简介
- 噪声抑制技术用于消除背景噪声,改善语音信号的信噪比和可懂度,让人和机器听的更清楚
- 常见的噪声种类:人声噪声、街道噪声、汽车噪声
- 噪声抑制方法的分类:
- 按照输入通道数分:单通道降噪、多通道降噪
- 按照噪声统计特性分:平稳噪声抑制、非平稳噪声抑制
- 按照降噪方法分:被动降噪、主动降噪
- 下面介绍的方法用于单通道的、被动的、平稳噪声抑制
Minima Controlled Recursive Averaging(MCRA)
-
传统信号处理方法中降噪方法可分为两个大的步骤:
- 一是对噪声的估计(Noise Estimation/Tracking)
- 二是对增益因子的估计
-
噪声估计的常用方法:
- 递归平均(Recursive Averaging):只要某个频带中语音存在的概率很低,则可以利用这个频带估计/更新噪声谱
- 最小值追踪(Minima Controlled/Tracking):由于语音信号的稀疏性,即使语音存在,在一个短时窗内(0.5s-1.5s),每个频带的最小值也会大概率趋近于噪声功率,因此可以通过在短时窗内追踪最小值的方法获得每个频带的噪声估计
- 直方图统计(Histogram-based Method):带噪语音信号的每个频带在一个短时窗内做直方图统计,出现频次最高的值对应这个频带的噪声水平
-
MCRA的步骤:
-
考虑带有加性噪声的数据模型: y ( n ) = x ( n ) + d ( n ) y(n)=x(n)+d(n) y(n)=x(n)+d(n)
-
输入信号经过STFT: Y ( k , l ) = ∑ n = 0 N − 1 y ( n + l M ) h ( n ) e − j 2 π N n k Y(k,l)=\sum_{n=0}^{N-1}y(n+lM)h(n)e^{-j\frac{2\pi}{N}nk} Y(k,l)=∑n=0N−1y(n+lM)h(n)e−jN2πnk,得到时频谱图
-
其中,
- k是frequency bin的索引
- l是时间帧的索引
- h(n)是窗函数
- M是frame shift
-
给定两个假设 H 0 ( k , l ) H_0(k,l) H0(k,l)和 H 1 ( k , l ) H_1(k,l) H1(k,l),分别表示“语音不存在”和“语音存在”:
H 0 ( k , l ) : Y ( k , l ) = D ( k , l ) H 1 ( k , l ) : Y ( k , l ) = X ( k , l ) + D ( k , l ) \begin{aligned} H_0(k,l):&Y(k,l)=D(k,l) \\ H_1(k,l):&Y(k,l)=X(k,l)+D(k,l) \end{aligned} H0(k,l):H1(k,l):Y(k,l)=D(k,l)Y(k,l)=X(k,l)+D(k,l) -
对噪声的估计定义为: λ d ( k , l ) = E [ ∣ D ( k , l ) ∣ 2 ] \lambda_d(k,l)=E[|D(k,l)|^2] λd(k,l)=E[∣D(k,l)∣2],也就是噪声的能量
-
采用时间递归平滑的方式,当“语音不存在”时,迭代更新 λ d ( k , l ) \lambda_d(k,l) λd(k,l)
