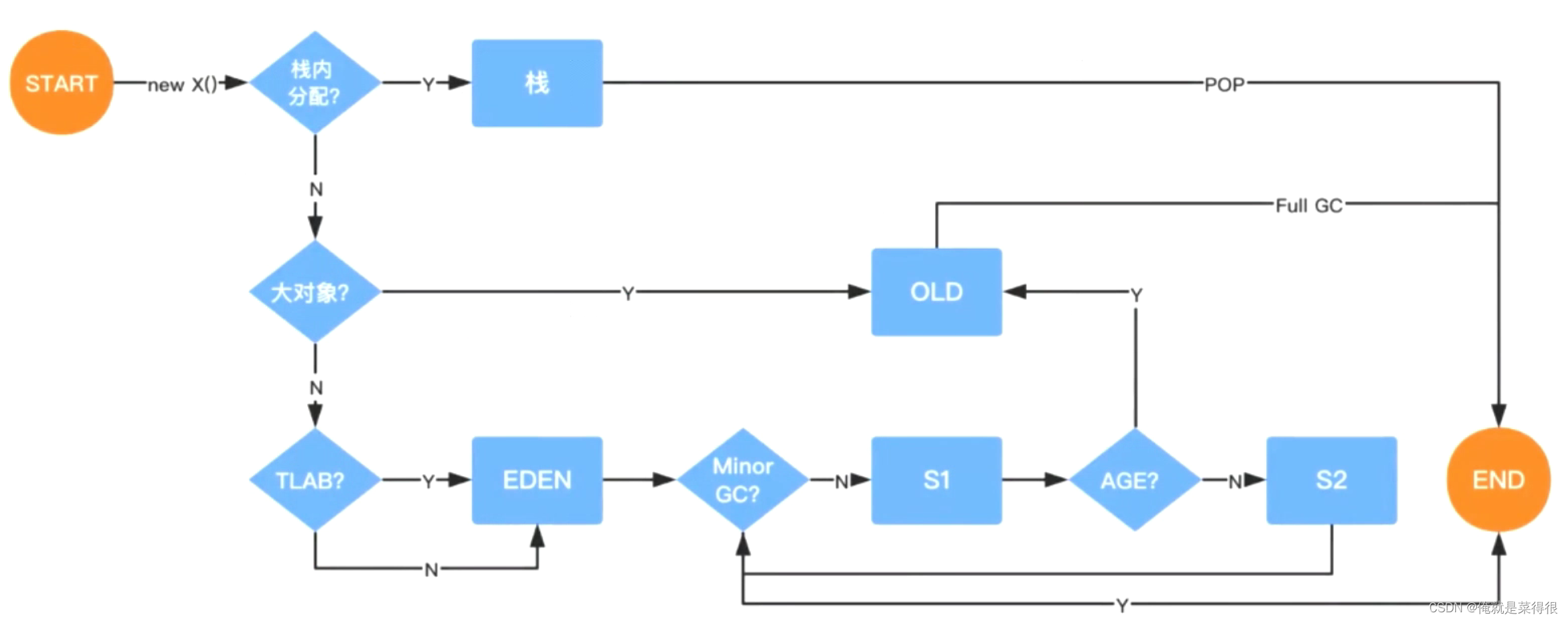
在上一篇文章中,我们学习了数据库的Redis的主从集群复制模式,如果从库出现问题,那么其他主从库还可以处理读写请求,但是如果主库宕机,写请求从库处理不了,整个系统就不可用了,虽然只处理只读请求,显然是不符合业务需求。
