学习目标/Target
了解数据可视化系统架构
掌握Phoenix集成HBase
熟悉建立Phoenix与HBase表映射
了解Spring Boot项目的创建
掌握Java Web项目中实体类的创建
掌握Java Web项目中数据库访问接口的创建
掌握Java Web项目中控制器类的创建
熟悉Java Web项目中HTML页面的创建
熟悉如何运行Spring Boot项目
概述
数据可视化是指将数据或信息表示为图形中的可视对象来传达数据或信息的技术,目标是清晰有效地向用户传达信息,以便用户可以轻松了解数据或信息中的复杂关系。用户可以通过图形中的可视对象直观地看到数据分析结果,从而更容易理解业务变化趋势或发现新的业务模式。数据可视化是数据分析中的一个重要步骤。本章将详细讲解如何搭建数据可视化系统,展示本项目的分析结果数据。
1. 系统概述
1.1 技术选取


SpringBoot 的设计目的是为了简化Spring应用的初始搭建以及开发过程,摆脱复杂的手动配置,能迅速搭建起一个Java Web项目。

MyBatis是一个开源的数据持久层框架,其内部封装了JDBC访问数据库的操作,支持普通的SQL查询、存储过程和高级映射。

Echarts是一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,提供了多种丰富的可视化类型。
 多学一招:Phoenix查询引擎与MyBatis
多学一招:Phoenix查询引擎与MyBatis
MyBatis是一个支持SQL查询的数据持久层框架,而项目所用到的HBase数据库是不支持JDBC访问和SQL语句查询的,这就导致我们搭建的数据可视化系统无法使用MyBatis框架访问HBase数据库。因此,需要借助Apache Phoenix查询引擎使得HBase支持通过JDBC的方式进行访问,并将SQL查询转成 HBase的相关操作。 
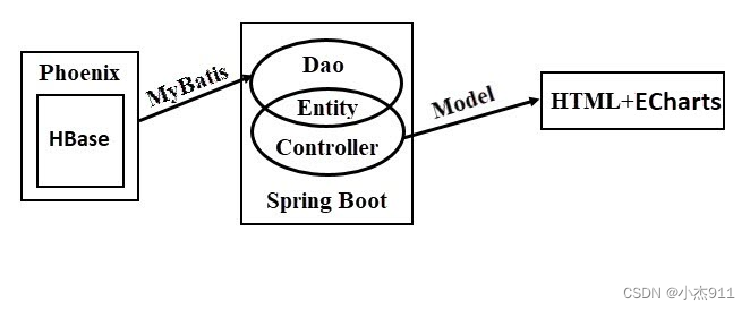
1.2 系统架构
离线数据可视化展示

实时数据可视化展示


2. 数据表设计与实现
2.1 数据表介绍
热门品类Top10分析结果表user_session_top10
| 字段名称 | 数据类型 | 相关说明 |
| ROW | varchar | 主键(对应HBase表中的RowKey) |
| cartcount | varchar | 品类中商品被加入购物车的总次数 |
| category_id | varchar | 品类id |
| purchasecount | varchar | 品类中商品被购买的总次数 |
| viewcount | varchar | 品类中商品被查看的总次数 |
各区域热门商品Top3分析结果表user_session_top3
| 字段名称 | 数据类型 | 相关说明 |
| ROW | varchar | 主键(对应HBase表中的RowKey) |
| product_id | varchar | 商品id |
| viewcount | varchar | 商品被查看的总次数 |
| area | varchar | 区域名称 |
页面单跳转化率统计表conversion
| 字段名称 | 数据类型 | 相关说明 |
| ROW | varchar | 主键(对应HBase表中的RowKey) |
| convert_page | varchar | 转换页面(网页切片) |
| convert_rage | varchar | 转换率 |
用户广告点击流实时统计表adstream
| 字段名称 | 数据类型 | 相关说明 |
| ROW | varchar | 主键(对应HBase表中的RowKey) |
| city | varchar | 城市名称 |
| ad_count | varchar | 广告点击次数 |
| ad_id | varchar | 广告id |
2.2 Phoenix集成HBase