H 0 ′ ( k , l ) : λ ^ d ( k , l + 1 ) = α d λ ^ d ( k , l ) + ( 1 − α d ) ∣ Y ( k , l ) ∣ 2 H 1 ′ ( k , l ) : λ ^ d ( k , l + 1 ) = λ ^ d ( k , l ) 其中, α d ( 0 < α d < 1 )是平滑因子 \begin{aligned} H'_0(k,l):&\hat{\lambda}_d(k,l+1)=\alpha_d \hat{\lambda}_d(k,l)+(1-\alpha_d)|Y(k,l)|^2\\ H'_1(k,l):&\hat{\lambda}_d(k,l+1)=\hat{\lambda}_d(k,l) \\ 其中,&\alpha_d(0 < \alpha_d < 1)是平滑因子 \end{aligned} H0′(k,l):H1′(k,l):其中,λ^d(k,l+1)=αdλ^d(k,l)+(1−αd)∣Y(k,l)∣2λ^d(k,l+1)=λ^d(k,l)αd(0<αd<1)是平滑因子 -
语音存在概率(Speech Presence Probability): p ′ ( k , l ) = P ( H 1 ′ ( k , l ) ∣ Y ( k , l ) ) p'(k,l)=P(H'_1(k,l)|Y(k,l)) p′(k,l)=P(H1′(k,l)∣Y(k,l))
-
对噪声的估计可表示为:
λ ^ d ( k , l + 1 ) = λ ^ d ( k , l ) p ′ ( k , l ) + [ α d λ ^ d ( k , l ) + ( 1 − α d ) ∣ Y ( k , l ) ∣ 2 ] ( 1 − p ′ ( k , l ) ) = α ^ d ( k , l ) λ ^ d ( k , l ) + [ 1 − α ^ d ( k , l ) ] ∣ Y ( k , l ) ∣ 2 其中, α ^ d ( k , l ) = α d + ( 1 − α d ) p ′ ( k , l ) \begin{aligned} \hat{\lambda}_d(k,l+1)&=\hat{\lambda}_d(k,l)p'(k,l)+[\alpha_d \hat{\lambda}_d(k,l)+(1-\alpha_d)|Y(k,l)|^2](1-p'(k,l)) \\ &=\hat{\alpha}_d(k,l) \hat{\lambda}_d(k,l)+[1-\hat{\alpha}_d(k,l)]|Y(k,l)|^2 \\ 其中,\hat{\alpha}_d(k,l)&=\alpha_d+(1-\alpha_d) p'(k,l) \end{aligned} λ^d(k,l+1)其中,α^d(k,l)=λ^d(k,l)p′(k,l)+[αdλ^d(k,l)+(1−αd)∣Y(k,l)∣2](1−p′(k,l))=α^d(k,l)λ^d(k,l)+[1−α^d(k,l)]∣Y(k,l)∣2=αd+(1−αd)p′(k,l) -
现在的问题是:如何确定 p ′ ( k , l ) p'(k,l) p′(k,l)
-
计算 p ′ ( k , l ) p'(k,l) p′(k,l)的思路:在一个短时窗内,计算局部能量 S ( k , l ) S(k,l) S(k,l)与最小能量 S m i n ( k , l ) S_{min}(k,l) Smin(k,l)的比值
-
局部能量的计算:
- 频域平滑: S f ( k , l ) = ∑ i = − w w b ( i ) ∣ Y ( k − i , l ) ∣ 2 S_f(k,l)=\sum_{i=-w}^{w}b(i)|Y(k-i,l)|^2 Sf(k,l)=∑i=−wwb(i)∣Y(k−i,l)∣2
- 时域平滑: S ( k , l ) = α s S ( k , l − 1 ) + ( 1 − α s ) S f ( k , l ) S(k,l)=\alpha_sS(k,l-1)+(1-\alpha_s)S_f(k,l) S(k,l)=αsS(k,l−1)+(1−αs)Sf(k,l)
