0 基础知识
-
知识图谱中,知识的结构化表示主要有符号表示和向量表示两类方法。符号表示包括:一阶谓词逻辑,语义网络,描述逻辑和框架系统等。当前主要采用基于图的符号化知识表示,最常用的是有向标记图。
-
有向标记图分为:属性图(property graph)和RDF图(Resource Description Framework,RDF)。
- 属性图:图数据库Neo4j实现的图结构表示模型,工业界最常用的知识图谱建模方法。优点:允许为实体或边添加属性,易于存储和查询。缺点:缺乏工业标准规范的支持,不关注更深层次的语义表达、不支持符号逻辑推理。
- 顶点(vertex)/节点(node)
- 边(edge)/关系(relation):有向边和对应标签
- 标签(label)
- 属性(property):键值对
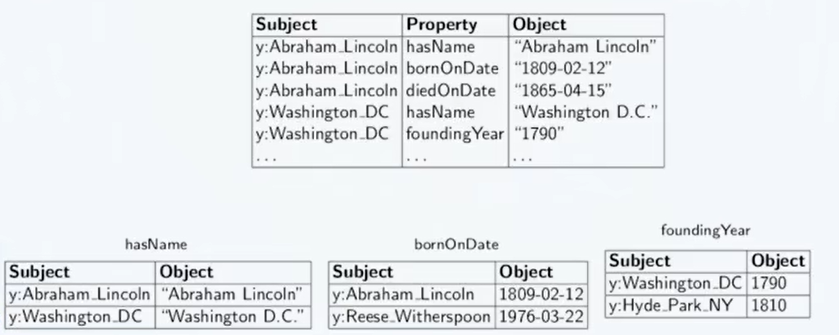
- RDF:W3C推出的语义数据交换标准与规范,支持逻辑推理。RDF的基本组成单元是 (S,P,O)三元组,(Subject主,Predicate谓,Object宾)。
- 在RDF的基础上还提供了RDFS(Resource Description Framework Schema)。定义了Class、subClass、Property、subProperty、domain、range、type…等概念。

- 在RDF的基础上还提供了RDFS(Resource Description Framework Schema)。定义了Class、subClass、Property、subProperty、domain、range、type…等概念。
- 属性图:图数据库Neo4j实现的图结构表示模型,工业界最常用的知识图谱建模方法。优点:允许为实体或边添加属性,易于存储和查询。缺点:缺乏工业标准规范的支持,不关注更深层次的语义表达、不支持符号逻辑推理。
-
OWL(Ontology Web Language): 在RDFS的基础上增加了更多的语义表达构建,如一对多、多对一、多对多等关系,全称量词和存在量词,互反关系、传递关系、自反关系、对称性等。

1 图数据存储
- 知识图谱的存储分为:基于关系数据库的存储和基于原生图的存储。图数据库对于知识图谱并非必须项。
- 考虑存储结构主要考虑:存储的物理结构、存储的性能问题、图的查询问题。
基于关系数据库的存储
- 一般不用这种方式,除非场景非常简单。
- 图上的查询语言:SPARQL。

- 最简单的存储:SPO三元组

- 属性表存储:把同一实体类型的属性组织为一张表进行存储。优点:self-join减少了。缺点:空值多,对Subject聚类比较复杂,不易处理多值属性。


- 二元表存储:对三元组按属性分表。优点:无空值,不用聚类,对subject-subject-join性能好,缺点:insert代价高,subject-object join性能差。
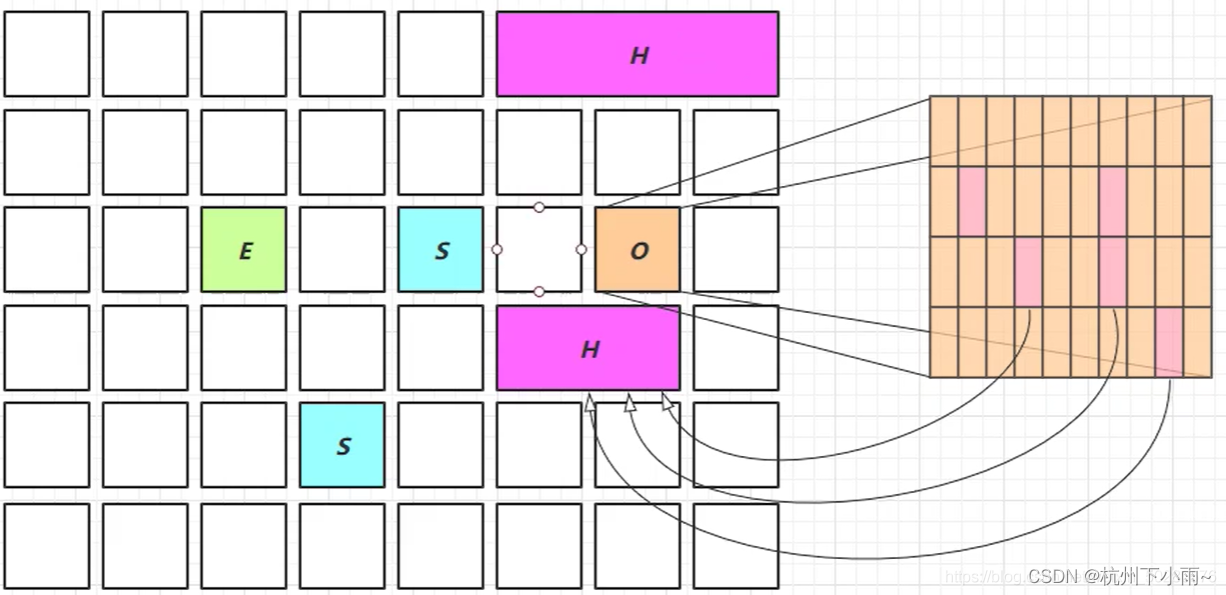
- 全索引结构存储:


