用线程池可以减少创建线程的数量,提高程序效率,并且允许任务在处理非常忙碌的时候等待处理。
首先,我们要知道一点,虽然线程的创建相对于进程来说是微不足道的,但频繁的创建线程对系统的开销也是不小的。因此,我们可以设计一个线程池来缓解这个开销。
在 Java 中创建一个线程池,这样我们后续在创建线程时,直接在这个线程池里面拿,线程不用了也是还给这个线程池即可。从线程池里面拿线程比从系统中创建线程高效性其原因为:
- 从线程池拿线程,相当于用户态操作
- 从系统中创建线程,涉及到用户态和内核态之间的切换,真正的创建是在内核态完成的
解释用户态、内核态:
用户态与内核态是操作系统的基本概念,一个操作系统等于 内核 + 应用程序。在 Java 中编写一句 println("hello") 这个操作 应用程序 会告诉 内核 :“我要进行一个字符串打印”。然后内核再通过驱动程序操控显示器,完成打印。
简单的一句 println("hello") 是无伤大雅的,但同一时刻 应用程序 传给 内核 很多数据,内核只有一个。因此,不能及时的给这么多数据提供服务。
用户态的cpu权限受限,只能访问到自己内存中的数据,无法访问其他资源。这样,在执行操作时只向创建好的内存申请即可,能及时的给这些数据提供服务。
举个例子:张三去某银行取钱,但是他没有带身份证复印件。此时他有两种选择,自己去银行大厅处自行打印、让柜台服务员帮他打印。张三自己去大厅打印复印件是非常很快的(用户态操作),但让柜台工作人员打印的话,工作人员乘机倒杯咖啡摸会鱼此时就不能快速的打印复印件(用户态与内核态的切换)。

因此,用户态操作是可控的,而涉及到内核态就不可控了。所以,我们创建设计线程池就能保证大多数操作都是用户态方式下进行的。
2. Java标准库中的线程池
Java 中最常见的线程池创建是使用 Executors.newFixedThreadPool() 能够创建固定的线程数,() 内填你需要线程数。
它返回类型为 ExecutorService(执行服务),通过 ExecutorService下的 submit 方法就可以注册一个任务到线程池中,submit 是一种固定了线程池的线程数量的创建方法。
创建固定线程数的线程,如以下代码:
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("Hello pool");
}
});
}运行后打印:

