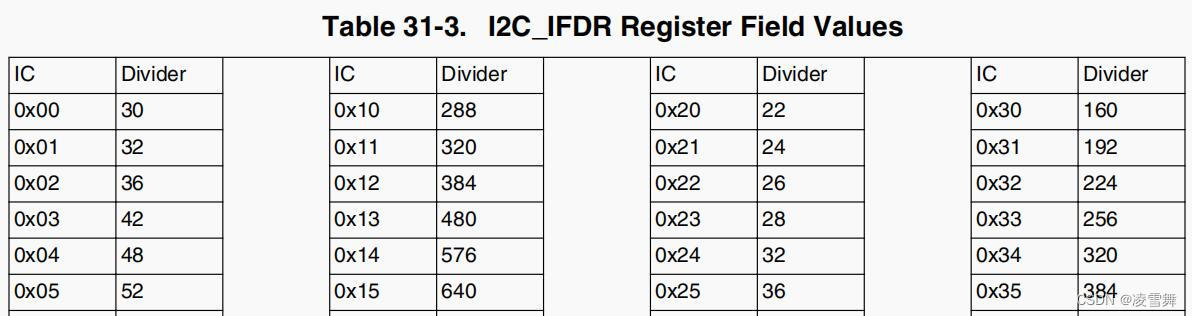
本文已参与「新人创作礼」活动,一起开启掘金创作之路。
1. 简 介
Apache DolphinScheduler(海豚调度),国人之光,是许多国人雷锋开源在Apache的顶级项目,主要功能就是负责任务的调度处理。
1.1 概 念
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用,架构如图1.1,大概看一下,看不懂没关系,后续细讲;

图1.1 架构分布图
分布式:就是可以这个组件不同的部分可以分布在不同的机器上,整体的协调工作完成任务调度;(为啥要分布式而不装在一台,因为一头牛拉一大堆物资可能会累死,除了培养更加强壮的牛以外,还可以让多头牛去拉);去中心化:DolphinScheduler有多台master(负责发号施令,布置任务,接受成果),假设有m1,m2,m3……,也有多台worker(负责真正干活的小弟),假设有w1,w2,w3……,而这些机器都注册在zookeeper,每次任务A来的时候,都同时需要m和w,但是根据你配置的不同任务A将分到不同的m和w上,而不是单纯在一个单点上运行,提高容错性,当然如果你玩单机模式,则不存在这个概念;易扩展:既然master,worker可以有多个,那可不可有更多,所以DolphinScheduler是支持扩容的,反之,实践中发现太败家了,需要回收一些机器,也是可以支持缩容的;可视化DAG工作流任务调度:就是除了提供查看日志来查看任务和工作流的运行情况,还有个有序无环图可查看任务和工作流的运行情况;处理流程中错综复杂的依赖关系:现在有要跑的项目A,B;项目A有工作流a1(内有任务一s1,任务二s2),a2(内有任务一s3,任务二s4),a3(内有任务一s5,任务二s6);项目B里面有工作流b1(内有任务一s7,任务二s8),b2(内有任务一s9,任务二s10);一般的任务调度器,都能保证一个工作流内的任务如s1,s2是有序往下运行的,当然也可并行;但是有些调度器就实现不了工作流a1和a2以及a3之间有依赖关系了,比如某些场景下必须工作流b1先跑完,才可以跑a1,a2;那更甚至的必须先跑完整个项目B才能跑 项目A就更不支持了,即项目之间有壁垒,这些都是比价差劲的,需要用户自己想办法去实现,但是DolphinScheduler这些缺陷都填了,即以上的这些复杂依赖关系,不论是工作流之间,项目之间都支持;
1.2 优缺点
官网提出她有四大优点,如图1.2,个人觉得高可用和DAG监控界面算是比较优秀的,其他的是一个调度器必备的,不能作为特色吧,另外赞扬一句,DolphinScheduler的WebUI做的是真的绚丽,令人看了很舒服;

图1.2 DolphinSheduler的优点
缺点:相对而言目前(20210605)比较年轻,还在持续更新中,还需要与大家共同成长,个别功能不完善,如虽然支持多个Master节点,但是不自带Master之间的自动故障转移,即你在用API访问时,需要自己配置反向代理;支持的数据源比较单一,如Presto,ElasticSearch等暂不支持;任务类型的控件还较少,邮件、中止等控件还没有。
1.3 哪些人适合DolphinScheduler(纯属个人观点)
如果第一公司不想花大价钱购买商业ETL工具及调度器,第二公司也没规划人力自研调度器,那么DolphinScheduler将是不错的选择; 因为确实也存在很优秀的商业调度器,唯一的缺点就是贵嘛;而DolphinScheduler在目前的开源调度器中,如Azkaban,XXL-Job,Ozzie,AirFlow等对比,确实略胜一筹,如果自研开源调度器,人力成本也是需要估量的,因为DolphinScheduler完全开源,也可以借鉴DolphinScheduler。
1.4 社区
-
官网:dolphinscheduler.apache.org/ -
GitHub:github.com/apache/dolp… -
微信公众号:海豚调度 -
微信号:easyworkflow,让她拉你进群,共同探讨dolphinscheduler; -
其 他:……
欢迎大家加入社区工程促进Apache DolphinScheduler越来越好。
2. 集群模式安装详解(比官网还细,个人手把手实践避坑)
目前(20210606)支持的部署模式如下;
- 单机部署
集群部署- Docker部署
- Kubernetes部署
- SkyWalking-Agent部署
Why集群模式?现在DolphinScheduler支持的部署模式越来越丰富了 ,博主翻了下日志,新的版本对后续的部署模式Docker,Kubernetes,SkyWalking-Agent做了很大的优化和调整,这些模式如果有兴趣,建议用最新的版本,但是生产环境本着最新版本倒退2个版本的原则,博主还是选用了较为稳定的1.3.5版本,而且博主的大数据集群都是集群部署模式,多少有点个人爱好因素,就选择了集群部署模式,因为博主喜欢这种任何配置都安排在清清楚楚的文件夹的感觉;
2.1 架构图详解

图2.1 DolphinScheduler架构图
-
MasterServer:MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务,该服务内主要包含:- Distributed Quartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
- MasterSchedulerThread是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作;
- MasterExecThread主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理;
- MasterTaskExecThread主要负责任务的持久化。
-
WorkerServer:WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 Server基于netty提供监听服务,该服务包含:FetchTaskThread主要负责不断从Task Queue中领取任务,并根据不同任务类型调用TaskScheduleThread对应执行器。 -
LoggerServer:是一个RPC服务,提供日志分片查看、刷新和下载等功能; -
ZooKeeper:ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。 -
Task Queue: 提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,实际上我们压测过百万级数据存队列,对系统稳定性和性能没影响。 -
Alert:提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能又有邮件通知和**SNMP(暂未实现)**两种。 -
API:API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。 -
UI:系统的前端页面,提供系统的各种可视化操作界面,详见实战教学。
2.2 机器安排
根据上面的架构,可以集群模式机器分配可以如下;
MasterServer:最好能有2+台MasterServer,可以实现高可用; 2.WorkerServer:最好能有3+台WorkerServer分别接收任务调度运行;如果条件允许,最好能MasterServer、WorkerServer分布在不同的机器上,避免WorkerServer导致机器性能瓶颈影响到MasterServer,实在条件不允许,就搞两台和MasterServer共用也行,这样你只要3台机器即可;否则是5台;LoggerServer:是跟着WorkerServer的,不用特别准备机器;ZooKeeper:如果你有ZooKeeper集群,用已有的就行,如果没有就用这5台安装一个ZooKeeper集群;Task Queue:不用刻意准备机器;Alert:5台机器任选一台;API:可以多台,也不建议刻意准备,博主是跟着MasterServer的两台;UI:可以多台,也不建议刻意准备,博主是跟着MasterServer的两台;
因此整个机器安排如表2.2;
表2.2 集群模式机器部署安排
| 机器\服务 | MasterServer | WorkerServer | LoggerServer | Alert | API&UI | ZooKeeper(已有可忽略) |
|---|---|---|---|---|---|---|
| node1(10.192.168.20) | 1 | 1 | 1 | |||
| node2(10.192.168.21) | 1 | 1 | 1 | |||
| node3(10.192.168.22) | 1 | 1 | 1 | 1 | ||
| node4(10.192.168.23) | 1 | 1 | 1 | |||
| node5(10.192.168.24) | 1 | 1 | 1 |
2.3 安装前准备
博主选择安装的是Apache DolphinScheduler 1.3.5版本,接下来做一些安装前的准备;
2.3.1 安装要求
以下基础配置是需要每台机器都有的,选装的看你自己安排;
操作系统:那就开源到底,建议选用CentOS7,配置建议为CPU 4核+、内存8 GB+、SAS磁盘、千兆网卡……,总之只要不是太low的配置就行,如果实在不会操作Linux,可以关注下博主的Linux栏,有手把手教程安装Linux操作系统,配置网络,用户管理等;jdk:JDK (1.8+),必须装;python:最好能装,因为后续调度Python脚本也是很常见的,可以参考博客Linux通过anaconda来安装python;ZooKeeper:ZooKeeper (3.4.6+) ,必须要装;Hadoop集群:Hadoop (2.6+) or MinIO :选装,如果需要用到资源上传功能,可以选择上传到Hadoop or MinIO上;
注意:jdk、ZooKeeper、Hadoop 、免密登录的安装,可以参考博客:Hadoop集群大数据解决方案之搭建Hadoop3.X+HA模式(二);
元数据库:PostgreSQL (8.2.15+) or MySQL (5.7系列) : 两者任选其一即可, 如MySQL则需要JDBC Driver 5.1.47+,建议选用MySQL,如果不会安装,可以参考博客:Linux(CentOS-7)下安装MySQL-5.7.30,在其中一台安装好MySQL并开启服务,其他的WorkerServer最好能安装好MySQL客户端,因为后续的调度及其可用在Shell脚本上用到MySQL脚本,注意如果你有Hive元数据库,可以存在Hive元数据库同一实例下,不用再可以准备MySQL了;Spark:选装,如果有调度spark的任务,也是需要在WorkerServer安装Spark客户端;Hive:选装,如果有调度hive的任务,也是需要在WorkerServer安装hive客户端;其他:只要运行在linux的任务,都需要支持有客户端,否则,会出现xxx command not found;
注意:DolphinScheduler本身不依赖Hadoop、Hive、Spark,仅是会调用他们的Client,用于对应任务的提交,安装客户端博主一般的做法就是去相应的官网,找到该软件的tar包,然后上传到你的Linux机器的某个位置,以MySQL为例子,如/data/tools/mysql/目录下,然后解压,假设得到/data/tools/mysql/mysql-5.7,然后把mysql下的/data/tools/mysql/mysql-5.7/bin目录写入环境变量,另外记得在/usr/bin目录下也设置下软链接,指令
ln -sf /data/tools/mysql/mysql-5.7 /usr/bin/mysql,保证shell脚本/usr/bin/sh 能引用到,其他客户端的安装基本也是这样;
如果以上工具都已经ready的,恭喜你,你对大数据领域已经有很深的认识了;
2.3.2 选择/创建安装维护账号
如果你已经玩转大数据集群,那么必然是有一个账号在启动者集群的各项任务,如hadoop,hdfs,hive等等,博主的集群有个这样的账号,名字就叫hadoop,那么就继续用hadoop账号去做免密登录,下载安装DolphinScheduler,如果你没有这种账号,那么随意,官网是说建一个dolphinScheduler账号,这个看你,账号叫啥都行;
2.3.3 集群之间免密登录
集群之间免密登录虽然上面博客也又说到,这里再啰嗦几句,博主有一篇花式玩转Linux集群免密登录一文教你把免密登录整的明明白白,有兴趣的可以看看,切记免密登录是绑定账号的,这里的免密登录一般用到上面2.3.2选择/创建安装维护的账号,假设你用的hadoop创建了集群的免密登录,那么当你切换root账号时,root账号并没有免密登录的权限,需要重新配置。
2.3.4 下载
博主在集群安装的软件一般是/data/tools下,注意,Dolphinscheduler不比hadoop,spark,hive等软件,这些软件的tar包安装都是解压,然后配置,然后启动就能用,Dolphinscheduler下载的tar包apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz,解压后的文件重命名apache-dolphinschedule-1.3.5是一个类似于windows的exe文件,是需要在conf/config/install_config.conf 下指定真实的installPath(一定要安装的用户有可读可写的权限),一切配置好以后,运行install.sh就能把DS装到你选定的目录,后续的启动、关闭都是在installPath上进行的,以下操作需要在每一台机器上都进行; 我们就先在20上配置好;
shell
复制代码
# 进入/data/tools cd /data/tools # 创建总文件夹dolphinscheduler mkdir dolphinscheduler # 进入dolphinscheduler cd dolphinscheduler # 下载,如果网速不好,就去dolphinscheduler官网或者git下载这个tar包,然后上传到集群的这个目录 wget https://downloads.apache.org/dolphinscheduler/1.3.5/apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz # 解压 tar -zxvf apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz # 因为名字老长了,做一下重命名 mv apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin apache-dolphinscheduler-1.3.5 # 创建installPath,一定要安装的用户有可读可写的权限 mkdir install-ds-1.3.5 # 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可 # 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可 # 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可 ln -sf /data/tools/dolphinscheduler/install-ds-1.3.5 current # 进入解压的apache-dolphinscheduler-1.3.5 cd apache-dolphinscheduler-1.3.5 # 查看下当前目录 ls -al # 结果如下 drwxr-xr-x 9 hadoop supergroup 204 Jun 1 20:23 . drwxr-xr-x 4 hadoop supergroup 178 Jun 2 00:15 .. drwxr-xr-x 2 hadoop supergroup 95 Jun 1 20:23 bin drwxr-xr-x 6 hadoop supergroup 4096 Jun 2 10:02 conf -rw-r--r-- 1 hadoop supergroup 563 Feb 7 17:46 DISCLAIMER -rwxr-xr-x 1 hadoop supergroup 4663 Feb 7 17:46 install.sh drwxr-xr-x 2 hadoop supergroup 12288 Jun 1 20:26 lib -rw-r--r-- 1 hadoop supergroup 38540 Feb 7 17:46 LICENSE drwxr-xr-x 3 hadoop supergroup 12288 Feb 7 17:46 licenses -rw-r--r-- 1 hadoop supergroup 70942 Feb 7 17:46 NOTICE drwxr-xr-x 2 hadoop supergroup 254 Jun 1 20:23 script drwxr-xr-x 4 hadoop supergroup 149 Jun 1 20:23 sql drwxr-xr-x 8 hadoop supergroup 149 Jun 1 20:23 ui
以上文件做一个简单的介绍,具体如下;
shell
复制代码
├─bin DS命令存放目录 │ ├─dolphinscheduler-daemon.sh 启动/关闭DS服务脚本 │ ├─start-all.sh 根据配置文件启动所有DS服务 │ ├─stop-all.sh 根据配置文件关闭所有DS服务 ├─conf 配置文件目录 │ ├─application-api.properties api服务配置文件 │ ├─datasource.properties 数据库配置文件 │ ├─zookeeper.properties zookeeper配置文件 │ ├─master.properties master服务配置文件 │ ├─worker.properties worker服务配置文件 │ ├─quartz.properties quartz服务配置文件 │ ├─common.properties 公共服务[存储]配置文件 │ ├─alert.properties alert服务配置文件 │ ├─config 环境变量配置文件夹 │ ├─install_config.conf DS环境变量配置脚本[用于DS安装/启动] │ ├─env 运行脚本环境变量配置目录 │ ├─dolphinscheduler_env.sh 运行脚本加载环境变量配置文件[如: JAVA_HOME,HADOOP_HOME, HIVE_HOME ...] │ ├─org mybatis mapper文件目录 │ ├─i18n i18n配置文件目录 │ ├─logback-api.xml api服务日志配置文件 │ ├─logback-master.xml master服务日志配置文件 │ ├─logback-worker.xml worker服务日志配置文件 │ ├─logback-alert.xml alert服务日志配置文件 ├─sql DS的元数据创建升级sql文件 │ ├─create 创建SQL脚本目录 │ ├─upgrade 升级SQL脚本目录 │ ├─dolphinscheduler-postgre.sql postgre数据库初始化脚本 │ ├─dolphinscheduler_mysql.sql mysql数据库初始化脚本 │ ├─soft_version 当前DS版本标识文件 ├─script DS服务部署,数据库创建/升级脚本目录 │ ├─create-dolphinscheduler.sh DS数据库初始化脚本 │ ├─upgrade-dolphinscheduler.sh DS数据库升级脚本 │ ├─monitor-server.sh DS服务监控启动脚本 │ ├─scp-hosts.sh 安装文件传输脚本 │ ├─remove-zk-node.sh 清理zookeeper缓存文件脚本 ├─ui 前端WEB资源目录 ├─lib DS依赖的jar存放目录 ├─install.sh 自动安装DS服务脚本
在安装配置中用到的关键性文件为conf/datasource.properties、conf/config/install_config.conf、conf/env/dolphinscheduler_env.sh,简单吧,其他的文件,需要了解其功能即可,一般不用特意修改,除非你要个性化设置,下面进入安装配置;
2.4 安装步骤
2.4.1 创建元数据库
如果你装过Hive,这一步骤就不陌生了,没有也没关系,其实就是找一个数据库存放Dolphinscheduler的元数据(metadata,解释数据的数据,比如你有多少项目,多少工作流,MatserServer、WorkServer是哪些等等),这里一般选用MySQL,如果你有Hive,也可以放在Hive元数据库的那个实例下,新建一个dolphinscheduler库即可,如果没有,就在刚刚准备的MySQL实例内新建dolphinscheduler库;这种库一般都比较重要,强烈要求DBA进行备份和监控,以防不测;
在你的MySQL客户端,跑以下语句完成元数据库的创建,如果有DBA,恭喜你,可以交给DBA做,告诉他建一个dolphinscheduler ,需要某账号(没有则新建,博主选的是dw_user账号)该库的所有权限;
sql
复制代码
-- 创建数据库dolphinscheduler CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- 给你的一个数据库账号赋权,一定要可读可写,最好是dolphinscheduler库权限全给账号dw_user且能远程连接 GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dw_user'@'%' IDENTIFIED BY '123456qwer'; # 设置账号能连接权限全给账号dw_user且能本地连接 GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dw_user'@'localhost' IDENTIFIED BY '123456qwer'; # 刷新权限 flush privileges;
特别提醒:既然用了MySQL,自然连接MySQL的jar包不能少,一样的,如果你安装了Hive,直接把Hive的lib下的mysql-connector-java-x.x.xx.jar复制到你解压的apache-dolphinscheduler-1.3.5/lib/下即可,如果没有,就去官网下载;
shell
复制代码
# 如果装过hive则copy copy /data/tools/hive/current/lib/mysql-connector-java-8.0.13.jar /data/tools/dolphinscheduler/dolphinscheduler-1.3.5/lib # 没有的话直接下载 # 下载到/data/source文件夹 # 进入 cd /data/source # 下载 wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.25.tar.gz # copy到lib下,没网的话就在有网的机器下好再上传到这里 cp /data/source/mysql-connector-java-8.0.25/mysql-connector-java-8.0.25.jar /data/tools/dolphinscheduler/dolphinscheduler-1.3.5/lib
2.4.2 初始化元数据库表
这里假设元数据库就安装在10.192.168.20上(自己根据自己的机器来),初始化之前,先要修改下conf 目录下 datasource.properties 中的下列配置;
shell
复制代码
# 进入dolphinscheduler-1.3.5 cd /data/tools/dolphinscheduler/dolphinscheduler-1.3.5 # 编辑conf/datasource.properties vim conf/datasource.properties #具体改动如下,注释调postgre配置,新增mysql的 #postgre #spring.datasource.driver-class-name=org.postgresql.Driver #spring.datasource.url=jdbc:postgresql://localhost:5432/dolphinscheduler # mysql spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://10.192.168.20:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true spring.datasource.username=dw_user spring.datasource.password=123456qwer # 修改完记得保存退出 :wq! # 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接 # 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接 # 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接 # 博主的jdk安装在/data/tools/java/current下,设置/usr/bin/java软链接 ln -sf /data/tools/java/current/bin/java /usr/bin/java # 运行元数据库初始化脚本,如果没java或者没配置环境变量,会报错`/bin/java: No such file or directory` sh script/create-dolphinscheduler.sh
这是你在MySQL客户端刷线下数据库dolphinscheduler,你会发现新建了38张表(版本1.3.5其他版本可能有差距,总之没报错即可),局部表预览和E-R图如图2.4.1,2.4.2;

