过期Key处理:
1)Redis之所以性能强大,最主要的原因就是基于内存来存储,然而单节点的Redis内存不宜设置的过大,否则会影响持久化或者是主从复制的性能,可以通过修改配置文件来设置redis的最大内存,通过maxmemory 1gb,但是当内存达到上限的时候,就无法存储更多数据了
2)在之前学习Redis缓存的时候,可以通过expire命令来给Redis的key设置TTL过期时间
3)可以发现,当key的ttl过期之后,再一次访问name的时候返回的是nul,说明这个key已经不存在了,对应的内存也就释放了,从而起到了内存回收的目的
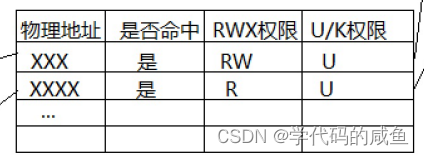
4)Redis本身是一个典型的key-value键值对的内存存储的数据库,因此所有的key和value都是保存在之前学习过的Dict结构中,但是在database结构体中有两个Dict,一个是用来记录key-value,一个用来记录key-ttl;
在设置键的过期时间的同时,设置一个定时器,当键过期了,定时器马上把该键删除
定时删除对内存来说是友好的,因为它可以及时清理过期键,但对CPU是不友好的,如果过期键太多,删除操作会消耗过多的资源
在过期 key 比较多的情况下,删除过期 key 这一行为可能会占用相当一部分 CPU 时间,在内存不紧张但是 CPU 时间非常紧张的情况下,将 CPU 时间用在删除和当前任务无关的过期 key 上,无疑会对服务器的响应时间和吞吐量造成影响



Redis采用的是 惰性删除 + 定期删除 的策略
一)惰性删除:顾名思义就是说并不是在TTL到期之后就立即删除,而是在访问一个Key的时候(增删改查),检查该Key的存活时间,如果过期了才执行删除;
当查询数据的时候,首先根据key查询对应的expires,检查是否过期,如果过期就返回null,并删除对应的数据和expires,如果不过期,就返回数据
假设给一个key设置了过期时间,但是永远不会访问这个key,那么这个key就永远也不会被删除,这样就会导致内存占用过多的状况
这种方式看似很完美,在访问的时候检查key的过期时间,不会占用太多的额外CPU资源但是如果一个key已经过期了,如果长时间没有被访问,那么这个key就会一直存留在内存之中,严重消耗了内存资源,并且删除的目标仅限于当前处理的 key不会在删除其他无关的过期 key 上花费任何 CPU 时间
二)周期删除:顾名思义就是设置一个定时任务,周期性的抽样部分过期的key,然后执行删除,执行周期有两种:
定期删除是定时删除和惰性删除的一个折中方案,每隔一段时间来删除过期键,可以根据实际场景自定义这个间隔时间,在CPU资源和内存资源上作出权衡
2.1)Redis初始化会设置一个定时任务serverCron(),按照server.hz(1s中最多执行1次)的频率来执行过期的key的清理,模式为slow,过期的key,早晚会被抽到,执行时间长,执行的频率比较低;
2.2)Redis初始化后的1ms去执行
2.3)serverCron的返回值是完成serverCron再隔多少毫秒之后执行此定时任务(100ms)
2.4)getLRUClock时钟是更新lruclock到当前时间,为后期的LRU和LFU做准备,并且接下来会调用atomicSet方法设置到server.lruclock里面,lruclock是redis内部维护的一个时钟,是以微秒为单位的,每隔一个周期会进行记录一次,每隔100ms会更新一次,每调用一次serverCron方法lruclock是不断的会发生变化的
2.5)开始执行数据库的数据清理,例如说过期的key的清理;
2.2)Redis的每一个事件循环前会调用beforeSleep()函数,执行过期的key清理,模式为FAST,执行频率比较高,执行的时间非常短,不超过1ms
1)redis服务一进行启动,先调用initserver()函数,完成各种各样的注册,创建ServerSocket以及eventpoll,将ServerSocket对应的fd挂到红黑树上面;
2)接下来会执行aemain来进行事件循环,开启一个事件循环,会不断的调用beforesleep,再来调用aeapipoll,相当于是epoll_wait,等待事件就绪,如果事件就绪了,就进行对应的Socket的读写,处理IO事件;
3)最后会调用serverCron()进行定时任务的清理,但是除了redis在初始化之后1ms调用serverCron之外,以后的serverCron执行完成之后都会返回一个1000/server.sz,返回的就是100ms,默认就是下一次aeApiPoll执行的时间,所以当while循环执行的时候程序会进行检查serverCron()执行的时间到了没有,如果时间到了才执行,确保每隔100ms执行一次,时间不到就不执行serverCron函数了,因为while循环速度非常快,如果在每一次循环中都去调用serverCron()函数,那么这个函数执行的频率就会非常高了,但是再beforeSleep模式中,Fast模式清理是随着循环而进行的,每一次执行while循环,都会执行fast回收;
4)因为fast执行的模式是非常快的,清理速度也是非常快的,一次执行的速度会控制在1ms以内,而slow模式可能执行一次可能是消耗几十毫秒,如果serverCron()每循环一次都要执行,每一次主线程执行while循环都需要卡顿几十毫秒,那么主线程执行性能将会非常低,所以slow模式并不是在每一次循环都执行,而是每隔100ms之后执行,避免主线程阻塞;
slow模式属于是低频,长时间的清理,清理效果会更好一点,可以清理更多的Key
fast模式属于高频,少量清理,耗时时间非常的短,最长不超过1ms
但是他们都是为了在不阻塞主线程的情况下,尽可能过多的清理过期的key