在虚拟机Spark01中安装Phoenix并集成HBase。
STEP 01
下载Phoenix安装包:
访问Phoenix官网下载Linux操作系统的Phoenix安装包apache-phoenix-4.14.1-HBase-1.2-bin.tar.gz。
STEP 02
上传Phoenix安装包:
使用SecureCRT远程连接工具连接虚拟机Spark01,在存放应用安装包的目录/export/software/下执行“rz”命令上传Phoenix安装包。
STEP 03
安装Phoenix:
通过解压缩的方式安装Phoenix,将Phoenix安装到存放应用的目录/export/servers/。
tar -zxvf /export/software/apache-phoenix-4.14.1-HBase-1.2-bin.tar.gz -C /export/servers/
STEP 04
Phoenix集成HBase(拷贝jar包):
进入Phoenix安装目录,将phoenix-core-4.14.1-HBase-1.2.jar和phoenix-4.14.1-HBase-1.2-client.jar拷贝到HBase安装目录的lib目录下。
$ cd /export/servers/apache-phoenix-4.14.1-HBase-1.2-bin/
$ cp {phoenix-core-4.14.1-HBase-1.2.jar,phoenix-4.14.1-HBase-1.2-client.jar} /export/servers/hbase-1.2.1/lib/
STEP 05
Phoenix集成HBase(关闭HBase集群):
执行“stop-hbase.sh”命令关闭HBase集群。
STEP 06
Phoenix集成HBase(修改HBase配置文件):
进入HBase安装目录下的conf目录,执行“vi hbase-site.xml”命令编辑hbase-site.xml文件,添加命名空间映射配置。
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
STEP 07
Phoenix集成HBase(分发文件):
将HBase安装目录分发到集群中的其它两台虚拟机Spark02和Spark03。
scp -r /export/servers/hbase-1.2.1/ root@spark02:/export/servers/
scp -r /export/servers/hbase-1.2.1/ root@spark03:/export/servers/
STEP 08
Phoenix集成HBase(复制HBase配置文件):
进入HBase安装目录下的conf目录,将hbase-site.xml文件复制到Phoenix安装目录下的bin目录。
cp hbase-site.xml /export/servers/apache-phoenix-4.14.1-HBase-1.2-bin/bin/
STEP 09
Phoenix集成HBase(启动HBase集群):
执行“start-hbase.sh”命令启动HBase集群。


在启动HBase集群前应确保Hadoop和Zookeeper集群正常启动,且保证集群各服务间时间一致,若出现时间不一致情况,则需要在各服务器执行“systemctl restart chronyd”命令重启chronyd服务进行时间同步。
2.3 建立Phoenix与HBase表映射

操作Phoenix,建立Phoenix与HBase表映射。
Phoenix提供三种操作方式,即命令行界面、JDBC和Squirrel,其中命令行界面是Phoenix默认提供的交互工具sqlline;JDBC是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口;Squirrel是Phoenix的客户端工具提供可视化操作窗口。

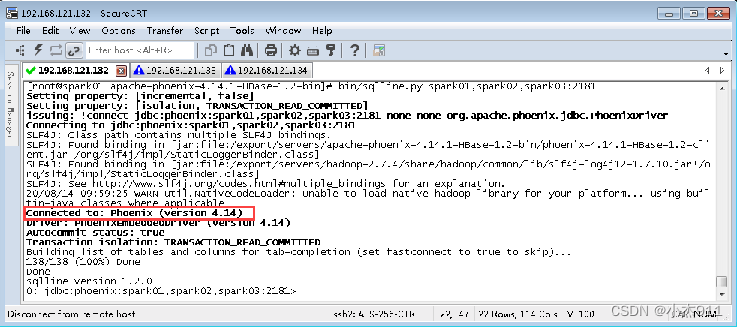
连接Phoenix:
在Phoenix安装目录的bin目录中存在Python脚本文件sqlline.py用于启动sqlline,在启动sqlline时需要输入Zookeeper集群地址及端口号连接Phoenix。
#进入Phoenix安装目录 $ cd /export/servers/apache-phoenix-4.14.1-HBase-1.2-bin
#启动sqlline
$ bin/sqlline.py spark01,spark02,spark03:2181

查看Phoenix表及视图:
在sqlline中执行“!table”命令查看Phoenix表及视图。
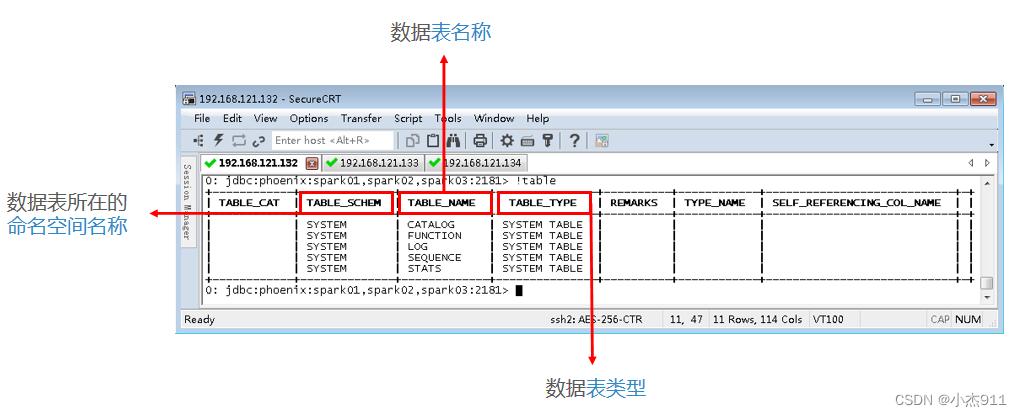

建立表映射(top10):
通过CREATE语句在Phoenix中创建表top10建立与HBase数据库中表top10 的映射。
> create table "top10"
> (
> "ROW" varchar primary key,
> "top10_category"."cartcount" varchar,
> "top10_category"."category_id" varchar ,
> "top10_category"."purchasecount" varchar ,
> "top10_category"."viewcount" varchar
> ) column_encoded_bytes=0;

