目录
Graph Augmentation for GNNs
引入
Why Graph Augmentation
Graph Augmentation Approaches
Feature Augmentation on Graphs
Input graph没有node features
GNN很难学习的一些特定结构
Graph Structure augmentation
Augment sparse graphs——添加虚拟节点或边
Node Neighborhood Sampling
Prediction with GNNS
Node-level prediction
Edge-level prediction
Head的选择1:Concatenation + Linear
Head的选择2:Dot product
Graph-level prediction
Head的选择1:Global pooling
Head的选择2:Hierarchical Global Pooling
Training Graph Neural Networks
Supervised&Unsupervised learning
Final loss
Classification Loss
Regression loss
Evaluation metrics
Regression evaluate
Classification evaluate
split dataset
Transductive setting
Inductive setting
Example: Node Classification
Example: Graph Classification
Example: Link Prediction
总结
Graph Augmentation for GNNs
引入
Why Graph Augmentation
之前都是假设原始input graph = computational graph,但是存在以下问题:
1.features
input graph缺少features
2.graph structure
- graph too sparse——导致message传递低效
- graph too dense —— 导致message传递costly
- graph too large —— 导致不能computational graph不适于GPU
因此原始input graph不太可能是用于embedding的最优computational graph
Graph Augmentation Approaches
1.Graph Feature augmentation
input graph缺少features——feature augmentation
2.Graph Structure augmentation
- graph too sparse ——添加虚拟节点或边
- graph too dense —— 当传递message时,对邻居节点采样
- graph too large —— 采样子图用于计算embedding
Feature Augmentation on Graphs
Input graph没有node features
对应于只有邻接矩阵的情况
1.为节点分配常数值作为特征
2.为节点分配不同的ID(one-hot编码)


GNN很难学习的一些特定结构
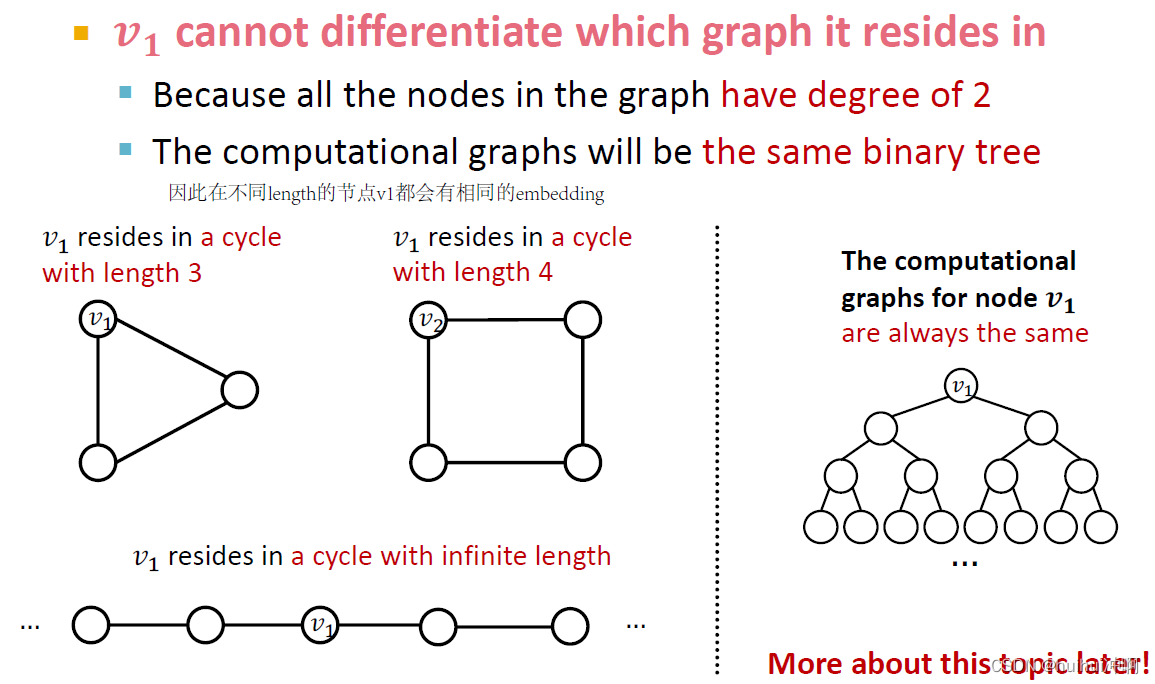
例如cycle结构,不同length的cycle图的节点都有相同的计算图,会得到相同的embedding,因此不能区分节点到底在哪个length的图上。可以使用cycle count作为节点特征。
还有其它难以学习的结构,可以使用Node degree、Clustering coefficient、PageRank、Centrality作为节点特征。