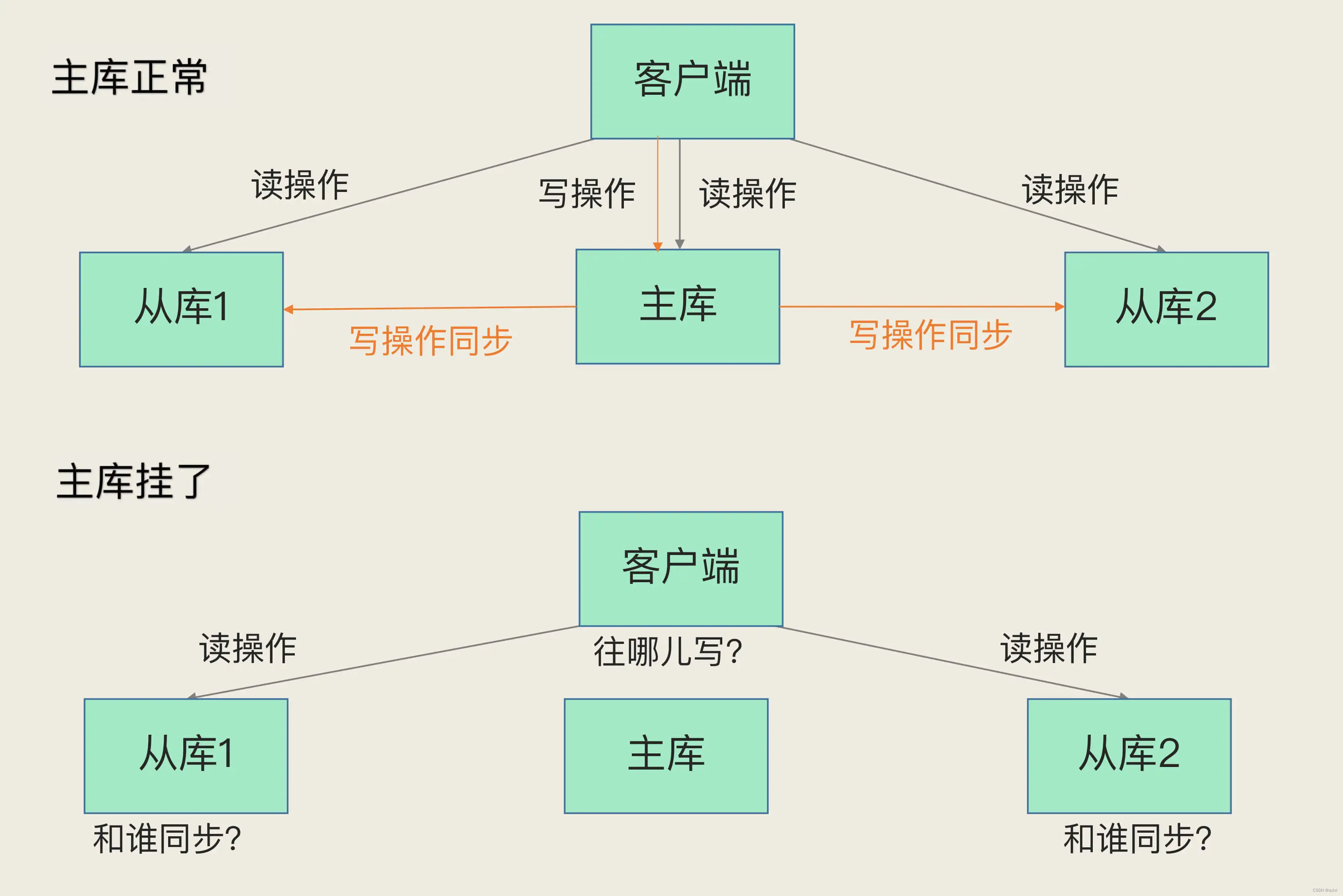
如上图中所示当主库出现异常的,如何处理,一般的处理方式是通过选择一个新的主库进行处理请求。
- 主库是否真的挂了?
- 如何选择一个主库?
- 如何将新的主库信息同步给从库?
