文章目录
- 0、参考资料
- 1、WAV 格式了解
- 1.1 WAV 文件头
- 1.2 RIFF Chunk 区块
- 1.3 Format Chunk 区块
- 1.4 Data Chunk 区块
- 2、音频剪裁 -> 解码 -> 编码
- 2.1 mp3
- 2.1.1 裁剪
- 2.1.2 解码
- 2.1.3 编码
- 2.2 pcm 裁剪
0、参考资料
【音频处理】WAV 文件格式分析 ( 逐个字节解析文件头 | 相关字段的计算公式 )
android音频学习笔记之wav头文件
1、WAV 格式了解
WAV格式,多媒体中使用的声波文件格式之一,它是以RIFF格式为标准的。RIFF是英文 Resource Interchange File Format 的缩写,每个WAV文件的头四个字节便是“RIFF”。WAV文件分为两部分:- 第一部分:文件头,记录重要的参数信息,对于音频而言,包括采样率、通道数、位宽等
- 第二部分:数据块,也就是一帧一帧的二进制数据,对于音频而言,就是原始的
PCM数据
1.1 WAV 文件头


WAV文件头,主要分为三部分:RIFF Chunk 区块、Format Chunk 区块、Data Chunk 区块
1.2 RIFF Chunk 区块
RIFF数据块长度为 12 字节,共有三种码段。ChunkID:填入“RIFF”为标识,表示这是一个RIFF格式文件ChunkSize:除了RIFF及自己以外,整个文件的长度,该值计算方式为 PCM 音频样本总字节数 + 44 − 8Format:填入WAVE来标识这是一个wav文件
// RIFF 资源交换文件标志
header[0] = 'R'.code.toByte()
header[1] = 'I'.code.toByte()
header[2] = 'F'.code.toByte()
header[3] = 'F'.code.toByte()
// 数据大小
header[4] = (totalDataLen and 0xffL).toByte()
header[5] = (totalDataLen shr 8 and 0xffL).toByte()
header[6] = (totalDataLen shr 16 and 0xffL).toByte()
header[7] = (totalDataLen shr 24 and 0xffL).toByte()
// WAVE 标识 wav 文件
header[8] = 'W'.code.toByte()
header[9] = 'A'.code.toByte()
header[10] = 'V'.code.toByte()
header[11] = 'E'.code.toByte()
1.3 Format Chunk 区块
-
Subchunk1ID:填入“fmt”为标识,波形格式标志 -
Subchunk1Size:Subchunk1减去Subchunk1ID和Subchunk1Size之后剩下的长度,一般为 16 -
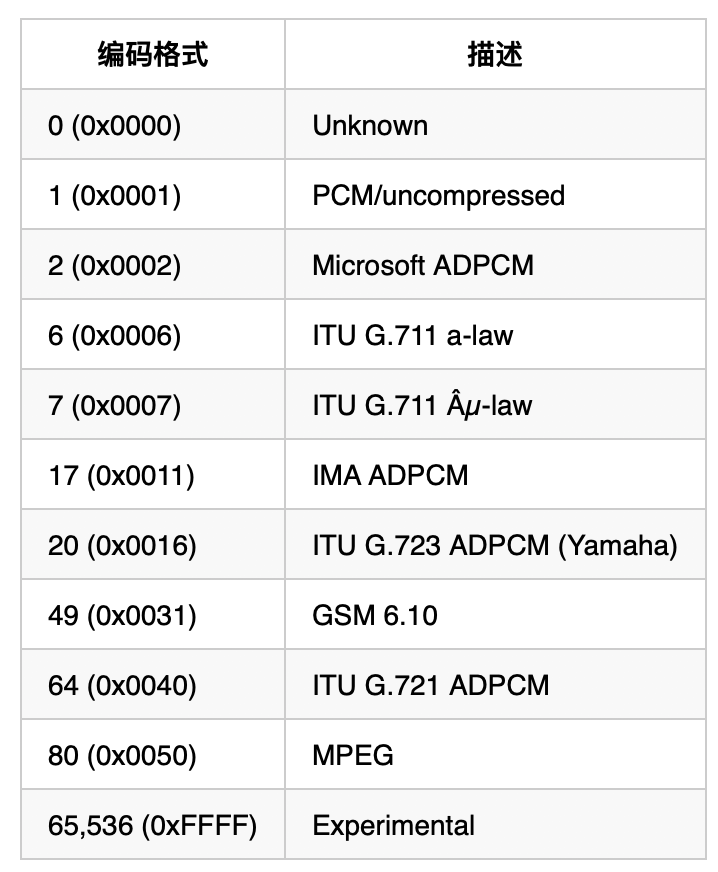
AudioFormat:编码格式,即压缩格式,1 表示PCM格式,无压缩wav文件几乎支持所有ACM规范的编码格式,其信息存储在文件头 21、22 两个字节中,有如下编码格式:
-
NumChannels:声道数,1 表示单声道,2 表示双声道 -
SampleRate:采样率 -
ByteRate:波形数据传输速率, 即每秒中的字节数,计算公式为:

-
BlockAlign:标识块对齐的内容(数据块的调整数),播放软件一次处理多少个该值大小的字节数据,以便将其用于缓冲区的调整,也标识一帧的字节数。每个采样所需的字节数,计算公式为:

-
BitsPerSample:采样位宽,即每个采样点的bit数,其中 8 表示 8bit,16 表示 16bit,32 表示 32bit。
// 'fmt ':波形格式标志,最后一位空格
header[12] = 'f'.code.toByte()
header[13] = 'm'.code.toByte()
header[14] = 't'.code.toByte()
header[15] = ' '.code.toByte() // 过渡字节
// 数据大小
header[16] = 16 // 4 bytes: size of 'fmt ' chunk
header[17] = 0
header[18] = 0
header[19] = 0
// 编码方式为 PCM 编码格式
header[20] = 1 // format = 1
header[21] = 0
// 通道数
header[22] = channels.toByte()