基于原生图的存储
- Neo4j 定义了图查询语言:Cypher。
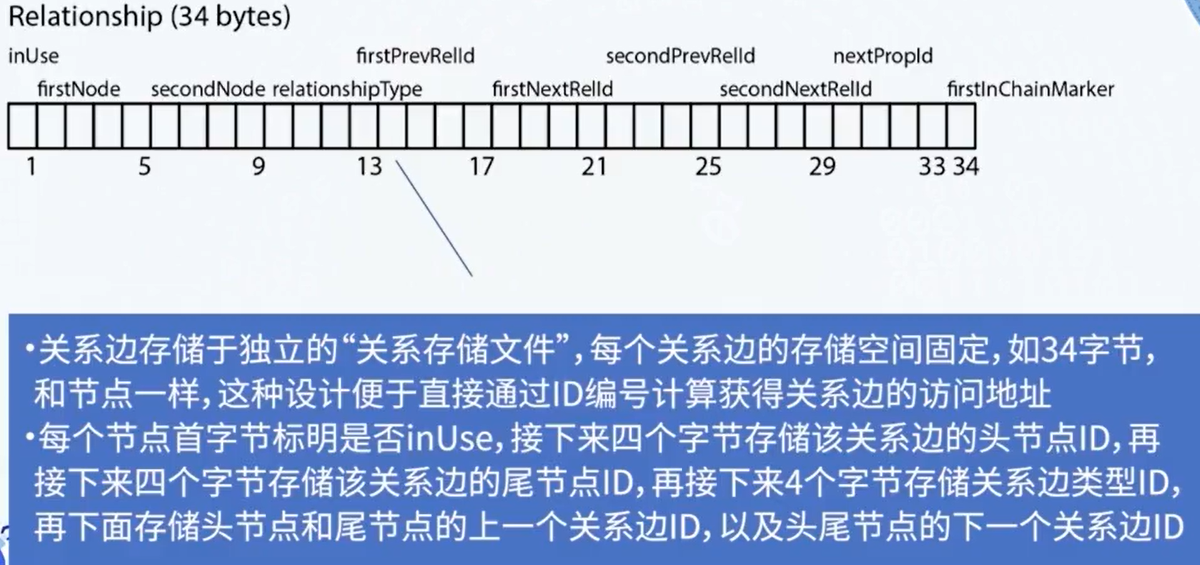
- 实现原理:免索引邻接(index-free adjacency),为每个节点维护了一组指向相邻节点的引用,这个引用可以看作相邻节点的微索引。


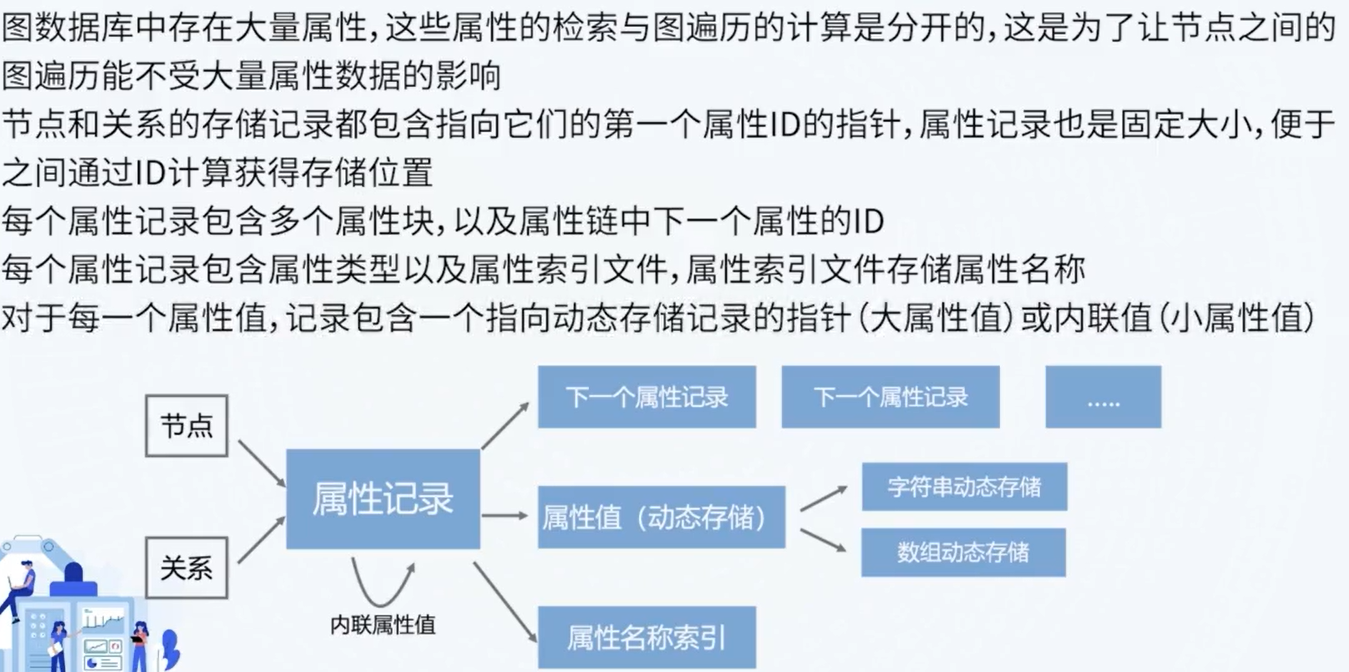
2 知识抽取

- 文本知识抽取:命名实体识别、概念抽取、关系抽取、事件抽取。

命名实体识别
- 最朴素的做法是定义规则进行正则匹配,但规则难以维护。因此一般用AI来进行序列标注。


- 基于机器学习的方法有:HMM、CRF;目前主要研究基于深度学习的序列标注算法,如CNN/RNN/Transformer,如:BiLSTM+CRF,基于预训练模型。


