【group by】mysql分组查询的案例和原理
- 【一】group by的使用场景
- 【二】group by的基本语法
- 【1】基本语法
- 【2】常用的聚合函数
- (1)max函数:取出分组中的最大值
- (2)avg函数:取出分组中的平均值
- (3)count函数:统计每个分组中的数据有多少条
- (4)sum函数:取出分组结果中的总和
- (5)min函数:取出分组中的最小值
- 【3】条件where和having的区别
- (1)案例一:where过滤
- (2)案例二:having过滤
- (3)案例三:where+having
- (4)案例四:按表达式或函数进行筛选
- (5)案例五:按照多个字段分组
- 【三】注意点和常见的报错信息
- 【1】注意的问题
- (1)where + having的使用
- (2)group by一定要配合聚合函数一起使用嘛?
- (3)group by的字段一定要出现在select中嘛?
- (4)group by导致的慢SQL问题
- 【2】常见的报错信息
- 【四】group by的原理分析
- 【1】分析案例
- 【2】group by的原理
- (1)explain分析
- (2)group by 的简单执行流程
- 【3】where和having的原理
- (1)group by + where 的执行流程
- (2)group by + having 的执行
- (3)同时有where、group by 、having的执行顺序
- 【五】group by的优化方案
- 【1】优化的思路
- 【2】group by 后面的字段加索引
- 【3】order by null 不用排序
- 【4】尽量只使用内存临时表
- 【5】使用SQL_BIG_RESULT优化
- 【六】实际使用案例分析
【一】group by的使用场景
【二】group by的基本语法
【1】基本语法
除了出现在group by后面的字段,如果要在select后查询其他字段,必须用聚合函数进行聚合
select
聚合函数,
列(要求出现在group by的后面)
from
表
where
筛选条件
group by
分组的列表
order by
子句
【2】常用的聚合函数
(1)max函数:取出分组中的最大值
根据岗位来分组,并且查询每个岗位中最高工资的员工的工资是多少
select
max(salary),
job_id
from
employees
group by
job_id;
(2)avg函数:取出分组中的平均值
根据部门分组,并且查询每个部门中工资的平均值
select
avg(salary),
department_id
from
employees
where
email like '%a%'
group by
department_id
(3)count函数:统计每个分组中的数据有多少条
(4)sum函数:取出分组结果中的总和
(5)min函数:取出分组中的最小值
【3】条件where和having的区别
(1)分组查询中的筛选条件分为两类:
1-分组前筛选: 数据源是原始表,用where,放在group by前面,因为在分组前筛选
2-分组后筛选:数据源是分组后的结果集 ,用having,放在group by后面,因为在分组后进行筛选。
(1)案例一:where过滤
查询有奖金的每个领导手下最高工资的员工工资
select
max(salary),
manager_id
from
employees
where
commission_pct is not null
group by
manager_id
(2)案例二:having过滤
查询哪个部门的员工个数大于2
select
count(*),
department_id
from
employees
group by
department_id
having
count(*) > 2;
分组后筛选的思路:
1-查询每个部门的员工个数;
2-根据1的结果进行筛选,查询哪个部门员工个数大于2
(3)案例三:where+having
查询每个工种有奖金的员工的最高工资大于12000的工种编号和最高工资
select
max(salary),
job_id
from
employees
where
commission_pct is not null
group by
job_id
having
max(salary) > 12000;
思路:
1-首先where筛选有奖金的员工
2-然后根据岗位id分组
3-然后max(salary)取出每个分组中的工资最高值
4-最后having筛选工资最高值大于12000的组
(4)案例四:按表达式或函数进行筛选
按照员工姓名长度分组,查询每一组员工个数,筛选员工个数大于5的有哪些
select
count(*) ,
length(last_name) as len_name
from
employees
group by
length(last_name)
having
count(*) > 5;
(5)案例五:按照多个字段分组
查询每个部门每个工种的员工平均工资,并且按照平均工资的高低排序
select
avg(salary),
department_id,
job_id
from
employees
where
department_id is not null
group by
department_id,
job_id
order by
avg(salary) desc;
【三】注意点和常见的报错信息
【1】注意的问题
(1)where + having的使用
(1)having子句用于分组后筛选,where子句用于行条件筛选
(2)having一般都是配合group by 和聚合函数一起出现如(count(),sum(),avg(),max(),min())
(3)where条件子句中不能使用聚集函数,而having子句就可以。
(4)having只能用在group by之后,where执行在group by之前
(2)group by一定要配合聚合函数一起使用嘛?
(3)group by的字段一定要出现在select中嘛?
(4)group by导致的慢SQL问题
group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。
【2】常见的报错信息
(1)分组后没有使用聚合函数
(2)select后的字段没有出现在group by之后
【四】group by的原理分析
【1】分析案例
group by一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。
一张员工表
CREATE TABLE `staff` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`id_card` varchar(20) NOT NULL COMMENT '身份证号码',
`name` varchar(64) NOT NULL COMMENT '姓名',
`age` int(4) NOT NULL COMMENT '年龄',
`city` varchar(64) NOT NULL COMMENT '城市',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
表中的数据如下