- b ( i ) b(i) b(i)是频域窗函数, α s ( 0 < α s < 1 ) \alpha_s(0<\alpha_s<1) αs(0<αs<1)是局部能量的时域平滑因子
-
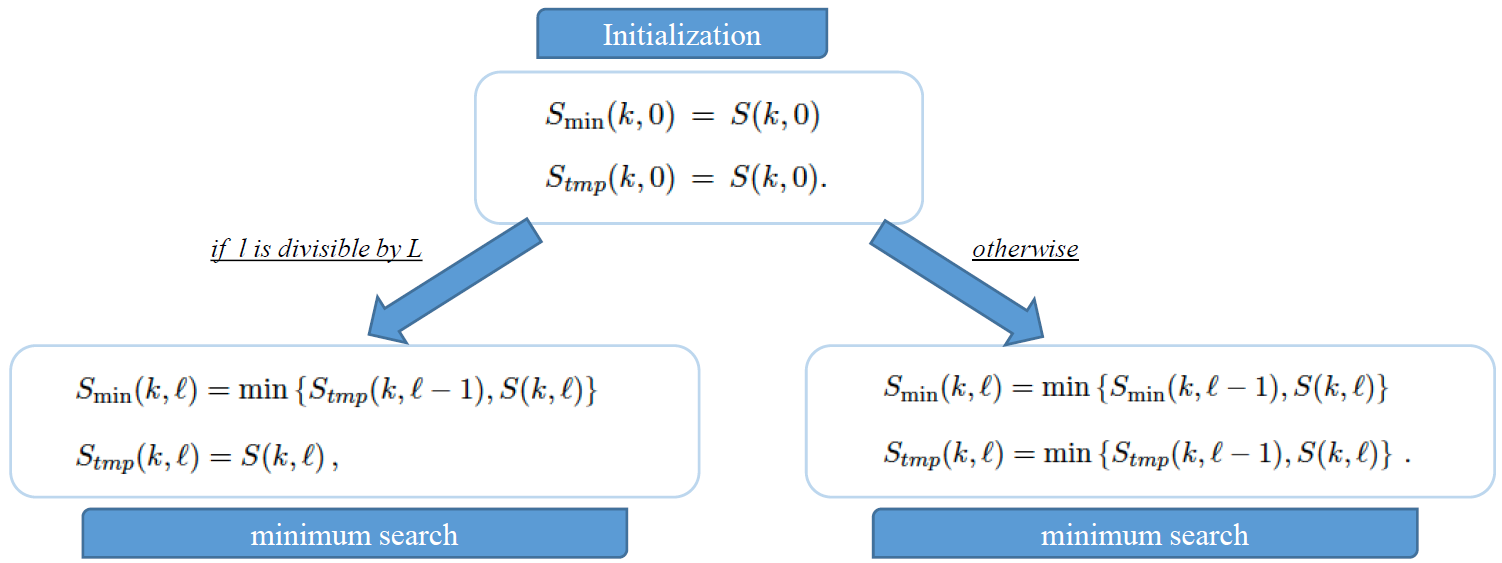
最小能量的计算:
- 常规做法:采用局部最小值搜索的方法,设定一个时间窗L(L通常为1s),搜索局部最小值
- 简化做法:
-
计算比值: S r ( k , l ) = S ( k , l ) S m i n ( k , l ) S_r(k,l)=\frac{S(k,l)}{S_{min}(k,l)} Sr(k,l)=Smin(k,l)S(k,l)
-
语音是否存在的判别式为:
I ( k , l ) = { 1 , S r ( k , l ) > δ 0 , o t h e r w i s e I(k,l)= \left\{\begin{matrix} 1,S_r(k,l)>\delta \\ 0,otherwise \end{matrix}\right. I(k,l)={1,Sr(k,l)>δ0,otherwise -
语音存在概率的迭代估计:
- p ^ ′ ( k , l ) = α p p ^ ′ ( k , l − 1 ) + ( 1 − α p ) I ( k , l ) \hat{p}'(k,l)=\alpha_p\hat{p}'(k,l-1)+(1-\alpha_p)I(k,l) p^′(k,l)=αpp^′(k,l−1)+(1−αp)I(k,l)
- α p ( 0 < α p < 1 ) \alpha_p(0<\alpha_p<1) αp(0<αp<1)是语音存在概率的平滑因子
-
MCRA噪声估计流程:

-
MCRA参考参数

-
估计出噪声后,将带噪语音与增益因子相乘,即可进行噪声抑制
X ^ ( k , l ) = G ( k , l ) Y ( k , l ) 或 ∣ X ^ ( k ) ∣ 2 = G 2 ( k ) ∣ Y ( k ) ∣ 2 \begin{aligned} \hat{X}(k,l)&=G(k,l)Y(k,l) \\ 或 |\hat{X}(k)|^2&=G^2(k)|Y(k)|^2 \end{aligned} X^(k,l)或∣X^(k)∣2=G(k,l)Y(k,l)=G2(k)∣Y(k)∣2 -
确定增益因子的方法:
- 谱减法
- 维纳滤波
- MMSE
-
谱减法:假设噪声平稳或缓慢变化,从带噪语音谱中,将噪声谱减去
- 增益因子的表达式:
G ( k ) = ∣ X ^ ( k ) ∣ 2 ∣ Y ( k ) ∣ 2 = ∣ Y ( k ) ∣ 2 − ∣ D ^ ( k ) ∣ 2 ∣ Y ( k ) ∣ 2 = ∣ Y ( k ) ∣ 2 − λ d ( k ) ∣ Y ( k ) ∣ 2 = 1 − λ d ( k ) ∣ Y ( k ) ∣ 2 = 1 − 1 γ ( k ) \begin{aligned} G(k)&=\sqrt{\frac{|\hat{X}(k)|^2}{|Y(k)|^2}} \\ &=\sqrt{\frac{|Y(k)|^2-|\hat{D}(k)|^2}{|Y(k)|^2}}=\sqrt{\frac{|Y(k)|^2-\lambda_d(k)}{|Y(k)|^2}} \\ &=\sqrt{1-\frac{\lambda_d(k)}{|Y(k)|^2}}=\sqrt{1-\frac{1}{\gamma(k)}} \end{aligned} G(k)=∣Y(k)∣2∣X^(k)∣2=∣Y(k)∣2∣Y(k)∣2−∣D^(k)∣2=∣Y(k)∣2∣Y(k)∣2−λd(k)=1−∣Y(k)∣2λd(k)=1−γ(k)1 - 其中, γ ( k ) = ∣ Y ( k ) ∣ 2 λ d ( k ) \gamma(k)=\frac{|Y(k)|^2}{\lambda_d(k)} γ(k)=λd(k)∣Y(k)∣2,被称为后验信噪比