图2.4.1 局部元数据表

图2.4.2 局部元数据表E-R图
2.4.3 修改dolphinscheduler的环境变量conf/env/dolphinscheduler_env.sh
修改 conf/env 目录的dolphinscheduler_env.sh环境变量,博主的配置如下,你们可以按照自己的来;
shell
复制代码
# 进入 /data/tools/dolphinscheduler/dolphinscheduler-1.3.5 cd /data/tools/dolphinscheduler/dolphinscheduler-1.3.5 # 编辑conf/env/dolphinscheduler_env.sh vim conf/env/dolphinscheduler_env.sh # 具体操作如下 # 这一步非常重要,例如 JAVA_HOME 和 PATH 是必须要配置的,没有用到的可以忽略或者注释掉 export HADOOP_HOME=/data/tools/hadoop/current export HADOOP_CONF_DIR=/data/tools/hadoop/current/etc/hadoop export SPARK_HOME1=/data/tools/spark/current # export SPARK_HOME2=/opt/soft/spark2 export PYTHON_HOME=/data/tools/anaconda/anaconda3/bin/python # 注意python需要把整个路径写全,最后的python是执行文件,其他的都是到文件夹的 export JAVA_HOME=/data/tools/java/current export HIVE_HOME=/data/tools/hive/current export FLINK_HOME=/data/tools/flink/current # export DATAX_HOME=/opt/soft/datax/bin/datax.py export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$PATH # 千万记得保存退出 :wq!
2.4.4 修改部署配置文件 conf/config/install_config.conf
shell
复制代码
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # NOTICE : If the following config has special characters in the variable `.*[]^${}\+?|()@#&`, Please escape, for example, `[` escape to `\[` # postgresql or mysql 这里选择mysql为元数据库 dbtype="mysql" # db config # db address and port mysql数据库的实例 dbhost="10.192.168.20:3306" # db username 用户名 username="dw_user" # database name 数据库名 dbname="dolphinscheduler" # db passwprd 登录密码 # NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[` password="123456qwer!" # zk cluster ZooKeeper集群,配置你自己有ZooKeeper集群 zkQuorum="10.192.168.20:2181,10.192.168.21:2181,10.192.168.22:2181,10.192.168.23:2181,10.192.168.24:2181" # Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd) # 安装目录,这个很重要,就是一键部署后的目录,这里选择之前早已准备好的安装目录,切记一定要安装账号对该目录有可读,可写,可执行权限 installPath="/data/tools/dolphinscheduler/install-ds-1.3.5" # deployment user # Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself # 操作系统的账号,这里选择你平时使用的大数据账号即可 deployUser="hadoop" # alert config # mail server host # 这里是你公司的邮箱服务器,一般公司都有自己的邮箱服务器,可以找基础设施部邮件组询问下 mailServerHost="appmail.rowyet.cn" # mail server port # note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct. # 邮箱服务器端口 mailServerPort="25" # sender # 后续的邮件如数据发送,告警发送使用的账户,可以让基础设施部创建个你们自己的邮箱 mailSender="dw_bi@rowyet.cn" # user # 同mailSender即可 mailUser="dw_bi@rowyet.cn" # sender password # note: The mail.passwd is email service authorization code, not the email login password. # mailSender、mailUser邮箱的密码,安全还是要有的,不然岂不是谁都可以冒名顶替发送了嘛 mailPassword="r@123*qwe" # TLS mail protocol support 默认值即可 starttlsEnable="true" # SSL mail protocol support 默认值即可 # only one of TLS and SSL can be in the true state. sslEnable="false" #note: sslTrust is the same as mailServerHost 你的邮箱服务器 sslTrust="appmail.rowyet.cn" # resource storage type:HDFS,S3,NONE 因为博主有hdfs,打算把上传的资源文件放到hdfs,所以这些写hdfs,这里也支持s3,没有则写NONE resourceStorageType="HDFS" # 因为博主的是hdfs,则把s3相关的配置注释了 # if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory. # if S3,write S3 address,HA,for example :s3a://dolphinscheduler, # Note,s3 be sure to create the root directory /dolphinscheduler # 配置hdfs的集群,因为博主的是ha的hdfs,则直接配置集群的名称和8020端口 defaultFS="hdfs://dw-rowyet:8020" # if resourceStorageType is S3, the following three configuration is required, otherwise please ignore # s3Endpoint="http://192.168.xx.xx:9010" # s3AccessKey="xxxxxxxxxx" # s3SecretKey="xxxxxxxxxx" # if resourcemanager HA enable, please type the HA ips ; if resourcemanager is single, make this value empty 这里配置yarn,因为博主的yarn也是ha的,把两台全部写上 yarnHaIps="10.192.168.20,10.192.168.20" # if resourcemanager HA enable or not use resourcemanager, please skip this value setting; If resourcemanager is single, you only need to replace yarnIp1 to actual resourcemanager hostname. 默认即可 singleYarnIp="yarnIp1" # resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。/dolphinscheduler is recommended # 这个地方是你资源库上传的存放路径,因为配置在hdfs,所以下面的路劲是hdfs的 resourceUploadPath="/dolphinscheduler/data-1.3.5" # who have permissions to create directory under HDFS/S3 root path # Note: if kerberos is enabled, please config hdfsRootUser= hdfsRootUser="hadoop" # 因为博主没用到k8s,所以k8s的配置保持默认即可 # kerberos config # whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore kerberosStartUp="false" # kdc krb5 config file path krb5ConfPath="$installPath/conf/krb5.conf" # keytab username keytabUserName="hdfs-mycluster@ESZ.COM" # username keytab path keytabPath="$installPath/conf/hdfs.headless.keytab" # api server port 这里是你web ui和api的端口,默认是12345,生产环境建议改改,也是一种安全嘛,不改问题也不大,博主设置9090 apiServerPort="9090" # install hosts # Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname # 这里是你的整个dolphinscheduler集群的机器,一台都别少 ips="10.192.168.20,10.192.168.21,10.192.168.22,10.192.168.23,10.192.168.24" # ssh port, default 22 # Note: if ssh port is not default, modify here 默认即可 sshPort="22" # run master machine # Note: list of hosts hostname for deploying master 这里是你的两台master masters="10.192.168.20,10.192.168.21" # run worker machine # note: need to write the worker group name of each worker, the default value is "default" # 这里是你的workerserver,新版本里面work的分组必须配置在这里,如默认的defaul workers="10.192.168.22:defaul,10.192.168.23:defaul,10.192.168.24:defaul" # 如果多个分组,这样三台机器属于默认default组,22还属于etl组,23、24还属于realtime组; # 在运行任务和工作流时你是可以指定worker组的,但是博主觉得这个有点鸡肋,没必要分组,就采用默认的分组吧; # 因为测试下来调度的瓶颈往往是运行机器本身的资源,如一下子开多了,内存不够,所以worker分组只是利于管理,实际用处不大; #workers="10.192.168.22:defaul,10.192.168.23:defaul,10.192.168.24:defaul,10.192.168.22:etl,0.192.168.23:realtime,10.192.168.24:realtime" # run alert machine # note: list of machine hostnames for deploying alert server # 邮件告警服务器,一台即可 alertServer="10.192.168.22" # run api machine # note: list of machine hostnames for deploying api server # web ui和api调用的服务器,可以设置多台,且多台之间是相互独立的,可以高可用,挂一台另一台能正常工作 # 缺点也有,目前的版本不支持配置这个组的一个组名,即访问时只能单独写死ip,除非自己配置反向代理,本身不自带两台机器自动故障转移 apiServers="10.192.168.20,10.192.168.21"
特别提醒:
- 如果需要用资源上传到Hadoop集群功能, 并且Hadoop集群的NameNode 配置了 HA的话 ,需要开启 HDFS类型的资源上传,同时需要将Hadoop集群下的core-site.xml和hdfs-site.xml复制到/opt/dolphinscheduler/conf,非NameNode HA跳过次步骤;
- conf文件夹下的其他配置信息
master.properties、master.properties等如果你没有个性化的配置,就不用再修改了,如果想要个性化配置,可参考官网的配置文件; - 到此配置就全部结束了,接下来一键部署;
2.4.5 一键部署
20这台机器已经配置好了,为了方便,就把20这台机器的dolphinscheduler复制到21,22,23,24这些机器上,然后再一键部署启动;
shell
复制代码
# 以下步骤在21,22,23,24上都需要完成 # 以下步骤在21,22,23,24上都需要完成 # 以下步骤在21,22,23,24上都需要完成 # 以21为例 # 进入/data/tools cd /data/tools # 创建总文件夹dolphinscheduler mkdir dolphinscheduler # 进入dolphinscheduler cd dolphinscheduler # 将20上的tar复制到21 scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz /data/tools/dolphinscheduler/ # 解压 tar -zxvf apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz # 因为名字老长了,做一下重命名 mv apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin apache-dolphinscheduler-1.3.5 # 将20配置好的datasource.properties复制到21 scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /datasource.properties /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ # 将20配置好的install_config.conf复制到21 scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /config/install_config.conf /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/config # 将20配置好的install_config.conf复制到21 scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /env/dolphinscheduler_env.sh /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/env # 创建installPath,一定要安装的用户有可读可写的权限 mkdir install-ds-1.3.5 # 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软连即可,博主的独到秘籍 ln -sf /data/tools/dolphinscheduler/install-ds-1.3.5 current # 以上步骤在21,22,23,24上都需要完成 # 以上步骤在21,22,23,24上都需要完成 # 以上步骤在21,22,23,24上都需要完成 # 然后任意选一台机器,这里就选20吧,进入/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/ cd /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/ # 一键部署启动 sh install.sh #注意: # 第一次部署的话,在运行中第3步`3,stop server`出现5次以下信息,此信息可以忽略 # sh: bin/dolphinscheduler-daemon.sh: No such file or directory # 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的 # 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的 # 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的
2.4.6 守护进程与日志
还记得表2.2 集群模式机器部署安排吗,对着自己的机器安排,在不同的机器上执行jps,查看守护进程,以表格2.2为例,各守护进程分布如下;
shell
复制代码
MasterServer ----- master服务 (20,21机器) WorkerServer ----- worker服务 (22,23,24机器) LoggerServer ----- logger服务 (22,23,24机器) 这个不是启动日志,而是你的工作流运行的历史记录 ApiApplicationServer ----- api服务 (20,21机器) AlertServer ----- alert服务 (22机器) # 同理各自的启动日志也是跟着各个守护进程的机器的,这个才是集群启动的真正日志 logs/ ├── dolphinscheduler-alert-server.log (22机器) ├── dolphinscheduler-master-server.log (20,21机器) |—— dolphinscheduler-worker-server.log (22,23,24机器) |—— dolphinscheduler-api-server.log (20,21机器) |—— dolphinscheduler-logger-server.log (22,23,24机器) # 还记得配置的web ui端口吗?这个非常重要,可以在(20,21机器)查看下端口是否存在 ss -tnlp | grep 9090 # 一切都正常的可以访问web ui了,正常则查看对应守护进程的日志,看看有啥问题;
2.4.7 访问Web UI
访问Web UI的网址是:http://10.192.168.20:9090/dolphinscheduler或者http://10.192.168.21:9090/dolphinscheduler,,http://10.192.168.20:9090/dolphinscheduler,注意看仔细,后面还有一个dolphinscheduler,别漏了,跳转如图2.4.7; 默认账号:admin;默认密码:dolphinscheduler123;登录进去记得改一下 密码,生产环境还是安全点好,不要让你的密码别人一猜就中;