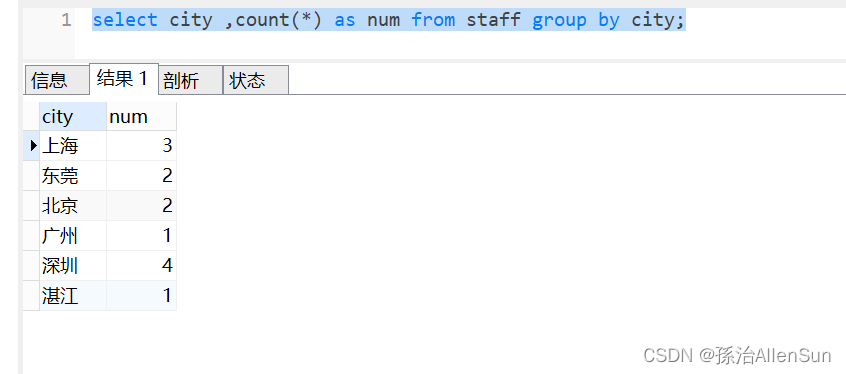
现在有这么一个需求:统计每个城市的员工数量。对应的 SQL 语句就可以这么写:
select city ,count(*) as num from staff group by city;
执行结果如下
【2】group by的原理
(1)explain分析
explain select city ,count(*) as num from staff group by city;

(1)Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表
(2)Extra 这个字段的Using filesort表示使用了排序
(2)group by 的简单执行流程
explain select city ,count(*) as num from staff group by city;
这个sql的执行流程:
(1)创建内存临时表,表里有两个字段city和num;
(2)全表扫描staff的记录,依次取出city = 'X’的记录。
1-判断临时表中是否有为 city='X’的行,没有就插入一个记录 (X,1);
2-如果临时表中有city='X’的行的行,就将x 这一行的num值加 1;
(3)遍历完成后,再根据字段city做排序,得到结果集返回给客户端。
流程的执行图如下:
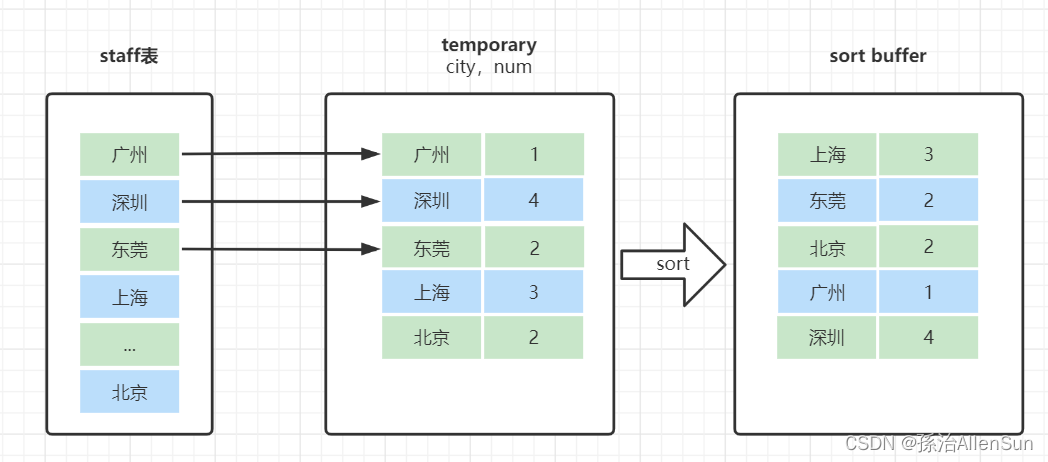
临时表的排序流程:
就是把需要排序的字段,放到sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和rowid排序
(1)如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回
(2)如果是rowid排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回。
(3)怎么确定走的是全字段排序还是rowid 排序排序呢?由一个数据库参数控制的,max_length_for_sort_data
【3】where和having的原理
(1)group by + where 的执行流程
(1)如果加了where条件之后,并且where条件列加了索引呢,执行流程是怎样?
select city ,count(*) as num from staff where age> 30 group by city;
//加索引
alter table staff add index idx_age (age);
(2)explain分析
explain select city ,count(*) as num from staff where age> 30 group by city;