Graph Structure augmentation
Augment sparse graphs——添加虚拟节点或边
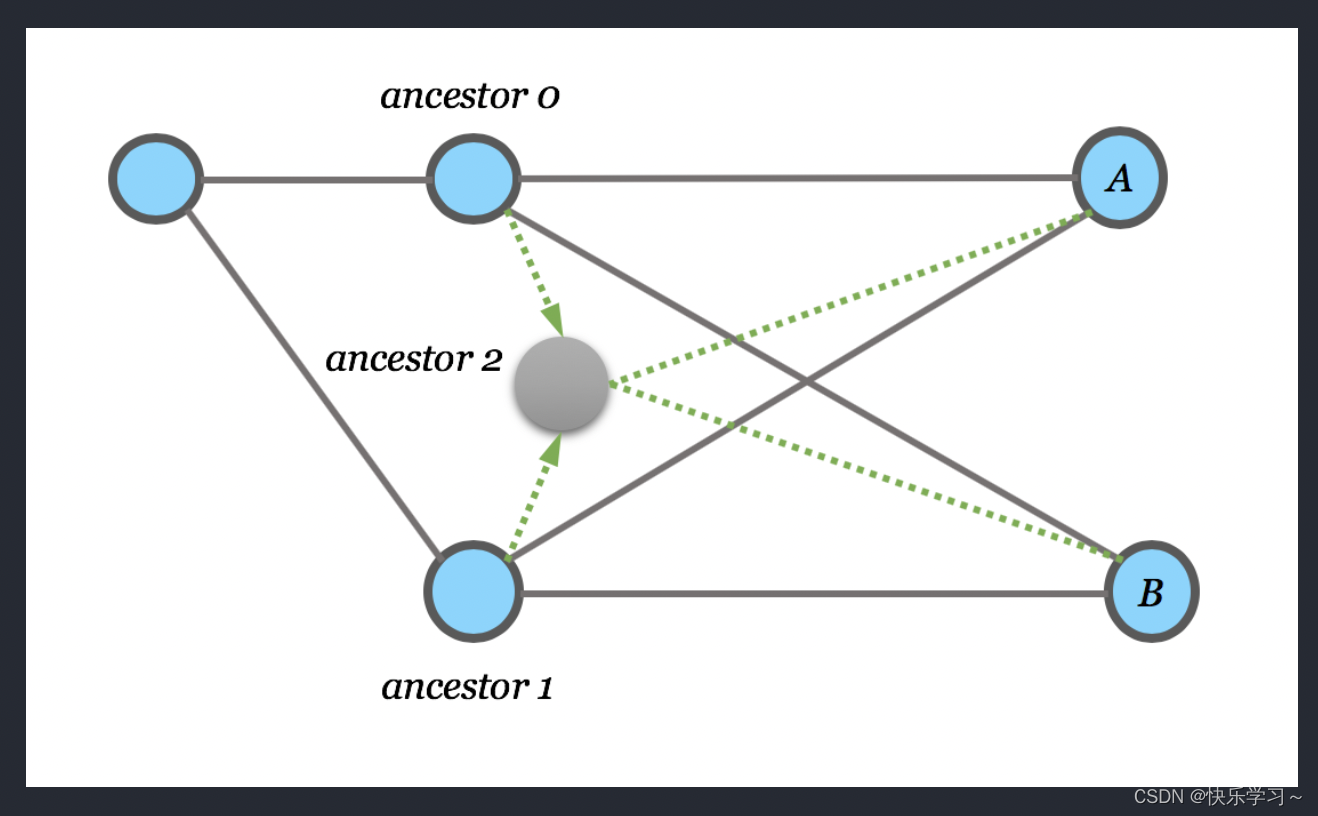
1.添加虚拟边
常用的方式:通过虚拟边连接2-hop的neighbors。将用于计算GNN的邻接矩阵A变为实现。(因为无权无权图邻接矩阵A 的n次幂的含义:每一个元素aij表示从节点i用n步走到
节点j有多少种路径)。
可以用在二部图上:例如作者-论文网络,相当于在一篇论文的共同作者/同作者的两篇论文间添加虚拟边,则可以直接交换信息,则GNN变浅运算速度加快

2.添加虚拟节点
虚拟节点会与图中的每一个节点相连。在一个稀疏图中,两个节点之间的最短路径距离很大,添加虚拟节点后,任意两个节点之间的距离变为2,添加虚拟节点之后图中节点的距离会更小,节点间传递message会更有效更快,图神经网络的深度也不用那么大。

