在 NLP (Natural Language Processing, 自然语言处理) 领域,ChatGPT 和其他的聊天机器人应用引起了极大的关注。每个社区为构建自己的应用,也都在持续地寻求强大、可靠的开源模型。自 Vaswani 等人于 2017 年首次提出 Attention Is All You Need 之后,基于 transformer 的强大的模型一直在不断地涌现,它们在 NLP 相关任务上的表现远远超过基于 RNN (Recurrent Neural Networks, 递归神经网络) 的 SoTA 模型,甚至多数认为 RNN 已死。而本文将介绍一个集 RNN 和 transformer 两者的优势于一身的全新网络架构——RWKV!现已在 HuggingFace transformers 库中支持。
RWKV 项目概览
RWKV 项目已经启动,由 Bo Peng 主导、贡献和维护。同时项目成员在官方 Discord 也开设了不同主题的讨论频道: 如性能 (RWKV.cpp、量化等),扩展性 (数据集收集和处理),相关研究 (chat 微调、多模态微调等)。该项目中训练 RWKV 模型所需的 GPU 资源由 Stability AI 提供。
读者可以加入 官方 discord 频道 了解详情或者参与讨论。如想了解 RWKV 背后的思想,可以参考这两篇博文:
https://johanwind.github.io/2023/03/23/rwkv_overview.html
https://johanwind.github.io/2023/03/23/rwkv_details.html
Transformer 与 RNN 架构对比
RNN 架构是最早广泛用于处理序列数据的神经网络架构之一。与接收固定输入尺寸的经典架构不同,RNN 接收当前时刻的 “token”(即数据流中的当前数据点) 和先前时刻的 “状态” 作为输入,通过网络预测输出下一时刻的 “token” 和 “状态”,同时输出的 “状态” 还能继续用到后续的预测中去,一直到序列末尾。RNN 还可以用于不同的 “模式”,适用于多种不同的场景。参考 Andrej Karpathy 的博客,RNN 可以用于: 一对一 (图像分类),一对多 (图像描述),多对一 (序列分类),多对多 (序列生成),等等。

由于 RNN 在计算每一时刻的预测值时使用的都是同一组网络权重,因此 RNN 很难解决长距离序列信息的记忆问题,这一定程度上也是训练过程中梯度消失导致的。为解决这个问题,相继有新的网络架构被提出,如 LSTM 或者 GRU,其中 transformer 是已被证实最有效的架构。
在 transformer 架构中,不同时刻的输入 token 可以在 self-attention 模块中并行处理。首先 token 经过 Q、K、V 权重矩阵做线性变换投影到不同的空间,得到的 Q、K 矩阵用于计算注意力分数 (通过 softmax,如下图所示),然后乘以 V 的隐状态得到最终的隐状态,这种架构设计可以有效缓解长距离序列问题,同时具有比 RNN 更快的训练和推理速度。


在训练过程中,Transformer 架构相比于传统的 RNN 和 CNN 有多个优势,最突出的优势是它能够学到上下文特征表达。不同于每次仅处理输入序列中一个 token 的 RNN 和 CNN,transformer 可以单次处理整个输入序列,这种特性也使得 transformer 可以很好地应对长距离序列 token 依赖问题,因此 transformer 在语言翻译和问答等多种任务中表现非常亮眼。
在推理过程中,RNN 架构在推理速度和内存效率方面会具有一些优势。例如计算简单 (只需矩阵 - 向量运算) 、内存友好 (内存不会随着推理阶段的进行而增加),速度稳定 (与上下文窗口长度一致,因为 RNN 只关注当前时刻的 token 和状态)。
RWKV 架构
RWKV 的灵感来自于 Apple 公司的 Attention Free Transformer。RWKV 该架构经过精心简化和优化,可以转换为 RNN。除此此外,为使 RWKV 性能媲美 GPT,还额外使用了许多技巧,例如 TokenShift 和 SmallInitEmb (使用的完整技巧列表在 官方 GitHub 仓库的 README 中 说明)。对于 RWKV 的训练,现有的项目仓库可以将参数量扩展到 14B,并且迭代修了 RWKV-4 的一些训练问题,例如数值不稳定性等。