建立表映射(top3)。 通过CREATE语句在Phoenix中创建表top3建立与HBase数据库中表top3 的映射。
> create table "top3"
> (
> "ROW" varchar primary key,
> "top3_area_product"."product_id" varchar,
> "top3_area_product"."viewcount" varchar,
> "top3_area_product"."area" varchar
> ) column_encoded_bytes=0;

建立表映射(conversion):
通过CREATE语句在Phoenix中创建表conversion建立与HBase数据库中表conversion的映射。
> create table "conversion"
> (
> "ROW" varchar primary key,
> "page_conversion"."convert_page" varchar,
> "page_conversion"."convert_rage" varchar
> ) column_encoded_bytes=0;

建立表映射(adstream):
通过CREATE语句在Phoenix中创建表adstream建立与HBase数据库中表adstream的映射。
> create table "adstream"
> (
> "ROW" varchar primary key,
> "area_ads_count"."city" varchar,
> "area_ads_count"."ad_count" varchar,
> "area_ads_count"."ad_id" varchar
> ) column_encoded_bytes=0;

Phoenix的命令区分大小写,如果不加双引号,则默认为大写,因此在Phoenix中执行创建表的命令时需要在表名、列族名和列名处添加双引号。
若在Phoenix中执行删除表操作,则HBase中具有映射关系的表也会一同被删除,导致数据丢失。如果Phoenix中创建的映射表只是用于查询操作,则建议使用创建视图的方式建立映射,建立视图映射的方式与建立表映射的方式一致,这里以建立视图adstream的映射为例。
> create view "adstream"
> ( > "ROW" varchar primary key,
> "area_ads_count"."city" varchar,
> "area_ads_count"."ad_count" varchar,
> "area_ads_count"."ad_id" varchar
> );
如果想要删除Phoenix中的表,又不想在删除Phoenix表的同时删除HBase中的映射表,造成数据的丢失,那么可以在Phoenix中执行删除表操作前,在HBase中创建映射表的快照。
disable '映射表'
#关闭表 snapshot '映射表', '快照名称'
#创建快照
在Phoenix中执行删除表操作后,在HBase中通过创建的快照恢复映射表。
list_snapshots #查询所有快照
clone_snapshot '快照名称', '映射表' #克隆快照赋予新的表
3. 创建Spring Boot项目
 通过IntelliJ IDEA开发工具创建并配置Spring Boot项目,为数据可视化系统的实现奠定基础。
通过IntelliJ IDEA开发工具创建并配置Spring Boot项目,为数据可视化系统的实现奠定基础。
步骤一:创建项目
打开IntelliJ IDEA开发工具,使用Spring Initializr初始化Spring Boot项目,构建Spring Boot项目结构。
选择使用的JDK版本
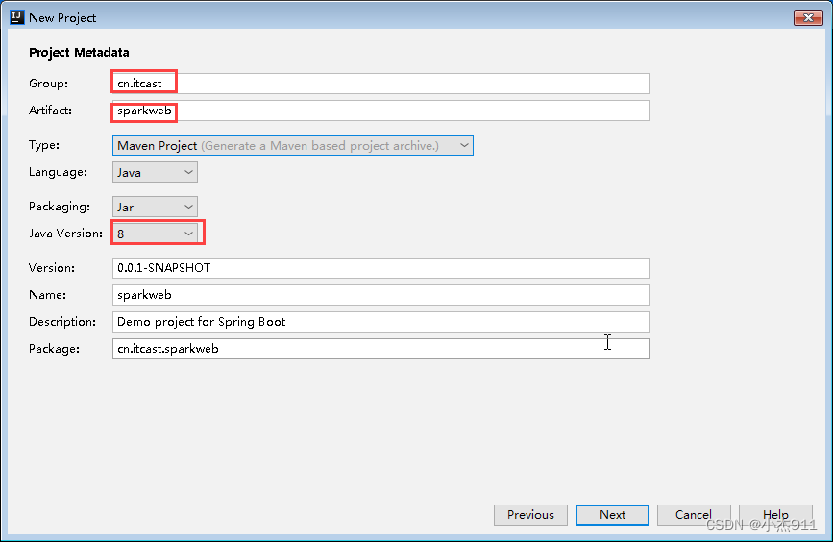
步骤二:配置项目信息
在“Project Metadata”界面配置项目基本信息。
项目组织唯一标识符
项目唯一的标识符
JDK版本
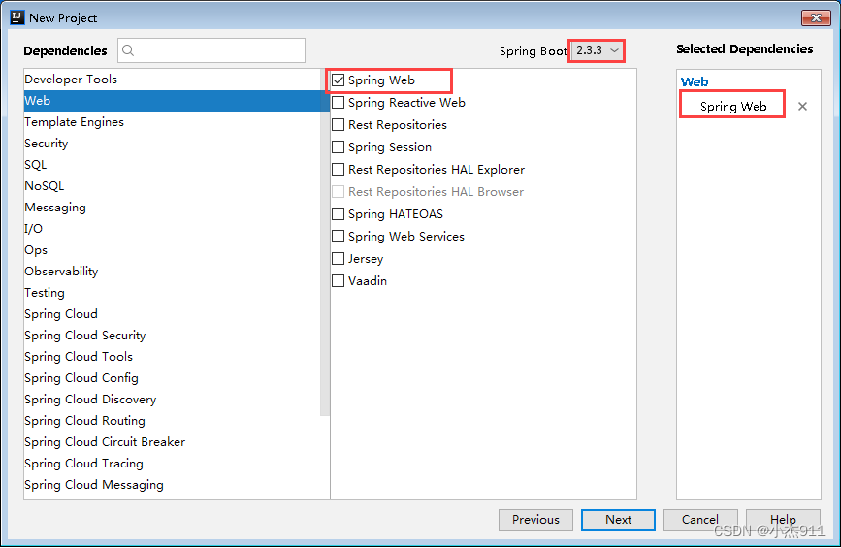
步骤三:配置项目依赖关系
在“Dependencles”界面配置项目依赖关系。
选择使用Spring Boot的版本
添加Spring Web依赖
步骤四:配置项目名称和目录
配置项目名称
配置项目目录