Node Neighborhood Sampling
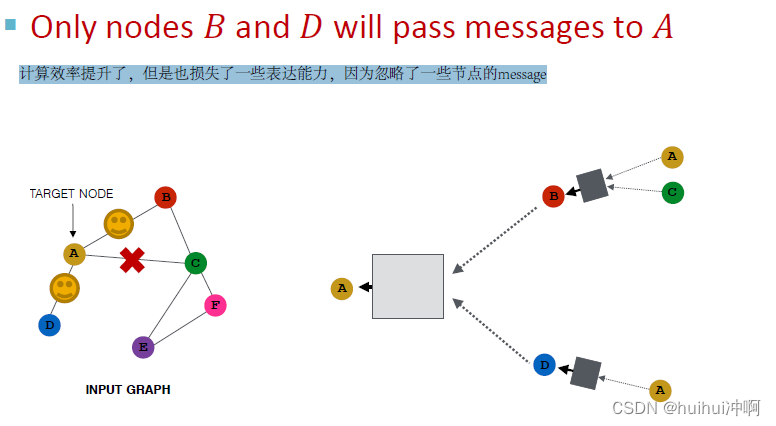
以前的做法是图中所有的节点都用于messag传递,如果图中边太多(dense)或者图太大,则高degree的节点要从所有邻居节点AGG message太expensive。
idea:可以采样邻居节点用于message传递
在不同一层或者不同epoch training时对一个节点的邻居节点可以用不同的sample方法(采样不同的点),当图很大时,用sample的方法可以使GNN变小很多,将其缩放为大量小图,计算效率提升了,极大的减少了计算cost,但是也损失了一些表达能力,因为忽略了一些节点的message。
Prediction with GNNS
不同的任务levels需要不同的prediction heads。Node-level prediction、Edge-level prediction Graph-level prediction
Node-level prediction
可以直接使用node embeddings做预测,在GNN计算后得到d维node embeddings,假设做k-way prediction(分类:有k个类别,回归:在k个targets),使用k*d维的矩阵W将d维embedding映射到k维输出预测y上,接着便可以计算损失

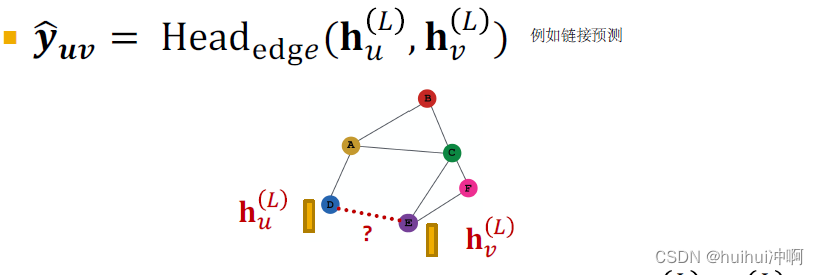
Edge-level prediction
使用node embeddings做预测,假设做k-way prediction,例如链接预测
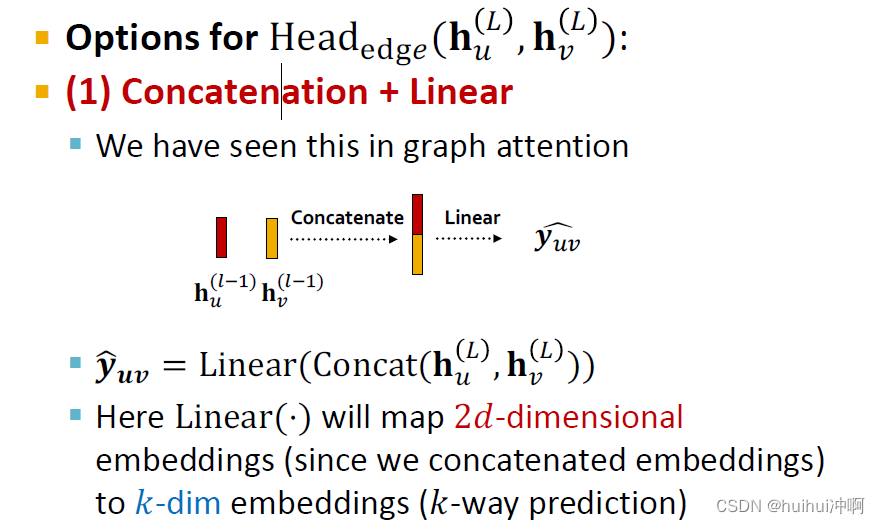
Head的选择1:Concatenation + Linear
将两个d维node embeddings拼接为一个2d维的向量,使用Linear将2维向量映射到k维向量
Head的选择2:Dot product

输出预测等于两个节点嵌入的点积。此方法仅适用于1-way预测(例如,链接预测:预测边的存在),如果想应用到k-way预测,则类似于多头注意力机制,使用k个参数矩阵W,点积乘W得到么一个预测,再将这些预测拼接起来。

Graph-level prediction
使用图中的所有节点embeddings做预测
类似于在GNN layer里的AGG(.)