而上面这个流程就是哨兵所解决的,哨兵机制是实现主从库自动切换的关键机制,有效解决了主从复制模式下故障转移的三个问题。
哨兵机制的核心流程
类比一下在现实生活中,哨兵的作用是什么,主要是负责周边安全,也就是会时不时的看一看周边有什么异常的情况没,有敌军没有。而Redis哨兵机制也是同样的原理,有一个单独的进程进行监听主从库运行实例,主要就是监控、选主、和通知。
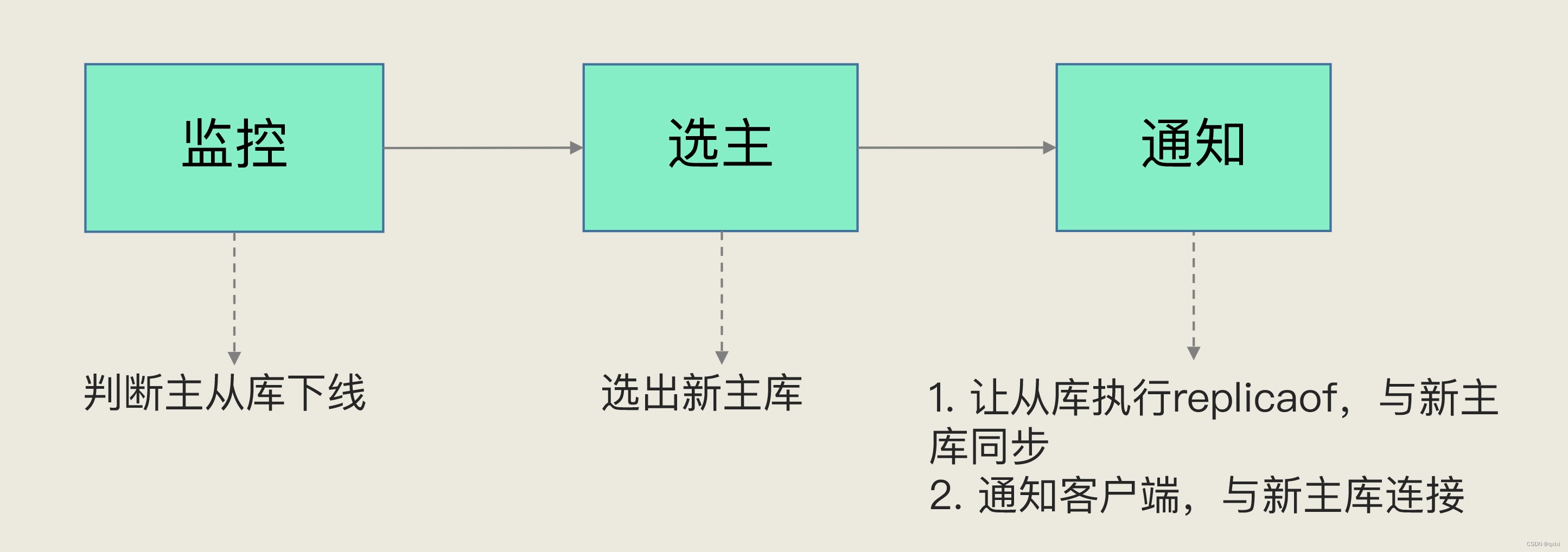
监控
监控主要是判断主从库是否出现服务实例异常,如网络连接、服务宕机、关闭等情况。如果只是针对的从库下线其实影响还好,并且其他的主从库也可以继续提供服务,但是如果主库出现下线,就需要选择一个新的主库来进行提供写服务,而选举的这个主库需要和集群内的从库进行数据的复制,以及选择主库的这个过程都是比较耗费资源的。具体的流程就是哨兵进程会定时发送PING到主从库。
选主