RWKV 是 RNN 和 Transformer 的强强联合
如何把 transformer 和 RNN 优势结合起来?基于 transformer 的模型的主要缺点是,在接收超出上下文长度预设值的输入时,推理结果可能会出现潜在的风险,因为注意力分数是针对训练时的预设值来同时计算整个序列的。
RNN 本身支持非常长的上下文长度。即使在训练时接收的上下文长度有限,RNN 也可以通过精心的编码,来得到数百万长度的推理结果。目前,RWKV 模型使用上下文长度上为 8192 ( ctx8192) 和 ctx1024 时的训练速度和内存需求均相同。
传统 RNN 模型的主要缺陷,以及 RWKV 是如何避免的:
传统的 RNN 模型无法利用很长距离的上下文信息 (LSTM 用作语言模型时也只能有效处理约 100 个 token),而 RWKV 可以处理数千个甚至更多的 token,如下图所示:

传统的 RNN 模型无法并行训练,而 RWKV 更像一个 “线性 GPT”,因此比 GPT 训练得更快。
通过将这两个优势强强联合,希望 RWKV 可以实现 “1 + 1 > 2” 的效果。
RWKV 注意力公式
RWKV 模型架构与经典的 transformer 模型架构非常相似 (例如也包含 embedding 层、Layer Normalization、用于预测下一 token 的因果语言模型头、以及多个完全相同的网络层等),唯一的区别在于注意力层,它与传统的 transformer 模型架构完全不同,因此 RWKV 的注意力计算公式也不一样。
本文不会对注意力层过多的介绍,这里推荐一篇 Johan Sokrates Wind 的博文,里面有对注意力层的分数计算公式等更全面的解释。
现有检查点
纯语言模型: RWKV-4 模型
大多数采用 RWKV 架构的语言模型参数量范围从 170M 到 14B 不等。据 RWKV 概述博文 介绍,这些模型已经在 Pile 数据集上完成训练,并进行了多项不同的基准测试,取得了与其他 SoTA 模型表现相当的性能结果。

指令微调/Chat 版: RWKV-4 Raven
Bo 还训练了 RWKV 架构的 “chat” 版本: RWKV-4 Raven 模型。RWKV-4 Raven 是一个在 Pile 数据集上预训练的模型,并在 ALPACA、CodeAlpaca、Guanaco、GPT4All、ShareGPT 等上进行了微调。RWKV-4 Raven 模型有多个版本,如不同语言 (仅英文、英文 + 中文 + 日文、英文 + 日文等) 和不同大小 (1.5B 参数、7B 参数、14B 参数) 等。
所有 HF 版的模型都可以在 Hugging Face Hub 的 RWKV 社区主页 找到。
集成 🤗 Transformers 库
感谢这个 Pull Request 的贡献,RWKV 架构现已集成到 🤗 transformers 库中。在作者撰写本文之时,您已经可以通过从源代码安装 transformers 库,或者使用其 main 分支。RWKV 架构也会与 transformers 库一起更新,您可以像使用任何其他架构一样使用它。
下面让我们来看一些使用示例。
文本生成示例
要在给定 prompt 的情况下生成文本,您可以使用 pipeline:
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were'}]或者可以运行下面的代码片段:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were使用 Raven 模型 (chat 模型) 示例
您可以以 alpaca 风格使用提示 chat 版模型,示例如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "Tell me about ravens"
prompt = f"### Instruction: {question}\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Instruction: Tell me about ravens
