出品人:Towhee 技术团队 作者:顾梦佳
由 OpenAI 推出的聊天机器人ChatGPT 爆火,带动 AI 受到了前所未有的关注。随之市面上也涌现出了各类开源的大语言模型(LLM),其中 LLaMA “羊驼系列”最受关注、最具潜力。LLaMA 是由 Meta AI 发布的一个开放且高效的大型基础语言模型,其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。而 Guanaco ”原驼“模型则是基于 LLaMA 利用QLoRA技术微调出来的最优模型。QLoRA 在降低大模型微调成本的同时,也保证了性能的提升。它只需要一张消费级显卡,就能在两天内获得一个99+%近似 ChatGPT 的大语言模型。其论文一经发布就受到了业内广泛关注,是目前热度最高的AI论文之一。
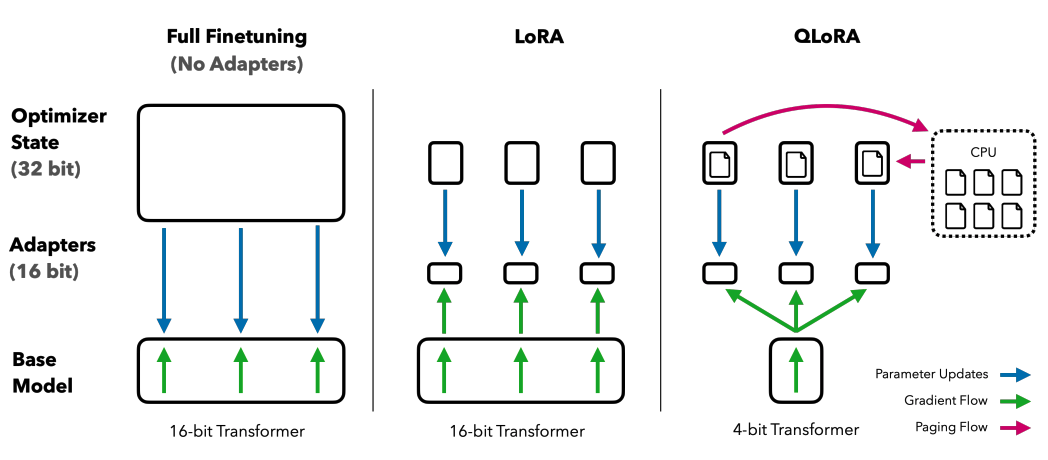 |Comparing finetune methods: Regular vs LoRA vs QLoRA
|Comparing finetune methods: Regular vs LoRA vs QLoRA
QLoRA 使用了一种新颖的高精度技术将预训练的Transformer模型量化为4位精度,然后添加一小组可学习的低秩适配器(LoRA)权重,通过反向传播梯度来调整这些量化权重。它通过引入多项创新技术改进了LoRA,用于每一层网络层,从而在节省内存的同时保证性能:
-
NF4(4位 NormalFloat):一种新的数据类型,对于正态分布的权重来说,在信息理论上是最优的。 -
双重量化:一种量化量化常数的方法,通过量化量化常数来减少平均内存占用。平均每个参数节能够省约0.37位,对于650亿参数的模型来说约为3GB。 -
分页优化器:它可以用于管理内存峰值,使用了英伟达统一内存,在处理具有长序列长度的小批量时可以避免梯度检查点的内存峰值。
实验结果表明,QLoRA 仅用小型的高质量数据集进行微调,就可以实现最先进的结果。它可以将微调 650亿参数模型的平均内存需求从大于780GB的GPU内存降至少于48GB。同时,与16位精度的微调基准相比,使用4位精度的 QLoRA 也不会降低运行时间或预测性能。这是 LLM 微调的一项重大突破,意味着目前最大的公开可用模型可以在单个GPU上进行微调。实验获得的最优大语言模型——650亿参数版的“原驼”,在 Vicuna 基准测试上达到了 ChatGPT 99.3%的水平,并且只需要用单张消费级显卡微调24小时以上。如果只训练不到12小时,330亿参数的“原驼”也能达到ChatGPT性能水平的97.8%。在部署时,最小的”原驼“模型(7B参数)只需要5GB的内存,而且其性能在Vicuna基准测试上比26GB的 Alpaca 模型高出20个百分点以上。
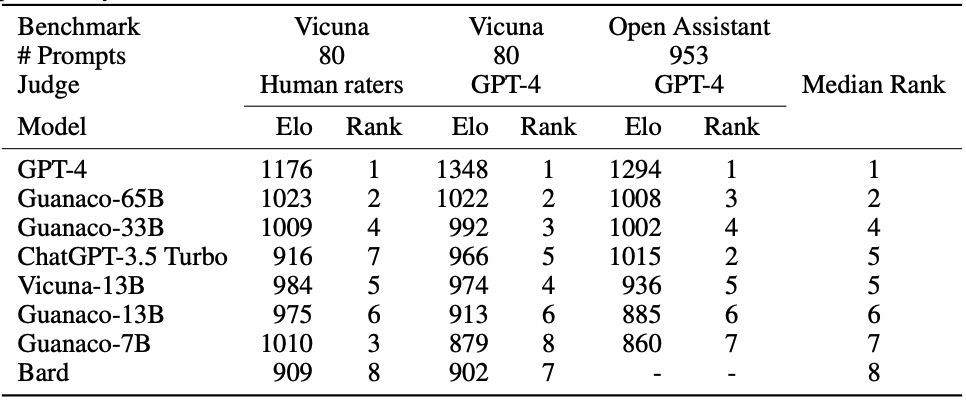
|Elo rating, judged by human raters or GPT-4
论文中使用的测试数据包括953条不重复的用户查询,筛选自两个数据集:”小羊驼“ Vicuna中80个不同类别的提示,以及OASST1(OpenAssistant Conversations)验证集的多语言多轮对话。利用这些数据集,QLoRA 的团队对“原驼“系列模型同时进行了机器(GPT-4)和人类评估。自动(机器)评估将不同系统与ChatGPT(GPT-3.5 Turbo)在基准测试中的表现进行对比。它利用 GPT-4 对各系统的表现评分,最终模型的整体表现被计算为ChatGPT得分的百分比。根据实验结果,ChatGPT 作为比较基线得分为 100%,GPT-4的平均得分为 114.5%,而开源大语言模型中“原驼”占领了最高分数 99.3%(65b)和97.8%(33b)。综合评估结合了机器和人类评估,锦标赛结果被聚合成Elo分数,采用了锦标赛的方式让模型相互竞争,以确定系统性能的排名。而竞标赛排名表示,“原驼”系列模型甚至比ChatGPT(GPT-3.5)更受欢迎。 总体而言,”原驼“更尊重事实、不容易受到错误信息的误导,并且拥有强大的心智理论(Theory of Mind),即理解自己以及周围人类的心理状态的能力。然而,它同时也具有一些明显的缺点,比如容易被提示攻击而泄漏信息、尤其不擅长数学。
相关资料:
-
代码地址: https://github.com/artidoro/qlora -
论文链接: QLORA: Efficient Finetuning of Quantized LLMs
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 
本文由 mdnice 多平台发布
![[ Term ] 你真的了解 UTC 时间吗?它和 GMT 时间的区别是什么?](https://img-blog.csdnimg.cn/f3b12bf4f7d74610892a916da8f51443.png)