一旦确定主库宕机后,就需要从已有的集群中选择一个从库作为一个主库实例,以提供服务。
通知
当选择一个新的主库实例后,需要主库发送自己的info信息到集群内的从库实例,然后让从库实例进行同步,以及通过客户端与主库建立连接。
在通知中,只需要一次网络的交互通知就可以,但是监控和选主过程中,需要判断好主库到底有没有宕机,以及如何选择一个新的主库。需要涉及到决策逻辑。
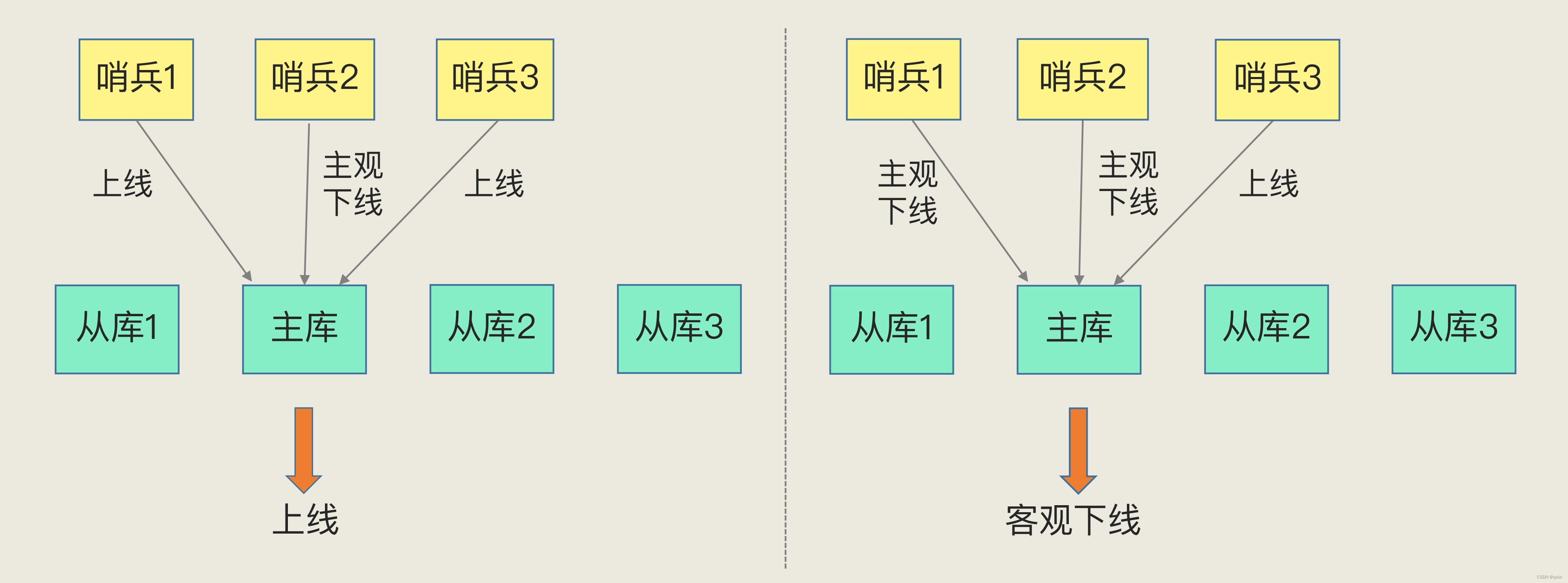
主观和客观下线
主观下线其实比较简单,就是当哨兵机制发送给主从库实例的PING超时相应,就会判断为主观下线,对于从库实例其实没有什么影响,但是对于主库如果误判了主库的下线,就会出现不必要的选主和主从复制过程,其中涉及到计算和通信开销。
而误判的判断标准就是哨兵以为A主库宕机了,但是实际上是由于A主库负载过高没有处理过来,那么后续的选择和主从复制就是消耗。
如何减少误判?