Head的选择1:Global pooling
在小图上效果好。

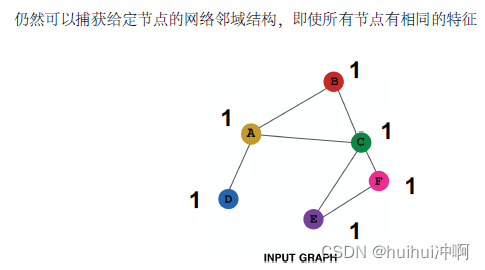
Global pooling 在 (large) graph 可能会丢失一些信息

可以看到G1于G2 者的图结构不同, 但Global pooling的结果相同,因此无法区分这两个图
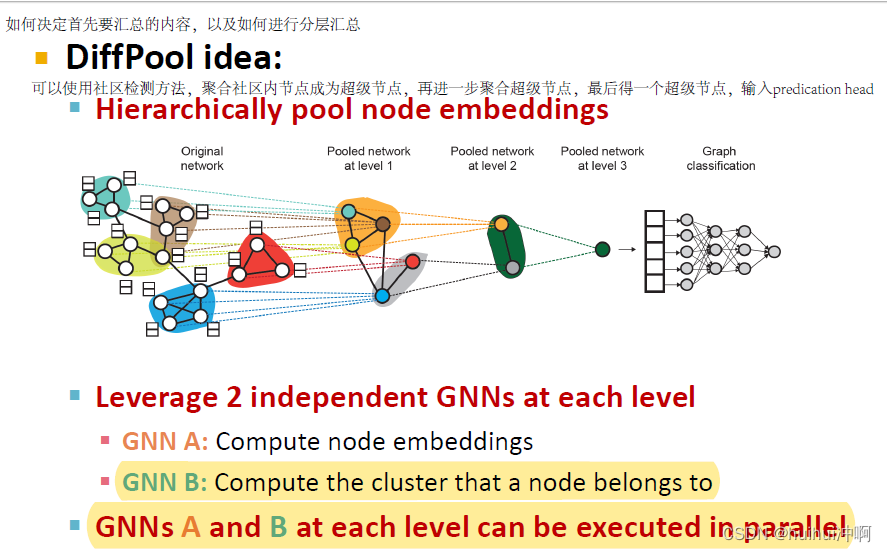
Head的选择2:Hierarchical Global Pooling
分层池化意味着不会将所有node embeddings同时汇合,而是先汇聚小子集内的节点,最后再将这些子集汇合到一起。