header[23] = 0
// 采样率,每个通道的播放速度
header[24] = (sampleRate and 0xff).toByte()
header[25] = (sampleRate shr 8 and 0xff).toByte()
header[26] = (sampleRate shr 16 and 0xff).toByte()
header[27] = (sampleRate shr 24 and 0xff).toByte()
// 音频数据传送速率,采样率 * 通道数 * 采样深度 / 8
header[28] = (byteRate and 0xffL).toByte()
header[29] = (byteRate shr 8 and 0xffL).toByte()
header[30] = (byteRate shr 16 and 0xffL).toByte()
header[31] = (byteRate shr 24 and 0xffL).toByte()
// 确定系统一次要处理多少个这样字节的数据,确定缓冲区,通道数 * 采样位数
header[32] = (channels * 16 / 8).toByte()
header[33] = 0
// 每个样本的数据位数
header[34] = 16
header[35] = 0
1.4 Data Chunk 区块
Subchunk2ID:填入“data”为标识Subchunk2Size:PCM音频数据的总长度,单位字节,即文件总字节数 - 44
// Data chunk
header[36] = 'd'.code.toByte() // data
header[37] = 'a'.code.toByte()
header[38] = 't'.code.toByte()
header[39] = 'a'.code.toByte()
header[40] = (totalAudioLen and 0xffL).toByte()
header[41] = (totalAudioLen shr 8 and 0xffL).toByte()
header[42] = (totalAudioLen shr 16 and 0xffL).toByte()
header[43] = (totalAudioLen shr 24 and 0xffL).toByte()
2、音频剪裁 -> 解码 -> 编码
2.1 mp3
2.1.1 裁剪
/**
* mp3 音频文件截取工具
*/
object Mp3CutUtils {
private const val TAG = "Mp3CutUtils"
/* 适当的调整 SAMPLE_SIZE 可以更加精确的裁剪音乐 */
private const val SAMPLE_SIZE = 1024 * 200
/*微秒*/
private const val MICRO_SECOND = 1000_000
/**
* 裁剪 MP3 格式的音频
* @param sourceFile 源文件地址
* @param targetFile 目标文件地址
* @param startSecond 截取开始时间(秒)
* @param endSecond 截取结束时间(秒)
*/
fun cutMp3Audio(
sourceFile: String,
targetFile: String,
startSecond: Float,
endSecond: Float
): Boolean {
// 转换为微秒
val startMicrosecond = startSecond * MICRO_SECOND
val endMicrosecond = endSecond * MICRO_SECOND
MLog.d(
TAG,
"cutMp3Audio: sourceFile = $sourceFile, targetFile = $targetFile, startMicrosecond = $startMicrosecond, endMicrosecond = $endMicrosecond"
)
var extractor: MediaExtractor? = null
var outputStream: BufferedOutputStream? = null
try {
extractor = MediaExtractor()
extractor.setDataSource(sourceFile)
val track = getAudioTrack(extractor)
if (track < 0) {
return false
}
// 选择音频轨道