图2.4.7 WebUI首页
2.4.8 启动与关闭守护进程
和日常的java守护进程一样,放在文件件install-ds-1.3.5/bin/下,注意这里最好就使用你的install-ds-1.3.5目录下去开启了,最好能测试下是否能正常 启动与关闭守护进程; 特别提醒:java程序有时候会出现stop不掉的情况,实在stop不掉,就直接kill,但是优先stop,因为stop其实会做一下守护进程的安全退出工作,kill则是异常退出;当然也会有start不成功的,那就需要你去查看下install-ds-1.3.5/logs/相应服务的日志,查看下为啥start失败了,这个原因有很多,自己网上百度下对症下药吧;
shell
复制代码
# 一键停止集群所有服务 sh ./bin/stop-all.sh # 一键开启集群所有服务 sh ./bin/start-all.sh # 启停Master sh ./bin/dolphinscheduler-daemon.sh start master-server sh ./bin/dolphinscheduler-daemon.sh stop master-server # 启停Worker sh ./bin/dolphinscheduler-daemon.sh start worker-server sh ./bin/dolphinscheduler-daemon.sh stop worker-server # 启停Api sh ./bin/dolphinscheduler-daemon.sh start api-server sh ./bin/dolphinscheduler-daemon.sh stop api-server # 启停Logger sh ./bin/dolphinscheduler-daemon.sh start logger-server sh ./bin/dolphinscheduler-daemon.sh stop logger-server # 启停Alert sh ./bin/dolphinscheduler-daemon.sh start alert-server sh ./bin/dolphinscheduler-daemon.sh stop alert-server
到此整个安装部署就完成了,官网还绑定一块企业微信告警,个人觉得,并不是大多数的公司都适合企业微信告警,支持企业微信的可以按照官网配置,比如博主就喜欢钉钉告警,这个就可以接入在自己的shell脚本实现,有兴趣的可以查看下博客调度Job报错或异常触发钉钉报警(Python 3.x版);
3. 实战教学
账号登录后跳转如图3.0,主要先关注下菜单栏,从左到右边分别是DolphinScheduler、首页、项目管理、资源中心、数据源中心、监控中心、安全中心(非admin账号不可见)、中英文(下拉语言选择)、admin(下拉查看你登录的账号信息及退出),接下来博主根据实际运用中的频率从低到高依此讲解这些菜单栏的使用。

图3.0 登录系统后的界面
3.1 用户退出&语言选择等杂项
语言选择:下拉可以选择中文、English;毕竟国人之光,中文肯定不能少,英语国际通用化;用户信息及退出:如图3.1,下拉显示用户信息、退出,退出则挑战登录界面图2.4.7,可选择账号重新登录;用户信息则有用户信息(可以编辑用户名、邮箱。手机),修改密码(修改用户的密码,admin的密码建议修改,在此操作);

图3.1 用户信息及退出
3.2 监控中心
如图3.2,此处就是将你的MasterServers、WorkerServers、Zookeeper集群、DB等集群中的机器性能(CPU、内存)和状态做一个展示。懂运维监控的同学都知道获取机器的这些数值并不难,但是DolphinScheduler展示的帅呀,界面做的非常清爽,总之帅就完事了;

图3.2 监控中心 ,
3.3 安全中心
这个菜单栏只有管理员账号才能看到,普通账号是无法看到的,普通用户只能通过3.1的用户信息及退出修改自己的用户信息,修改密码、令牌管理;
当切换到管理员账号,点击安全中心时,跳转如图3.3.1;右边栏分为租户管理,用户管理、告警组管理、Worker分组管理、队列管理、令牌管理,接下来做一个简单介绍;

图3.3.1 安全中心主页
3.3.1 队列管理
先讲队列管理吧,这个是最基础的,因为新建用户和租户时会让你选择队列管理,队列管理最好能跟你yarn里面的队列名字保持一致,因为在当你提交yarn的,spark,flink,mapreduce等程序时,默认是你用户管理(注意是用户管理,不是租户管理)选的队列就是你yarn里面的队列,比如博主新建一个hadoop账号,hadoop选择的etl队列,当以hadoop运行yarn的任务时,默认就是分配到yarn里面的etl队列,所以希望你的队列尽量跟yarn一致,如果不是yarn任务,比如mysql脚本之类的,此时的队列无任何作用,随便设置;为啥是希望而不是一定要和yarn队列一致呢?因为这些spark,flink,mapreduce等的yarn任务,在跑的时候也可以指定队列参数,所以当你指定了参数后,hadoop账户原始指定的队列将被忽略; 创建队列的操作如图3.3.2;
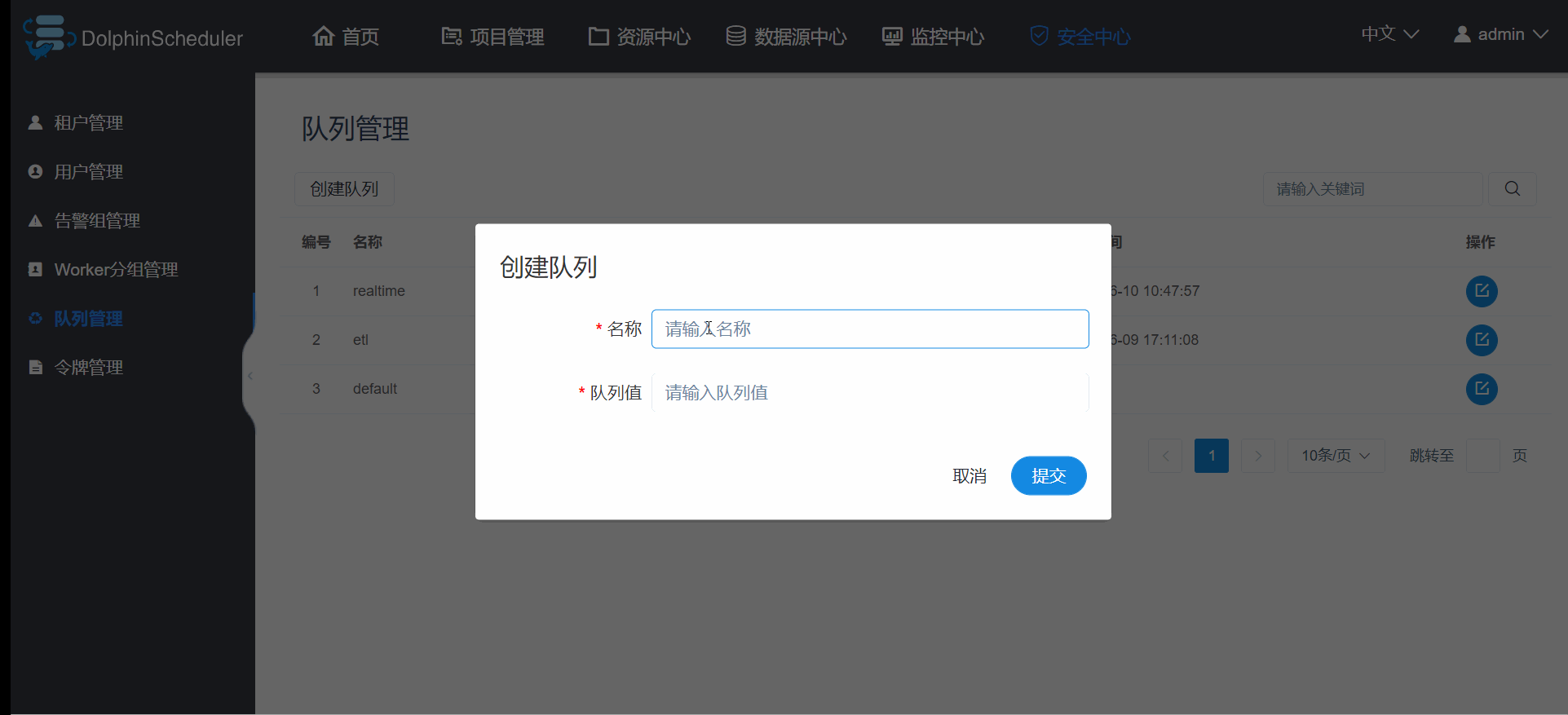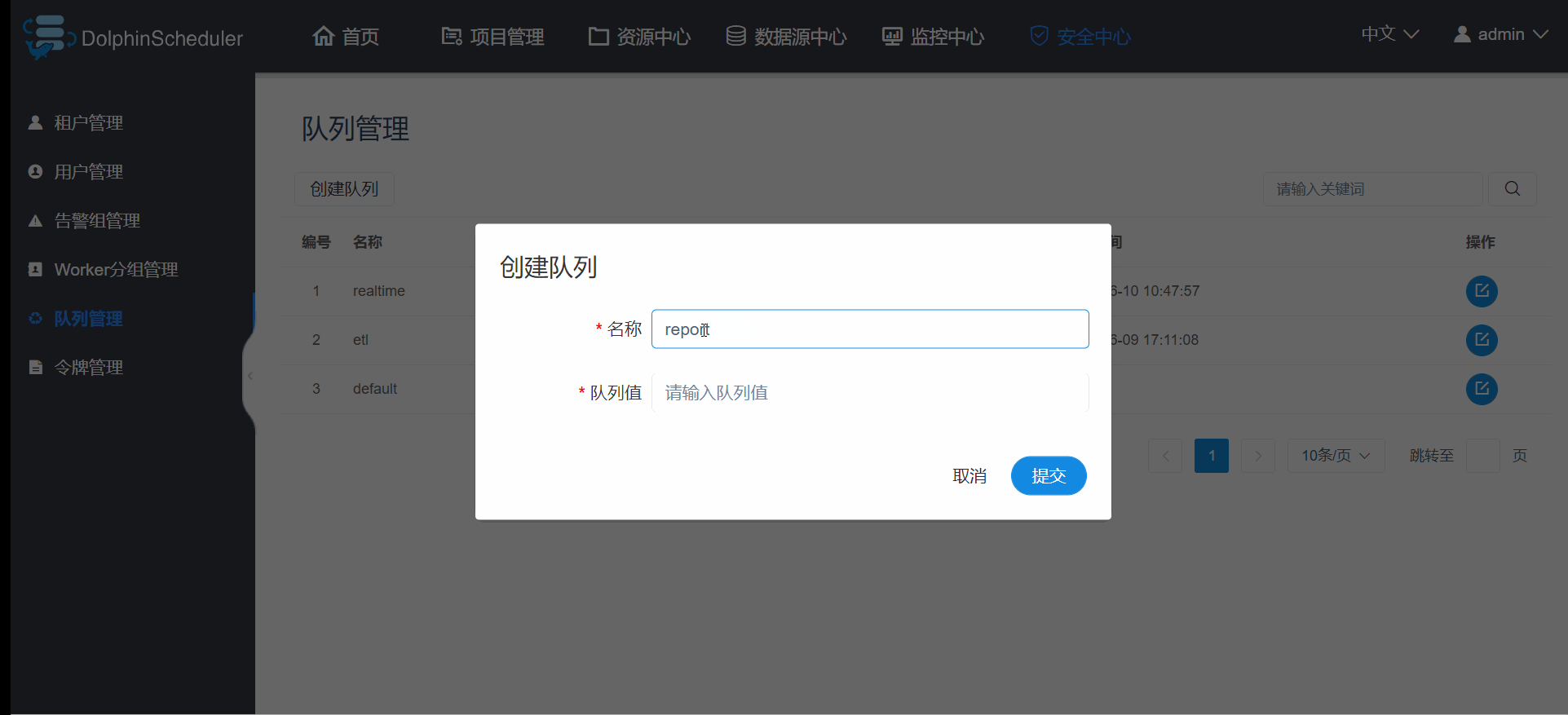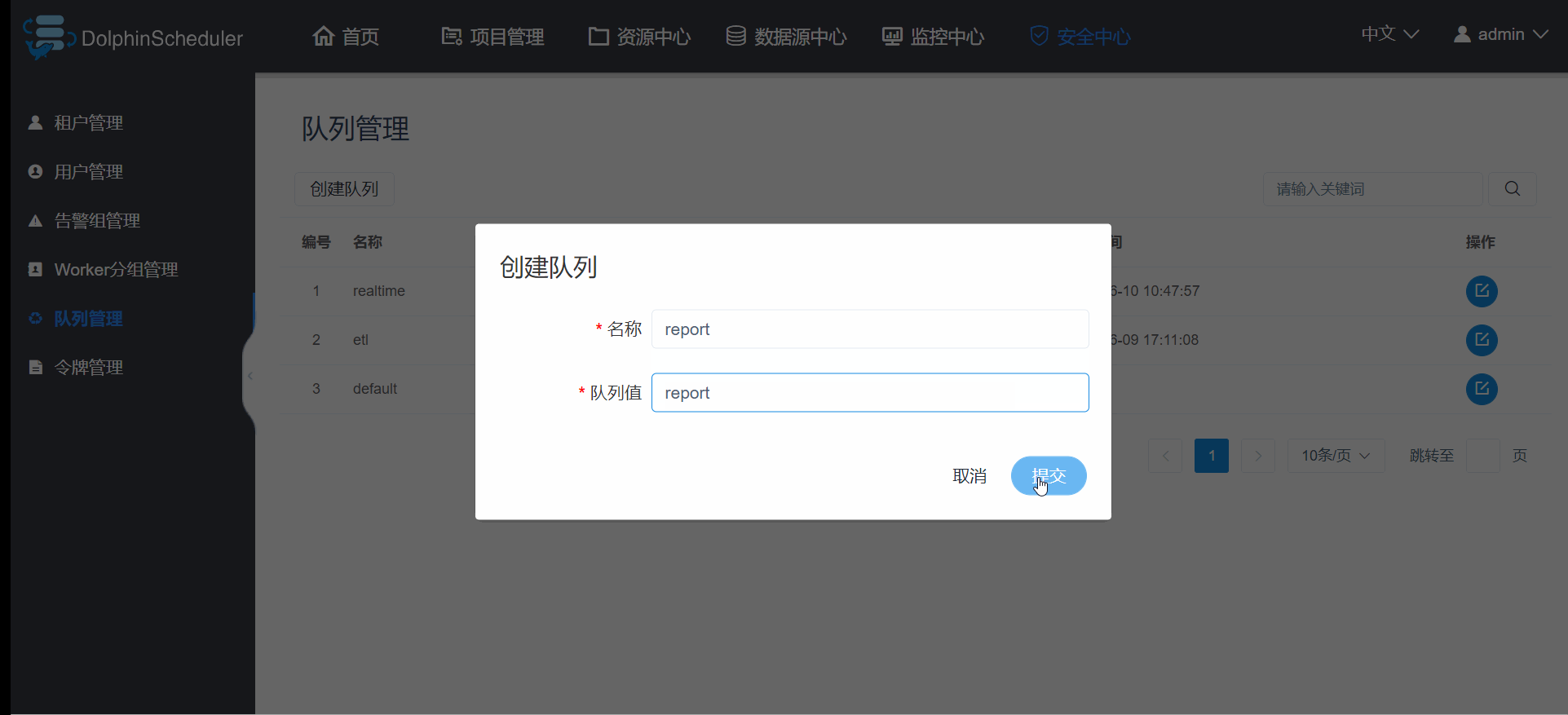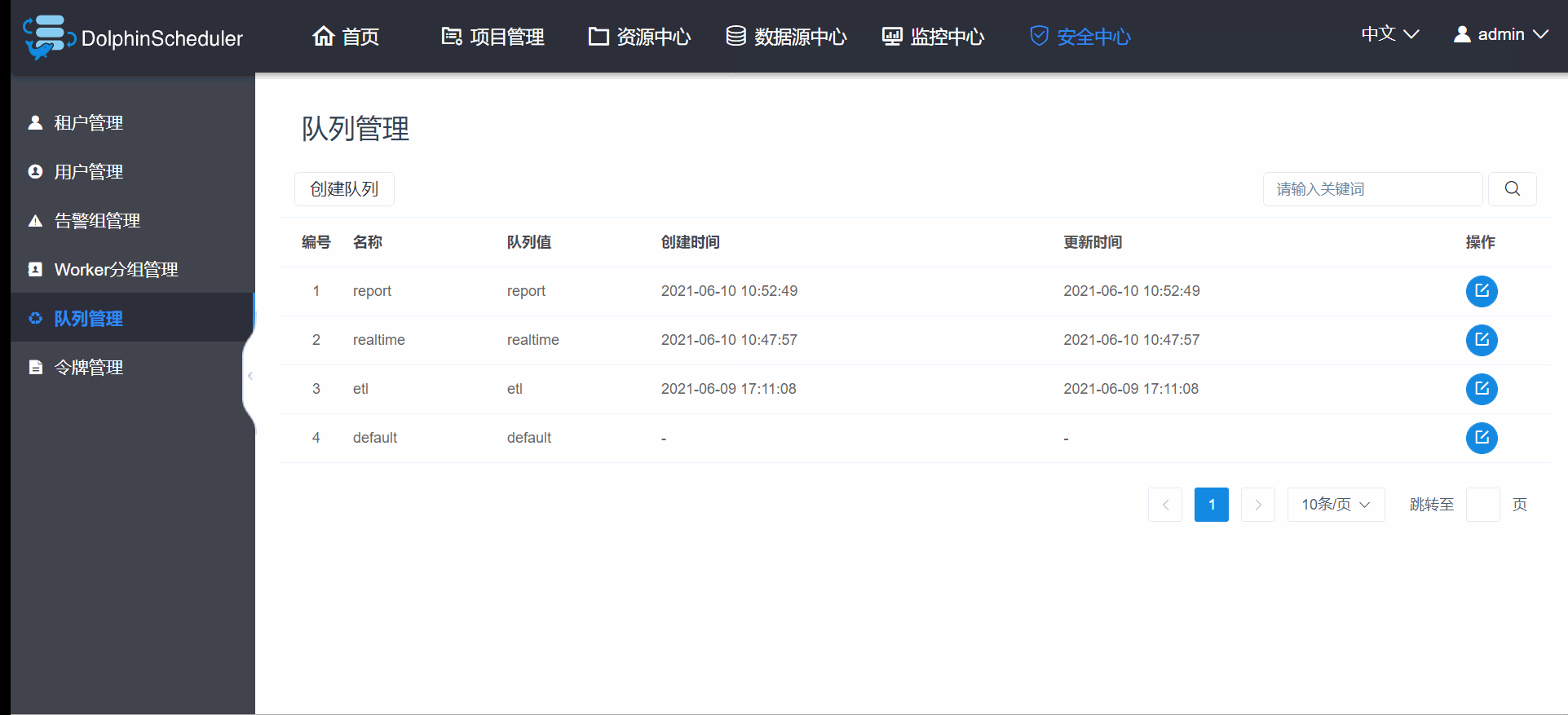
图3.3.2 队列管理
3.3.2 租户管理
租户其实就是你DolphinScheduler集群机器里面真实的linux用户;其实也很好理解,DolphinScheduler的用户运行任务,但是任务真正在集群机器里面执行,必然是要用到Linux用户去执行,所以DolphinScheduler的用户必须绑定一个租户,而且,租户必须是群机器里面真实的linux用户,多个DolphinScheduler的用户可以绑定同一个租户; 创建租户的操作如图3.3.3,博主的集群机器里有个linux账号叫ds;