步骤五:初始化项目
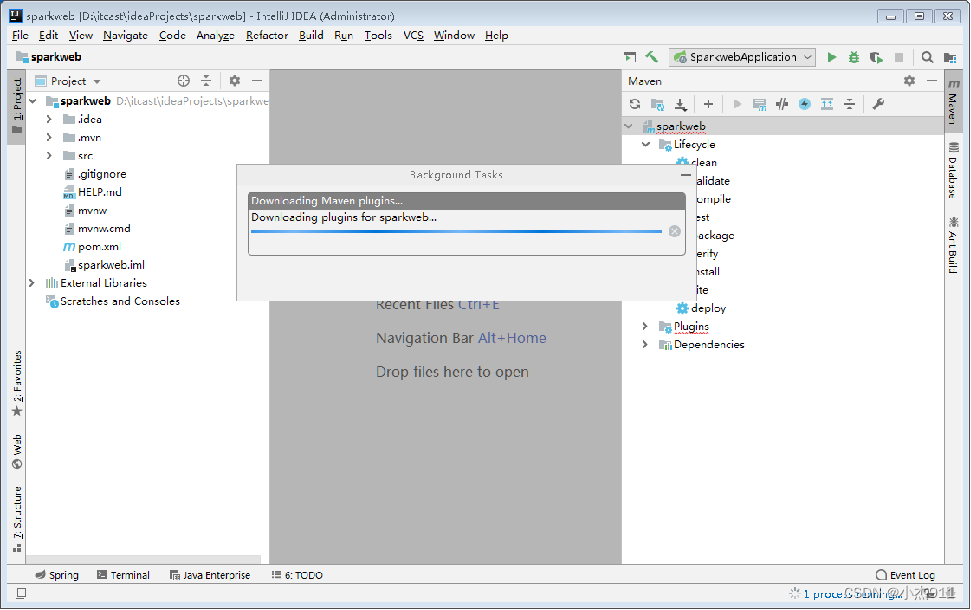
步骤六:初始化完成后的目录结构
Spring Boot项目默认会生成项目启动类
静态资源文件夹(static)
模板页面文件夹(templates)
项目全局配置文件(application.properties)
Spring Boot项目默认会生成项目测试类
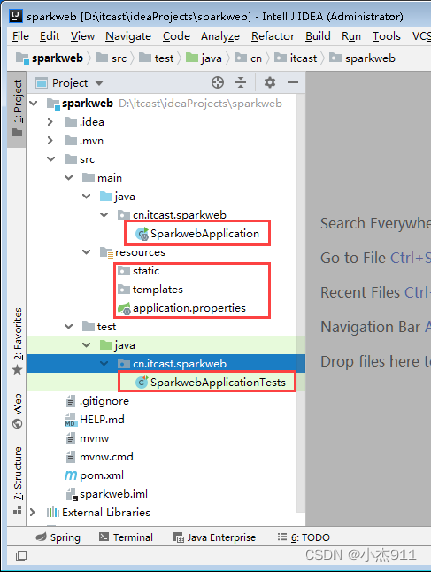
步骤七:调整项目目录结构
为了便于区分项目中不同类的功能,这里对项目默认的目录结构进行调整,在包“cn.itcast.sparkweb”下创建用于存放实体类的包entity、存放数据访问接口的包dao和存放控制器类的包controller。
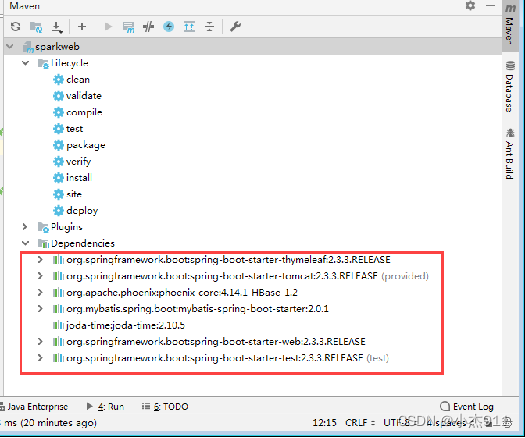
步骤八:配置项目依赖
本项目所需要的依赖包括Thymeleaf、Tomcat、Phoenix、MyBatis和Joda-Time。其中Thymeleaf是一个模板引擎用于Java Web应用程序开发;Tomcat是Web容器用于运行Java Web应用程序;Phoenix用于在项目中通过Java API操作Phoenix;MyBatis用于在项目中使用MyBatis框架;Joda-Time是Java日期时间处理库。
步骤八:配置项目全局配置文件
在项目的resources目录配置全局配置文件application.properties,添加如下配置内容:
#设置连接Phoenix的JDBC驱动器
spring.datasource.driver-class-name=org.apache.phoenix.jdbc.PhoenixDriver
#设置Phoenix连接地址及端口号 spring.datasource.url=jdbc:phoenix:192.168.121.132,192.168.121.133,192.168.121.134:2181 #设置Thymeleaf模板路径
spring.thymeleaf.prefix=classpath:/templates/
# 设置Thymeleaf模板后缀名
spring.thymeleaf.suffix=.html
4. 实现热门品类Top10数据可视化
4.1 创建实体类Top10Entity
为了便于热门品类Top10分析结果数据的传递,在项目的entity包中创建实体类Top10Entity,存储Phoenix中表top10的数据。
public class Top10Entity {
private String cartcount;
private String category_id;
private String purchasecount;
private String viewcount;
//实现属性的getter/setter方法
...
}
4.2 创建数据库访问接口Top10Dao
在项目的dao包中创建一个数据库访问接口Top10Dao,读取Phoenix中表top10的数据。
import cn.itcast.sparkweb.entity.Top10Entity;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface Top10Dao {
@Select("select \"cartcount\",\"category_id\",\"purchasecount\",\"viewcount\" from \"top10\"")
List<Top10Entity> getTop10();
}
4.3 创建控制器类Top10Controller
在项目的controller包中创建控制器类Top10Controller,用于实现接口Top10Dao中的方法getTop10()读取表top10的数据,通过Model对象向HTML传递数据。
@Controller public class Top10Controller {
@Autowired
private Top10Dao top10Dao;
@RequestMapping(value = "/top10",produces = "text/html;charset=utf-8")
public String top10(Model model) {
List<Top10Entity> top10 = top10Dao.getTop10(); model.addAttribute("top10",top10);
return "top10";
}
}