extractor.selectTrack(track)
outputStream = BufferedOutputStream(FileOutputStream(targetFile), SAMPLE_SIZE)
MLog.d(
TAG, "cutMp3Audio: startMicrosecond = $startMicrosecond, endMicrosecond = $endMicrosecond"
)
//跳至开始裁剪位置
extractor.seekTo(startMicrosecond.toLong(), MediaExtractor.SEEK_TO_PREVIOUS_SYNC)
while (true) {
val buffer: ByteBuffer = ByteBuffer.allocate(SAMPLE_SIZE)
val sampleSize = extractor.readSampleData(buffer, 0)
val timeStamp = extractor.sampleTime
MLog.d(TAG, "cutMp3Audio: sampleSize = $sampleSize, timeStamp = $timeStamp")
// >= 1000000 是要裁剪停止和指定的裁剪结尾不小于 1 秒,否则裁剪 5 秒可能产生需要 4 秒音频
// 裁剪到只有 4.6 秒,大多数音乐播放器是向下取整,这样对于播放器变成了 4 秒,
// 所以要裁剪比 4 秒多一秒的边界
if (timeStamp > endMicrosecond && timeStamp - endMicrosecond >= MICRO_SECOND) {
break
}
if (sampleSize <= 0) {
break
}
val buf = ByteArray(sampleSize)
buffer.get(buf, 0, sampleSize)
// 写入文件
outputStream.write(buf)
// 音轨数据往前读
extractor.advance()
}
} catch (e: Exception) {
e.printStackTrace()
return false
} finally {
extractor?.release()
if (outputStream != null) {
try {
outputStream.close()
} catch (e: Exception) {
e.printStackTrace()
}
}
}
return true
}
/**
* 获取音频数据轨道
* @param audioExtractor
*/
fun getAudioTrack(audioExtractor: MediaExtractor): Int {
for (i in 0 until audioExtractor.trackCount) {
val format = audioExtractor.getTrackFormat(i)
val mime = format.getString(MediaFormat.KEY_MIME)
if (mime?.startsWith(AudioConstant.AUDIO_PREFIX) == true) {
return i
}
}
return -1
}
}
2.1.2 解码
/**
* MP3 -> PCM 解码
*/
object Mp3DecodeUtil {
private const val TAG = "Mp3DecodeUtil"
/**
* 解码 MP3 文件
* @param mp3Path mp3 文件路径
*/
fun decodeMP3(mp3Path: String): Boolean {
MLog.d(TAG, "decodeMP3: mp3Path = $mp3Path")
val audioExtractor = MediaExtractor()
var audioDecoder: MediaCodec? = null
try {
audioExtractor.setDataSource(mp3Path)
val track = getAudioTrack(audioExtractor)
if (track != -1) {
val format = audioExtractor.getTrackFormat(track)
val mime = format.getString(MediaFormat.KEY_MIME)
audioExtractor.selectTrack(track)
audioDecoder = MediaCodec.createDecoderByType(mime!!)
