目录
背景
Unicode
UTF-8
ISO-8859-1
GB2312和GBK
ANSI
UTF-16LE 和UTF-16BE
UTF-16
LE 和BE是什么
如何处理字节序问题
"带有BOM的UTF-8"又是什么?
背景
由于计算机是美国人发明的,因此最早只有127个字母被编码到计算机中,也就是大小写英文字母、数字和一些符号,这个编码表称为ASCII编码。
例如:大写字母A的编码是65,小写字母z的编码时122。
要处理中文,显然一个字节是不够的,至少需要两个字节,且不能和ASCII编码冲突,所以我国制定了GB2312编码,用于把中文编进去。
可以想象,全世界上有上百种语言,日本把日文编写到Shift_JIS里,韩国把韩文编写到Euc-kr里,各国有各国的标准,就不可避免出现冲突,结果就是,在多语言混合的文本中就会显示乱码。
在此背景下,Unicode应运而生,Unicode把所有语言都统一到一套编码里,这样就不会有乱码问题了。
Unicode
Unicode标准在不断发展,最常用的是用两个字节表示一个字符(如果要用到非常生僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
下面看看ASCII编码和Unicode编码的区别:ASCII编码时1个字节,二Unicode编码通常是两个字节。
字母A用ASCII编码是十进制的65,二进制的01000001。
字符0用ASCII编码是十进制的48,二进制的00110000。
注意字符0和整数0是不同的。
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可,因此A的Unicode编码是00000000 01000001。
那么新的问题就出现了:如果统一成Unicode编码,乱码问题从此消失了,但是写的文本基本上全部是英文时,用Unicode编码比ASCII编码多一倍存储空间,在存储和传输上十分不划算。
UTF-8
本着节约的精神,又出现了把Unicode编码转化成为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1~6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4~6个字节。如果你要传输的文本包含大量英文字母,用UTF-8编码就会节省空间。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可看成是UTF-8编码的一部分,所以只支持ASCII编码的大量历史遗留软件可在UTF-8编码下继续使用。
搞清楚ASCII、Unicode和UTF-8的关系后,可总结一下现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保持到硬盘或需要传输时,可转换为UTF-8编码。
例如,用记事本编辑时,从文件读取的UTF-8字符转换为Unicode字符到内存;编辑完成后,保持时再把Unicode转换为UTF-8保持到文件。
ISO-8859-1
首先发难的是欧美拉丁系国家,他们发现ASCII编码只用了从0000 0000(二进制)到0111 1111(二进制)128种符号,浪费啊浪费。他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集",也就是Latin-1字符集,即ISO-8859-1。
iso-8859-1最多能表示的字符范围是0-255(编码范围是0x00-0xFF),其中0x00-0x7F之间完全和ASCII一致(ASCII是7位编码,能个表示128个字符),因此向下兼容ASCII,
由于ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO 8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,所以很多情况下(如很多协议传输数据时)都使用ISO 8859-1编码,由于ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO 8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,所以很多情况下(如很多协议传输数据时)都使用ISO 8859-1编码
比如,虽然“中文”两个字符就不存在ISO 8859-1编码,但可以用iso8859-1编码来“表示”。通过查询下文将要介绍的GB2312编码表,“中文”应该是"d6d0 cec4"两个字符,使用ISO 8859-1编码来“表示”的时候则将它拆开为4个字节来表示,即"d6 d0 ce c4"(事实上,在进行存储的时候,也是以字节为单位处理的)。如果使用Unicode编码,则表示为"4e2d 6587";使用UTF编码,则是6个字节"e4 b8 ad e6 96 87"。很明显,这种使用ISO 8869-1对汉字进行表示的方法还需要以另一种编码为基础。
有些环境下,将ISO 8859-1写作Latin-1。
GB2312和GBK
GB2312是一种用两个字节表示汉字的编码方法。它的全称是“中华人民共和国国家标准简体中文字符集“,由中国国家标准总局发布,1981年5月1日实施。
GBK是对GB2312-80的扩展.由于GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如“啰”),部分人名用字(如中国前总理***的“*”字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。
对于ASCII字符,gbk依然是用一个字符表示的,是兼容的
国家标准GB18030-2005《信息技术 中文编码字符集》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准.GB18030-2005的主要特点是在GB18030-2000*础上增加了CJK统一汉字扩充B的汉字。
ANSI
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、Big5、Shift_JIS 等各自的编码标准。这些使用 1 至 4 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
由此可见,ANSI实际上指什么,有赖于操作系统的语言。这其实可以理解为微软(因为根据引用3所说,只有Windows系统使用ANSI编码)为了适应不同国家的编码方式的不同而想到的方法:在不同国家默认使用不同的编码方法,只是为了显示功能性的统一才起名为ANSI。
UTF-16LE 和UTF-16BE
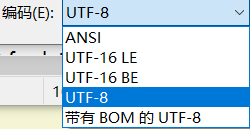
这是记事本中的编码方式,还剩下UTF-16 LE和UTF-16 BE我们没有提到。
UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元, 长度为2 Byte)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
UTF-16的出现时间比UTF-8早,但是相比UTF-8,它有几个显著的缺点:
- 不支持ASCII编码:由UTF-16的定义可以看出来,它的最短长度是16位,也就是2个字节,这就使得它无法兼容ASCII
- 相比UTF-8更费空间
现今UTF-16依然存在于计算机系统中是为了向下兼容,其本身用的已经不太多了(但也有应用,比如在JavaScript中,所有的string类型(或者被称为DOMString)都是使用UTF-16编码的),所以详细的编码方法这里就不说了。
LE 和BE是什么
LE是指低字节序(Little Endian),BE指高字节序(Big Endian),这里涉及到了一个很底层的问题:如果一个字符需要两个字节来表示,那么这两个字节应该怎么存储,是高位在前还是低位在前?这个问题在当初学习汇编语言时就曾给我造成疑惑,但当时的我并不知道这背后的故事。
Endian读作End-ian或者Indian。这个术语的起源可以追溯到格列佛游记。(小说中,小人国为水煮蛋应该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。)
字节序方案只是一个微处理器架构设计者的偏好问题,例如,Intel使用低字节序,Motorola使用高字节序。
以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
可以看到,BE方式和人类读写数值的方式是一致的,那为什么不直接用BE?
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序
我们可以注意到一个问题,上面图中为什么只有UTF-16有字节序问题,为什么ANSI和UTF-8没有字节序问题?不是因为UTF-16特别,是因为Unicode在制定标准的时候,并没有规定字节序,这就给UTF-16和UTF-32这样的以多字节为处理单位的编码方式埋了一个大坑,使得后代许多人都纠结在字节序转换的问题上。而UTF-8是以单字节为*本处理单位的
如何处理字节序问题
有一个很巧妙的约定来解决UTF-16的字节序问题,它叫做BOM(字节顺序标记)。BOM放置在文档的开头,用来告诉阅读器这个文档的字节序是什么。如果是高字节序,就写入FE FF;如果是低字节序,就写入FF FE。
"带有BOM的UTF-8"又是什么?
UTF-8 不需要 BOM,尽管 Unicode 标准允许在 UTF-8 中使用 BOM。
所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下:把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。
微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题。例如UTF-8 的网页代码不应使用 BOM,否则常常会出错。