slow模式规则:低频高时长的执行
1)执行频率受server.hz影响,默认是10,即每一秒执行10次,每一个执行周期是100ms
2)执行清理key的耗时不超过一次执行周期的25%;
3)逐个遍历db,逐个遍历db中的bucket,抽取20个key查看他们是否过期,直到把所有的buket都遍历到,如果发现过期的key就直接干掉;
4)如果没有达到时间上线25ms况且过期key的比例超过10%,那么再次进行一次抽样,否则结束;
fast模式规则:过期key的比例小于10%不执行,高频低时长
1)执行频率受beforesleep()函数调用的影响,但是两次fast模式执行的间隔不应该低于2ms,fast模式每一次执行前都会判断上一次fast到现在的时间,如果不足2ms就会跳过;
2)执行清理的耗时不超过1ms
3)遍历整个db,逐个遍历db中的bucket,抽取20个key判断是否过期
4)如果没有达到时间上限1ms,况且过期key的比例超过10%,那么在进行一次抽样否则结束
Redis 中,flushall 和 flushdb 都是清空当前数据库的操作,但是两者有很大的区别:
1)flushall 清空数据库并执行持久化操作,也就是 rdb 文件会发生改变,变成 76 个字节大小(初始状态下为 76 字节),所以执行 flushall 之后数据库真正意义上清空了
2)flushdb 清空数据库,但是不执行持久化操作,也就是说 rdb 文件不发生改变。而 Redis 的数据是从 rdb 快照文件中读取加载到内存的,所以在 flushdb 之后,如果想恢复数据库,则可以直接 kill 掉 redis-server 进程,然后重新启动服务,如此 Redis 重新读取 rdb 文件,数据恢复到 flushdb 操作之前的状态;
3)注意:要直接 kill 掉 redis-server 服务,因为 shutdown 操作会触发持久化,lsof -i:6379命令查看 redis-server 的进程号,然后 kill 即可

redis的内存淘汰策略:
redis的过期策略可以将redis中一些过期的key直接删除,但是在一些庞大的项目中,因为数据量非常的多,请求不断地向redis中进行存储数据,很有可能仅仅淘汰过期的key也很难满足内存的使用,此时内存也有可能达到上限;