audioDecoder.configure(format, null, null, 0)
audioDecoder.start()
}
} catch (e: IOException) {
e.printStackTrace()
return false
}
coreDecode(mp3Path, audioExtractor, audioDecoder)
MLog.d(TAG, "decoderMP3: stop")
audioDecoder?.stop()
audioDecoder?.release()
audioExtractor?.release()
return true
}
private fun coreDecode(mp3:String, audioExtractor: MediaExtractor, audioDecoder: MediaCodec?) {
audioDecoder ?: return
val info = MediaCodec.BufferInfo()
// 得到输出 PCM 文件的路径 val pcmFilePath =
val pcmFilePath = "${mp3.substring(0, mp3.lastIndexOf("."))}${AudioConstant.SUFFIX_PCM}"
val fos = FileOutputStream(File(pcmFilePath))
val bufferedOutputStream = BufferedOutputStream(fos)
while (true) {
extractorInputBuffer(audioExtractor, audioDecoder!!)
val outIndex = audioDecoder.dequeueOutputBuffer(info, 50000)
MLog.d(TAG, "decoderMP3: presentationTimeUs = ${info.presentationTimeUs}, outIndex = $outIndex")
if (outIndex >= 0) {
MLog.d(TAG, "decoderMP3: outIndex >= 0")
val data = audioDecoder.getOutputBuffer(outIndex)
if (info.flags and MediaCodec.BUFFER_FLAG_CODEC_CONFIG != 0) {
info.size = 0
}
if (info.size != 0) {
data!!.position(info.offset)
data.limit(info.offset + info.size)
// 将数据写入 bufferedOutputStream 中
bufferedOutputStream.write(ByteArray(data.remaining()) { data.get() })
data.clear()
}
audioDecoder.releaseOutputBuffer(outIndex, false)
}
if (info.flags and MediaCodec.BUFFER_FLAG_END_OF_STREAM != 0) {
MLog.d(TAG, "decoderMP3: MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0")
convertPcm2Wav(pcmFilePath, audioExtractor)
break
}
}
}
private fun extractorInputBuffer(mediaExtractor: MediaExtractor, mediaCodec: MediaCodec) {
val inputIndex = mediaCodec.dequeueInputBuffer(50000)
if (inputIndex >= 0) {
val inputBuffer = mediaCodec.getInputBuffer(inputIndex)
val sampleTime = mediaExtractor.sampleTime
val sampleSize = mediaExtractor.readSampleData(inputBuffer!!, 0)
if (mediaExtractor.advance()) {
mediaCodec.queueInputBuffer(inputIndex, 0, sampleSize, sampleTime, 0)
} else {
if (sampleSize > 0) {
mediaCodec.queueInputBuffer(
inputIndex,
0,
sampleSize,
sampleTime,
MediaCodec.BUFFER_FLAG_END_OF_STREAM
)
} else {
mediaCodec.queueInputBuffer(
inputIndex,
0,
0,
0,
MediaCodec.BUFFER_FLAG_END_OF_STREAM
)
}
}
}
}
private fun convertPcm2Wav(pcmFilePath: String, audioExtractor: MediaExtractor) {
val wavFilePath = "${pcmFilePath.substring(0, pcmFilePath.lastIndexOf("."))}${AudioConstant.SUFFIX_CUT_WAV}"
MLog.d(TAG, "convertPcm2Wav: pcmFilePath = $pcmFilePath, wavFilePath = $wavFilePath")
val track = getAudioTrack(audioExtractor)
if (track == -1) return
val format = audioExtractor.getTrackFormat(track)
val duration = format.getLong(MediaFormat.KEY_DURATION)
val channelCount = format.getInteger(MediaFormat.KEY_CHANNEL_COUNT)
val sampleRate = format.getInteger(MediaFormat.KEY_SAMPLE_RATE)
val byteNumber = (if (format.containsKey(MediaFormat.KEY_WIDTH)) format.getInteger(
"bit-width"
) else 16) / 8
MLog.d(TAG, "convertPcm2Wav: duration = $duration, sampleRate = $sampleRate, channelCount = $channelCount, byteNumber = $byteNumber")
PcmEncodeUtil.convertPcm2Wav(pcmFilePath, wavFilePath, sampleRate, channelCount, byteNumber)
}
}
2.1.3 编码
/**
* PCM -> WAV 编码
*/
object PcmEncodeUtil {
private const val TAG = "PcmEncodeUtil"
/**
* PCM 文件转 WAV 文件
* @param inPcmFilePath 输入 PCM 文件路径
* @param outWavFilePath 输出 WAV 文件路径
* @param sampleRate 采样率,例如 44100
* @param channels 声道数 单声道 1 或 双声道 2
* @param bitNum 采样位数,8 或 16
*/
fun convertPcm2Wav(
inPcmFilePath: String?,
outWavFilePath: String?,
sampleRate: Int ,
channels: Int ,
bitNum: Int
) {
MLog.d(TAG, "convertPcm2Wav: inPcmFilePath = $inPcmFilePath, outWavFilePath = $outWavFilePath")
if (inPcmFilePath.isNullOrEmpty() || outWavFilePath.isNullOrEmpty()) {
MLog.d(
TAG,
"convertPcm2Wav: 文件路径为空!!!"
