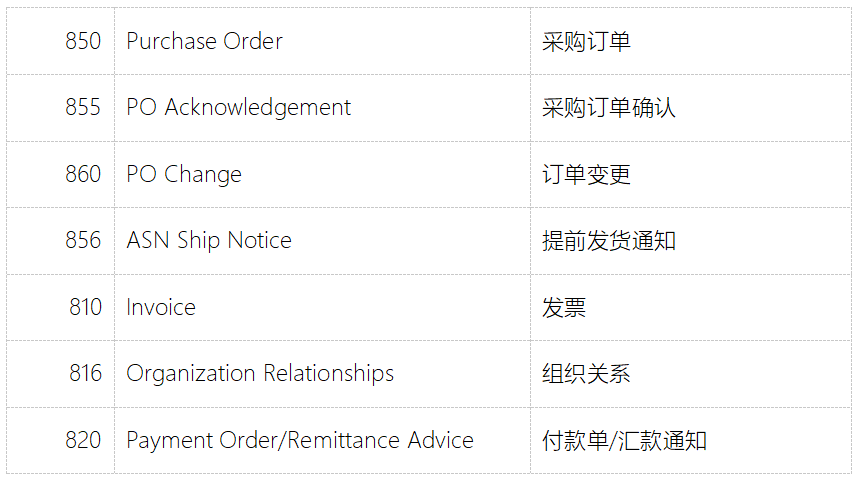
计算机硬件包括CPU,内存,网卡
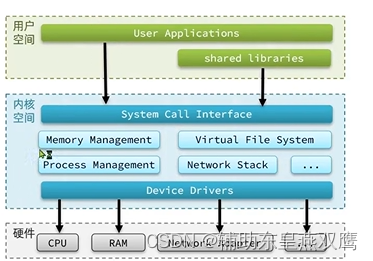
为了避免用户应用和操作系统内核产生冲突乃至内核崩溃,用户应用和内核是隔离开的
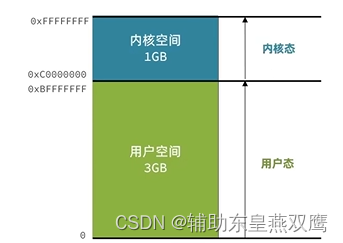
1)进程的寻址空间会被划分成两部分,内核空间和用户空间,内核和用户应用都无法直接访问物理内存,而是给他们分配不同的虚拟内存地址空间映射到不同的物理内存,应用或者内核在访问虚拟地址内存空间的时候,其实就需要一个虚拟的地址了,这个地址是一个无符号的整数,从0开始,最大值取决于CPU地址总线和寄存器的带宽;
2)假设一个32位的系统,他的地址的最大值就是2^32,寻址的范围就是从0-2^32,内存地址的每一个值代表的就是一个存储单元,也就是一个字节,所以2^32这么大的寻址空间
用户空间只能执行受限的命令,并且不能调用系统资源必须通过内核提供的接口来进行访问
内核空间可以执行特权命令,调用一切系统资源
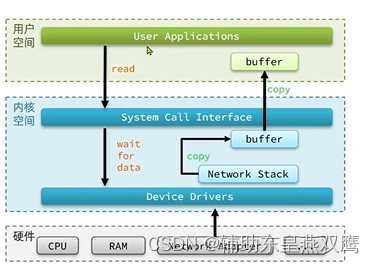
linux系统为了提升IO效率,会在用户空间和内核空间都加入一个缓冲区:
用户进程想要在写数据的时候,要把用户缓冲区数据拷贝到内核缓冲区里面然后再写入设备
读数据的时候,要从设备中读取数据到内核缓冲区,然后再将内核缓冲区数据拷贝到用户缓冲区
性能瓶颈:
1)等待内核寻址磁盘,如果要读取网卡,不光要寻址还需要等待别人发送数据过来,因为网卡本身就是别人通过网络发送过来的数据,最终也就是硬件将数据准备好放到内核缓冲区中
2)数据拷贝:内核缓冲区将内核缓冲区的数据拷贝到用户缓冲区里,或者是用户缓冲区的数据拷贝到用户缓冲区;
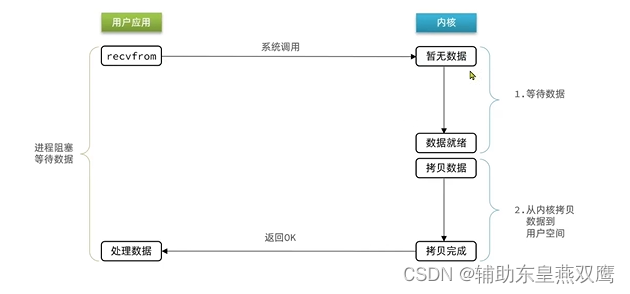
阻塞IO:就是两个阶段都需要阻塞等待
等待数据的结束条件:只要内核将磁盘数据或者其他硬件设备上的数据读取到内核缓冲区