若在Top10Controller中的接口上添加Autowired注解时,程序报错,报错的内容为“Could not autowire. No beans of ‘ Top10Dao’ type found.”,这是IntelliJ IDEA内置的检查工具导致,并不影响程序的启动和编译,可以参照如图所示内容消除此问题。
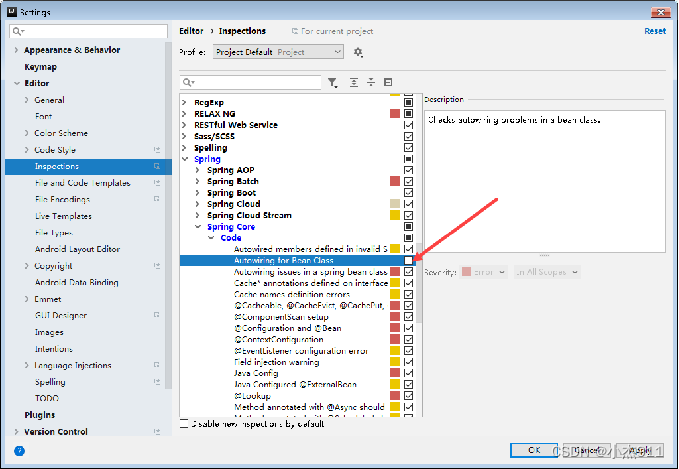
4.4 创建HTML文件top10.html
在项目中的templates目录下创建HTML文件top10.html,在该文件中通过jQuery获取Model对象传递到HTML的热门品类Top10的数据,并将获取到的数据填充到ECharts柱状图模板中,实现热门品类Top10数据的可视化展示。
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>top10</title>
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js"></script>
</head>
<body> …… </body>
</html>
4.5 运行项目实现热门品类Top10数据可视化
为了避免JDBC无法操作Phoenix的问题,在运行项目前需要在项目的resources目录下创建Hbase-site.xml文件,在文件中添加开启命名空间和支持二级索引配置。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
<description>开启命名空间</description>
</property>
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
<description>支持二级索引</description>
</property>
</configuration>
单击IntelliJ IDEA中的【启动】按钮运行项目。
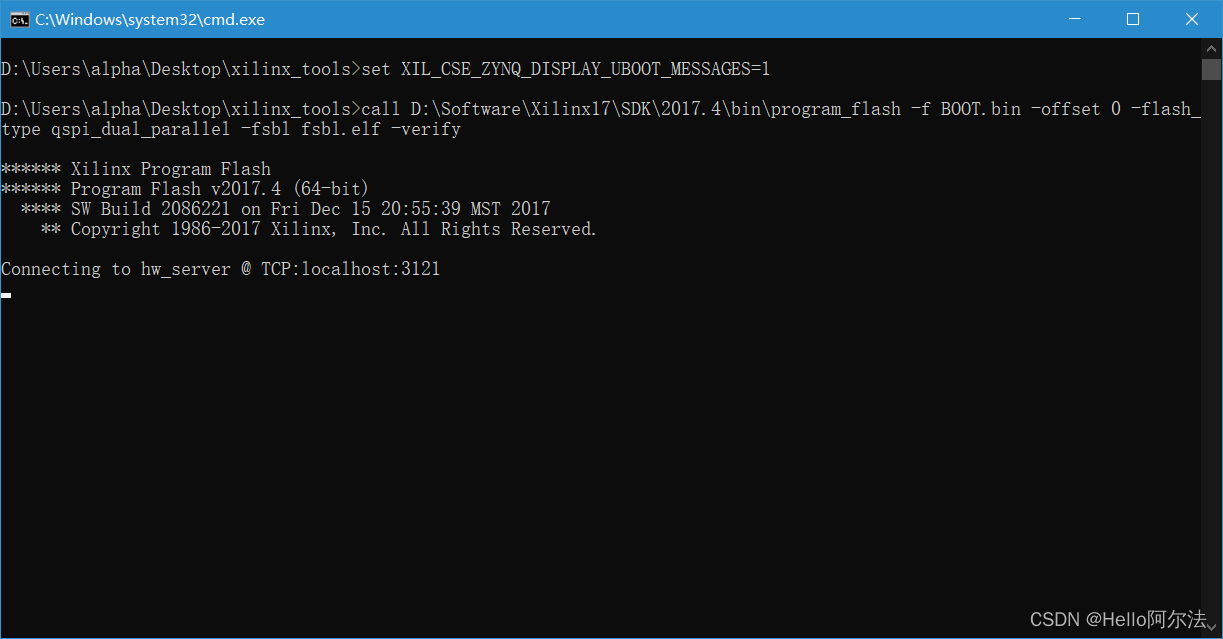
在IntelliJ IDEA控制台可查看项目的启动信息。
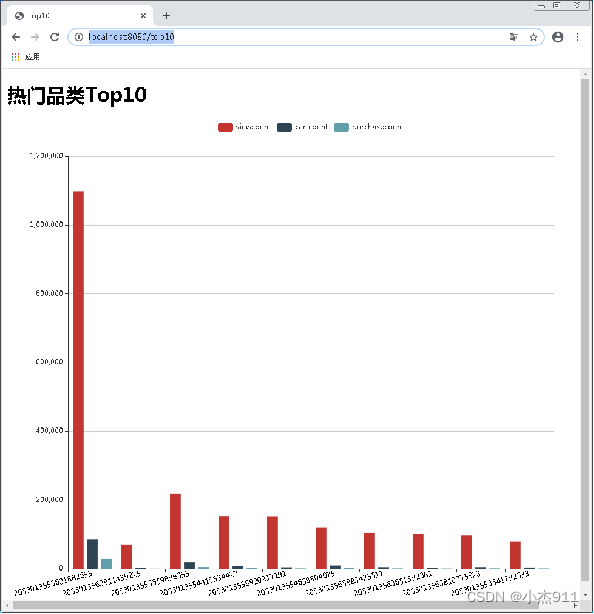
在浏览器中输入“http://localhost:8080/top10”查看热门品类Top10数据可视化的展示效果。

