前言:
我们平时所说的文件都是指硬盘上的文件,而我们之前在JavaSE阶段代码绝大部分都是围绕内存展开的,定义个变量,其实就是内存上申请空间。
内存和硬盘的区别:
- 速度:内存比硬盘快很多。
- 空间:内存空间比硬盘小。
- 成本:内存比硬盘贵一点。
那么我们接下来的知识是如何通过Java进行操作硬盘上的文件.
目录
1. 文件路径
2. 文件分类
3. 文件系统操作
3.1 构造File对象
3.2 File属性
3.3 构造方法
3.4 Fiel类的方法
4. 文件的读写(数据流)
4.1 IO流原理
4.2 流的分类
4.2.1 字节流
4.2.2 字符流
5. 小练习
6. 如何按照进行读P(通常使用Scanner)
7. 如何按照行进行写(通常使用PrintWriter)
1. 文件路径
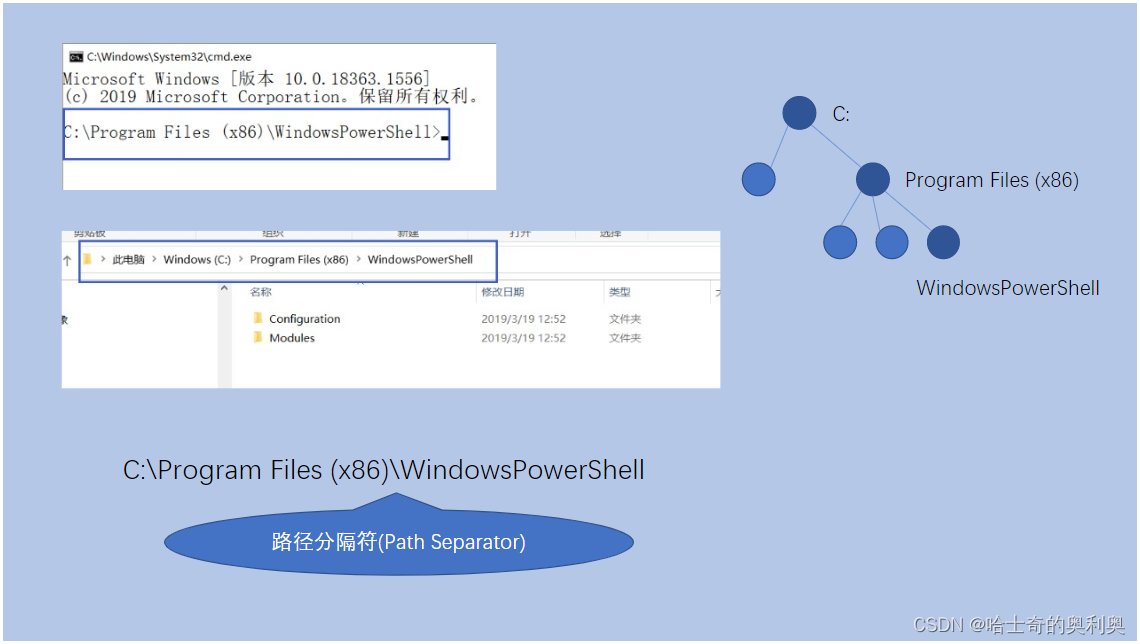
 上图就是我们通过电脑的文件系统产看到的文件路径
上图就是我们通过电脑的文件系统产看到的文件路径
1. 文系统是以树型结构来组织文件和目录的。N叉树。
文件路径就是以树根节点出发,沿着树杈,一路往下走,到达目标文件,此时这中间经过的内容、
Windows都是以“此电脑”起头的。表示路径的时候,可以把“此电脑”省略,直接从盘符开始表示。
实际表示路径,是通过一个字符串表示,每个目录之间使用斜杠/来分割.
2. 除了可以从根开始进行路径的描述,我们可以从任意结点出发,进行路径的描述,而这种描述方式就被称为相对路径(relative path),相对于当前所在结点的一条路径.