- 参考文献:《A Survey On Deep Learning for Named Entity Recognition》(TKDE2020)
关系抽取与属性补全




- 实体-关系联合抽取



- 多元关系


- 半监督

- 属性补全:


- 参考资料:开源中文关系抽取框架 deepke
概念抽取


事件识别与抽取






知识抽取前沿问题






3 知识图谱推理



基于本体的推理




基于规则的推理







基于embedding的推理




基于规则学习的推理
本章后续略。
4 知识融合

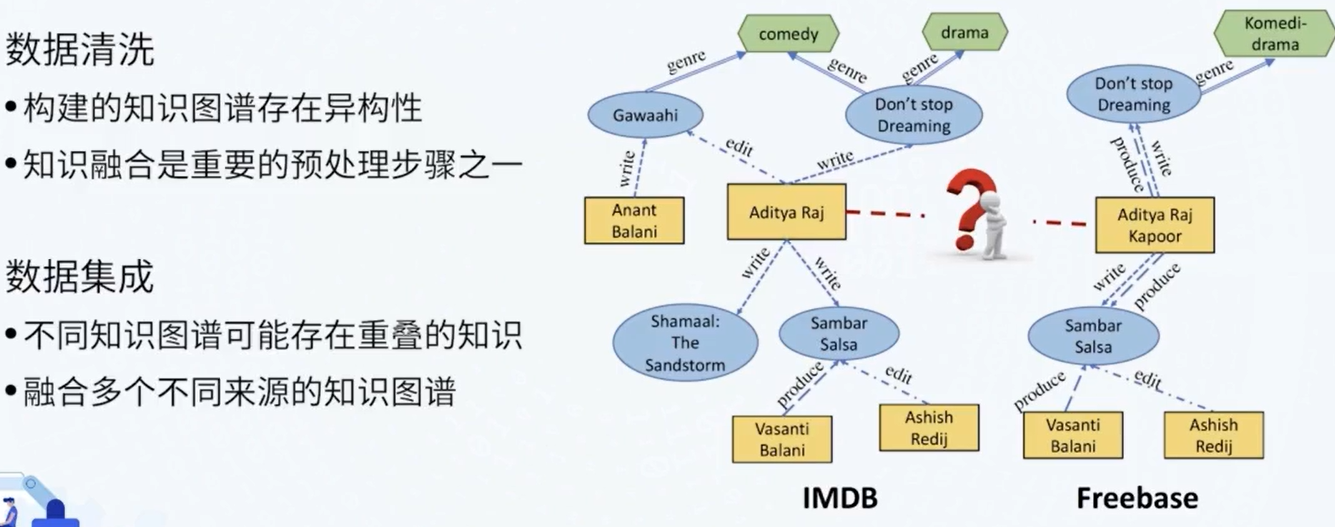


本体匹配


- 距离度量:编辑距离、汉明距离、字串相似度、dice距离、jaccard系数等等;