- 增益因子的表达式:
-
频域维纳滤波:估计出的纯净语音幅度谱与真实幅度谱的均方误差最小
- 频域估计误差: E ( k ) = X ( k ) − X ^ ( k ) = X ( k ) − G ( k ) Y ( k ) E(k)=X(k)-\hat{X}(k)=X(k)-G(k)Y(k) E(k)=X(k)−X^(k)=X(k)−G(k)Y(k)
- 目标函数: J = E [ ∣ E ( k ) ∣ 2 ] J=E[|E(k)|^2] J=E[∣E(k)∣2]
- 最小化目标函数,可以得到增益因子的表达式:
G ( k ) = λ x ( k ) λ x ( k ) + λ d ( k ) = ξ ( k ) ξ ( k ) + 1 G(k)=\frac{\lambda_x(k)}{\lambda_x(k)+\lambda_d(k)}=\frac{\xi(k)}{\xi(k)+1} G(k)=λx(k)+λd(k)λx(k)=ξ(k)+1ξ(k) - 其中, λ x ( k ) = E [ ∣ X ( k ) ∣ 2 ] \lambda_x(k)=E[|X(k)|^2] λx(k)=E[∣X(k)∣2], ξ ( k ) = λ x ( k ) λ d ( k ) \xi(k)=\frac{\lambda_x(k)}{\lambda_d(k)} ξ(k)=λd(k)λx(k)被称为先验信噪比
- 后验信噪比: γ ( k ) = ∣ Y ( k ) ∣ 2 λ d ( k ) \gamma(k)=\frac{|Y(k)|^2}{\lambda_d(k)} γ(k)=λd(k)∣Y(k)∣2
- 先验信噪比: ξ ( k ) = λ x ( k ) λ d ( k ) \xi(k)=\frac{\lambda_x(k)}{\lambda_d(k)} ξ(k)=λd(k)λx(k)
- 根据后验信噪比估计先验信噪比——判决引导法(Decision Directed,DD)
ξ ( k , l ) = α D D ∣ X ^ ( k , l − 1 ) ∣ 2 λ d ( k , l − 1 ) + ( 1 − α D D ) m a x { γ ( k , l ) − 1 , 0 } \xi(k,l)=\alpha_{DD}\frac{|\hat{X}(k,l-1)|^2}{\lambda_d(k,l-1)}+(1-\alpha_{DD})max\{ \gamma(k,l)-1,0 \} ξ(k,l)=αDDλd(k,l−1)∣X^(k,l−1)∣2+(1−αDD)max{γ(k,l)−1,0} - 其中, α D D \alpha_{DD} αDD经验值为0.95~0.98, λ d ( k , l − 1 ) \lambda_d(k,l-1) λd(k,l−1)可用 λ d ( k , l ) \lambda_d(k,l) λd(k,l)代替
-
MMSE的增益因子:
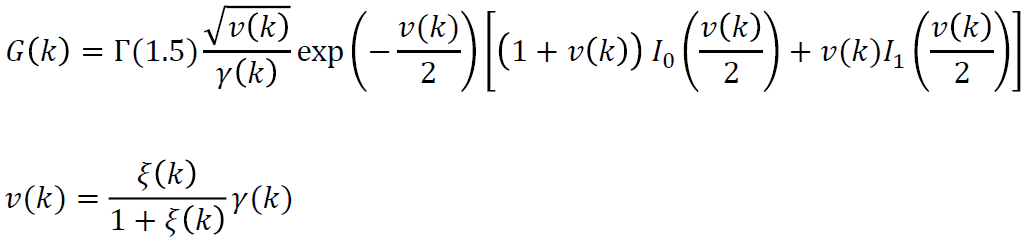
-
MMSE的推导可参考:Ephraim, Y., and D. Malah. “Speech Enhancement Using a Minimum-Mean Square Error Short-Time Spectral Amplitude Estimator.”