)
return
}
MLog.d(TAG, "convertPcm2Wav: 开始转 WAV")
var `in`: FileInputStream? = null
var out: FileOutputStream? = null
val data = ByteArray(1024)
try {
`in` = FileInputStream(inPcmFilePath)
out = FileOutputStream(outWavFilePath)
// PCM 文件大小
val totalAudioLen = `in`.channel.size()
writeWaveFileHeader(out, totalAudioLen, sampleRate, channels, bitNum)
var length = 0
while (`in`.read(data).also { length = it } > 0) {
out.write(data, 0, length)
}
} catch (e: Exception) {
MLog.d(TAG, "convertPcm2Wav: error = $e")
e.printStackTrace()
} finally {
// 编码结束后删除文件 .temp
MLog.d(TAG, "convertPcm2Wav: deleteFile = $inPcmFilePath")
File(inPcmFilePath).delete()
MLog.d(TAG, "convertPcm2Wav: 关闭流")
if (`in` != null) {
try {
`in`.close()
} catch (e: IOException) {
e.printStackTrace()
}
}
if (out != null) {
try {
out.close()
} catch (e: IOException) {
e.printStackTrace()
}
}
}
}
/**
* 输出 WAV 文件
* @param out WAV输出文件流
* @param totalAudioLen 整个音频 PCM 数据大小
* @param sampleRate 采样率
* @param channels 声道数
* @param bitNum 采样位数
*/
private fun writeWaveFileHeader(
out: FileOutputStream, totalAudioLen: Long,
sampleRate: Int, channels: Int, bitNum: Int
) {
val header = getWaveHeader(totalAudioLen, sampleRate, channels, bitNum)
out.write(header, 0, AudioConstant.WAVE_HEAD_SIZE)
}
/**
* 获取Wav header 字节数据
* @param totalAudioLen 整个音频PCM数据大小
* @param sampleRate 采样率
* @param channels 声道数
* @param bitNum 采样位数
*/
fun getWaveHeader(totalAudioLen: Long, sampleRate: Int, channels: Int, bitNum: Int): ByteArray {
// 总大小,由于不包括 RIFF 和 WAV,所以是 44 - 8 = 36,在加上 PCM 文件大小
val totalDataLen = totalAudioLen + 36
// 采样字节 byte 率
val byteRate = (sampleRate * channels * bitNum / 8).toLong()
val header = ByteArray(AudioConstant.WAVE_HEAD_SIZE)
header[0] = 'R'.code.toByte() // RIFF
header[1] = 'I'.code.toByte()
header[2] = 'F'.code.toByte()
header[3] = 'F'.code.toByte()
header[4] = (totalDataLen and 0xffL).toByte() // 数据大小
header[5] = (totalDataLen shr 8 and 0xffL).toByte()
header[6] = (totalDataLen shr 16 and 0xffL).toByte()
header[7] = (totalDataLen shr 24 and 0xffL).toByte()
header[8] = 'W'.code.toByte() // WAVE
header[9] = 'A'.code.toByte()
header[10] = 'V'.code.toByte()
header[11] = 'E'.code.toByte()
// FMT Chunk
header[12] = 'f'.code.toByte() // 'fmt '
header[13] = 'm'.code.toByte()
header[14] = 't'.code.toByte()
header[15] = ' '.code.toByte() // 过渡字节
// 数据大小
header[16] = 16 // 4 bytes: size of 'fmt ' chunk
header[17] = 0
header[18] = 0
header[19] = 0
// 编码方式 10H 为 PCM 编码格式
header[20] = 1 // format = 1
header[21] = 0
// 通道数
header[22] = channels.toByte()
header[23] = 0
// 采样率,每个通道的播放速度
header[24] = (sampleRate and 0xff).toByte()