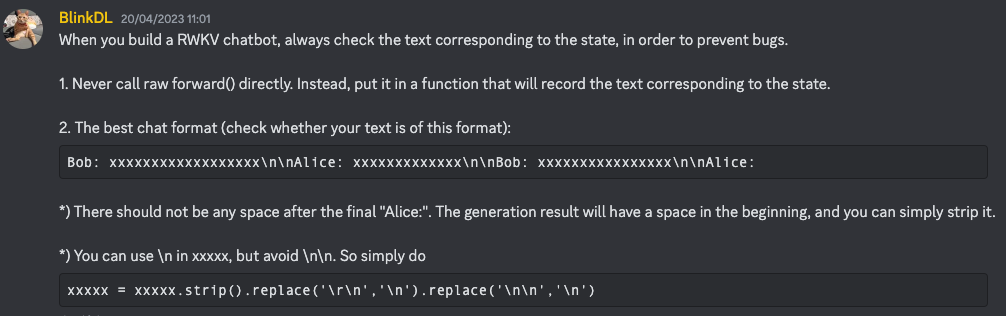
### Response: RAVENS are a type of bird that is native to the Middle East and North Africa. They are known for their intelligence, adaptability, and their ability to live in a variety of environments. RAVENS are known for their intelligence, adaptability, and their ability to live in a variety of environments. They are known for their intelligence, adaptability, and their ability to live in a variety of environments.据 Bo 所述,这条 discord 消息 (访问超链接时请确保已加入 discord 频道) 中有更详细的书写指令技巧。
权重转换
任何用户都可以使用 transformers 库中提供的转换脚本轻松地将原始 RWKV 模型权重转换为 HF 格式。具体步骤为: 首先,将 “原始” 权重 push 到 Hugging Face Hub (假定目标仓库为 RAW_HUB_REPO,目标权重文件为 RAW_FILE),然后运行以下转换脚本:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR如果您想将转换后的模型 push 到 Hub 上 (假定推送目录为 dummy_user/converted-rwkv),首先请确保在 push 模型之前使用 huggingface-cli login 登录 HF 账号,然后运行:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv未来工作
多语言 RWKV
Bo 目前正在研究在多语言语料库上训练 RWKV 模型,最近发布了一个新的 多语言分词器。
社区后续研究方向
RWKV 社区非常活跃,致力于几个后续研究方向。项目清单可以在 RWKV 的 discord 专用频道中找到 (访问超链接时请确保已加入 discord 频道)。欢迎加入这个 RWKV 研究频道,以及对 RWKV 的积极贡献!
模型压缩与加速
由于只需要矩阵 - 向量运算,对于非标准化和实验性的计算硬件,RWKV 是一个非常理想的架构选择,例如光子处理器/加速器。
因此自然地,RWKV 架构也可以使用经典的加速和压缩技术 (如 ONNX、4 位/8 位量化等)。我们希望集成了 transformer 的 RWKV 架构能够使更多开发者和从业者受益。
在不久的将来,RWKV 还可以使用 optimum 库提出的加速技术。rwkv.cpp 或 rwkv-cpp-cuda 仓库涉及的其中一些技术在库中已标明。
致谢
我们 Hugging Face 团队非常感谢 Bo 和 RWKV 社区抽出宝贵时间来回答关于架构的问题,以及非常感谢他们的帮助和支持。我们很期待在 HF 生态中看到更多 RWKV 模型的应用。我们还要感谢 Johan Wind 发布的关于 RWKV 的博文,这对我们理解架构本身和其潜力有很大帮助。最后,我们着重感谢 ArEnSc 开启 RWKV 集成到 transformers 库的 PR 所做的工作,以及感谢 Merve Noyan、Maria Khalusova 和 Pedro Cuenca 审阅和校对本篇文章!
引用
如果您希望在工作中使用 RWKV,请使用此 cff 引用。https://github.com/BlinkDL/RWKV-LM/blob/main/CITATION.cff
英文原文: https://hf.co/blog/rwkv
作者: BlinkDL, Harrison Vanderbyl, Sylvain Gugger, Younes Belkada
译者: SuSung-boy
审校/排版: zhongdongy (阿东)