如果在现实生活中,帮派之间选择帮主,那么简单的逻辑就是主要过了半数以上的结果就是大家都认同的,同样的道理,也就是利用哨兵集群,比如哨兵1,2认为主库下线,那么就可以认为主库下线。
客观下线:只要大多数的哨兵实例,都判断主库已经主观下线,主库会被标记为客观下线
如何选定主库
选择主库的过程中,先会筛选不符合条件的从库实例,然后从符合的实例中进行按照优先级、复制进度、ID号打分,得分最高者就是从库。
筛选
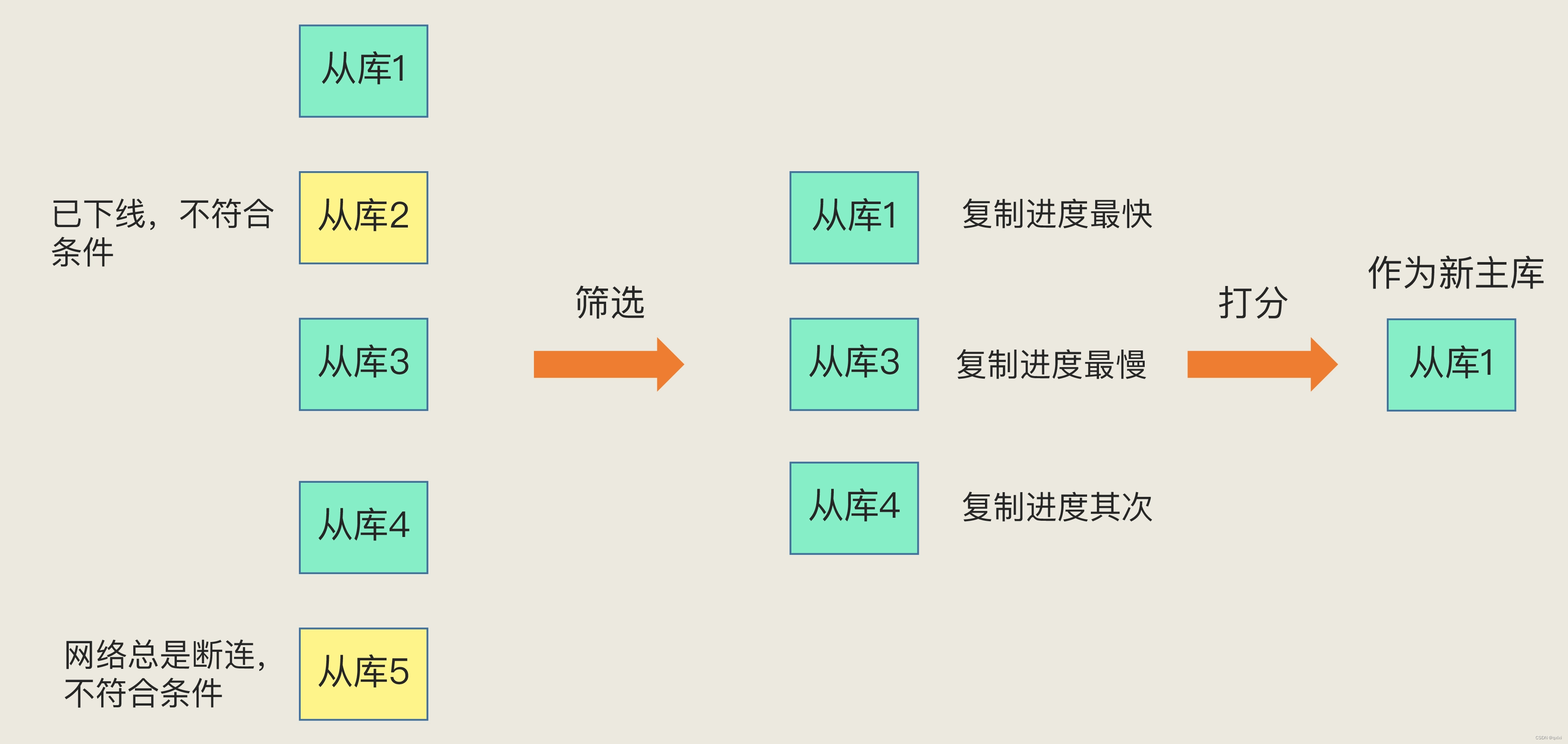
筛选的过程比较简单,必须是在线的从库实例以及网络比较稳定的实例。
网络稳定通常是查看之前的网络连接状态,当超过一定的阈值,其实就可以判断不符合条件,而在Redis中有down-after-milliseconds 是主从库断连的最大连接超时时间,如果在给定时间内都没有连接上,并且超过10次,那么就不符合选择主库的条件。
上图中就是将已经下线的从库2 以及网络不稳定的从库5 pass。
评分
评分的过程只要有3个过程,只要评选出分数高者,就选定为主库。具体就是1.优先级最高 2.数据复制进度快的高 3.id实例小的高