header[25] = (sampleRate shr 8 and 0xff).toByte()
header[26] = (sampleRate shr 16 and 0xff).toByte()
header[27] = (sampleRate shr 24 and 0xff).toByte()
// 音频数据传送速率,采样率*通道数*采样深度/8
header[28] = (byteRate and 0xffL).toByte()
header[29] = (byteRate shr 8 and 0xffL).toByte()
header[30] = (byteRate shr 16 and 0xffL).toByte()
header[31] = (byteRate shr 24 and 0xffL).toByte()
// 确定系统一次要处理多少个这样字节的数据,确定缓冲区,通道数*采样位数
header[32] = (channels * 16 / 8).toByte()
header[33] = 0
// 每个样本的数据位数
header[34] = 16
header[35] = 0
// Data chunk
header[36] = 'd'.code.toByte() // data
header[37] = 'a'.code.toByte()
header[38] = 't'.code.toByte()
header[39] = 'a'.code.toByte()
header[40] = (totalAudioLen and 0xffL).toByte()
header[41] = (totalAudioLen shr 8 and 0xffL).toByte()
header[42] = (totalAudioLen shr 16 and 0xffL).toByte()
header[43] = (totalAudioLen shr 24 and 0xffL).toByte()
return header
}
}
2.2 pcm 裁剪
/**
* wav 音频文件截取工具
*/
object WavCutUtils {
private const val TAG = "WavCutUtils"
/* 一个 int 所占字节大小*/
private const val INT_BYTE_SIZE = 4
/**
* 截取 wav 音频文件
* @param sourceFile 源文件地址
* @param targetFile 目标文件地址
* @param start 截取开始时间(秒)
* @param end 截取结束时间(秒)
* @param duration 总时长(秒)
*/
fun cutWavAudio(
sourceFile: String,
targetFile: String,
start: Int,
end: Int,
duration: Int
): Boolean {
MLog.d(TAG, "cutWavAudio: sourceFile = $sourceFile, targetFile = $targetFile, start = $start, end = $end, duration = $duration")
val wav = File(sourceFile)
try {
val src = RandomAccessFile(wav, "r")
val headSize = getHeadSize(src)
MLog.d(TAG, "cutWavAudio: headSize = $headSize")
if (!wav.exists()) {
return false
}
if (start < 0 || end <= 0 || start >= duration || end > duration || start >= end) {
return false
}
val fis = FileInputStream(wav)
// 音频数据大小(wav文件头长度不一定是44)
val wavSize = (wav.length() - headSize).toInt()
// 截取的音频数据大小
val splitSize = wavSize / duration * (end - start)
// 截取时跳过的音频数据大小
val skipSize = wavSize / duration * start
MLog.d(TAG, "cutWavAudio: wavSize = $wavSize, splitSize = $splitSize, skipSize = $skipSize")
// 核心操作
coreOperate(fis, targetFile, splitSize, headSize, skipSize)
} catch (e: Exception) {
e.printStackTrace()
return false
}
return true
}
/**
* 核心处理数据
* @param fis 输入流
* @param targetFile 目标文件路径
* @param splitSize 截取的音频数据大小
* @param headSize 头部信息大小
* @param skipSize 跳过的音频数据大小
*/
private fun coreOperate(fis: FileInputStream, targetFile: String, splitSize: Int, headSize: Int, skipSize: Int) {
// 存放文件大小, 4 代表一个 int 占用字节数
val buf1 = ByteBuffer.allocate(INT_BYTE_SIZE)
// 放入文件长度信息
buf1.putInt(splitSize + 36)
// 代表文件长度
var fileLen = buf1.array()
// 存放音频数据大小,4 代表一个 int 占用字节数
val buf2 = ByteBuffer.allocate(INT_BYTE_SIZE)