那应该决定汇聚节点子集的策略?使用社区检测的方法,聚合社区内节点成为超级节点,再进一步聚合超级节点,最后得一个超级节点,输入predication head。
在每个level使用2个独立的GNN:GNN A用于计算node embedding;GNN B 用于计算社区检测,计算节点属于哪个cluster。
在each pooling layer:
使用 GNN B 中的社区检测来聚合 GNN A 生成的节点嵌入
为每个cluster创建一个新的超级节点,留下clusters之间的 Edge 生成新的pooled network
GNN A和GNN B 可以并行训练。
Training Graph Neural Networks
Supervised&Unsupervised learning
ground-truth来自于Supervised labels与Unsupervised signals。Supervised learning是labels来自于外部,而Unsupervised learning的signals来自于图自身。两者的区别是监督信息来自于外部和内部的区别。
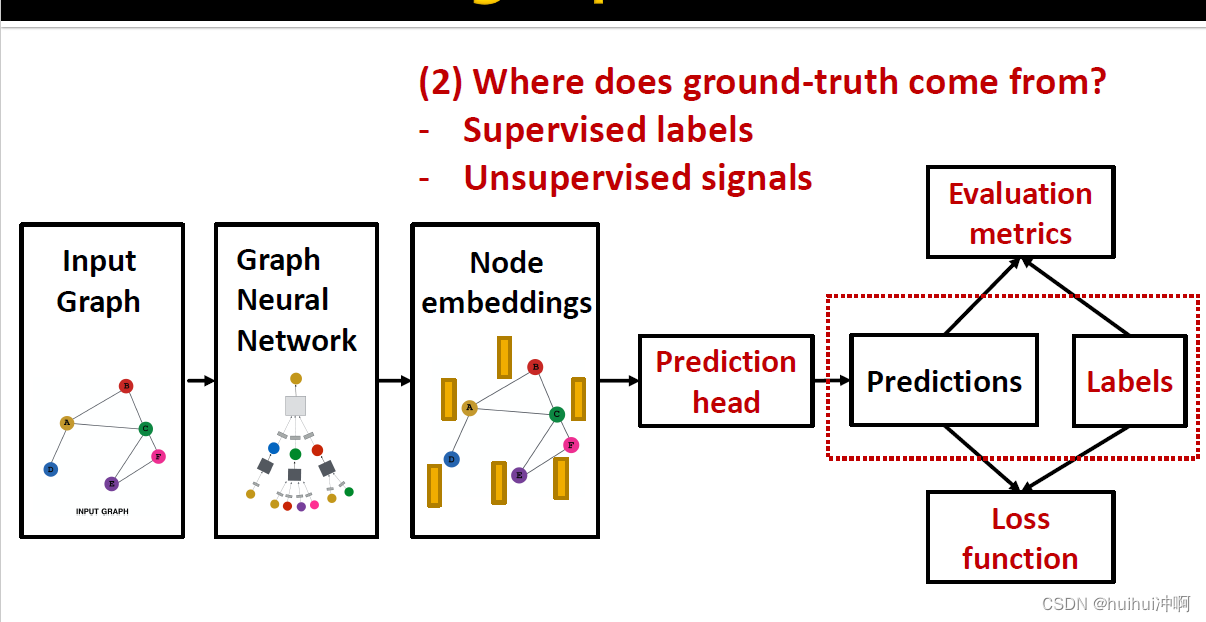