图3.3.3 租户管理
3.3.3 用户管理
用户管理就是管理登录DolphinScheduler的用户,新建用户如图3.3.4,一定要绑定租户,一定要写邮箱,用户邮件服务,要选一个队列,密码为登录DolphinScheduler的Web UI的密码,请妥善保管;

图3.3.4 用户管理
用户管理还有些很重要的功能,比如编辑用户,删除用用户(管理员不可删),另外一个就是授权功能,你可以将已存在的项目、资源、数据源、UDF函数授权给其他需要的用户,实现复用,这一点感觉很友好,不然会冗余很多不必要的资源,但是切记,只有管理员能看到这个界面哟,即只有管理员能做这个事情。

图3.3.4 用户管理及授权管理
3.3.4 告警组管理
告警组就是设置一个告警的组,将你DolphinScheduler的用户选择性的加进去,然后,在后续你运行的任务成功或者失败后可以选择通知哪个告警组,告警组管理如图3.3.5;

图3.3.5 告警组管理
3.3.5 Worker分组管理
新的版本已经不支持在Web UI界面新建Worker分组了,需要配置Worker分组,需要在配置文件里面conf/config/install_config.conf的workers="10.192.168.22:defaul,10.192.168.23:defaul,10.192.168.24:defaul,10.192.168.22:etl,0.192.168.23:realtime,10.192.168.24:realtime如此来指定了,然后再重启,这个界面如图3.3.6,只能做一个预览; 博主个人测下来,发现任务调度的瓶颈不在Worker选择本身,而在于任务运行所需要的资源耗费本身,加上调度规模不是特别复杂,就没有对Worker分组,如果个人有需要,可以根据个人的设置,如果你了多个Worker分组,任务调度时就可以选择Worker分组,那么任务只会去这个组的这些Worker上调度(注意:不一定就在Worker分组上运行,这个要结合你的脚本,比如你指定的是spark的yarn cluster模式,那脚本就运行在yarn cluster里,Worker分组只是做了一个提交的动作,这一点要切记),从而做个任务运行调度机器隔离。

图3.3.6 Worker分组管理
3.3.6 令牌管理
令牌管理是绑定用户的,类似于用户的一个秘钥,在调用api时候会用到,平时没啥用;注意,Dolphinscheduler的令牌失效时间一定要你写,如果你不想老更换,你就时间写大点;

图3.3.7 令牌管理
3.4 数据源中心
数据源中心就是在后续项目开发中,你设计的工作流中有个SQL控件,可以执行SQL相关的查询和非查询语句,所以需要依赖数据源,数据源的管理中心就在此处,如图3.4.1,点击创建数据源,支持MYSQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER、DB2数据源,创建都是依赖JDBC的参数,这里就以MySQL为例创建一个,然后点击测试连接,显示上方弹出成功,则代表连接成功,点击提交保存; 因为是JDBC连接,所以也可以加一下JDBC的优化参数,DolphinScheduler要求以json的格式填写,举例如下。
json
复制代码
{"rewriteBatchedStatements":"true","useServerPrepStmts":"true" ,"characterEncoding":"utf8","useCompression":"true"}

图3.4.1 数据源中心管理
3.5 资源中心
资源中心就是将你自己的脚本、jar包、UDF函数等资源文件上传到之前安装配置文件conf/config/install_config.conf指定的resourceUploadPath="/dolphinscheduler/data-1.3.5"处,因为博主配置 的是用hdfs来存储资源文件,所以最终就会上传到hdfs的/dolphinscheduler/data-1.3.5目录下,当然,也是支持你新建文件夹; 如图3.5.1,资源中心分为文件管理和UDF管理,UDF管理又分为资源管理,函数管理;资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件 操作功能:重命名、下载、删除,因为目前UDF函数只支持HIVE的临时UDF函数,所以博主觉得这个功能非常鸡肋,生产中几乎没啥用,因为真要UDF,博主一般都是注册成永久UDF的,所以重点说说文件管理。

图3.5.1 资源中心
文件管理:支持你创建文件夹(文件夹只能由重命名和删除操作),创建文件,文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties;或者上传本地已存在的文件;文件的操作支持编辑、文件重新上传、重命名、下载、删除;点击文件名称可以进行查看文件内容,具体操作如图3.5.2; 文件管理的用途:那自然就是这个文件上传上去后有什么用呢,那就是在你任务调度的时候,控件是支持你引用文件的,也就是说到时候你只要sh /data/hello.sh就能执行资源中心的这个文件脚本,而不用再重新写;

3.5.3 文件管理操作
注意:博主将资源中心上传到了hdfs对吧,那hdfs和Web UI端的文件存在以下关系: 1 Web UI端新增一个时文件或者文件夹时,这个不用多说,hdfs自然会存下来(其实新建一个文件夹hdfs是不会新建文件夹的,只有该文件夹内有资源时,hdfs才会把文件夹和资源一起建立起来); 2. 当我在Web UI端删除一个文件和文件夹时,hdfs文件系统内也会删除; 3. 但是当我在hdfs删除一个文件时,Web UI端不会删除,但是当你再打开时会报异常说hdfs该文件不存在; 4. 当你上传一个文件到hdfs指定的资源目录下时,你刷下下Web UI端的界面,依然是看不到你hdfs上传的文件的; 5. 目前文件只支持单个上传,不支持批处理。
3.6 项目管理
这一节也是工作中接触到的最频繁的,博主这里也重点阐述下;首先来阐述下几个重要的概念,只要是调度器,基本都有项目,其实就是一个命名空间或者文件夹的概念,来归档管理不同的工作流;工作流,就是将多个任务连接有序的连接起来的一个组合;最小单位就是任务,具体需要执行功能的一个控件;如图3.6.1,一个项目下可以有多个工作流,换句话说你也可以将所有工作流放在一个项目内,只是这样不方便管理和用户授权,多个工作流之间本身是相互独立没有依赖的,但是DolphinScheduler有控件可以支持他们有依赖,这个后续控件再讲解,最后就是一个工作流下面的一个或多个任务; 举个不太恰当的比喻:项目就是你面向对象编程的工程,工作流就是你的类,任务就是你实现功能的函数;而DolphinScheduler 里面的工作流实例就是带调度时间的一次类的初始化后的实例对象,任务实例就是初始化是对象运行这个传入参数运行的函数,可能有些不恰当哈,纯属个人理解,总之你能理解就行;

图3.6.1 项目、工作流、任务关系图
3.6.1 创建、编辑、删除项目
首先如图3.6.2,先来创建一个项目,创建完后可以对项目进行编辑和删除,点击项目名称,就可以跳转到该项目的项目首页(这里的项目首页和3.7的项目首页略有不同,这里只能看到自己项目的流程状态和任务状态统计,而3.7的是所有项目的统计)和该项目的工作流,工作流下包含工作流定义、工作流实例、任务实例,这些概念理解之前一段已讲解,这里就不累赘了,大家理解即可。

图3.6.2 创建、编辑、删除项目
3.6.2 工作流定义
操作如图3.6.3:
- 支持
创建工作流(新建一个工作流)和导入工作流(将别人的已存在的工作流文件给你,让你加载进来);- 点击
创建工作流后跳转ETL作业的编辑界面,左侧工具栏是目前支持的控件;- 将左侧你需要的控件鼠标左键拖拽到界面进行编辑;
- 增加任务执行的先后顺序: 点击右上角
横线图标连接任务;- 删除依赖关系: 点击右上角
箭头图标,选中连接线,点击右上角删除图标,删除任务间的依赖关系。- 删除控件:点击控件,点击右上角
删除图标;- 下载工作流:点击右上角的
云朵,下载的文件可通过步骤1的导入工作流加载进来,形成呼应;- 全屏操作:点击右上角的
全屏按钮支持放大全屏;- 格式化DAG:点击
格式化DAG按钮,不是删除格式化的那个意思,是对整个DAG的排版布局进行调整,看起来舒畅;- 保存工作流定义: 点击”保存“按钮,弹出"设置DAG图名称"弹框,进行保存。