以上代码中,创建固定线程数量为 1 的线程池,并调用 submit 方法添加 run 任务到线程池中。代码比较简单,唯一需要注意的是 Executors.newFixedThreadPool() 是一种通过 ThreadPoolExecutor 类里面的静态方法来完成对象构造的,利用的是工厂模式。
2.1 工厂模式
如果想要多种不同的构造方法,这样的操作必须要在重载的情况下完成,但重载有坑(构造方法不能被重载)。因此在工厂模式下就能避免这个坑,它提供一个工厂类,工厂类里面有不同的方法来完成不同操作。
举例子:一个点有两种构造方式,1是直接通过横、纵坐标构造点,2是通过极坐标的方式来求:
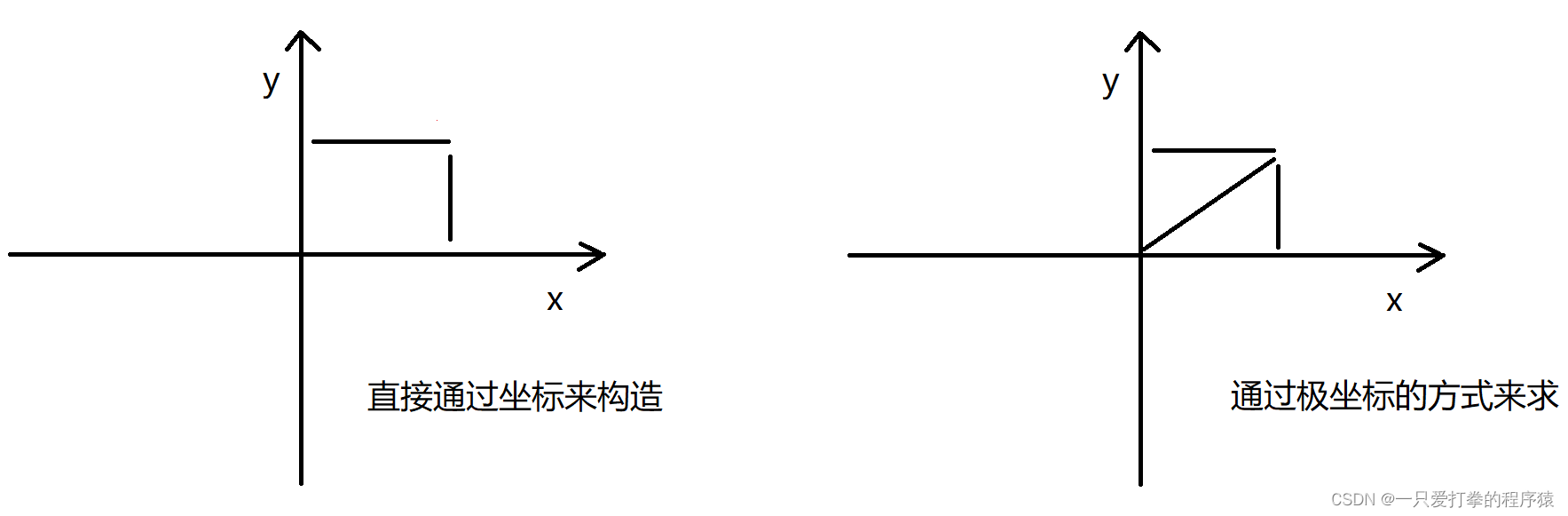
直接通过坐标的方式来构造点,能写出以下代码:
class Point {
public Point(double x,double y) {
//代码
}
public Point(double r,double a) {
//代码
}
}通过坐标的形式构造点,难免会用到重载, 类里面使用构造方法进行重载的话就会造成 Point 方法的 签名 相同,不能正常的编译。
通过工厂模式:
class PointBuilder {
public static Point makePointXY(double x,double y){
}
public static Point makePointRA(double r,double a){
}
}如果按照工厂模式,在工厂类里面实现一些不同名的方法,这样就能避免在构造方法重载造成的方法签名相同错误,并且我们返回的类型始终是 Point 。
在线程池中的 Executors.newFixedThreadPool() 方法就是 Executors 对 ThreadPoolExecutor 类里面的构造方法进行了封装,装好的方法一共有四个,具体请看下方讲解。
2.2 创建线程池的方式
Executors 创建线程池的几种方法:
- newFiexedThreadPool:创建固定线程数的线程池
- newCachedThreadPool:创建线程数目动态增长的线程池.
- newSingleThreadExecutor:创建只包含单个线程的线程池.
- newScheduledThreadPool:设定 延迟时间后执行命令,或者定期执行命令. 是进阶版的 Timer.
Executors 本质上是 ThreadPoolExecutor 类的封装。ThreadPoolExecutor 类底层的方法有很多,底层的构造方法就有四个,构造方法里面的参数也是参差不齐。
因此,Java 标准库就把 ThreadPoolExecutor 类封装为 Executors,利用的就是工厂模式。这样我们就能直接调用一些方法来创建线程池、添加任务。
3. ThreadPoolExecutor 类
工欲善其事,必先磨其器。我们可以直接使用 Executors 直接创建线程池,但不能不知道 Executors 的底层是什么。上面讲到了,Executors 就是 ThreadPooExecutor 类封装而来的。
因此我们可以通过 jdk api 帮助手册 来观察 ThreadPoolExecutor 类的组成原理。找到 java.util.concurrent 包底下的 ThreadPoolExecutor 即可看到下图四个方法。

我们可以看到一共有四个不同参数的构造方法,而且参数非常的多,因此我们搞定参数最多的方法,其余的就都认识了,请看下方讲解。
3.1 ThreadPoolExcutor 构造方法参数详解
上图四个方法,我们直接来看第四行最长的方法中的参数。