2. 文件分类
即使是普通文件,根据其保存数据的不同,也经常被分为不同的类型,我们一般简单的划分为文本文件和二进制文件,分别指代保存被字符集编码的文本和按照标准格式保存的非被字符集编码过的文件。
- txt:文本文件
- .java/.c:文本文件
- .class: 二进制文件
- .exe :二进制文件
- jpg,mp3:二进制文件
记事本出现乱码的原因:
二进制都是一个一个的字节,记事本尝试着把当前若干个字节的数据往utf8码表里套,套出来的是啥就是啥。word编辑的docx和excel编辑的表格都是二进制文件。
3. 文件系统操作
Java标准库,给我们提供了File这个类,File对象是硬盘上一个文件的"抽象"表示,文件是存储在硬盘上的,直接通过代码操作硬盘是不方便的,就在内存中创建一个对象,就可以通过操作这个对象进行操作硬盘的内容了.(注意,有 File 对象,并不代表真实存在该文件)
3.1 构造File对象
构造的过程中,可以使用绝对路径/相对路径来进行初始化。这个路径指向的文件,可以是真实存在的,也可以不是真实存在的。
import java.io.File;
public class FileTest{
public static void main(String args[]){
File file = new File("d:/test.txt")
}
}
3.2 File属性

3.3 构造方法

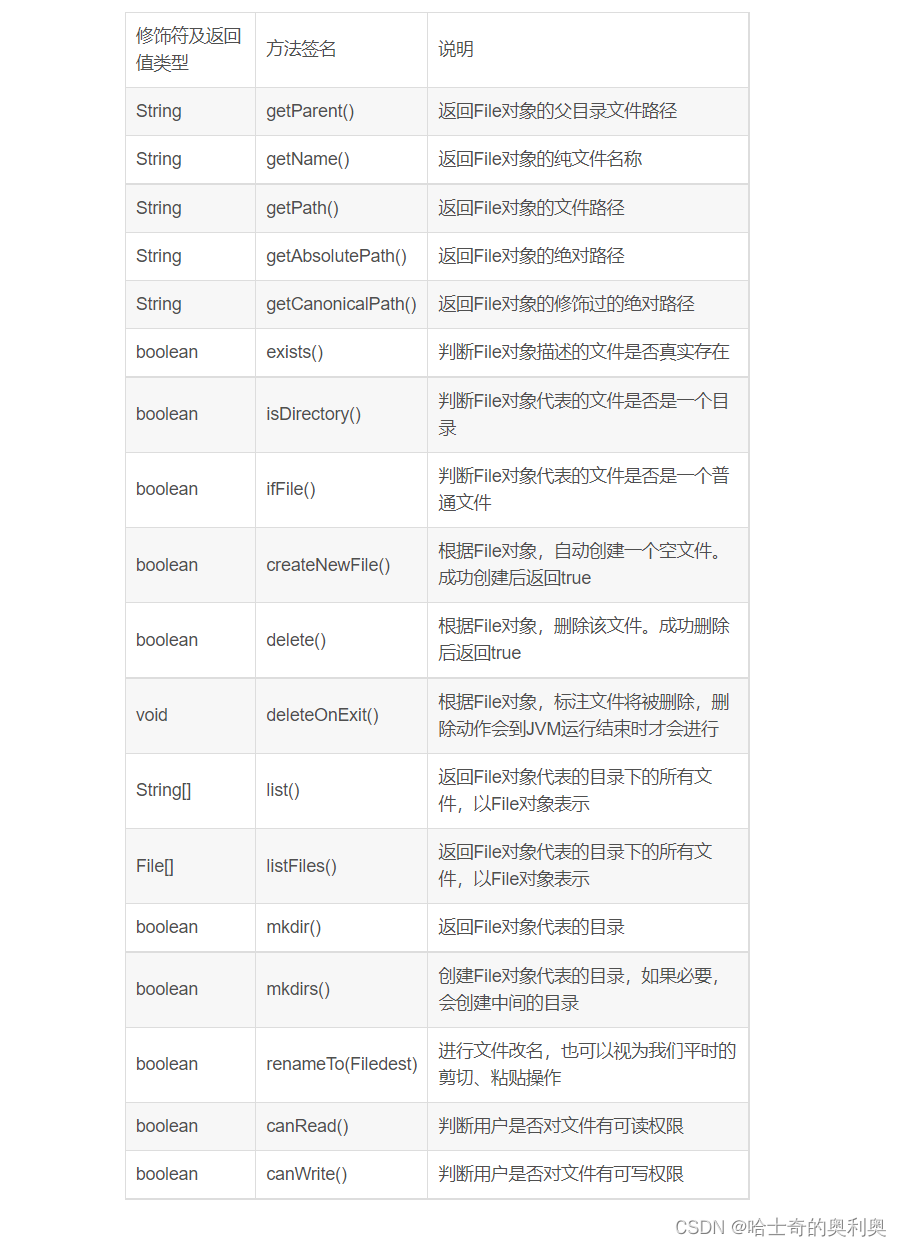
3.4 Fiel类的方法
4. 文件的读写(数据流)