图3.6.3 工作流定义
工作流保存后,会形成一个工作流列表,工作流定义列表的操作功能如下:
编辑: 只能编辑"下线"的工作流定义。工作流DAG编辑同创建工作流定义。上线: 工作流状态为"下线"时,上线工作流,只有"上线"状态的工作流能运行,但不能编辑。下线: 工作流状态为"上线"时,下线工作流,下线状态的工作流可以编辑,但不能运行。运行: 只有上线的工作流能运行。运行操作步骤见2.3.3 运行工作流。复制工作流:工作流状态为"下线"时,可以复制一份已存在的工作流副本,进行操作。定时: 只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为"下线",需在定时管理页面上线定时才生效。定时操作步骤见2.3.4 工作流定时。定时管理: 定时管理页面可编辑、上线/下线、删除定时。删除: 删除工作流定义。下载: 下载工作流定义到本地。树形图: 以树形结构展示任务节点的类型及任务状态。
3.6.3 工作流手动运行
只有上线的工作流才能运行,工作流运行的操作如图3.6.4;
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。”继续“表示:某一任务失败后,其他任务节点正常执行;”结束“表示:终止所有正在执行的任务,并终止整个流程。
- 通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
- 流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。当master线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
- worker分组:该流程只能在指定的worker机器组里执行。默认是Default,可以在任一worker上执行。
- 通知组:选择通知策略||超时报警||发生容错时,会发送流程信息或邮件到通知组里的所有成员。
- 收件人:选择通知策略||超时报警||发生容错时,会发送流程信息或告警邮件到收件人列表。
- 抄送人:选择通知策略||超时报警||发生容错时,会抄送流程信息或告警邮件到抄送人列表,最后的收件人是收件人列表+通知组两组的人。
- 启动参数: 在启动新的流程实例时,设置或覆盖全局参数的值。
- 补数:包括串行补数、并行补数2种模式。串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,依次生成N条流程实例;并行补数:指定时间范围内,多天同时进行补数,同时生成N条流程实例,补数的时间会影响你定义的时间参数;
- 工作流一旦被运行,就会形成工作流实例和任务实例,点击工作流实例可以查看目前正在跑的工作流,可以暂停、停止工作流,也可以查看工作流运行的甘特图(每个任务运行耗时明细),当工作流实例运行完成时,可以进行
编辑,重跑,这个大特色操作参考3.6.5工作流实例重跑(大特色);- 工作流一旦被运行,也会形成任务流实例,即这个工作流包含的任务正在运行,任务流实例可以看到该任务的运行信息,如在哪台worker上运行,运行状态,耗时,运行的日志等。 **注意暂停和停止任务慎用,坑多,属性进程管理的都知道,要挂起一个进程或者终止一个进程,是有很多意外的,能不用则别用吧。

