1. 项目背景
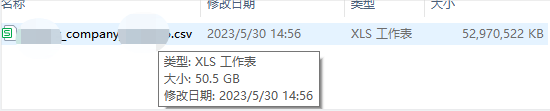
目前本地有50G的企业年报csv数据, 需要清洗出通信地址,并需要与原有的亿条数据合并以供业务查询最新的企业通信地址
2. 技术选型
Hadoop + ClickHouse
3. Hadoop数据清洗
我们50G的数据无须上传至集群处理,上传目前带宽2M/S, 巨慢,我直接在本地hadoop处理
我们先看下数据格式,以@_@分割,最后一列是杂乱的数据
315@_@102878404@_@91430802MA4PPBWA9Y@_@3@_@2021-03-19 15:29:05@_@2021-03-19 15:29:04@_@-@_@2019@_@<tr> <!--180 285 145--> <td>统一社会信用代码/注册号</td> <td>91430802MA4PPBWA9Y</td> <td>企业名称</td> <td>张家界恒晟广告传媒有限公司</td></tr><tr> <td>企业联系电话</td> <td>15874401535</td> <td>邮政编码</td> <td>427000</td></tr><tr> <td>企业经营状态</td> <td>开业</td> <td>从业人数</td> <td>1人</td></tr><tr> <td>电子邮箱</td> <td>-</td> <td>是否有网站或网店</td> <td>否</td></tr><tr> <td>企业通信地址</td> <td>湖南省张家界市永定区大庸桥办事处大庸桥居委会月亮湾小区金月阁5601号</td> <td>企业是否有投资信息<br>或购买其他公司股权</td> <td>否</td></tr><tr> <td>资产总额</td> <td>企业选择不公示</td> <td>所有者权益合计</td> <td>企业选择不公示</td></tr><tr> <td>销售总额</td> <td>企业选择不公示</td> <td>利润总额</td> <td>企业选择不公示</td></tr><tr> <td>营业总收入中主营业务收入</td> <td>企业选择不公示</td> <td>净利润</td> <td>企业选择不公示</td></tr><tr> <td>纳税总额</td>
public class Company implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "company");
job.setJarByClass(CompanyDriver.class);
job.setMapperClass(CompanyMapper.class);
job.setReducerClass(CompanyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(1);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
public static class CompanyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private Text keyOut = new Text();
private Text valueOut = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("@_@");
keyOut.set(key.toString());
String company_id = words[1];
String unified_code = words[2];
String year = words[7];
String company = StringUtils.substringBetween(words[8], "<td>统一社会信用代码/注册号</td> <td>", "</td> <td>企业名称</td>")
.replaceAll("\"", "");
String mailAddress = StringUtils.substringBetween(words[8], "<td>企业通信地址</td> <td>", "</td> <td>企业是否有投资信息")
.replaceAll("\"", "");
if (!company.contains("td") && !mailAddress.contains("td")) {
valueOut.set(key.toString() + '@' + company_id + '@' + unified_code + '@' + year + '@' + company + '@' + mailAddress);
context.write(valueOut, NullWritable.get());
}
}
}
public static class CompanyReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 防止相同数据丢失
for (NullWritable value : values) {
context.write(key, NullWritable.get());
}
}
}
}
public class CompanyDriver {
private static Tool tool;
public static void main(String[] args) throws Exception {
// 1. 创建配置文件
Configuration conf = new Configuration();
// 2. 判断是否有 tool 接口
switch (args[0]) {
case "company":
tool = new Company();
break;
default:
throw new RuntimeException(" No such tool: " + args[0]);
}
// 3. 用 Tool 执行程序
// Arrays.copyOfRange 将老数组的元素放到新数组里面
int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length));
System.exit(run);
}
}
参数传递运行与先前文章一致,25.hadoop系列之Yarn Tool接口实现动态传参 不在重复,10分钟左右处理完毕,处理后约1.8G


4. ClickHouse ReplaceMergeTree实践
现在我们将处理后数据导入ClickHouse
4.1 创建表company_report及导入处理后的part-r-00000文件
CREATE TABLE etl.company_report (
id String,
company_id String,
unified_code String,
year String,
company String,
mail_address String
) ENGINE MergeTree()
PARTITION BY substring(unified_code, 2, 2) PRIMARY KEY (id) ORDER BY (id);
clickhouse-client --format_csv_delimiter="@" --input_format_with_names_use_header=0 --query="INSERT INTO etl.company_report FORMAT CSV" --host=192.168.0.222 --password=shenjian < part-r-00000
4.2 关联插入dwd_company表
在左连接的子查询中,我们取当前企业最新的年报中的通信地址,如下图所示

# 关联导入,可能DataGrip客户端超时,就在ClickHouse-Client命令行运行即可
INSERT INTO etl.dwd_company(district, ent_name, reg_addr, unified_code, authority, region_code, reg_addr1, province_code, city_code, province_name, city_name, region_name, mail_address)
SELECT district, ent_name, reg_addr, unified_code, authority, region_code, reg_addr1, province_code, city_code, province_name, city_name, region_name, cr.mail_address
FROM etl.dwd_company c
LEFT JOIN (
SELECT unified_code, argMax(mail_address, year) mail_address, argMax(year, year) new_year FROM etl.company_report GROUP BY unified_code
) cr ON c.unified_code=cr.unified_code
WHERE cr.mail_address!='' and cr.mail_address is not null;

这插入速度还行吧,插入后,存在两条记录,对于ReplaceMergeTree来说,无妨,看过之前文章的你应该很熟悉为啥了吧

4.3 清洗企业通信地址
新建字段mail_address1,剔除省市区前缀信息,列式存储,全量更新很快,请不要单条那种更新
ALTER TABLE etl.dwd_company update mail_address1=replaceRegexpAll(mail_address, '^(.{2,}(省|自治区))?(.{2,}市)?(.{2,}(区|县))?', '') WHERE 1=1

4.4 手动执行分区合并
如果线上对ClickHouse服务稳定性要求极高不建议这样操作,可能影响服务,可以参考9.ClickHouse系列之数据一致性保证
optimize table etl.dwd_company final;
后面可以将dwd_company中所需字段数据导入数据中间层dwm_company,略
欢迎关注公众号算法小生与我沟通交流