分布式系统概念和设计
事务与并发控制
简介
- 事务的目标是在多个事务访问对象以及服务器面临崩溃的情况下,保证所有由服务器管理的对象始终维持在一个一致的状态上
事务是由客户定义的针对服务器对象的一组操作,组成为一个不可分割的单元,由服务器执行
服务器必须保证整个事务被执行,并将执行结果存储,或者出现故障时能够消除这些操作的影响
事务
- 客户端角度看待事务,是组成一个步骤的一组操作,将服务器数据从一个一致性状态转换为另一个一致性状态。
- 事务可以作为中间件的一部分提供。
- 事务总是应用到可恢复对象上并具有原子性,事务常常被作为原子事务。
- 故障原子性
- 服务器崩溃时事务的效果是原子的
- 持久性
- 一旦事务完成,所有的效果都会保存到持久存储中。
- 存储介质不受服务器崩溃影响。
- 隔离性
- 每个事务的执行不受其它事务的影响,事务执行过程中的中间效果对其他事务不可见

- 进程崩溃时的服务器动作
- 如果服务器意外进程崩溃,最终会被新的服务器进程替代。
- 新的服务器进程将放弃所有未提交的事务,并通过一个过程将对象的值恢复到最近提交的事务所产生的值
- 检查点的设计是为了处理崩溃后恢复到最近状态(CHECK POINT)
- 为了处理事务过程中客户进程崩溃,服务器给每个事务设定一个过期时间,服务器将放弃在过期时间还未完成提交的所有事务。
- 服务器进程崩溃时的客户动作
- 如果服务器在执行事务间崩溃,那么客户在超时后会接收到一个异常。
- 如果在执行事务期间,服务器崩溃了且被新服务器替代,那么未完成的事务将不在有效,当客户发起新操作时会接收到异常。
并发控制
更新丢失
事务U的更新被事务T覆盖,两个事务的更新前读出的数据都是旧的数据。
不一致检索
事务W汇总时其他事务已经完成了数据的更新。
串行等价性
每个事务知道它单独执行的正确效果,那么可以推断这些事务按照某种次序一次执行一个事务的组合也是正确的。串行等价衡量
事务放弃时的恢复
服务器必须记录所有已经提交事务的效果,而不保存被放弃事务的效果。
服务器必须保证事务被放弃后,它的更新作用完全取消,而不影响其它并发事务运行。
读取脏数据
事务的隔离性要求未提交的事务的状态对其它事务是不可见的状态。
如果某个事务读取了其他未提交事务写入的数据,这种交互会引起读取脏数据的问题。
事务可恢复性
如果一个事务访问了一个被放弃事务的更新结果,并且已经提交,那么这个事务的状态是不可恢复的。
解决不可恢复问题方法是:所有进行了脏数据读取的事务必须推迟提交。
可恢复的策略是推迟事务的提交,直到它读取更新结果的其它事务都已经提交。
连锁放弃
假设事务U一直推迟提交直到事务T放弃,那么此时事务U也要放弃,避免脏读。
同时,观察到U事务结果的其他事务也要放弃,这些事务的放弃可能导致观察这些事务结果的事务也要放弃,从而造成连锁放弃现象。
解决方法是:只允许事务读取已经提交写入的数据。
为了保证这一点:读取某对象的操作必须一直推迟到写该数据的事务提交或者放弃。
防止连锁反应是一个比保证事务可恢复性更强的条件。
过早写入
考虑事务放弃的另一种可能;
同时两个事务针对一个对象进行写操作的交互。
放弃事务时,将变量值恢复到该事务所有写操作的前映像。
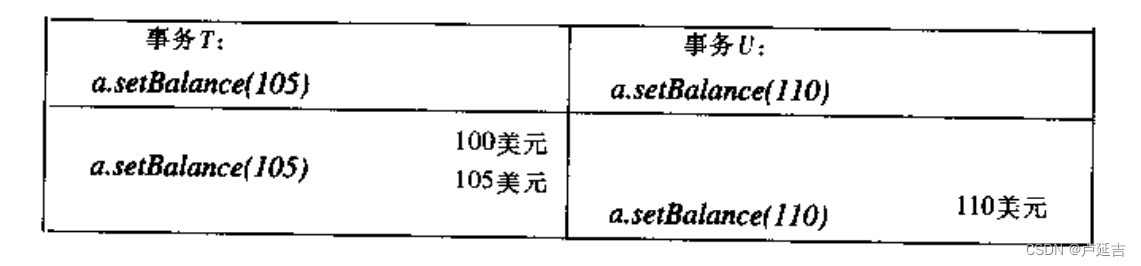