Final loss

Classification Loss
输出结果是离散值

Regression loss

Evaluation metrics
Regression evaluate

Classification evaluate
1.多分类
accuarcy

2.二分类
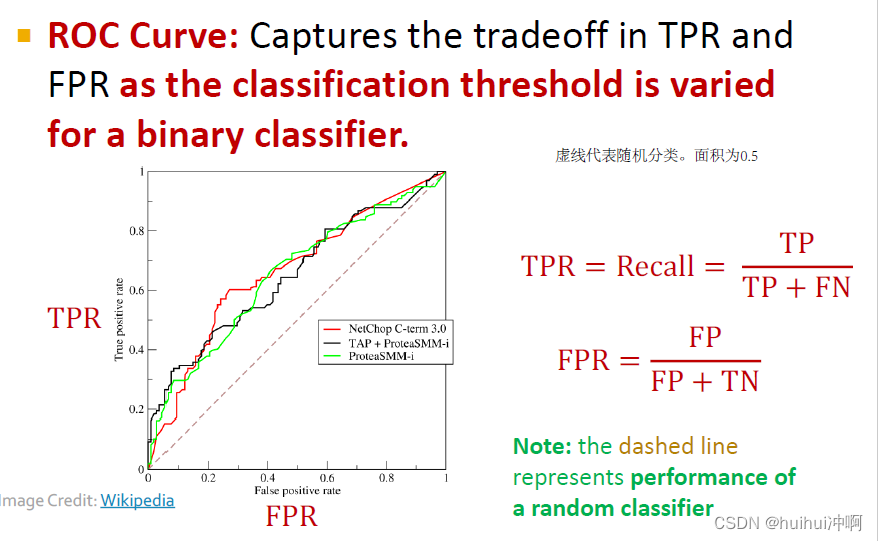
Accuracy、Precision / Recal。lf the range of prediction is [0,1], we will use 0.5 as threshold。metrics对分类阈值敏感,且在样本不均衡时,accuarcy可以被虚假分类器欺骗,例如将所有样本分为样本数多的类被,值也会很高。
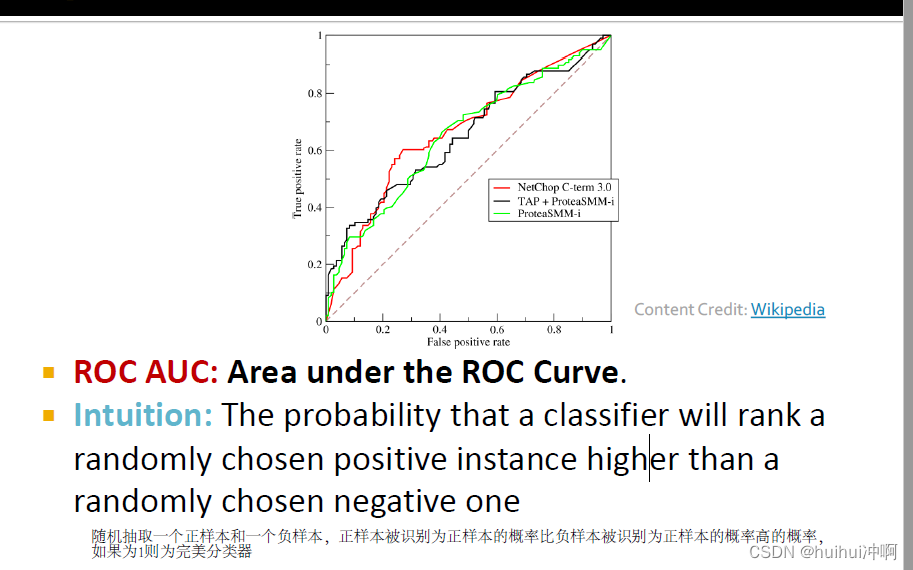
Metric对分类阈值不敏感的有ROC AUC
split dataset
Training set:用于优化GNN的参数
Validation set:develop model/超参数
Test set:保密直到用于最终的评价performance
但是不能保证test set最后没有信息泄露
当划分image数据集时,每一个数据点是一张image,数据之间相互独立,不会有信息泄露。
但是划分graph dataset是不同的,data points之间不相互独立,节点之间相互连接,存在信息泄露,测试集会收到验证集或者训练集节点传递的message。
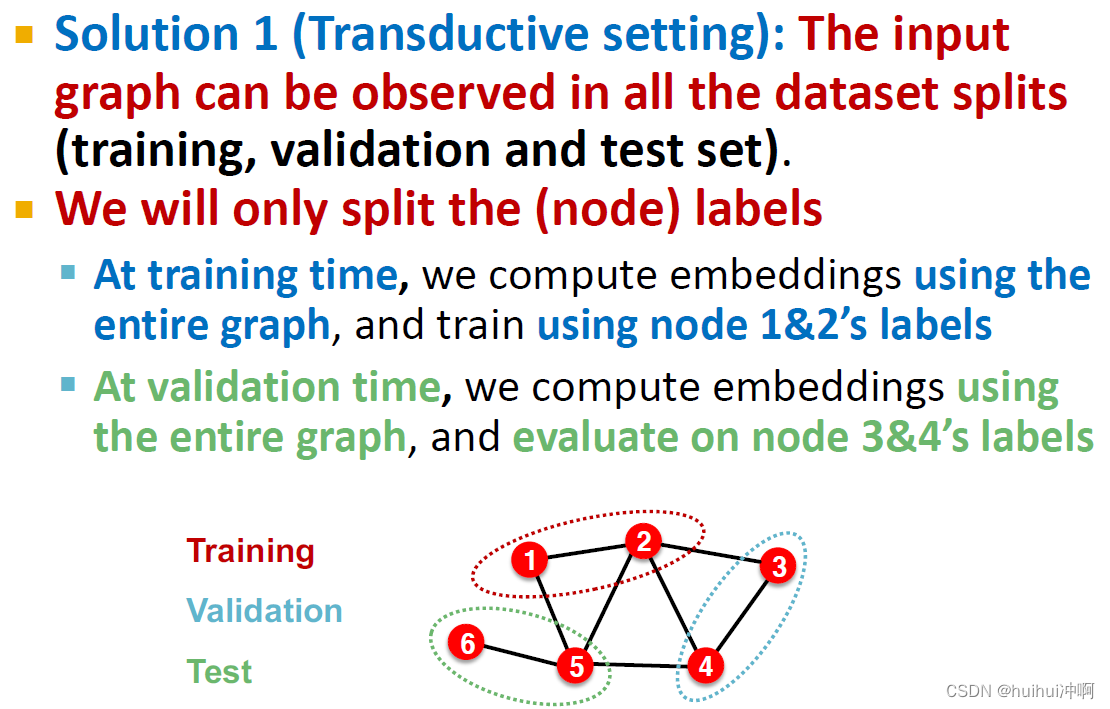
Transductive setting
training / validation / test sets are 在same graph上,dataset包含one graph;entire graph可以在所有的dataset splits上观察到,只划分labels,即在每个split上都可以看到完整的graph,但只能看到split的labels;只适用于node/edge预测任务。
Inductive setting
training / validation / test sets 在different graphs,dataset包含multiple graphs;
每个split只能观察split中的的图形。一个成功的模型应该推广到未见过的图形。适用于node/edge/graph任务。
移除边将entire分成multiple graphs,得到的多个graphs之间相互独立。这种做法会抛弃很多edge,会丢失很多图的信息,当graph很小时,最好不要采取。