最终可以看到,在阻塞IO模型中,用户进程在两个阶段都是阻塞状态
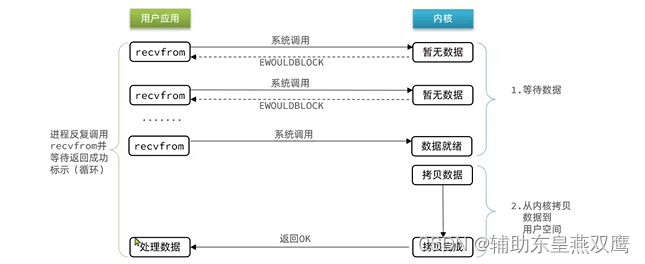
非阻塞IO:非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程
用户进程在第一阶段是频繁调用recvfrom操作的,直到操作系统内核将磁盘或者网卡的数据准备好,也就是写到内核缓冲区里面,这个过程用户进程是不会发生阻塞的,但是在第二个阶段,当操作系统内核将数据从内核缓冲区拷贝到用户空间,这个过程是阻塞的
但是可以看到,在非阻塞IO模型中,用户进程在第一个阶段是非阻塞,但是却是一个不断尝试的过程,和阻塞IO一样,这段期间用户进程并没有做什么有意义的事情,也是相当于忙等,况且因为非阻塞IO一直重试,就会导致频繁调用系统调用,会使CPU的使用率暴增
IO多路复用:
无论是阻塞IO还是非阻塞IO,用户应用在第一阶段都需要调用recvfrom(尝试读取数据)来进行获取数据,差别在于没有数据的时候的处理方案:
1)如果调用recvfrom,恰好没有数据,阻塞IO会使进程进入到阻塞状态,非阻塞IO会使CPU空转,一直尝试进行系统调用,所以他们都不能充分发挥CPU的作用
2)如果调用recvfrom,恰好有数据,那么用户进程会直接可以进入到第二阶段,读取并处理数据
比如说服务器端处理客户端的Socket请求的时候,在单线程情况下,只能依次处理一个Socket,如果说正在处理的socket没有就绪,数据不可读或者不可写,线程就会被阻塞,所有的其他Socket客户端都必须等待,性能自然非常差;
这个过程就类似于说服务员给顾客进行点餐,一共分成两步:
1)顾客要思考吃什么?也就是等待对应的数据就绪
2)顾客想好了,开始进行点餐,读取数据
想要进行提升效率,一共有两种方法:
1)增加更多的服务员,多线程进行执行
2)不进行排队,谁想好了吃什么(数据就绪了),服务员就给谁点餐(用户应用就去读取数据)
那么用户进程该如何知道内核中的数据是否就绪呢?