为了保证使用前映像进行事务恢复,获得正确的结果,写操作必须等到前面修改同一对象的其他事务提交或放弃后才能进行。
事务的严格执行
为了避免过早写入和脏读,通常要求事务推迟读写操作。
如果读操作和写操作都推迟到写同一对象的其它事务提交或放弃后才进行,这是严格执行条件。
事务的严格执行可以真正保证事务的隔离特性。
临时版本
对于参与事务可恢复对象服务器,必须保证事务放弃后,能够清楚所有对象的更新。
达到此目的,事务中的所有的更新操作都是针对对象在挥发存储中的临时版本。
每个事务都有本事务已更改的对象的临时版本集。
事务的所有更新操作将值存储在自己临时版本中。
如果可能,事务的访问操作会从临时版本中取值,如果失败,从对象取值。
只有更新提交事务,临时版本的数据才会应该真的更新对象数据,同时将数据持久化到存储。这个过程是一个原子步骤,保证更新成功或者失败。
期间将不允许其他事务访问对象,如果事务失败,则删除临时版本。
ACID
在事务中实现并发控制,通常需要考虑以下几种条件:
- 原子性(Atomicity):事务中的操作应该作为一个原子性单元来执行,即要么全部执行成功,要么全部回滚。如果事务中的某个操作失败,那么整个事务应该回滚到之前的状态,以确保数据的一致性。
- 一致性(Consistency):在事务执行过程中,如果数据被修改了,那么事务结束时,系统应该保持一致性。这意味着,在事务开始时和结束时,系统应该保持一致状态。
- 隔离性(Isolation):在并发情况下,多个事务可能同时访问数据库。为了确保事务之间不会相互干扰,系统应该实现隔离性,即每个事务应该感觉到自己是唯一的,并且能够独立地访问和修改数据。
- 持久性(Durability):在事务结束后,系统必须确保修改的数据被持久化到数据库中,即使系统中断或出现故障,数据也不应丢失。
这些条件通常被称为ACID特性,在事务性系统中是非常重要的,并且被广泛采用。
事务恢复
在事务放弃时恢复是非常重要的,因为这可以确保数据库的一致性和完整性。以下是一些关键的设计说明:
- 事务放弃时恢复应该是自动的,而不是手动的。这意味着,当出现故障时,系统应该能够自动检测到事务放弃,并进行恢复。
- 恢复操作应该能够检测到系统中断的位置,并将数据库恢复到中断前的状态。如果有多个事务同时进行,那么系统应该优先处理已经提交的事务,并且应该能够正确地协调所有事务的恢复。
- 在执行恢复操作时,应该谨慎考虑并发控制的条件。在恢复期间,数据库应该保持在“未提交”状态,以允许事务回滚和恢复。
- 在恢复期间,应该禁止所有事务的提交,以确保事务回滚和恢复顺利进行。在恢复结束后,系统应该允许新的事务提交。
- 恢复期间,系统应该将所有修改操作记录在日志文件中。这样一来,如果恢复操作失败,系统可以撤销所有的更改操作,以便恢复到中断前的状态。
这些是事务放弃时恢复的一些关键设计说明,可以帮助确保数据库的一致性和完整性。
嵌套事务

事务的并发访问和故障处理而言,子事务对于父事务是原子的。
在同一层次的子事务可以并发执行,但对公共对象的访问是串行化的。
每个子事务可以独立于其他事务而独立故障。
当某个子事务失败时,其父事务可能选择另一个子事务来完成工作
- 嵌套事务的主要优势:
- 在同一层次的子事务可以并发运行,提高事务内的并发度
- 子事务可以独立提交或者放弃,与单个事务相比,若干的子事务可能更健壮——减少当个事务的负载