Example: Node Classification

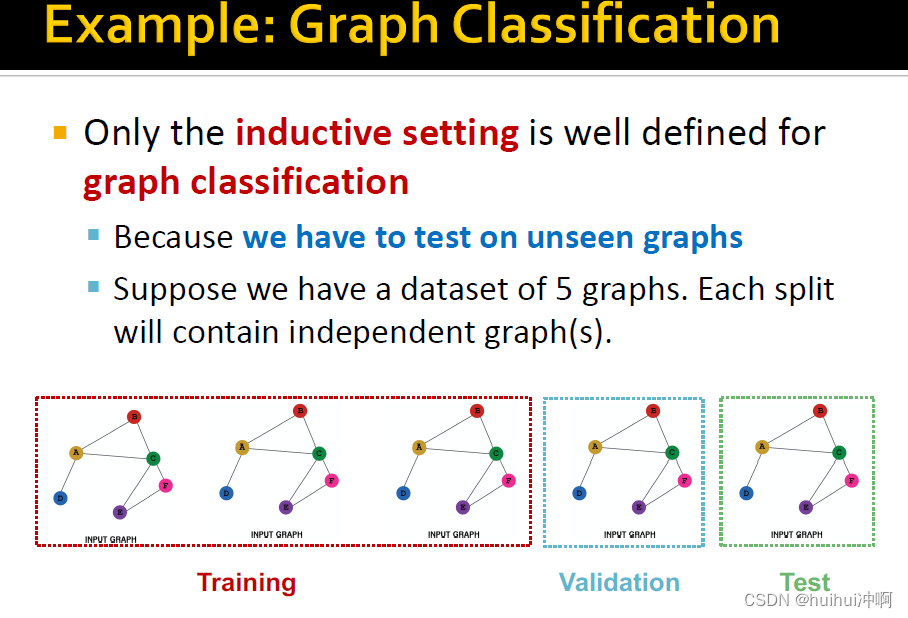
Example: Graph Classification
只有inductive setting可以用于graph classification,因为需要在未见过的test上,inductive可以推广到未见过的数据上。
Example: Link Prediction
link prediction的预测是tricky:link prediction是unsupervised / self-supervised任务,需要自己创建labels和dataset splits。因此,要隐藏GNN中的一些边,让GNN预测边是否存在。

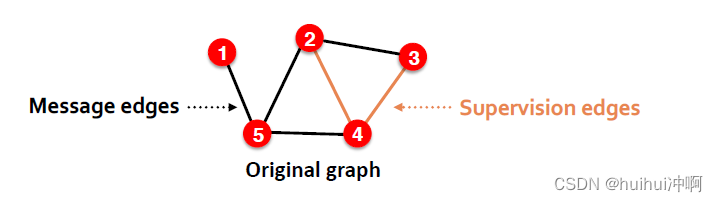
1.Step1:为original graph分配两种类型的边
Message edges:用于GNN的message passing
Supervision edges:用于计算objectives
在step1后,只有message edges会保留在图中,Supervision edges用于边预测时的监督信息,不会输入到GNN中。
Step 2: Split edges into train / validation / test
选择1:inductive边预测划分

选择2:Transductive 边预测划分
需要保密validation / test edges,为了训练 training set, 需要保密training set的supervision edges