优先级评分可以通过在设置redis实例的时候通过slave-priority配置项,比如针对硬件配置比较高的,设置较大的优先级。如果选择出即退出。
而复制进度快的,我们知道在数据复制的时候,主从库都分别通过master-repl-offset和slave-repl-offset在repl_backlog_buffer中记录自己的复制的位移,主要通过一个函数计算出那个从库的复制位移更接近已经宕机的主库位移就可以选择出。
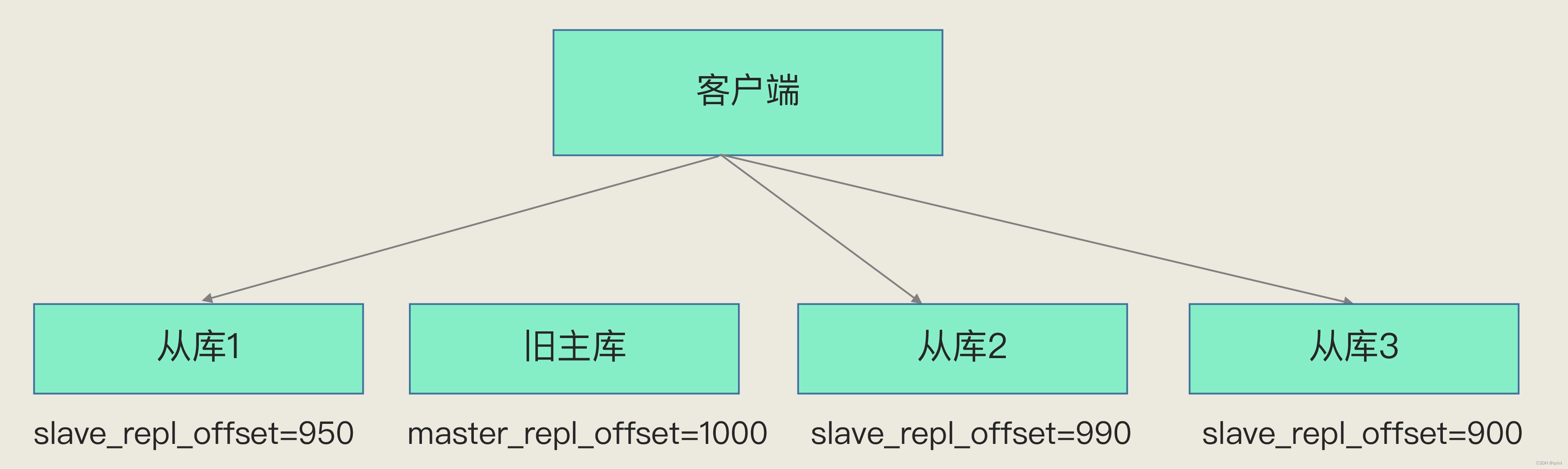
如果基于复制进度都没有办法选择出,那么只能通过ID最小的号选择为主库。
总结一下,其实选择主库的过程就是两个过程一个筛选数据以及通过优先级、数据复制进度、ID编号依次选择主库。
总结
本篇主要循序渐进介绍了在数据同步的过程中,如果主库实例宕机的情况下,如果选择一个主库。相应的引出了怎么判断主库下线(主观和客户下线)、以及如何选择主库、哨兵机制的核心流程。那么对于能解决选择主库的哨兵集群,又是什么样的原理,我们下一篇介绍。
通过使用哨兵实例可以减少误判率,但是哨兵集群中如果出现实例宕机,,是否会影响主库判断和选择?