首先,通过解压缩的方式在Windows操作系统中安装Hadoop;然后,将Hadoop添加到系统环境变量中,如图所示。

在Windows操作系统的C:\Windows\System32\drivers\etchost目录下编辑映射文件host,添加如下内容。
192.168.121.132 spark01
192.168.121.133 spark02
192.168.121.134 spark03
5. 实现各区域热门商品Top3数据可视化
5.1 创建实体类Top3Entity
为了便于各区域热门商品Top3分析结果数据的传递,在项目的entity包中创建实体类Top3Entity,存储Phoenix中表top3的数据。
public class Top3Entity {
private String product_id;
private String viewcount;
private String area;
//实现属性的getter和setter方法
...
}
5.2 创建数据库访问接口Top3Dao
在项目的dao包中创建一个数据库访问接口Top3Dao,读取Phoenix中表top3的数据。
import cn.itcast.sparkweb.entity.Top3Entity;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface Top3Dao {
@Select("select \"product_id\",\"viewcount\",\"area\" from \"top3\"")
List<Top3Entity> getTop3();
}
5.3 创建控制器类Top3Controller
在项目的controller包中创建控制器类Top3Controller,用于实现接口Top3Dao中的方法getTop3()读取表top3的数据,通过Model对象向HTML传递数据。
@Controller
public class Top3Controller {
@Autowired
private Top3Dao top3Dao;
@RequestMapping(value = "/top3",produces = "text/html;charset=utf-8")
public String top3(Model model) {
List<Top3Entity> top3 = top3Dao.getTop3();
model.addAttribute("top3",top3);
return "top3";
}
}
5.4 创建HTML文件top3.html
在项目中的templates目录下创建HTML文件top3.html,在该文件中通过jQuery获取Model对象传递到HTML的各区域热门商品Top3的数据,并将获取到的数据填充到ECharts柱状图模板中,实现各区域热门商品Top3数据的可视化展示。
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>top3</title>
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js"></script>
</head>
<body>
……
</body>
</html>
5.5 运行项目实现各区域热门商品Top3数据可视化
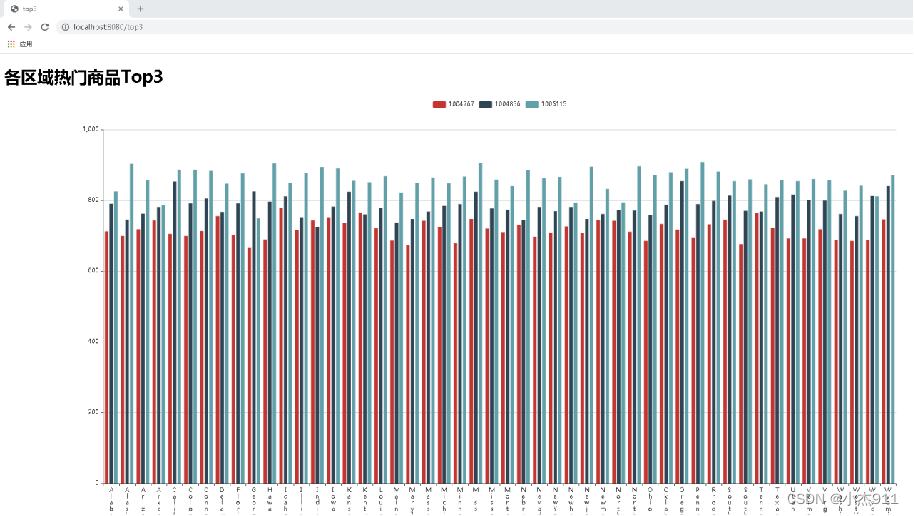
在IntelliJ IDEA中单击【启动】按钮运行项目,项目启动成功后,在浏览器中输入“http://localhost:8080/top3”查看各区域热门商品Top3数据可视化的展示效果。
6. 实现页面单跳转化率数据可视化
6.1 创建实体类ConversionEntity
为了便于页面单跳转化率数据的传递,在项目的entity包中创建实体类ConversionEntity,存储Phoenix中表conversion的数据。
public class ConversionEntity {
private String convert_page;
private String convert_rage;
//实现属性的getter和setter方法
...
}
6.2 创建数据库访问接口ConversionDao
在项目的dao包中创建一个数据库访问接口ConversionDao,读取Phoenix中表conversion的数据。
import cn.itcast.sparkweb.entity.ConversionEntity;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface ConversionDao {
@Select("select \"convert_page\",\"convert_rage\" from \"conversion\"") List<ConversionEntity> getConversion();
}
6.3 创建控制器类ConversionController