实体对齐



- 知识融合工具:silk



技术前沿



5 基于知识图谱的智能问答系统







基于查询模板的知识图谱问答
- TBSL















基于语义解析的知识图谱问答
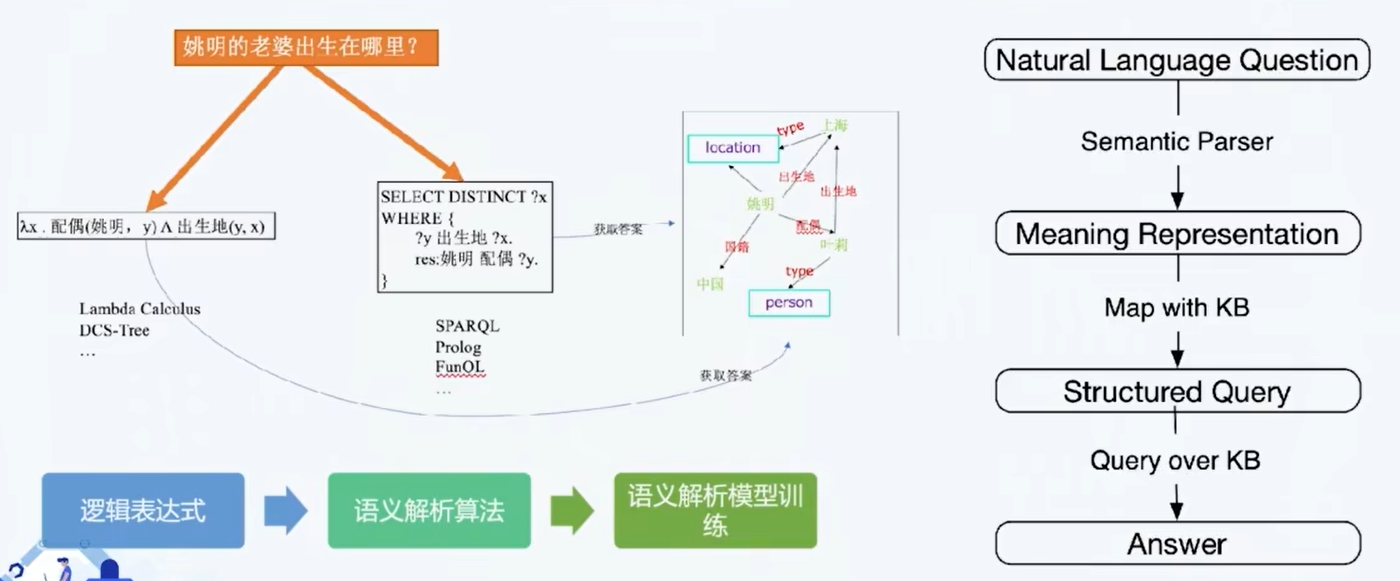
- 一步解析的困难:
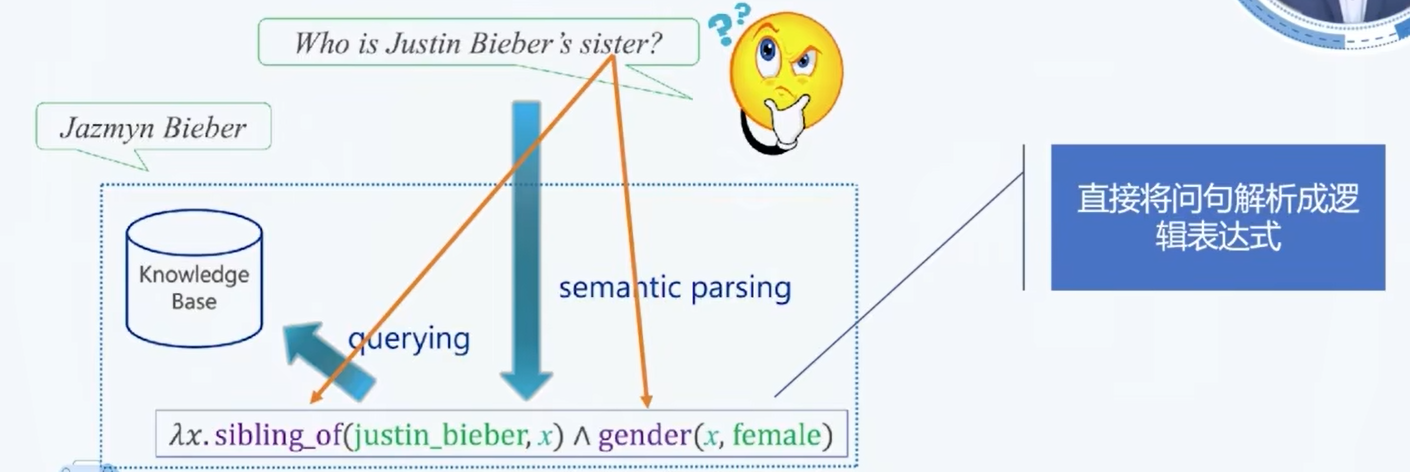
- 更合理的方式是两步解析:
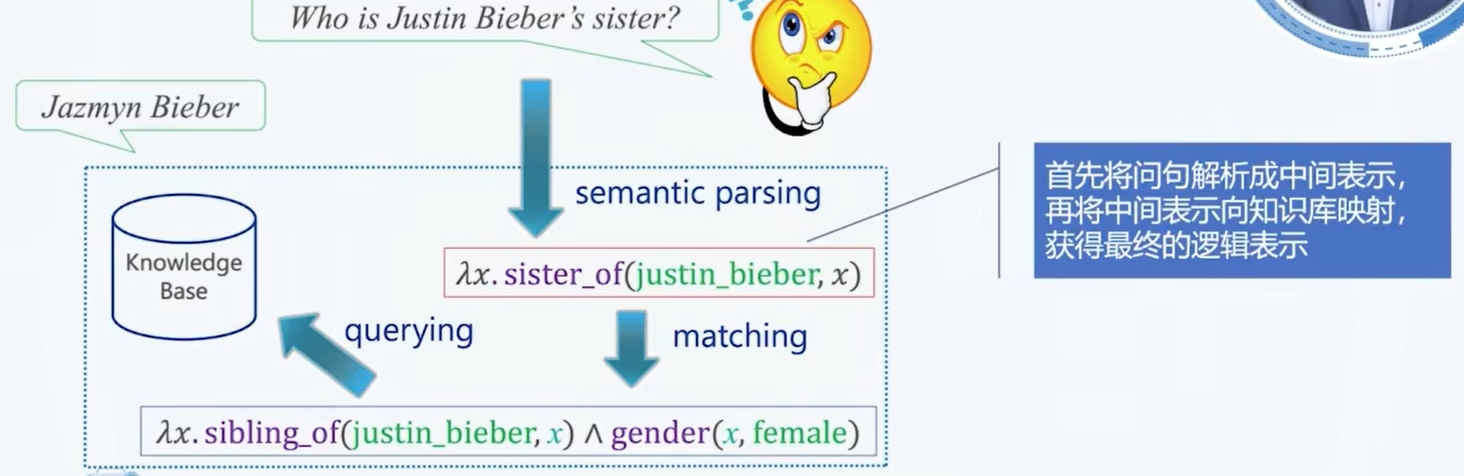






- 短语重写:

基于检索排序的知识图谱问答


- 实体链接







基于深度学习的知识图谱问答








6 图算法与图数据分析
图神经网络与图表示学习
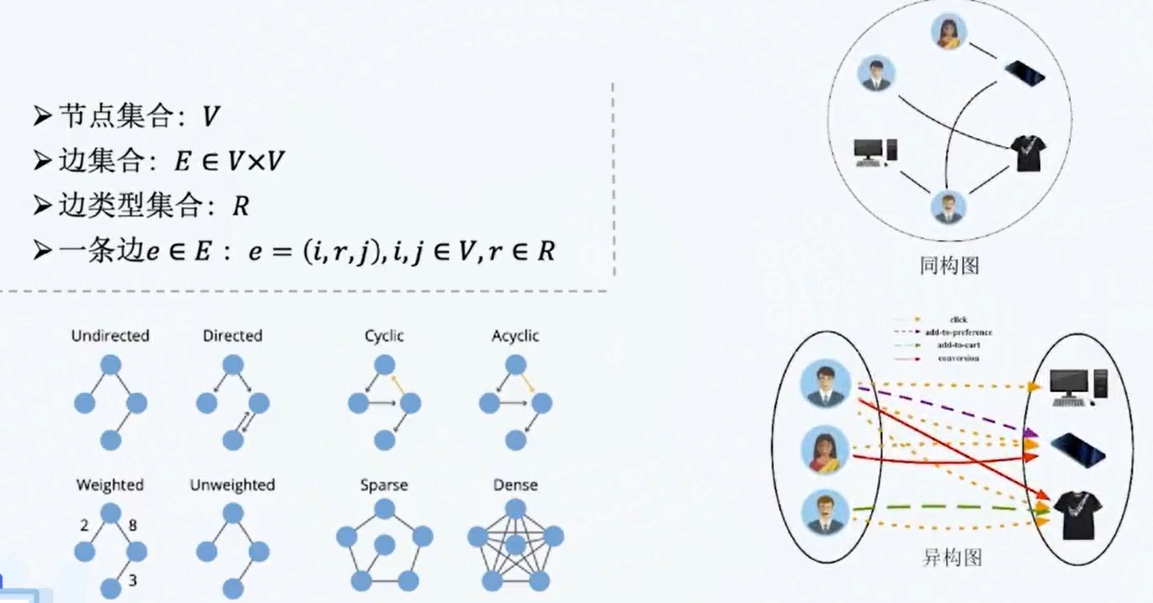









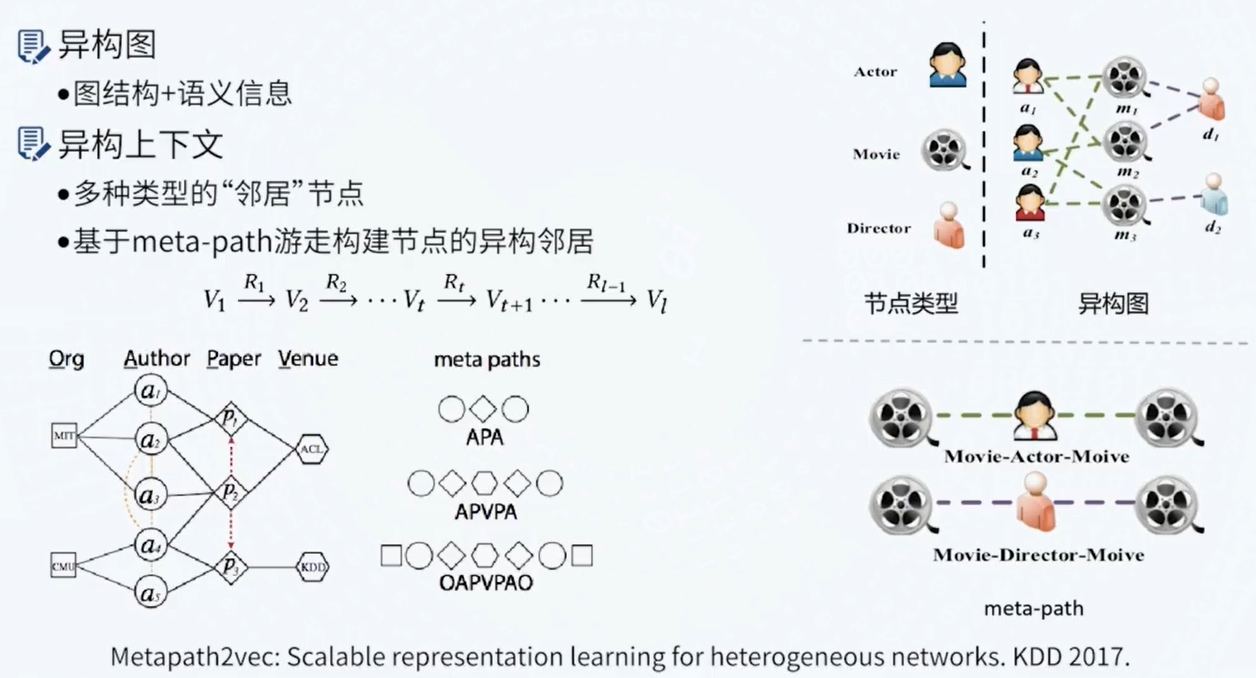