图3.6.4 工作流手动运行
3.6.4 工作流定时调度
调度器,顾名思义除了要支持手动运行外,还需要支持定时的Schedule调度,具体操作如如图3.6.5 :
- 采用的crond定时任务的表达式,只是加了图形界面操作,按需求设置好以后点击
执行时间可以查看接下来五次执行时间,确保自己设置的crond定时任务的表达式准确,其他配置和手动运行的参数类似,这里不再累赘;- 定时上线:点击"定时管理"按钮,进入定时管理页面,点击"上线"按钮,定时状态变为"上线",工作流定时生效;
- 如果定义的scheduler为每一天10点,但是希望明天不执行,那么只需下线,后天再上线即可;
- 注意:如果项目下线,定时任务管理也会跟着下线,当项目调整完再上线时,定时任务管理并不会自动上线,切记要手动让定时任务管理一起上线,切记要手动让定时任务管理一起上线,切记要手动让定时任务管理一起上线,否则作流定时不生效。
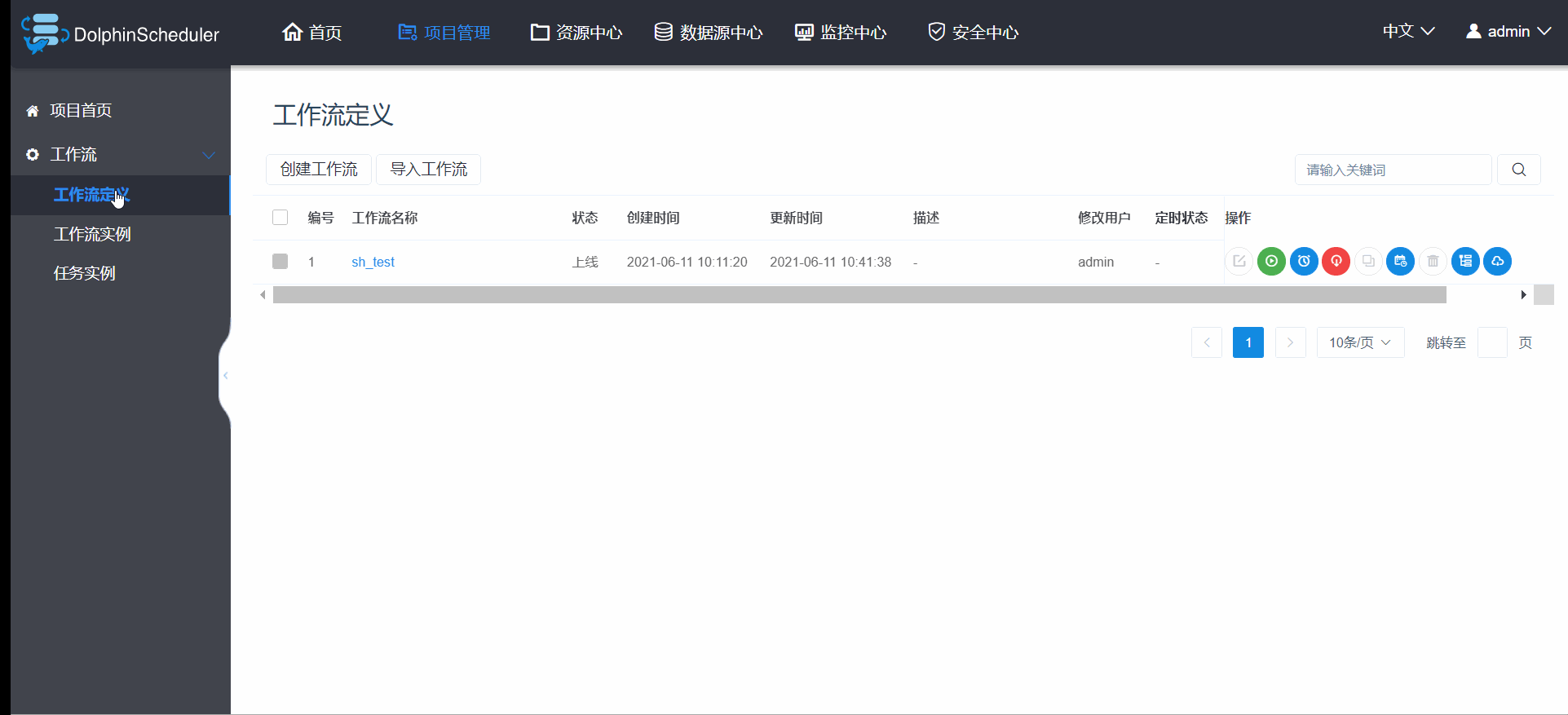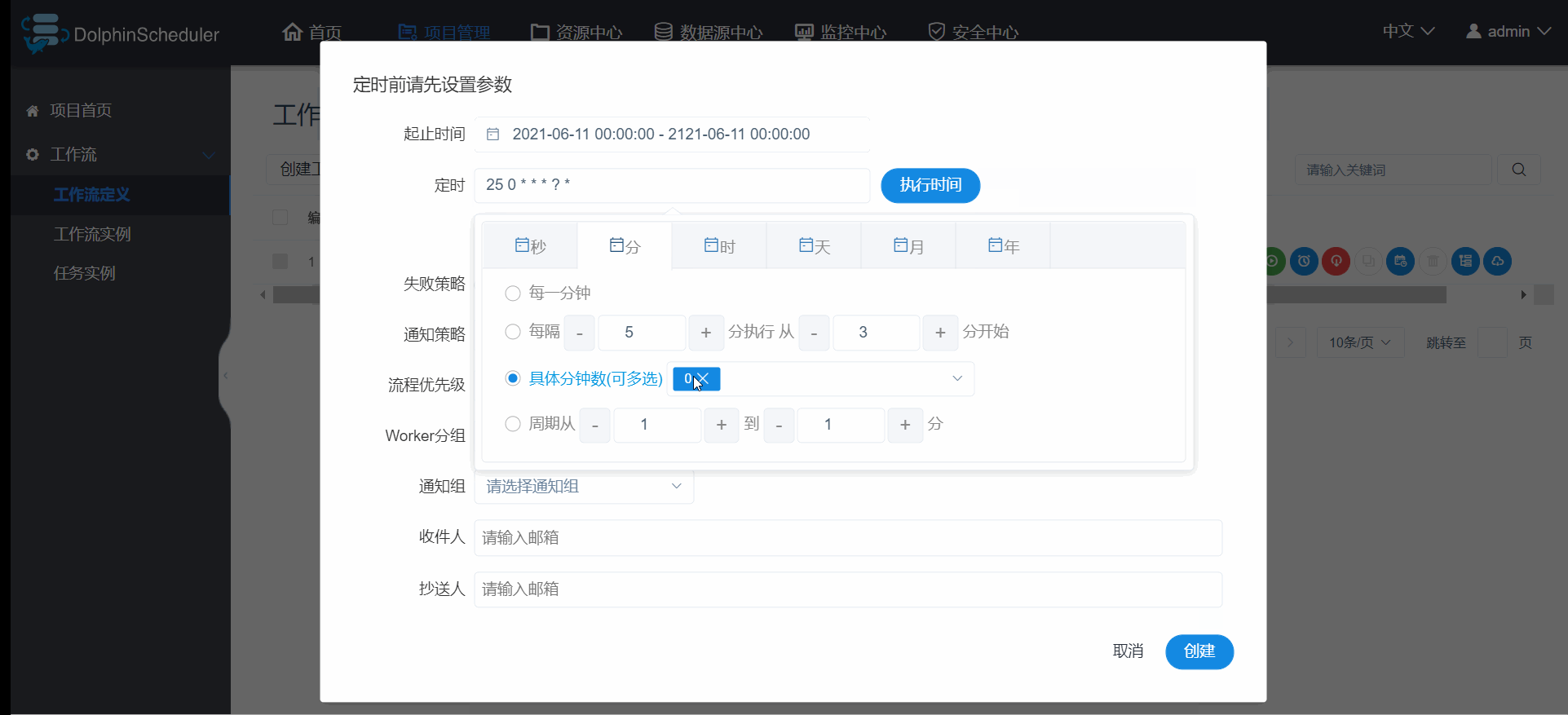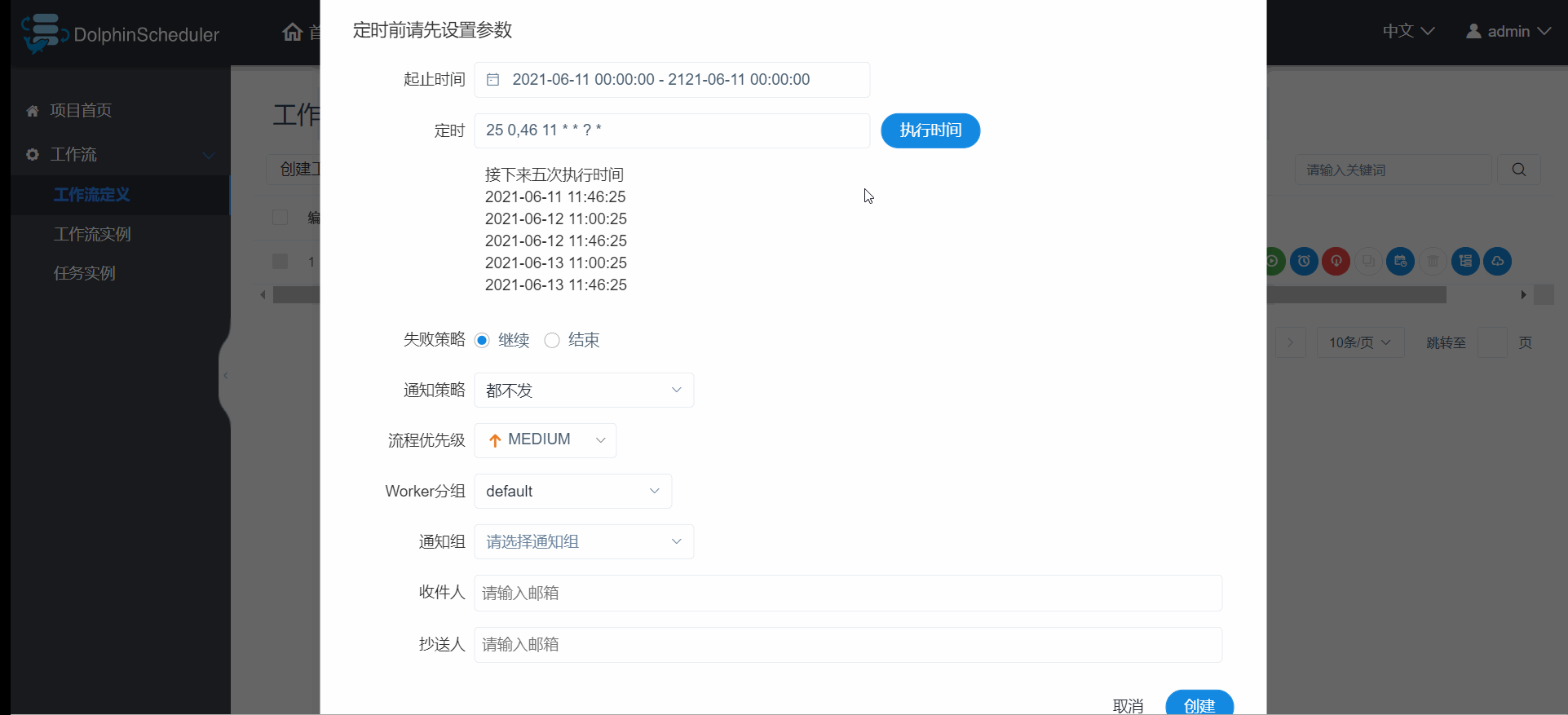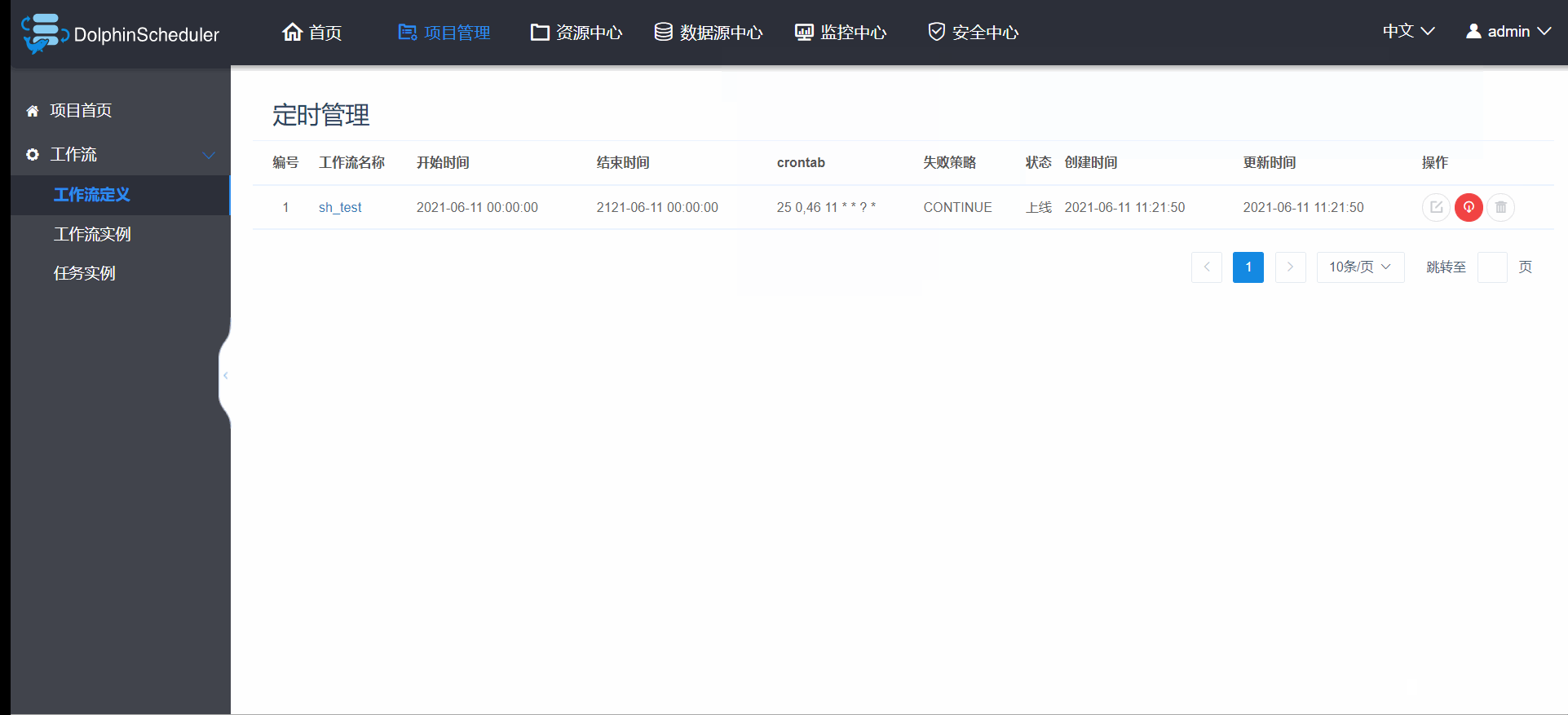
图3.6.5 工作流定时调度
3.6.5 工作流实例重跑(大特色)
DolphinScheduler的工作流重跑,除了支持正常的重跑以外,还可以允许你重新编辑工作流实例,新加、删除任务,然后你可以选择这次修改是否同步到你的工作流定义中,如果同步,则相当于改了工作流定义,如果不同步,则只是这次的工作流实例更改,再重跑该工作流实例,就是你修改的部分已回加载进来,厉害吧;这里之后你是否更好理解工作流实例和工作流定义的关系,即工作流定义就像一个模板,而工作流实例就是模板的基础上加自己的特色形成的调度。 操作明细如图3.6.6。
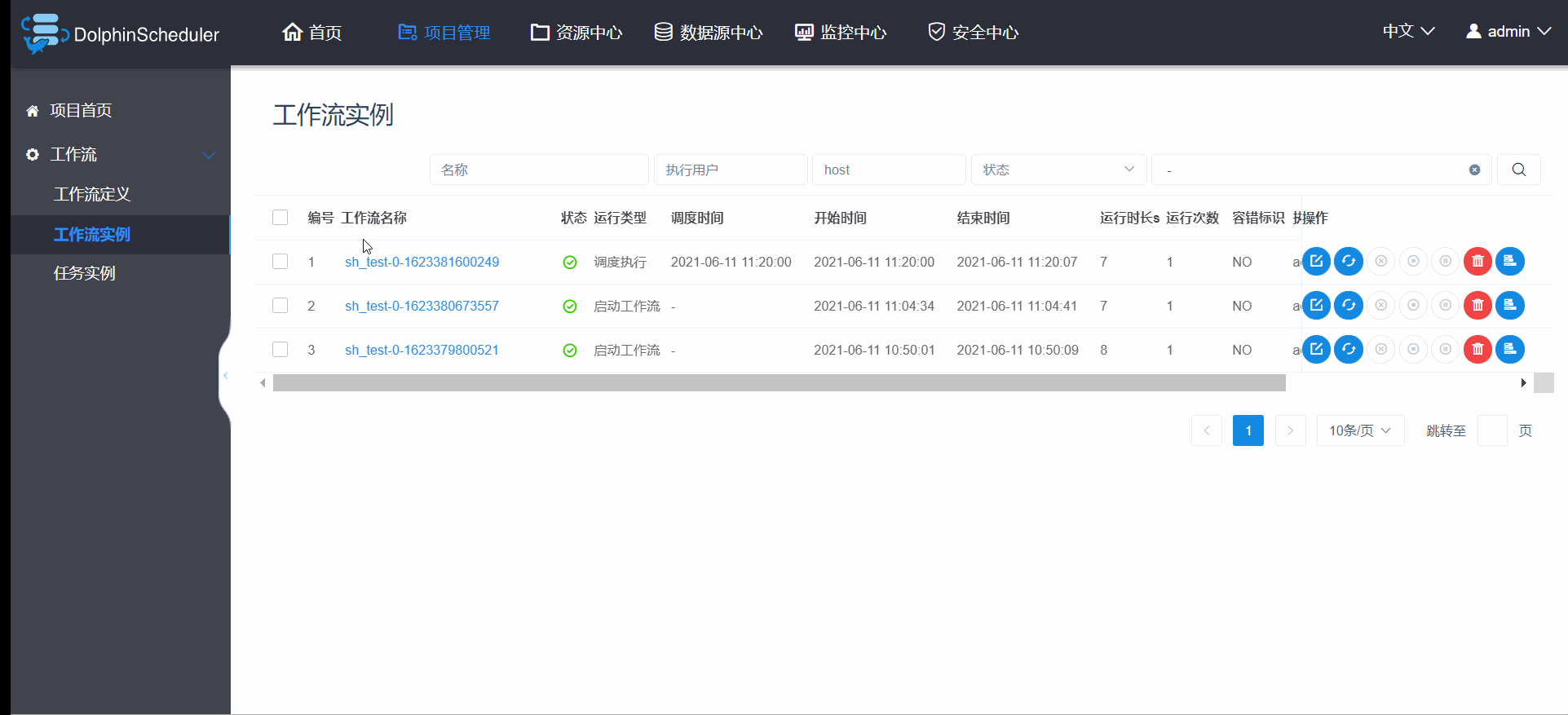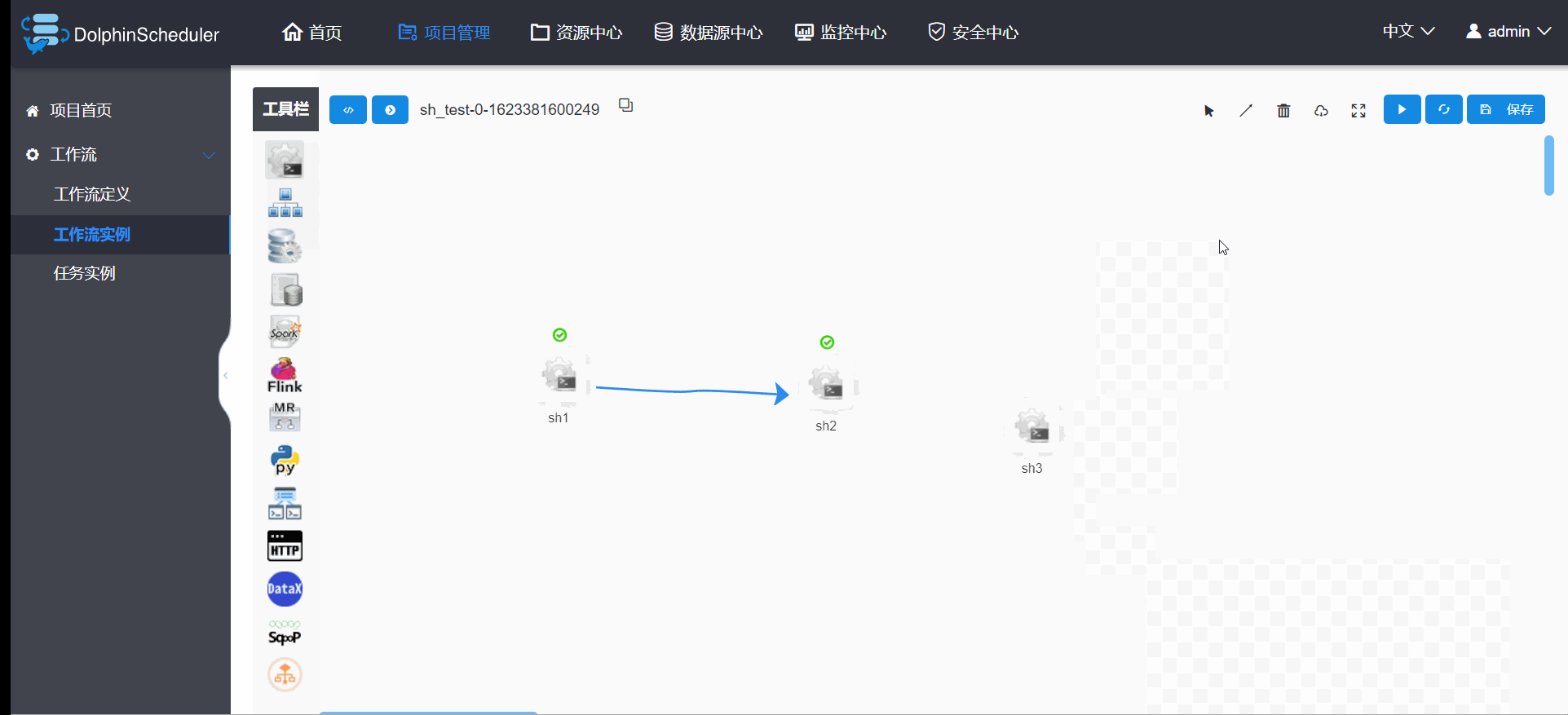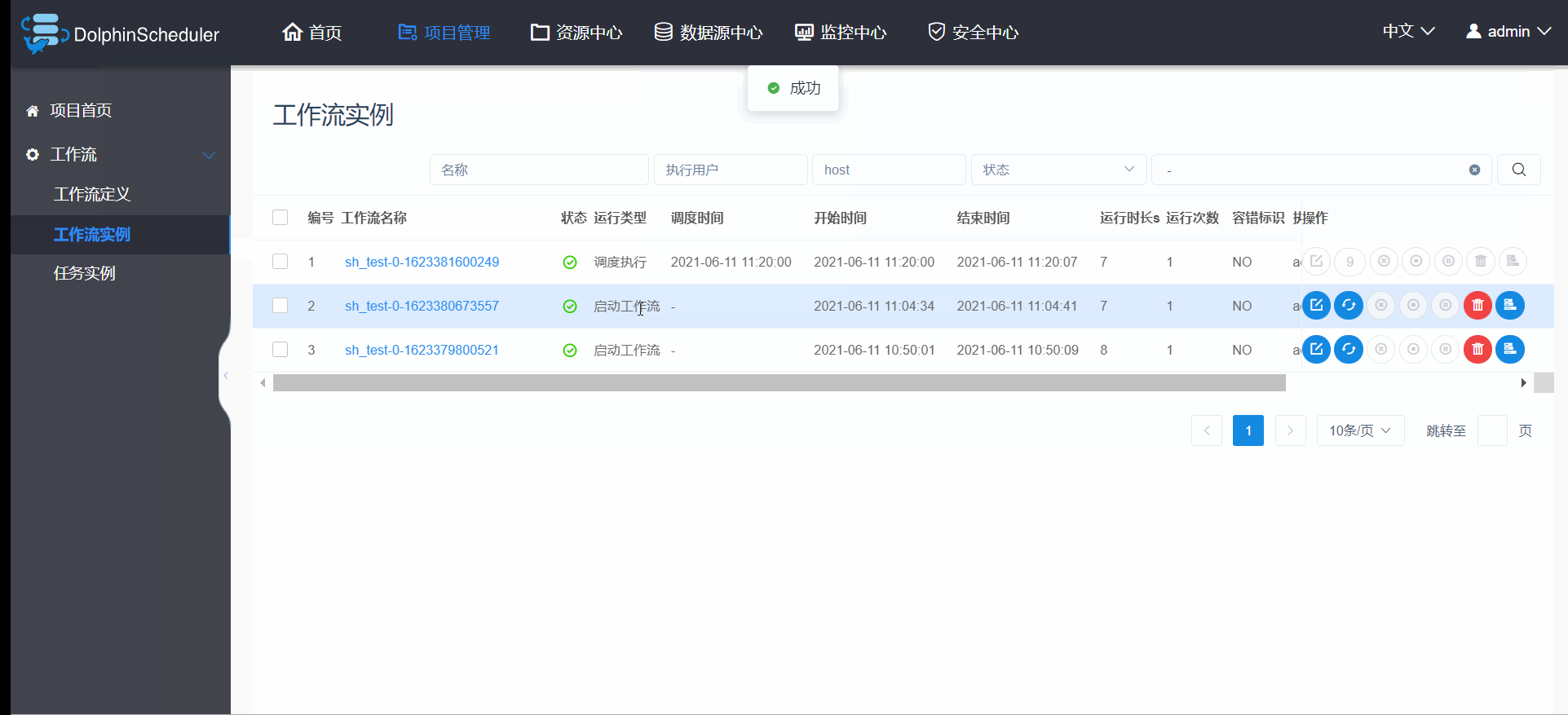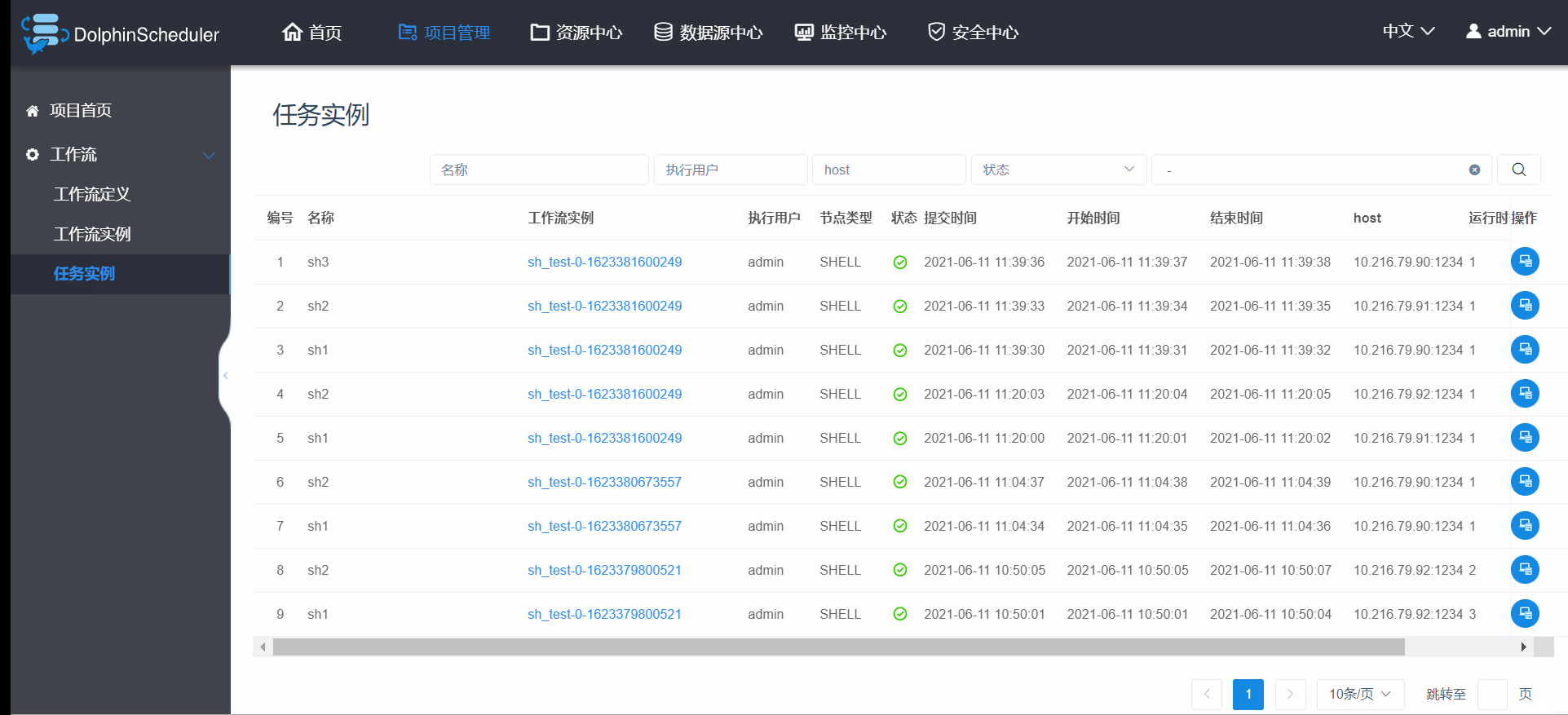
图3.6.6 工作流实例重跑
3.6.6 查看任务日志及历史运行
查看任务日志及历史运行的操作如图3.6.7;
- 查看日志可以直接点击
任务实例,再找到对应的任务实例列表,点击查看日志按钮查看日志;- 跳出的日志界面,支持下载运行日志,刷新日志进度,全屏查看;
- 查看任务日志及历史运行也可以点击
工作流实例,然后选择工作流名称,跳转ETL界面的运行情况,鼠标选择你想看的那个控件左键双击,跳转当前节点设置,右上角可查看该控件节点的查看历史和查看日志;- 看完这里,是否对安装机器里面为啥LoggerServer要跟着WorkerServer更好理解了。