在项目的controller包中创建控制器类ConversionController,用于实现接口ConversionDao中的方法conversion()读取表conversion的数据,通过Model对象向HTML传递数据。
@Controller public class ConversionController {
@Autowired
private ConversionDao conversionDao;
@RequestMapping(value = "/conversion",produces = "text/html;charset=utf-8")
public String conversion(Model model){
List<ConversionEntity> conversion = conversionDao.getConversion();
model.addAttribute("conversion",conversion);
return "conversion";
}
}
6.4 创建HTML文件conversion.html
在项目中的templates目录下创建HTML文件conversion.html,在该文件中通过jQuery获取Model对象传递到HTML的页面单跳转化率数据,并将获取到的数据填充到ECharts柱状图模板中,实现页面单跳转化率数据的可视化展示。
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>conversion</title>
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js"></script>
</head>
<body>
……
</body>
</html>
6.5 运行项目实现页面单跳转化率数据可视化
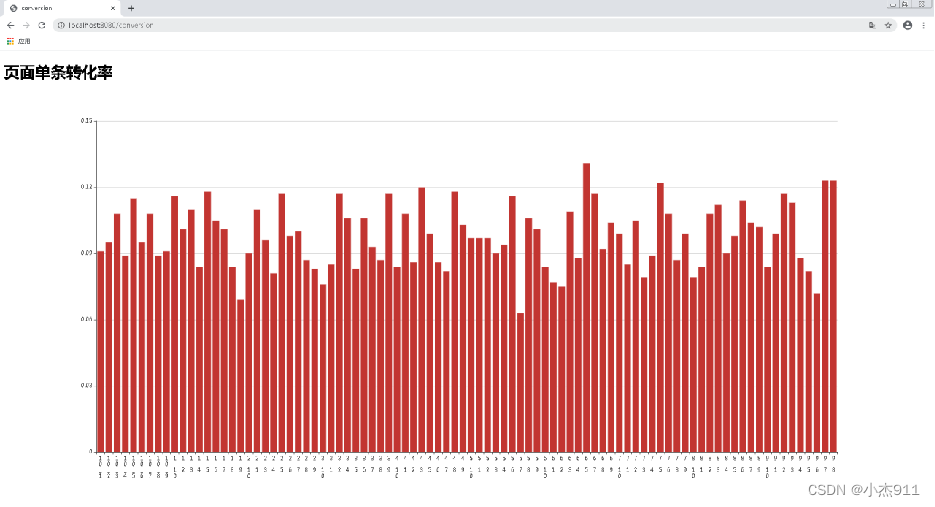
在IntelliJ IDEA中单击【启动】按钮运行项目,项目启动成功后,在浏览器中输入“http://localhost:8080/conversion”查看页面单跳转化率数据可视化的展示效果。
7. 实现广告点击流实时统计可视化
7.1 创建实体类AdsEntity
为了便于广告点击流实时统计结果数据的传递,在项目的entity包中创建实体类AdsEntity,存储Phoenix中表adstream的数据。
public class AdsEntity {
private String city;
private String ad_count;
private String ad_id;
//实现属性的getter和setter方法
...
}
7.2 创建数据库访问接口ConversionDao
在项目的dao包中创建一个数据库访问接口AdsDao,读取Phoenix中表adstream的数据。
import cn.itcast.sparkweb.entity.AdsEntity;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper public interface AdsDao {
@Select("select \"city\",\"ad_count\",\"ad_id\" from \"adstream\"")
List<AdsEntity>
ads();
}
7.3 创建控制器类AdsController
在项目的controller包中创建控制器类AdsController,用于实现接口AdsDao中的方法adsData ()读取表adstream的数据,将此数据作为方法的返回值传递到HTML。
@Controller public class AdsController {
@Autowired
private AdsDao adsDao;
@RequestMapping(value = "/adsdata",method = RequestMethod.POST) @ResponseBody
public List<AdsEntity> adsData(){
List<AdsEntity> ads = adsDao.ads();
return ads;
}
}
7.4 创建HTML文件ads.html
在项目中的templates目录下创建HTML文件ads.html,在该文件中通过jQuery的Ajax处理控制器类AdsController中adsData()方法返回的广告点击流实时统计数据,并将获取到的数据实时填充到ECharts柱状图模板中,实现广告点击流实时统计的可视化展示。
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>ads</title>
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js"></script>
</head>
<body>
……
</body>
</html>
7.5 运行项目实现广告点击流实时统计可视化