七个参数的讲解如下:
corPoolSize:核心线程,maximumPoolSize:最大线程。
举例,我们把 corPoolSize(核心线程)比 作正式工,maximumPoolSize(最大线程)比作 实习生 + 正式工。在工作比较多的时候,公司会多创建一些“临时线程”(多招一些实习生)。如果工作量少了,我们就会把临时的线程销毁(辞去实习生,保留正式工)。
keepAliveTime:保持存活时间。
当公司的任务是一阵一阵的,假如一个星期忙三天闲两天又开始忙。这时不会立马辞去实习生,等到很长一段时间不忙了才辞掉实习生(销毁临时线程)。这就是 keepAliveTime 的用处,不会立马销毁临时数据。
TimeUnit unit:线程的单位,类似于ms、s、h、day等。
BlockingQueue<Runnable> workQueue:阻塞队列,用来存储线程池里面的多个任务。
ThreadFactory threadFactory:工厂模式,创建线程的辅助类。
RejectedExecutionHandler handler:线程池的拒绝策略,当线程池满了,如何进行拒绝。在下方我会详细介绍。
通过上方的了解,如果我们直接使用 ThreadPoolExecutor 类来创建线程池得多麻烦,光是参数就有七个,因此 Java 中的 Executors 帮我们封装好了直接用就行。
代码案例,使用 ThreadPoolExcutor 类求斐波那契数列的前十个数:
public class FibonacciThreadPool {
// 定义斐波那契数列的计算函数
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
return fibonacci(n-1) + fibonacci(n-2);
}
public static void main(String[] args) {
// 创建一个线程池,最多同时执行3个线程
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
// 提交10个任务
for (int i = 1; i <= 10; i++) {
final int num = i;
executor.execute(() -> {
System.out.println(Thread.currentThread().getName() + " 计算斐波那契数列第" + num + "个数: " + fibonacci(num));
});
}
// 关闭线程池
executor.shutdown();
}
}运行后打印:
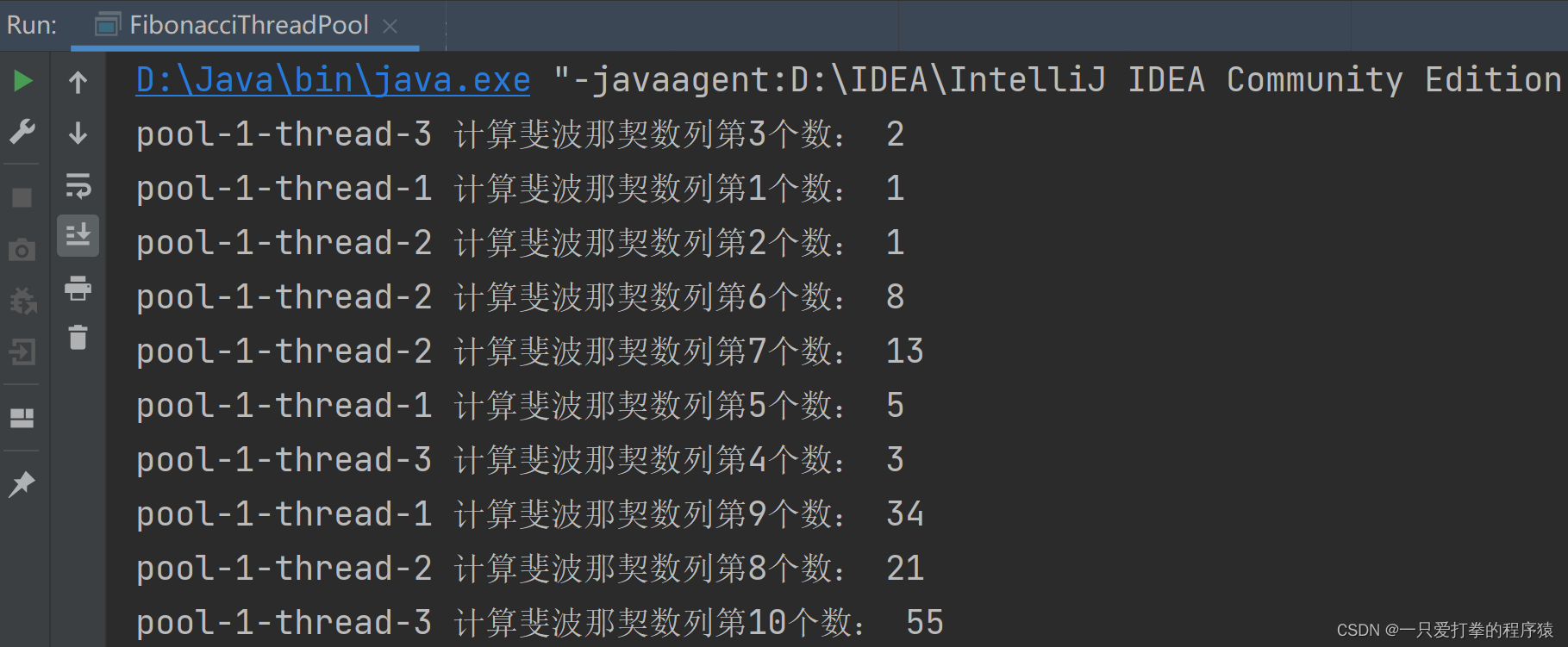 上述代码,实例化 ThreadPoolExcutor 类对象用了五个参数,用到的是参数最少的 ThreadPoolExcutor 构造方法。
上述代码,实例化 ThreadPoolExcutor 类对象用了五个参数,用到的是参数最少的 ThreadPoolExcutor 构造方法。