图3.6.7 查看任务日志及历史运行
3.6.7 各大ETL控件介绍
3.6.7.1 SHELL(SHELL脚本)
- 基本使用如图3.6.8;
- 配置的信息都好懂,重点说下可以自己写脚本,可以引用
资源(资源中心的shell脚本),然后sh 资源相对路径进行执行;- 自定义参数参考
3.6.7 参数设置;

图3.6.8 SHELL的使用
3.6.7.2 SUB_PROCESS(引用同项目下的其它工作流)
- 当在执行项目A里面的工作流1时,你希望带起该项目A下的工作流2一起跑,即打破同一项目下的工作流壁垒,让同一项目下工作流之间有依赖时使用该控件。 2.使用配置如图3.6.9。

图3.6.9 SUB_PROCESS的使用
3.6.7.3 PROCEDURE(执行存储过程)
1 . 使用如图图3.6.10,该控件首先是要支持存储过程的数据库; 2. 引用
数据源中心配置的数据源,方法其实就是你的存储过程名称; 3. 这个控件有点鸡肋,因为还有个控件SQL,也可以通过执行非查询的call存储过程的SQL语句来执行存储过程。

图3.6.10 PROCEDURE使用
3.6.7.4 SQL(执行查询或非查询的SQL语句)
- 数据源:选择对应的数据源
- sql类型:支持查询和非查询两种,查询是select类型的查询,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板。非查询是没有结果集返回的,是针对update、delete、insert三种类型的操作。
- sql参数:输入参数格式为key1=value1;key2=value2…
- sql语句:SQL语句
- UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数。
- 自定义参数:SQL任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
- 前置sql:前置sql在sql语句之前执行。
- 后置sql:后置sql在sql语句之后执行。
- 查询语句会将你的查询结果在根据你配置的邮箱以邮件附件或者表格内容正文的形式发送给到收件人和抄送人,这个功能还是很强的,遗憾的是目前的版本只支持xls的excel-2003,有点微瑕吧; 10 . 整体使用如图3.6.11。

图3.6.11 SQL使用
配置查询SQL语句的邮件表格或附件发送结果如图2.6.12。

图3.6.12 SQL使用
3.6.7.5 Spark、Flink、MR(MapReduce)大数据控件
调用这些大数据控件的本质其实还是运行了对应的shell脚本,如spark的spark-submit,而且这三个控件的配置非常相似,这里就以spark为例讲解;
- 程序类型:支持JAVA、Scala和Python三种语言
- 主函数的class:是Spark程序的入口Main Class的全路径
- 主jar包:是Spark的jar包
- 部署方式:支持yarn-cluster、yarn-client和local三种模式
- Driver内核数:可以设置Driver内核数及内存数
- Executor数量:可以设置Executor数量、Executor内存数和Executor内核数
- 命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、--files、--archives、--conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
- Spark版本,注意这里的Spark版本可不是1.x和2.x哈,这里是对应你配置的DolphinScheduler的环境变量
conf/env/dolphinscheduler_env.sh里的SPARK_HOME1和SPARK_HOME2,你配置了哪个就使用哪个- 选项参数:这里允许你新增或者修改控件未给出的spark的参数,如yarn队列
--queue etl,不写则默认是你使用的DolphinScheduler用户的队列值,再如你部署模式勾选的是local,但是后续的选项参数你写--master yarn --deploy-mode cluster,那么依然会是集群模式,同时有选项参数,也为非yarn资源管理器如mesos提供了支持 再次强调控件本质是转换成了shell脚本,这些控件也可以使用shell脚本代替,其实大多数控件都可以用shell脚本代替,只是控件为你提供了更好的图形界面配置参数。

图3.6.13 Spark、Flink、MR使用
如图3.6.14,通过日志可以看到Spark控件的本质还是跑的shell脚本的spark-submit;

图3.6.14 Spark、Flink、MR日志
3.6.7.6 Python
使用python节点,可以直接执行python脚本,对于python节点,本质也是worker会使用python **shell脚本方式提交任务,具体使用如图3.6.15。

图3.6.15 Python使用
3.6.7.7 DEPENDENT(与本项目或者其他项目的某些工作流有依赖)
这个控件就是打破项目之间的壁垒,当你在跑项目A的工作流1时,但是此时你希望项目B的整组工作流或者其中某个工作流完成后才能跑当前的工作流,即,项目A的工作流1依赖其他项目或者自身项目的某些工作流,就可以使用该控件;如果依赖的工作流在你指定的时间内没成功记录,则后续的任务不会跑,直到依赖的工作流成功运行或超时失败为止,具体使用如图3.6.16;

图3.6.16 DEPENDENT使用
3.6.7.8 HTTP(刷网页请求)
这个控件用的比较少,博主会用来刷一些solr索引,配置操作如图3.6.17;

图3.6.17 DEPENDENT使用
3.6.7.9 DataX和Sqoop(ETL工具)
这两个ETL工具,但是博主习惯用Spark做ETL,所以这两个控件用的少,有兴趣的可以参考下官网DATAX节点。
3.6.7.10 CONDITION(条件判断,上一个任务成功或者失败的后续)
如图3.6.18,CONDITION可以指定上一个控件的运行状态,当成功时进行某些操作,当失败时,进行另外的操作;

图3.6.18 CONDITION使用
以上就是DolphinScheduler的控件介绍,可能目前还不是很完善吧,如一些中止控件,邮件控件呀等还是暂缺,但是基本的大数据控件都有了,不足的地方就只能自己写shell脚本了,愿DolphinScheduler越来越好。
3.6.7 参数设置
DolphinScheduler 支持代码中自定义变量名,声明方式:${变量名}。可以是引用 "系统参数" 或指定 "常量"。我们定义这种基准变量为 [...] 格式的,[yyyyMMddHHmmss] 是可以任意分解组合的,比如:[yyyyMMdd],[yyyyMMdd], [yyyyMMdd],[HHmmss], $[yyyy-MM-dd] 等也可以使用以下格式:
后 N 年:$[add_months(yyyyMMdd,12*N)]前 N 年:$[add_months(yyyyMMdd,-12*N)]后 N 月:$[add_months(yyyyMMdd,N)]前 N 月:$[add_months(yyyyMMdd,-N)]后 N 周:$[yyyyMMdd+7*N]前 N 周:$[yyyyMMdd-7*N]后 N 天:$[yyyyMMdd+N]前 N 天:$[yyyyMMdd-N]后 N 小时:$[HHmmss+N/24]前 N 小时:$[HHmmss-N/24]后 N 分钟:$[HHmmss+N/24/60]前 N 分钟:$[HHmmss-N/24/60]
同时还支持系统参数
表3.6.1 时间系统参数
| 变量 | 含义 |
|---|---|
| ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 |
参数使用如图3.6.19 ;

图3.6.19 参数使用
参数使用输出日志如图3.6.20;