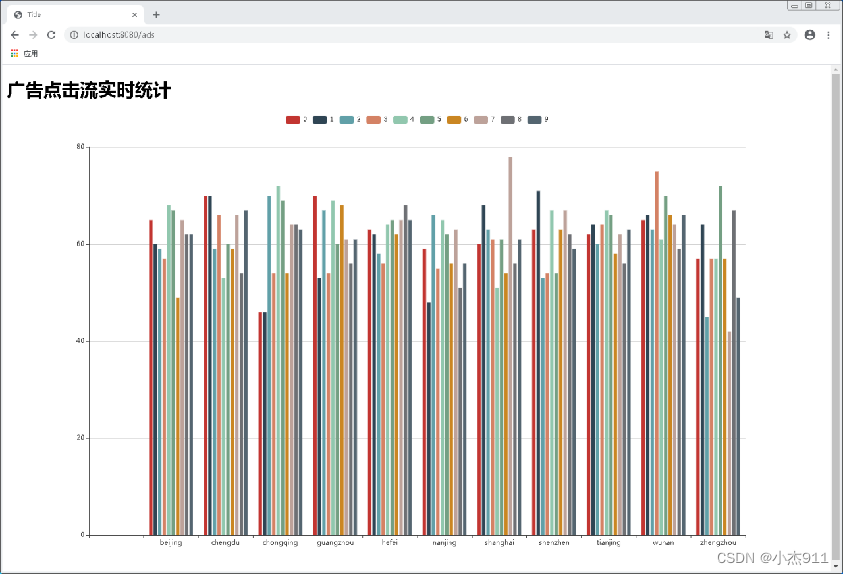
在项目sparkweb的主界面中单击【启动】按钮运行项目,项目启动成功后,在浏览器中输入“http://localhost:8080/ads”查看广告点击流实时统计可视化的展示效果。
小结
本文主要讲解了如何实现数据的可视化展示,首先,对实现可视化的技术以及系统架构进行详细讲解,使读者对实现数据可视化有了初步认知。接着,通过集成Phoenix与HBase实现将HBase中的数据映射到Phoenix,通过JDBC连接Phoenix获取分析结果。然后,讲解如何创建和配置Spring Boot项目。最后,在Spring Boot项目中编写相关类、接口以及HTML页面实现各区域热门商品Top3、热门品类Top10、页面单跳转化率以及广告点击流实时统计的可视化。通过本章的学习,读者应掌握Phoenix的使用,以及如何通过Spring Boot项目实现数据可视化展示。
求关注,点赞,一建三连!!!