至于这些参数含义,在上方有详细的讲解。
3.2 线程池的拒绝策略
在 jdk 文档中,拒绝策略有四个分别为:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy。

AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy四个拒绝策略解释如下:
-
被拒绝的任务的处理程序,抛出一个
RejectedExecutionException。 -
一个被拒绝的任务的处理程序,直接在
execute方法的调用线程中运行被拒绝的任务,除非执行程序已被关闭,否则这个任务被丢弃。 -
被拒绝的任务的处理程序,丢弃最旧的未处理请求,然后重试
execute,除非执行程序被关闭,在这种情况下,任务被丢弃。 -
被拒绝的任务的处理程序静默地丢弃被拒绝的任务。
通俗的来讲:
- AbortPolicy 表示线程池满了,如果继续添加任务,会直接抛出一个
RejectedExecutionException的异常。- CallerRunsPolicy 表示添加的线程自己负责执行这个任务,哪个线程添加的任务,哪个线程执行。
- DiscardOldestPolicy 表示丢弃最老的任务,也就是最先入队列的任务。
- DiscardPolicy 表示丢弃最新的任务,因为队列无法添加新任务了,因此抛弃最新的任务。
模拟实现线程池的拒绝操作:
public static void main(String[] args) {
int corePoolSize = 10;//核心线程
int maximumPoolSize = 15;//最大线程数(核心线程+临时线程)
long keepAliveTime = 5;//线程的存货时间
//自定义一个阻塞队列来存放线程
BlockingQueue workQueue = new LinkedBlockingDeque(10);
//当线程池满了,则抛出一个异常
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();
//自定义一个线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
TimeUnit.SECONDS,
workQueue,
handler
);
//循环10次
for (int i = 0; i < 10; i++) {
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
}运行后打印:

以上打印,由于线程的抢占式执行导致输出没有按顺序,但最终任务还是完成了。 当我把上述代码中的 for 循环设置为 100 次时则会抛出异常:

这个异常就是 线程池拒绝策略 中的 AbortPolicy,线程池已满,无法再继续添加线程。
4. 模拟实现线程池
实现线程池:
- 需要一个阻塞队列:用来存放任务
- 需要自创一个 submit 方法:用来往阻塞队列里面添加任务
- 一个存放线程数的构造方法:用来接受线程池所需要创建的线程个数
设计好以上的几个方法就能自行模拟实现一个线程池,相信在理解了上方中线程池的使用以及底层原理,就能很好理解以下代码:
class MyThreadPool {
//自创建一个阻塞队列,用来存放任务
BlockingQueue<Runnable> queue = new LinkedBlockingDeque<>();
//自创一个submit方法,用来往阻塞队列里面存数据
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
//通过构造方法,来添加线程数量
public MyThreadPool(int n){
for (int i = 0; i < n; i++) {
Thread thread = new Thread(() -> {
try {
while (true) {
Runnable runnable = queue.take();
runnable.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread.start();
}
}
}
public class TestDemo {
public static void main(String[] args) throws InterruptedException {
//实例化一个myThreadPool对象
MyThreadPool myThreadPool = new MyThreadPool(10);
for (int i = 0; i < 1000; i++) {
int num = i;
myThreadPool.submit(new Runnable() {
@Override
public void run() {
System.out.println("执行: " + num);
}
});
}
}
}运行后打印:
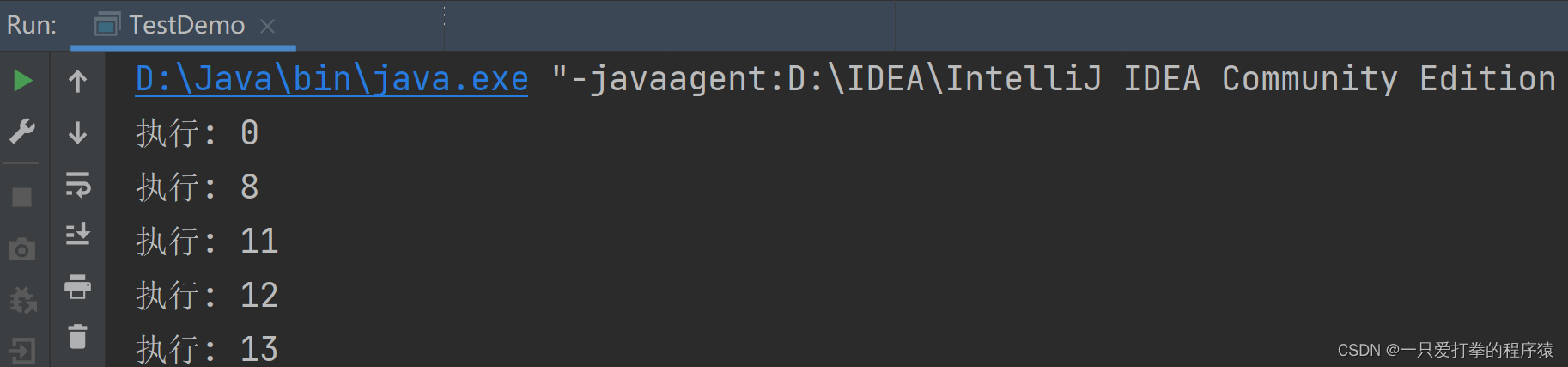
以上代码输出了 1000 个数据,我直截取了开头几个数据。我们发现打印的数据与添加数据的顺序不同,其原因也是线程抢占资源导致的,但最终的任务”输出数据“能够正常的完成。
创建线程池的方式有哪些?
- 使用 Executors 工厂类创建,创建方式比较简单,但定制能力有限。
- 使用 ThreadPoolExecutor 创建,创建方式比较复杂,但定制能力强。
LinkeadBlockingQueue在线程池中处于什么地位?
LinkeadBlockingQueue表示线程池的任务队列,用户通过 submit/execute 向任务队列中添加任务,再由线程池中的工作线程来执行任务。
🧑💻作者:一只爱打拳的程序猿,Java领域新星创作者,阿里云社区优质创作者、专家博主。
📒博客主页:这是博主的主页
🗃️文章收录于:Java多线程编程
🗂️JavaSE的学习:JavaSE
🗂️Java数据结构:数据结构与算法

本篇博文到这里就结束了,感谢点赞、评论、收藏、关注~