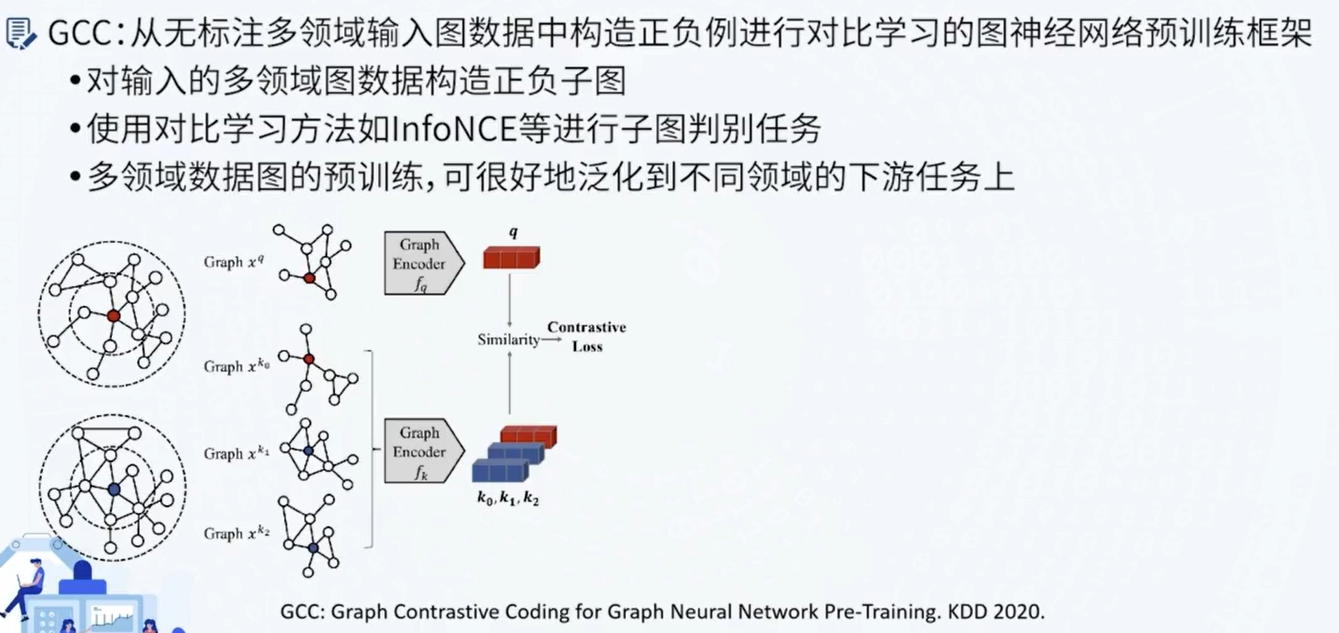

图神经网络与知识图谱







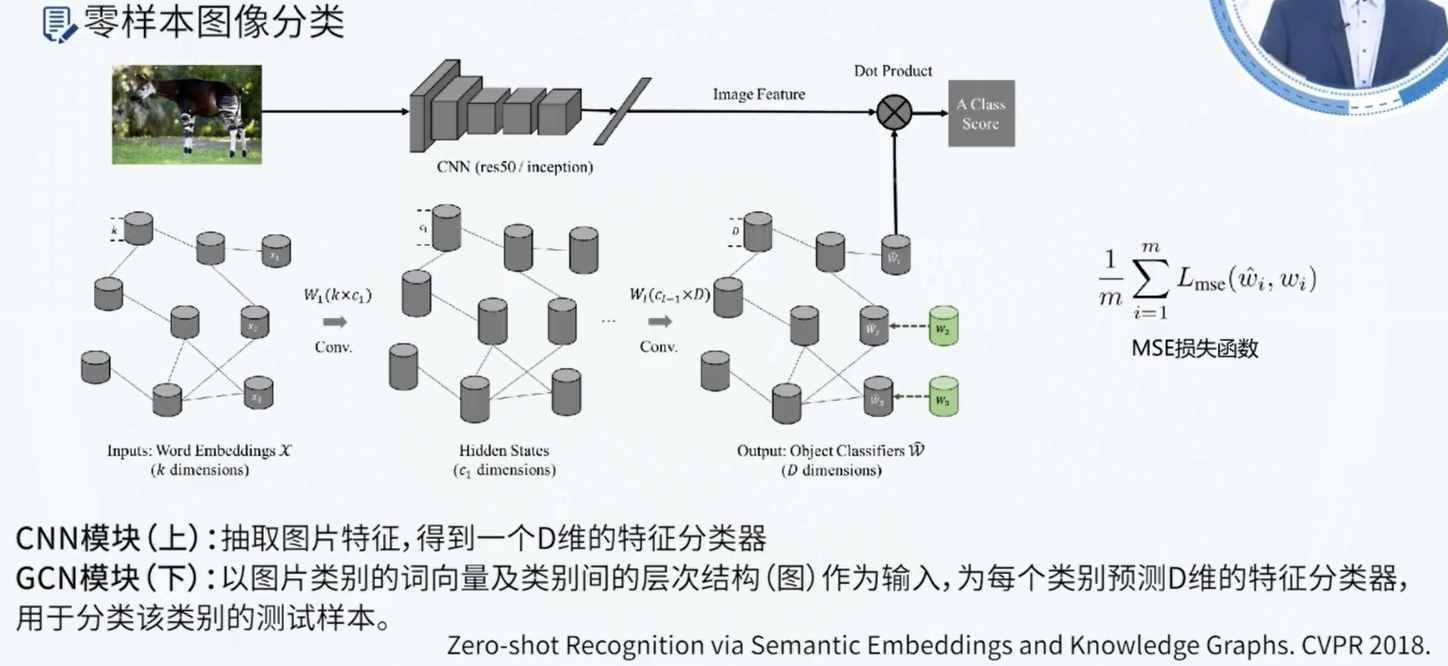


7 知识图谱前沿
多模态知识图谱


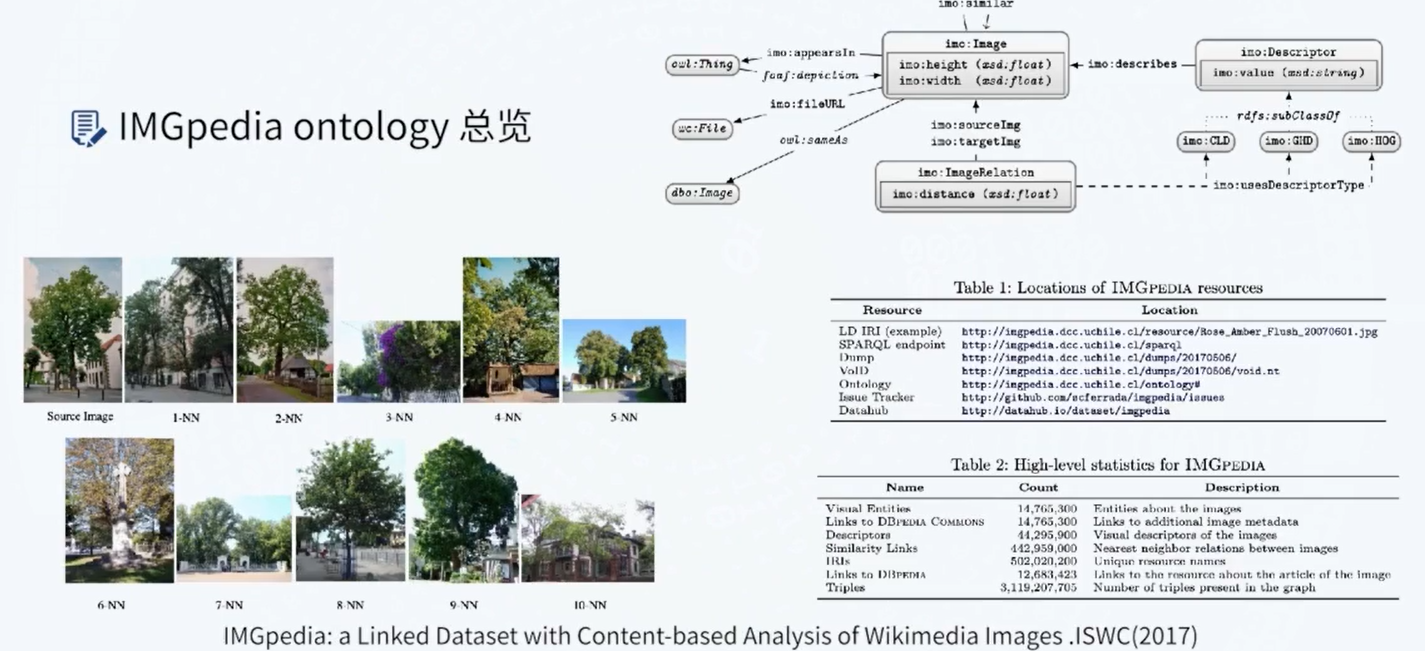