- 嵌套事务的提交规则:
- 事务在其子事务完成以后才能提交或者放弃
- 当一个子事务执行完毕后,可以独立决定是暂时提交还是放弃。如果放弃,那么这个决定是最终。
- 父事务放弃时,所有子事务都放弃。即使子事务可能已经暂时提交了。
- 如果顶层事务提交了,那么所有暂时提交的子事务都被最终提交了。
- 只有当顶层事务提交后,子事务的作用才能够持久化。
锁
事务必须通过调度使得对共享数据的执行效果是串行等价的。
服务器可以通过串行化对象访问来达到事务的串行等价。
简单的串行化机制是使用互斥锁。服务器试图给客户端访问的对象加锁,如果一个客户访问对象发下已经上锁,那么访问对象将会被挂起,或者是获取锁失败,知道对象解锁后才可以获取。
- 串行等价性要求一个事务对一个对象的访问相对于其他事务进行访问是串行化的,两个事务的所有冲突操作都必须以相同的次序执行。
- 事务在释放任何一个锁之后都不允许再申请新的锁。保证串行等价。
- 每个事务的都一个阶段是不断的申请锁,增长阶段。
- 第二个阶段事务不断的释放锁,收缩阶段。
- 所有事务在执行的过程中获取的锁必须在事务提交或者放弃之后才能释放。被称为严格的二阶段加锁。
- 锁可以阻止其他事务读写对象。在事务提交时,为了保证恢复性,锁必须在所有被更新的对象写入持久存储后才能释放。
锁的实现
- 被锁住对象的标识
- 当前拥有该锁的事务的事务标识
- 锁的类型
- 锁方法都是同步方法
死锁
两个事务都在等待并且相互依赖对方,只有对方释放锁才能获取锁。
加锁在对象的子项上更容易避免死锁,缩小粒度。
所超时是解决死锁的有效方式。
在加锁的机制中增加并发度
加锁规则建立在读操作和写操作之间的冲突之上,并且锁应用的粒度也更小。
增加并发度的空间方法
- 双版本锁
- 互斥锁的设置推迟到事务提交时才进行
- 层次锁
- 使用混合粒度的锁
层次锁和双版本锁都是乐观锁的实现方式。
层次锁是一种基于时间戳的乐观锁实现方式。它为每个数据项维护一个版本号,每次读取数据时都会检查版本号是否发生变化,如果版本号发生变化,则表示数据已经被修改,需要重新读取数据。层次锁还可以为不同的数据项设置不同的版本号,从而实现更细粒度的锁控制。
双版本锁是一种基于CAS(Compare and Swap)操作的乐观锁实现方式。它为每个数据项维护两个版本号,一个版本号用于读操作,一个版本号用于写操作。读操作时使用读版本号,写操作时使用写版本号。每次更新数据时,会先检查读版本号是否发生变化,如果没有变化,则进行CAS操作,将写版本号加1,并更新数据。如果读版本号发生变化,则表示数据已经被修改,需要重新读取数据。
层次锁和双版本锁都是乐观锁的实现方式,相比悲观锁,它们的性能更高,但也存在一些缺点。层次锁需要维护版本号,增加了额外的开销;双版本锁需要进行CAS操作,如果并发冲突较多,会导致CAS操作失败率增加,从而影响性能。
乐观并发控制
加锁的缺点
- 锁维护带来的开销
- 引起死锁。
- 降低潜在的并发度,避免引起连锁放弃锁只能在事务结束才释放。
时间戳排序
基于时间戳的并发控制,事务的每一个操作执行之前都要进行验证。每个事务都有唯一的时间戳。
如果验证不通过,立即放弃改事务,然后客户端可能重新发起新的事务。
时间戳定义了该事务在事务顺序中的次序,不能解决分布式问题。