图3.6.20参数使用
3.7 首页
首页就是可以查看某一段时间内的项目运行各大状态的统计结果,做的界面也非常的帅,如图3.7.1,注意这里的首页展示的是所有项目的状态统计,而项目首页展示的是单纯这个项目运行状态统计,虽然界面相似,内容还是略有不同的。
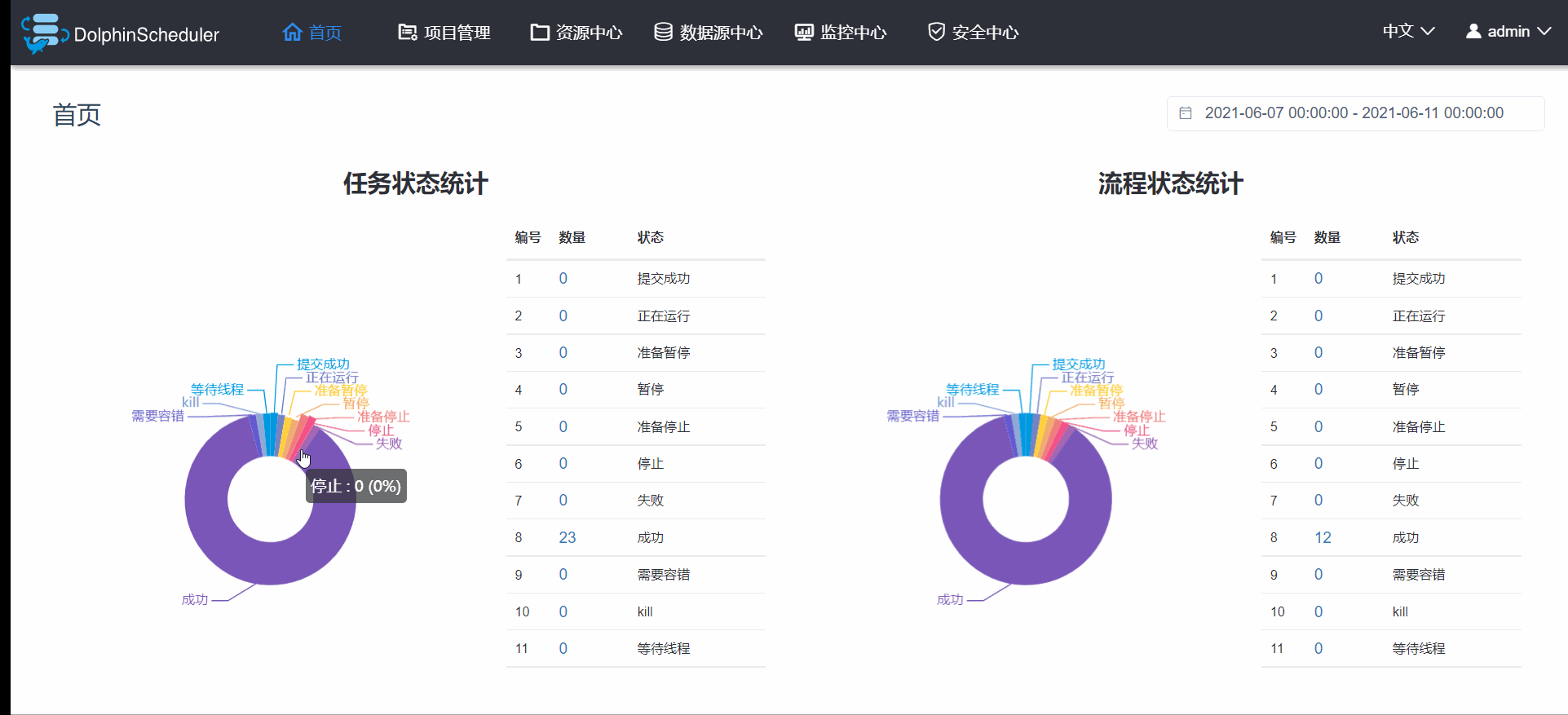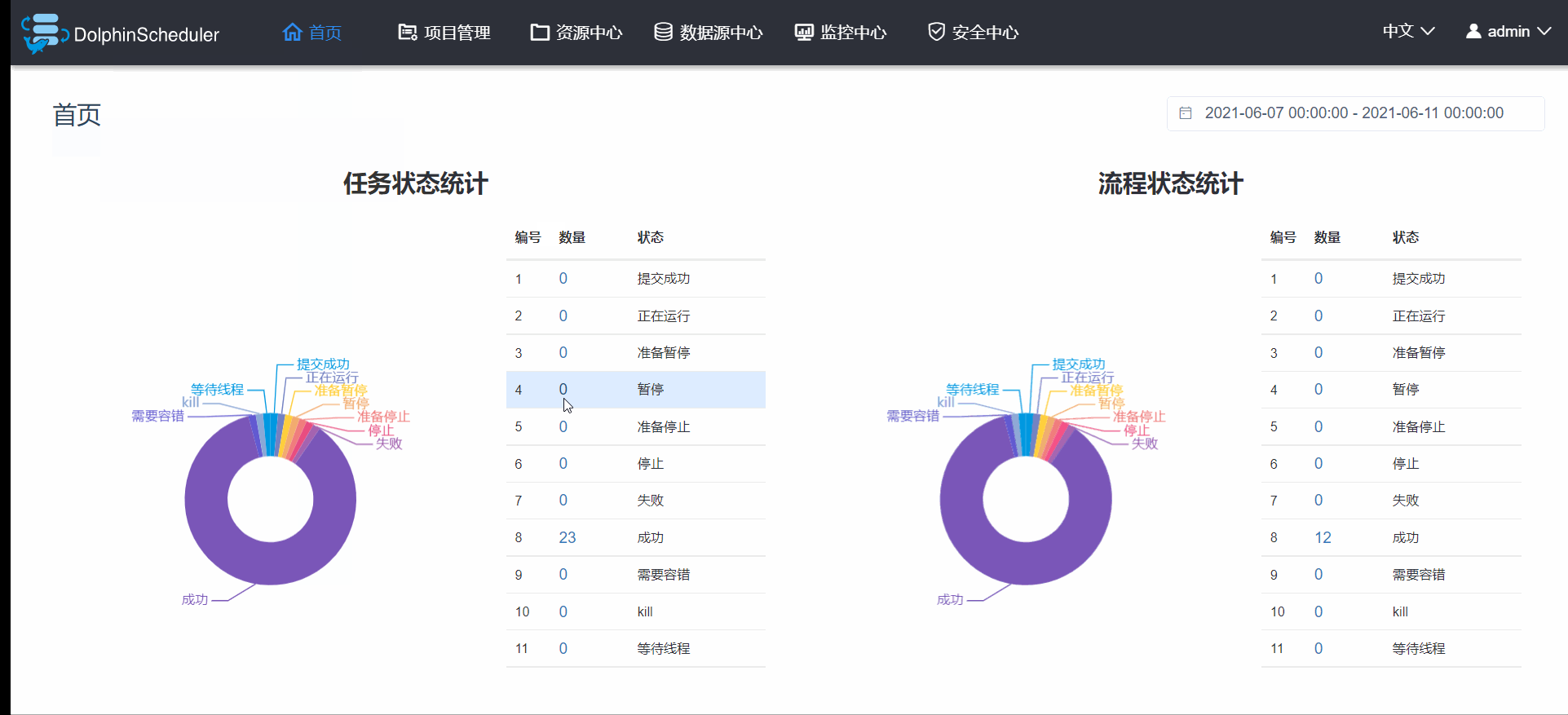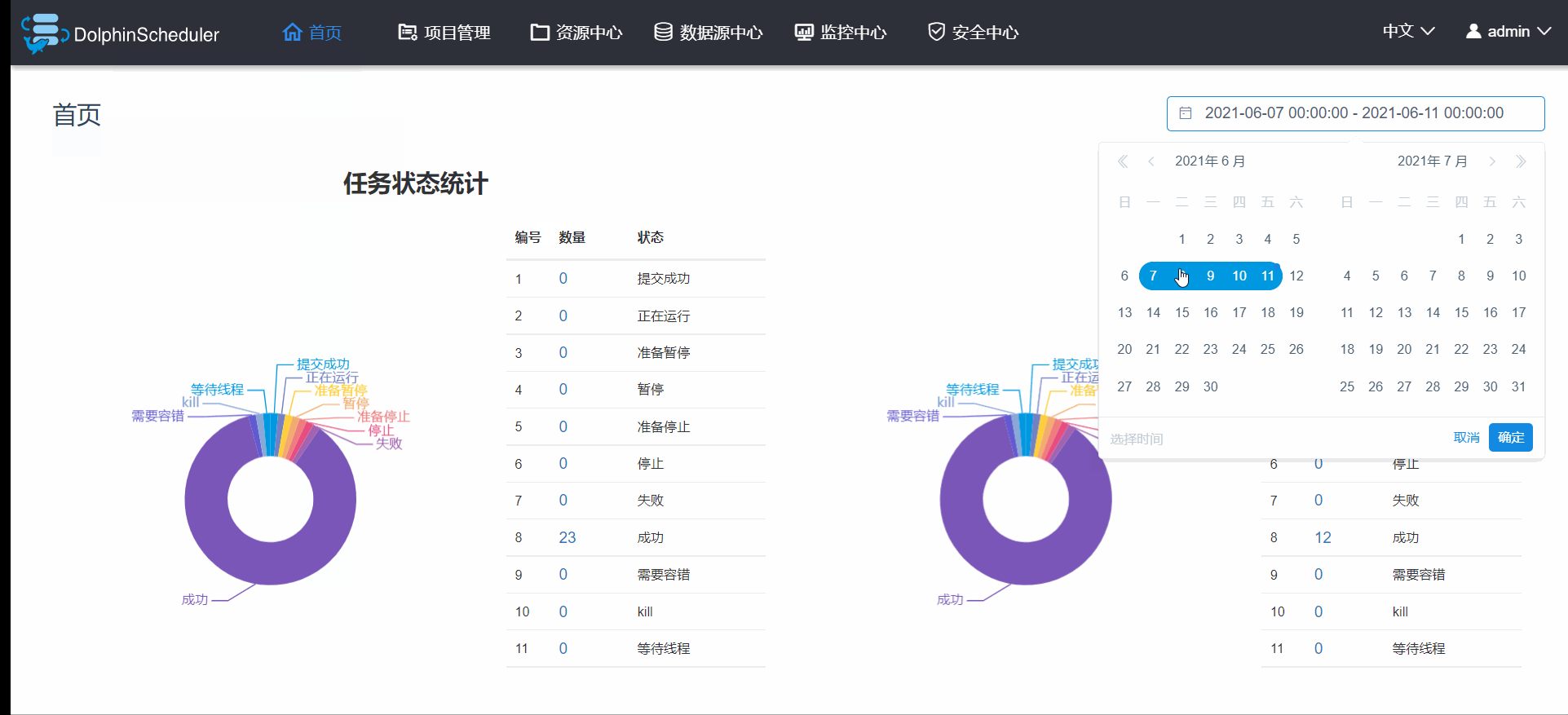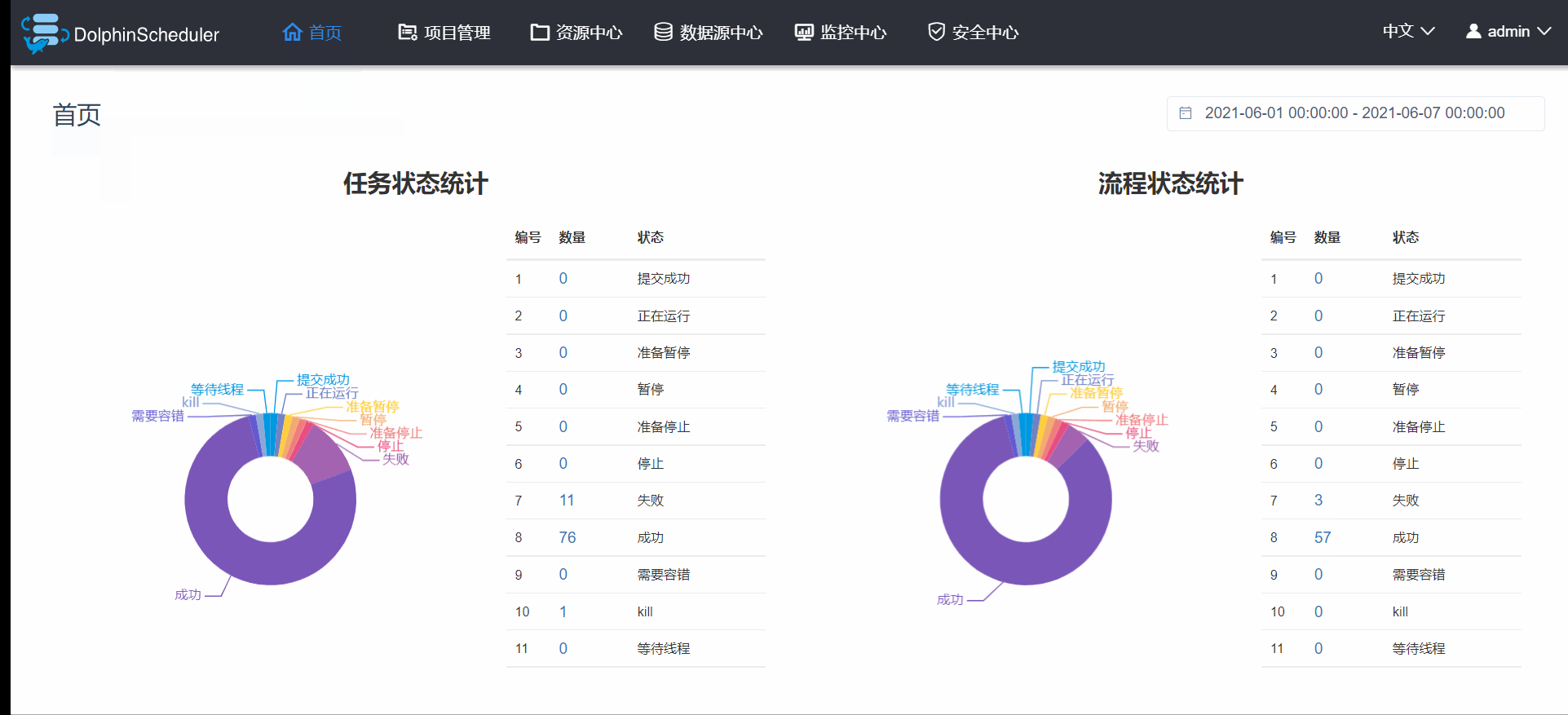
图3.7.1 首页预览
4. API调用
在Web UI上对应的每个操作,基本上后台都对应一个有参或者无参的api接口,当你写程序来控制DolphinScheduler时,就需要用到这些api的调用,比如,除了手动运行工作流,定时调度工作流,是否可以消息通知工作流该运行呢,答案当然是可以的,当你消费某一条特定的kafka消息时,再去运行指定的工作流即可,这个就需要api调用嵌入你的程序里面; 再比如,之前的项目新建,管理都是手工进行的,那么通过开发CICD自动化部署的程序,嵌入api,也是可以完全自动化部署到DolphinScheduler的;
api有个网页,是跟着你部署的MasterServer走的,如博主的;
http://10.192.168.20:9090/dolphinscheduler/doc.html?language=zh_CN&lang=cnhttp://10.192.168.21:9090/dolphinscheduler/doc.html?language=zh_CN&lang=cn
如图4.1,DolphinScheduler的网页api讲解和预览也是做的非常好,且自带postman的功能,让你在线调试,还是非常方便的,至于将api嵌入代码,这里博主就不作讲解了,有兴趣的可以参考博主的python栏博客,有讲解如何使用python调用api,其实也非常简单。

图4.1 api网页调试
5. 元数据表选讲
表5.1 元数据表
| 表名 | 表信息 |
|---|---|
| t_ds_access_token | 访问ds后端的token |
| t_ds_alert | 告警信息 |
| t_ds_alertgroup | 告警组 |
| t_ds_command | 执行命令 |
| t_ds_datasource | 数据源 |
| t_ds_error_command | 错误命令 |
| t_ds_process_definition | 流程定义 |
| t_ds_process_instance | 流程实例 |
| t_ds_project | 项目 |
| t_ds_queue | 队列 |
| t_ds_relation_datasource_user | 用户关联数据源 |
| t_ds_relation_process_instance | 子流程 |
| t_ds_relation_project_user | 用户关联项目 |
| t_ds_relation_resources_user | 用户关联资源 |
| t_ds_relation_udfs_user | 用户关联UDF函数 |
| t_ds_relation_user_alertgroup | 用户关联告警组 |
| t_ds_resources | 资源文件 |
| t_ds_schedules | 流程定时调度 |
| t_ds_session | 用户登录的session |
| t_ds_task_instance | 任务实例 |
| t_ds_tenant | 租户 |
| t_ds_udfs | UDF资源 |
| t_ds_user | 用户 |
| t_ds_version | ds版本信息 |
| 如表5.1,数据元数据表可以让你更好的把握DolphinScheduler的后台数据,可以参考官网元数据文档;熟悉后你也可以自己写一些sql语句来分析DolphinScheduler任务运行状况等,注意如果不是对源码十分熟悉,千万不要想当然的修改元数据表内数据,查询可以,否则容易造成系统崩溃,使用异常。 |
sql
复制代码
-- 查看所有项目的运行情况任务运行状况 select p.id as '项目id' ,p.name as '项目名称' ,p.description as '项目描述' ,d.id as '工作流id' ,d.name as '工作流名称' ,ti.name as '任务名称' ,case ti.state when 0 then '提交成功' when 1 then '正在运行' when 2 then '准备暂停' when 3 then '暂停' when 4 then '准备停止' when 5 then '停止' when 6 then '失败' when 7 then '成功' when 8 then '需要容错' when 9 then 'kill' when 10 then '等待线程' when 11 then '等待依赖完成' else '' end as '任务状态' ,ti.start_time as '任务开始时间' ,ti.end_time as '任务结束时间' from dolphinscheduler.t_ds_task_instance ti inner join dolphinscheduler.t_ds_process_definition d on ti.process_definition_id=d.id inner join dolphinscheduler.t_ds_project p on d.project_id=p.id -- where
查询结果如图5.2。

图5.2 查询结果
6. 扩容/缩容与升级
扩容,缩容、升级这些可能在实际运用中比较少用到,但是博主是想让大家知道,DolphinScheduler本身是支持这些操作的,这些操作之前需要你对DolphinScheduler的安装和实践有较熟悉的理解,然后建议在测试环境尝试一遍就可以在生产环境干起来了,这一块可以参考官网的扩容./缩容和升级,总之先熟练操作,这些步骤能不作就不作,避免不必要的意外吧,此外多关注DolphinScheduler的活动和更新,如果有新版本的功能模块你感兴趣,还是可以升级下的,愿大家的努力使得DolphinScheduler越来越好。
7. 其它
更多操作可以参考官网文档,或者留言博主,博主将第一时间答复您们。
作者:若隐_RowYet_大数据
链接:https://juejin.cn/post/7086854492016082980
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。