每一个客户端和服务器建立连接的时候,都会有一个网络套接字Socket,都有一个对应的文件描述符

文件描述符:简称为FD,是一个从0开始递增的无符号整数,用来关联linux系统中的一个文件,在linux系统中一切都是文件,例如常规文件,视频,硬件设备,还包括网络连接套接字
IO多路复用:是利用单个线程去监听多个FD,并在某一个FD可读,可写的时候得到通知,从而避免进行无效的等待,充分利用CPU资源
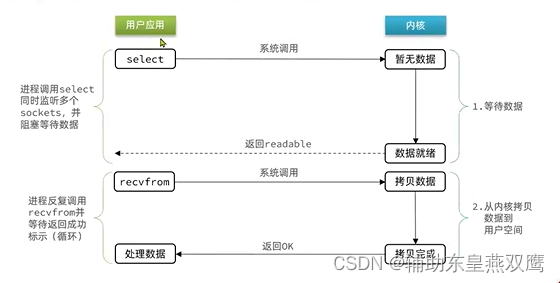
1)首先用户应用想要读取数据的时候首先调用的是select函数,不再是recvfrom函数了,recvfrom是直接尝试读取FD的数据,但是我们不知道当调用FD的时候数据是否就绪,如果你调用recvfrom的时候,FD中的数据没有等待就绪,这个用户进程就不得不阻塞等待;
2)每一个用户客户端Socket将对应的FD传递给Select函数,Select函数将FD传递到操作系统内核,然后操作系统内核就会监听多个FD,只要有任意一个FD就绪,直接就会通知对应的Socket客户端,这个操作系统内核监听FD的过程中如果没有FD准备就绪,那么所有的用户进程都会阻塞等待,如果有多个FD就绪,就会直接通知;
3)此时对应的Socket客户端就去调用recvfrom读取数据,况且一定是不会读取数据阻塞的(多个Socket如果被同时通知,同时也会排队去执行recvfrom系统调用)
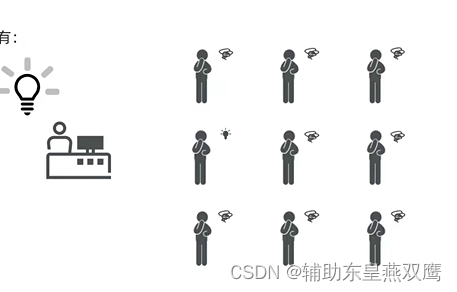
1)每一个人都在一个桌子上,服务员上面有一盏大灯,只要有顾客准备好点餐了,每一个顾客的桌子上都有一个开关,顾客准备好只需要按下开关就可以了,但是如果有任意一个顾客按下开关了,那么灯泡是一定会亮的
但是如果灯泡亮了,服务员就会寻找每一位按下按钮的顾客,需要进行遍历
2)现在不采用灯泡的模式了,而是直接在电脑上显示,如果又用户按下开关了,那么电脑上就直接显示出对应的用户记录,就不需要一个一个的进行遍历了;
select和poll只会通知用户进程有FD就绪了,但是不确定到底是哪一个FD,需要用户进程进行逐个遍历FD来进行确认,epoll则会在用户ID就绪的同时,就直接把已经就绪的FD写入到用户空间;
IO多路复用select:监听多个FD的集合
1)select函数中nfds,传递的最大的FD的值,等于是进行遍历的时候,FD的一个最大上限,FD的只是一个无符号整数,从0开始向上递增,指定这个值就是告诉内核,你进行遍历的FD就是最后一个FD;
2)select函数的监听集合*readfds,linux系统把可能发生的IO事件分为了三类
3)timeout代表操作系统FD要等待多久,超过等待事件之后返回,然后继续调用下一次Select继续检测FD;
1)用户态会首先进行创建fdset的集合,fdset结构非常特殊,里面有一个fdsbits属性,类型就是一个fdmask*数组,数组大小是有两个常量进行计算,最终是1024个比特位
2)reds表示要进行读取的内核数据的数组,会使用1024个比特位,可以监听1024个FD,0表示未监听,1表示监听,在刚进行创建的时候,每一个fds比特位都会被初始化成0;
3)假设此时要监听1 2 5,那么fds_bit的结构就类似于是:
4)用户进程开始调用系统调用select函数(5+1,rfds,null,null,3),第二个参数是要监听的读事件的fd集合;
5)当用户进程执行select函数的那一刻,用户进程就把对应的rfdbits传递到内核空间,这就涉及到了用户态和内核态的切换,涉及到数据的拷贝
6)操作系统内核就会遍历这个fds集合,来监听对应的fd是否就绪