4.1 IO流原理
- I/O分别是Input与Output的缩写,用于处理数据传输,读写文件、网络通讯等;
- Java程序中,对于数据的输入输出以流的方式进行;
- java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过方法输入或输出数据;
- input表示输入:读取外部数据,即将磁盘、光盘等存储设备的数据读到程序(内存)中;
- output表示输出:将程序(内存)数据输出到磁盘、光盘等存储设备中。
4.2 流的分类
针对文本文件,提供了一组类,统称为“字符流”(典型代表,Reader,Writer)
针对二进制文件,提供了一组类,统称为“字节流”(典型代表,InputStream,OutputStream)
4.2.1 字节流
1. 输入:InputStream
| 修饰符以及返回值类型 | 方法 | 说明 |
| int | read() | 读取一个字节的数据,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b 中,返回实际读到的数量;-1 代表以及读完了 |
| int | read(byte[] b, int off, int len) | 最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了 |
| void | close() | 关闭字节流 |
InputStream 只是一个抽象类,要使用还需要具体的实现类。关于 InputStream 的实现类有很多,基本可以认为不同的输入设备都可以对应一个 InputStream 类,我们现在只关心从文件中读取,所以使用FileInputStream.

代码示例
将文件完全读完的两种方式。相比较而言,后一种的 IO 次数更少,性能更好。
第一种:每次读取一个字符
import java.io.*;
// 需要先在项目目录下准备好一个 hello.txt 的文件,里面填充 "Hello" 的内容
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("hello.txt")) {
while (true) {
int b = is.read();
if (b == -1) {
// 代表文件已经全部读完
break;
}
System.out.printf("%c", b);
}
}
}
}第二种:读取指定长度的内容
import java.io.*;
// 需要先在项目目录下准备好一个 hello.txt 的文件,里面填充 "Hello" 的内容
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("hello.txt")) {
byte[] buf = new byte[1024];
int len;
while (true) {
len = is.read(buf);
if (len == -1) {
// 代表文件已经全部读完
break;
}
for (int i = 0; i < len; i++) {
System.out.printf("%c", buf[i]);
}
}
}
}

上述我们在文件中写入的内容为子母,因为是字节流,所以输出的是二进制字符
我们想要输出为hello需要转成字符
方法一:使用String的构造方法


每次使用 3 字节进行 utf-8 解码,得到中文字符,利用 String 中的构造方法完成, 这个方法了解下即可,不是通用的解决办法
方法2:使用Scanner



2. OutputStream
| 修饰符以及返回值类型 | 方法签名 | 说明 |
| void | write() | 写入要个字节的数据 |
| void | write(byte[] b) | 将 b 这个字符数组中的数据全部写入 os 中 |
| int | write(byte[] b, int off, int len) | 将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个 |
| void | close() | 关闭字节流 |
| void | flush() | 重要:我们知道 I/O 的速度是很慢的,所以,大多的 OutputStream 为了减少设备操作的次数,在写数据的时候都会将数据先暂时写入内存的一个指定区域里,直到该区域满了或者其他指定条件时才真正将数据写入设备中,这个区域一般称为缓冲区。但造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中。 |