在training time,使用training message edges预测training supervision edges。在validation time,使用training message edges & training supervision edges预测validation edges。在test time,使用training message edges & training supervision edges &validation edges预测test edges。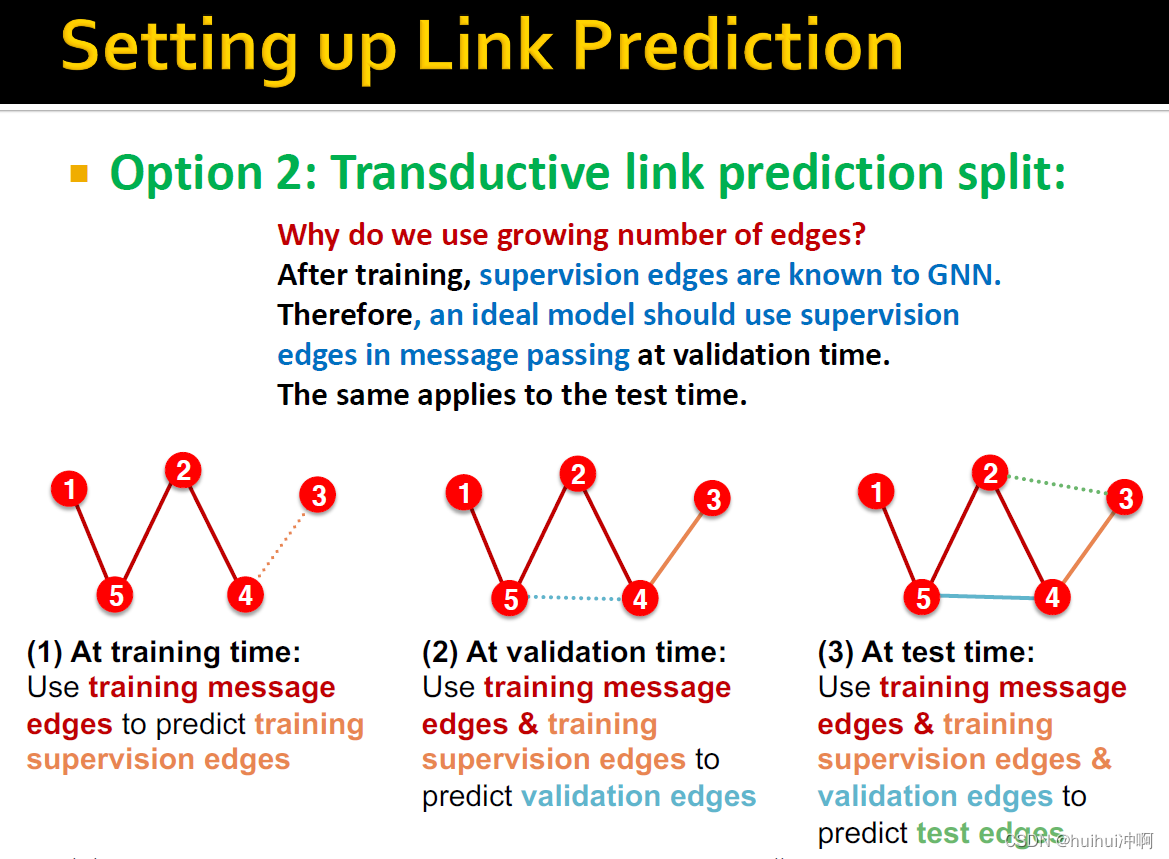
Transductive link prediction划分了四种类型的边:Training message edges Training supervision edges Validation edges Test edges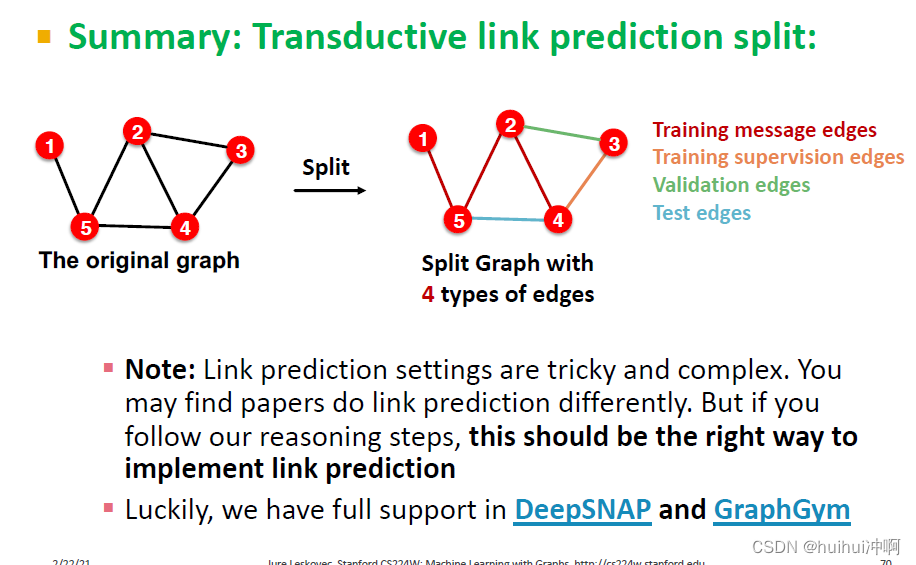
总结



![[激光原理与应用-33]:典型激光器 -5- 不同激光器的全面、综合比较](https://img-blog.csdnimg.cn/img_convert/a6e952d1db2cb2738699cdd607c033a3.jpeg)




![[附源码]计算机毕业设计基于SpringBoot的酒店预订系统设计与实现](https://img-blog.csdnimg.cn/6c7f662fc2b343b9a9e335bef0271842.png)