7)如果没有就绪,直接进行休眠,如果就绪了,内核就会将结果写到fd集合里面去了,内核就去再次进行遍历fd,就绪的直接保留,未就绪的直接清0,此时fd集合中保存的就是就序的fd,然后selcet的返回值就直接返回一个数字,代表有几个fd就绪了,此时select函数只是返回给用户进程有几个fd就绪了,但是并没有返回哪一个FD就绪了;
8)操作系统内核再将这个fds_bits集合重新拷贝返回给用户进程覆盖用户空间里面的fds集合
9)用户进程再次遍历fds中的比特位,然后对应的socket就去开始读取对应的数据,如此循环再次执行步骤2,反复执行,处理各种而样的读取数据
SelcetIO多路复用的缺点:
1)需要将整个fd_set从用户空间拷贝到内核空间,select结束之后还要将fd_set再次拷贝会用户空间,每执行一次select,就会涉及到两次用户态到内核态的切换,两次内存的拷贝,select函数在循环往复地执行,就回来会的拷贝;
2)select无法得知具体是哪一个fd就绪,需要遍历整个fdset
3)fd_set监听的fd数量不能超过1024个



IO多路复用poll:
poll模式针对于select模式做了一些简单改进,但是性能提升不明显,关键代码如下
1)poll函数里面,第一个参数fds表示操作系统内核监听的fd的集合,可以进行自定义大小
2)poll函数的第二个参数nfds代表数组中元素的个数,第三个参数是超时时间
pollfd又是一个结构体,这里没有使用二进制位来直接标注fd
第一个参数是要监听的fd,第二个参数是要监听的事件类型,第三个参数是真正发生的事件类型,在进行调用poll函数的时候,只需要传递前两个参数即可,第三个参数是由操作系统内核来进行设置的,如果内核发现数据有就绪的情况就将revents设置成1,否则设置成0;
IO流程:
1)创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
2)调用poll函数,将pollfd数组拷贝到内核空间,转成链表存储,是没有上限的
3)内核进行遍历fd,查看是否就绪
4)数据就绪或者超市以后,会拷贝pollfd数组到用户空间,返回就绪的fd数量是n
5)用户进程会进行判断N是否大于0,如果大于0就直接遍历pollfd数组,找到就绪的fd
poll相比于select来说,select中的fd_set大小上限是1024个,但是pollfd在内核中采用的是链表,是没有上限的,但是这并没有带来性能上的提升,监听的FD越多,每一次进行遍历消耗的时间也就越多,性能反而会下降

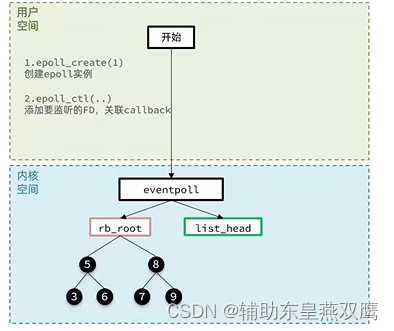
IO多路复用:epoll
1)首先会在用户空间调用epoll_create函数然后操作系统内核里面创建eventpoll结构体,在这个结构体里面包含了一棵红黑树,在这里面记录了要监听的FD,还有一个字段rdlist链表表示就绪的FD;
2)此时rb_root和list_head都是null,向用户空间返回的句柄就是eventpoll的唯一身份标识
3)然后用户空间会调用一个函数epoll_ctrl()函数,添加要监听的FD,关联epoll_create()函数返回的句柄,第一个参数是epoll实例的句柄,表明要将fd要添加到哪一个eventpoll里面,第二参数op表示要执行的操作,可以是新增操作,就是将当前指定的fd添加到eventpoll里面,也就是对应的红黑树上面(红黑树上面是记录着所有要进行监听的FD的),也可以进行删除,这个fd不想进行监听了,就从红黑树上移除,还可以进行修改fd的类型,但是在做初始化的时候一定是进行新增操作,将需要监听的fd给加入到红黑树里面
4)我们不仅要把多个fd添加到红黑树上面,而且要给每一个要进行监听的fd以及要监听的事件类型添加上一个回调函数,这个回调函数会在对应的fd事件就绪的时候