从explain 执行计划结果,可以发现查询条件命中了idx_age的索引,并且使用了临时表和排序。
Using index condition:表示索引下推优化,根据索引尽可能的过滤数据,然后再返回给服务器层根据where其他条件进行过滤。这里单个索引为什么会出现索引下推呢?explain出现并不代表一定是使用了索引下推,只是代表可以使用,但是不一定用了。
(3)执行流程如下
1-创建内存临时表,表里有两个字段city和num;
2-扫描索引树idx_age,找到大于年龄大于30的主键ID
3-通过主键ID,回表找到city = ‘X’
判断临时表中是否有为 city='X’的行,没有就插入一个记录 (X,1);
如果临时表中有city='X’的行的行,就将x 这一行的num值加 1;
4-继续重复2,3步骤,找到所有满足条件的数据,
5-最后根据字段city做排序,得到结果集返回给客户端。
(2)group by + having 的执行
(1)案例分析
查询每个城市的员工数量,获取到员工数量不低于3的城市,having可以很好解决
select city ,count(*) as num from staff group by city having num >= 3;
查询结果
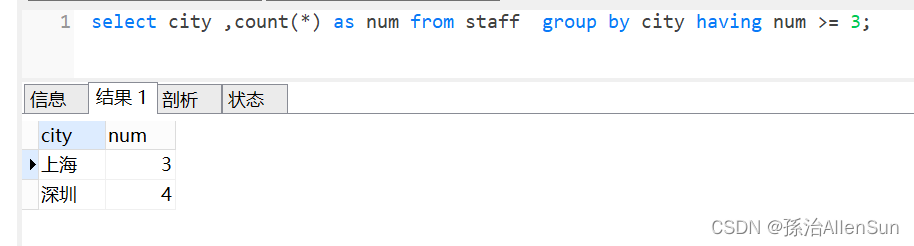
having称为分组过滤条件,它对返回的结果集操作。
(3)同时有where、group by 、having的执行顺序
(1)案例分析
select city ,count(*) as num from staff where age> 19 group by city having num >= 3;
(2)执行流程
1-执行where子句查找符合年龄大于19的员工数据
2-group by子句对员工数据,根据城市分组。
3-对group by子句形成的城市组,运行聚集函数计算每一组的员工数量值;
4-最后用having子句选出员工数量大于等于3的城市组。
【五】group by的优化方案
【1】优化的思路
方向1:既然它默认会排序,我们不给它排是不是就行了?
方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果了?
(1)group by 后面的字段加索引
(2)order by null 不用排序
(3)尽量只使用内存临时表
(4)使用SQL_BIG_RESULT
【2】group by 后面的字段加索引
如何保证group by后面的字段数值一开始就是有序的呢?当然就是加索引。
select city ,count(*) as num from staff where age= 19 group by city;
执行计划

给它加个联合索引idx_age_city(age,city)
alter table staff add index idx_age_city(age,city);
再去看执行计划,发现既不用排序,也不需要临时表

加合适的索引是优化group by最简单有效的优化方式。
【3】order by null 不用排序
并不是所有场景都适合加索引的,如果碰上不适合创建索引的场景,如果你的需求并不需要对结果集进行排序,可以使用order by null。
select city ,count(*) as num from staff group by city order by null
执行计划如下,已经没有filesort了
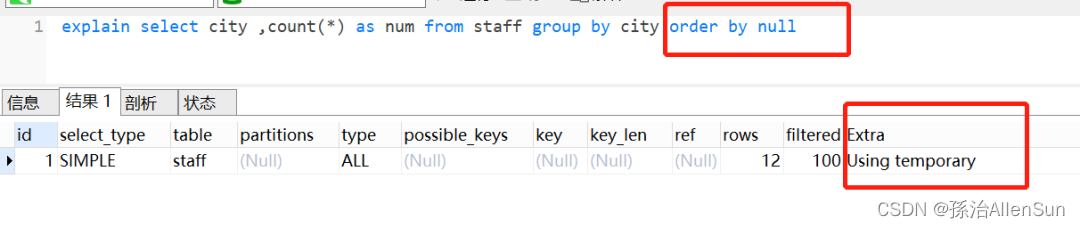
【4】尽量只使用内存临时表
如果group by需要统计的数据不多,我们可以尽量只使用内存临时表;因为如果group by 的过程因为内存临时表放不下数据,从而用到磁盘临时表的话,是比较耗时的。因此可以适当调大tmp_table_size参数,来避免用到磁盘临时表。
【5】使用SQL_BIG_RESULT优化
如果数据量实在太大怎么办呢?总不能无限调大tmp_table_size吧?但也不能眼睁睁看着数据先放到内存临时表,随着数据插入发现到达上限,再转成磁盘临时表吧?这样就有点不智能啦。
因此,如果预估数据量比较大,我们使用SQL_BIG_RESULT 这个提示直接用磁盘临时表。MySQl优化器发现,磁盘临时表是B+树存储,存储效率不如数组来得高。因此会直接用数组来存
示例SQl如下:
select SQL_BIG_RESULT city ,count(*) as num from staff group by city;
执行计划的Extra字段可以看到,执行没有再使用临时表,而是只有排序

执行流程如下:
(1)初始化 sort_buffer,放入city字段;
(2)扫描表staff,依次取出city的值,存入 sort_buffer 中;
(3)扫描完成后,对 sort_buffer的city字段做排序
(4)排序完成后,就得到了一个有序数组。
(5)根据有序数组,统计每个值出现的次数。