将内容写入到文件(输出)
方法1.
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
os.write('H');
os.write('e');
os.write('l');
os.write('l');
os.write('o');
// 不要忘记 flush
os.flush();
}
}
}方法2
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
byte[] b = new byte[] {
(byte)'G', (byte)'o', (byte)'o', (byte)'d'
};
os.write(b);
// 不要忘记 flush
os.flush();
}
}
}方法3
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
String s = "Nothing";
byte[] b = s.getBytes();
os.write(b);
// 不要忘记 flush
os.flush();
}
}
}上述,我们其实已经完成输出工作,但总是有所不方便,我们接来下将 OutputStream 处理下,使用PrintWriter 类来完成输出,因为PrintWriter 类中提供了我们熟悉的 print/println/printf 方法
代码示例
public static void main(String[] args) throws IOException {
try (OutputStream outputStream = new FileOutputStream("src/IoDemo2/hello.txt")){
PrintWriter printWriter = new PrintWriter(outputStream);
printWriter.println("嘿嘿");
printWriter.print("哈哈");
printWriter.printf("%d: 呵呵呵\r\n", 2);
printWriter.flush();
}
}
4.2.2 字符流
字符流就比较简单了
简单代码如下
1. Reader
package IoDemo2;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class reader {
public static void main(String[] args) {
try(Reader reader = new FileReader("src/IoDemo2/hello.txt")){
while (true){
int c = reader.read();
if (c == -1){
break;
}
char ch = (char) c;
System.out.println(ch);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
2. Writer
package IoDemo2;
import java.io.FileWriter;
import java.io.IOException;
import java.io.StringWriter;
import java.io.Writer;
public class writer {
public static void main(String[] args) {
try(Writer writer = new FileWriter("src/IoDemo2/hello.txt",true)){
writer.write("\nhello");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
5. 小练习
扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
注意:我们现在的方案性能较差,所以尽量不要在太复杂的目录下或者大文件下实验
package IoDemo2;
import java.io.*;
import java.util.Scanner;
/**
* Created with IntelliJ IDEA.
* Description:
* User: YAO
* Date: 2023-05-25
* Time: 15:23
*/
public class test1 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的根目录: ");
File rooDir = new File(scanner.nextLine());
if (!rooDir.isDirectory()){
System.out.println("输入有误,请重新输入:");
return;
}
// 2. 让用户输入一个查询的词
System.out.println("请输入要查询的词");
String word = scanner.nextLine();
//3. 递归的进行目录/文件遍历
scanDir(rooDir,word);
}
private static void scanDir(File rooDir, String word) {
// 1.列出当前的rootDir中的内容,没有内容,直接递归结束
File[] files = rooDir.listFiles();
if(files == null){
// 当前rootDir是一个空的目录
// 没必要进行递归
return;
}
for (File f: files){
System.out.println("当前搜索到: " + f.getAbsolutePath());
if (f.isFile()){
// 为普通文件
// 打开文件,读取内容,比较看是否包含上述关键词
String content = readFile(f);
if (content.contains(word)){
System.out.println(f.getAbsolutePath() + " 包含要查找的关键字!");
}
}else if(f.isDirectory()){
// 是目录
// 进行递归操作
scanDir(f,word);
}else {
// 其他文件
continue;
}
}
}
private static String readFile(File f){
// 读取文件的整个内容,返回出来
// 使用字符流来进行读取,由于我们匹配的是字符串,此处只能按照字符流进行匹配才是有意义的.
StringBuilder stringBuilder = new StringBuilder();
try(Reader reader = new FileReader(f)){
// 一次读一个字符,把读到的结果拼装到StringBuilder中,统一转成String
while (true){
int c = reader.read();
if(c == -1){
break;
}
stringBuilder.append((char) c);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return stringBuilder.toString();
}
}
6. 如何按照进行读P(通常使用Scanner)
package IoDemo2;
import java.io.*;
import java.util.Scanner;
/**
* Created with IntelliJ IDEA.
* Description:读取文件的一行
* User: YAO
* Date: 2023-05-24
* Time: 22:46
*/
public class readerRow {
/**
* 1.使用BufferedReader
*/
public static void main1(String[] args) {
try (BufferedReader bufferedReader = new BufferedReader(new FileReader("src/IoDemo2/hello.txt"))) {
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 2.使用Scanner
*/
public static void main2(String[] args) {
try (Scanner scanner = new Scanner(new FileReader("src/IoDemo2/hello.txt"))) {
while (scanner.hasNextLine()){
String line = scanner.nextLine();
System.out.println(line);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
/**
* 3.RandomAccessFile
* 行数达到一定规模,使用此方法读取会非常慢
*/
public static void main(String[] args) throws FileNotFoundException {
try (RandomAccessFile randomAccessFile = new RandomAccessFile("src/IoDemo2/hello.txt","r")){
String line;
while ((line = randomAccessFile.readLine()) != null) {
//将readLine读取出来的字符串通过getBytes方法按iso-8859-1编码成字节数组,然后再将字节数组按utf8解码,最后转换成字符串输出。
String lineNew = new String(line.getBytes("iso-8859-1"),"utf8");
System.out.println(lineNew);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}7. 如何按照行进行写(通常使用PrintWriter)
public static void main(String[] args) throws IOException {
try (OutputStream outputStream = new FileOutputStream("src/IoDemo2/hello.txt")){
PrintWriter printWriter = new PrintWriter(outputStream);
printWriter.println("嘿嘿");
printWriter.println("哈哈");
printWriter.flush();
}
}