// 放入数据长度信息
buf2.putInt(splitSize)
// 代表数据长度
var dataLen = buf2.array()
// 数组反转
fileLen = reverse(fileLen)
dataLen = reverse(dataLen)
val head = ByteArray(headSize)
// 读取源 wav 文件头部信息
fis.read(head, 0, head.size)
// 4 代表一个 int 占用字节数
for (i in 0..3) {
// 替换原头部信息里的文件长度
head[i + INT_BYTE_SIZE] = fileLen[i]
// 替换原头部信息里的数据长度
head[i + headSize - INT_BYTE_SIZE] = dataLen[i]
}
// 存放截取的音频数据
val fileByte = ByteArray(splitSize + head.size)
// 放入修改后的头部信息
for (i in head.indices) {
fileByte[i] = head[i]
}
// 存放截取时跳过的音频数据
val skipBytes = ByteArray(skipSize)
// 跳过不需要截取的数据
fis.read(skipBytes, 0, skipBytes.size)
// 读取要截取的数据到目标数组
fis.read(fileByte, head.size, fileByte.size - head.size)
fis.close()
// 如果目标文件已存在,则删除目标文件
val target = File(targetFile)
if (target.exists()) {
val result = target.delete()
}
// 给目标文件写入信息
val fos = FileOutputStream(target)
fos.write(fileByte)
fos.flush()
fos.close()
}
/**
* 数组反转
* @param array
*/
private fun reverse(array: ByteArray): ByteArray {
var temp: Byte
val len = array.size
for (i in 0 until len / 2) {
temp = array[i]
array[i] = array[len - 1 - i]
array[len - 1 - i] = temp
}
return array
}
/**
* 得到头文件大小
*/
private fun getHeadSize(srcFis: RandomAccessFile): Int {
var offset = 0
// riff
getChunkId(srcFis)
offset += 4
// length
getChunkSize(srcFis)
offset += 4
// wave
getChunkId(srcFis)
offset += 4
// fmt
getChunkId(srcFis)
offset += 4
// fmt length
var skipLength = getChunkSize(srcFis)
offset += 4
var skipBytes = ByteArray(skipLength)
srcFis.read(skipBytes)
offset += skipLength
var chunkId = getChunkId(srcFis)
offset += 4
while (chunkId != "data") {
skipLength = getChunkSize(srcFis)
offset += 4
skipBytes = ByteArray(skipLength)
srcFis.read(skipBytes)
offset += skipLength
chunkId = getChunkId(srcFis)
offset += 4
}
offset += 4
MLog.d(TAG, "getHeadSize: offset = $offset")
return offset
}
/**
* 获取块大小
*/
private fun getChunkSize(srcFis: RandomAccessFile): Int {
val formatSize = ByteArray(4)
srcFis.read(formatSize)
val fisrt8 = formatSize[0].toInt() and 0xFF
val fisrduration6 = formatSize[1].toInt() and 0xFF
val fisrt24 = formatSize[2].toInt() and 0xFF
val fisrt32 = formatSize[3].toInt() and 0xFF
val chunkSize = fisrt8 or (fisrduration6 shl 8) or (fisrt24 shl 16) or (fisrt32 shl 24)
MLog.d(TAG, "getChunkSize: chunkSize = $chunkSize")
return chunkSize
}
/**
* 获取块标识
*/
private fun getChunkId(srcFis: RandomAccessFile): String {
val bytes = ByteArray(4)
srcFis.read(bytes)
val stringBuilder = StringBuilder()
for (i in bytes.indices) {
stringBuilder.append(Char(bytes[i].toUShort()))
}
val chunkId = stringBuilder.toString()
MLog.d(TAG, "getChunkId: chunkId = $chunkId")
return chunkId
}
}