知识图谱与语言预训练







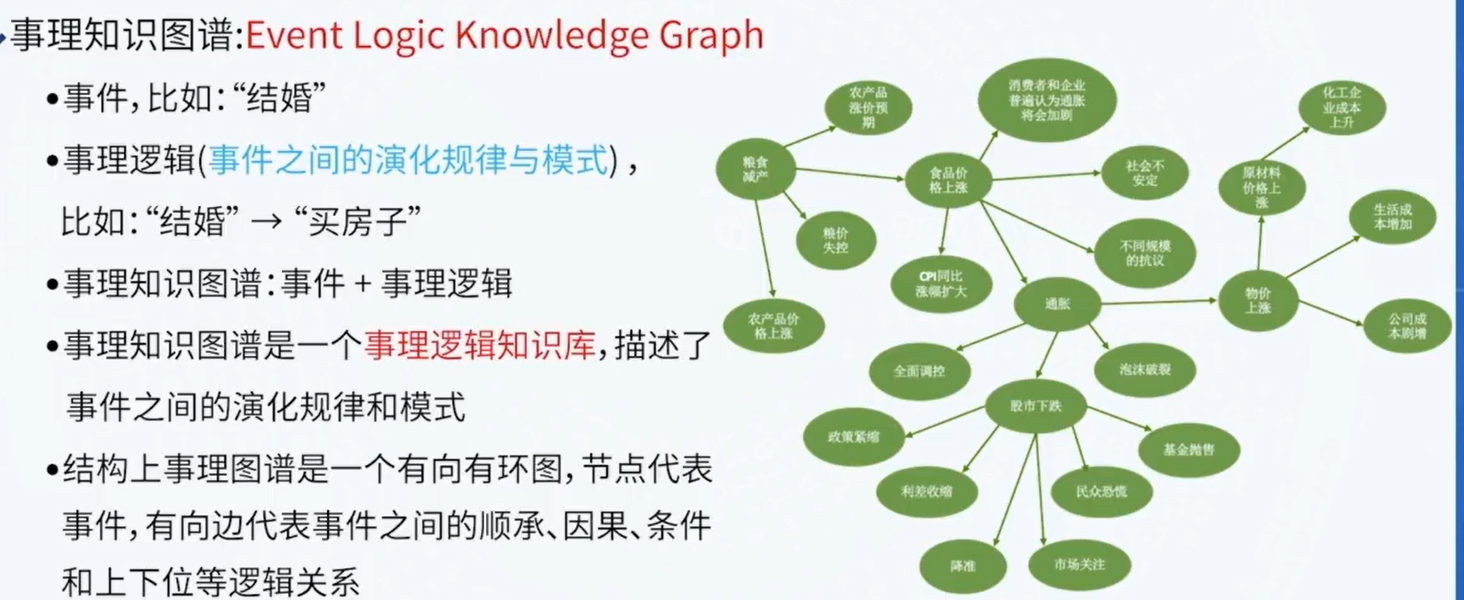
事理知识图谱








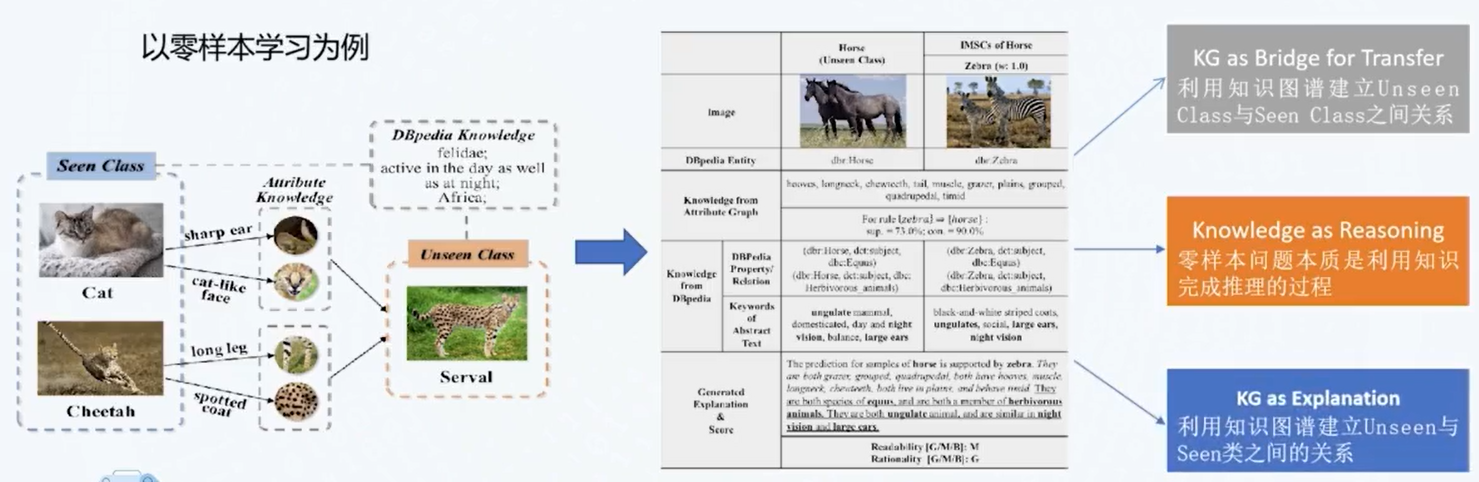
知识图谱与低资源学习









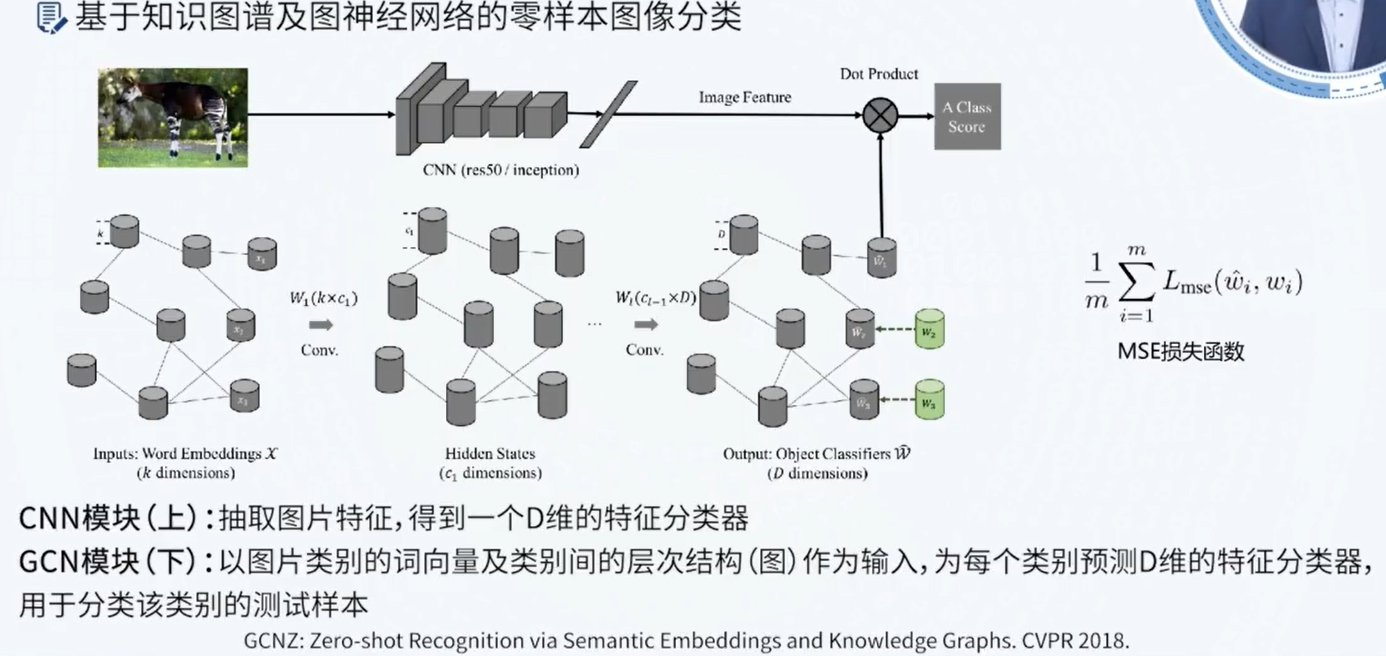
Reference
- 浙大 知识图谱
- 知识图谱:知识表示







![[GXYCTF2019]Ping Ping Ping解题过程](https://img-blog.csdnimg.cn/ea1c791e2c2b4c3e9ca2b4c2c0c1b535.png)