[2103.02221] Energy-Based Learning for Scene Graph Generation (arxiv.org)
目录
Abstarct
1 Introduction
2 Approach
2.1 Scene Graph Generation
2.2 Energy Based Modeling
2.3 Energy Models for Scene Graphs Generation
2.4 Energy Model Architectue
2.4.1 Edge Graph Neural Network
2.4.2 Pooling Layer
Abstarct
传统的场景图生成方法使用交叉熵损失来训练,将对象和关系视为独立的实体。然而,在一个固有的结构化预测问题中,这样的公式忽略了输出空间中的结构。本文提出一种新的energy-based学习框架来生成场景图。所提出的公式允许在输出空间中有效地合并场景图的结构。学习框架中的这个附加约束充当归纳偏差,并允许模型从少量标签中有效地学习。
1 Introduction
这些网络通常通过最小化两组标签上的个体交叉熵损失进行端到端训练。这种方法的主要缺点是预测的质量(损失)仅仅与正确预测标签的数量成正比,而忽略了场景图输出空间的丰富结构(例如,对象和关系标签集之间的相关性或排斥性)。此外,关系的训练样本数量的不平衡导致优势关系被严重偏爱,从而导致在测试时的关系预测有偏差。
因为基于交叉熵的训练将场景图中的object和relation视为独立的实体,这相当于将给定图像的场景图的可能性分解为单个对象和关系的可能性的乘积。
首先,在损失计算过程中,每个关系项的损失与场景图中其余部分预测的关系无关。因此,一个不正确的关系,如<人、骑、浪>,将与<人、后面、浪>一样受到惩罚,而不考虑其他关系<人,骑,岩石>。然而,使用常识推理,我们可以确定<人,骑,浪>在<人,携带,冲浪板>的情况下是极不可能的,相比与尽管不正确的关系‘behind’,应该受到严厉的惩罚。
其次,由于个体关系项的总和,为了使损失最小化,模型被激励去预测训练数据中更常见的关系。
作者提出基于能量的学习框架将场景图的结构整合到学习框架中,该框架依赖于图消息传递算法进行能量计算,该算法用于对给定图像的场景图的联合条件密度进行建模。这样的公式将问题从个体似然项的最大化总和转变为直接最大化对象和关系的联合似然。此外,这种增加的结构作为学习的归纳偏差,允许模型从更少的数据中有效地学习关系统计。
2 Approach
将image graph和场景图分别输入能量模型,并分别使用门控图神经网络和新型边缘图神经网络进行状态细化。然后,使用池化层获得每个图的向量表示。这些表示被连接起来,并作为输入传递给多层感知器,该感知器预测联合输入(图像)-输出(场景图)配置的能量。损耗是根据真实值和预测组态的能量值计算的。

2.1 Scene Graph Generation
概述基于标准交叉熵损失的当前场景图生成方法。
场景图生成方法采用一个两阶段的框架。(1)在第一阶段,给定一个图片I,使用Faster R-CNN等标准目标检测器获得边界框。使用RoIAlign和对象标签上的初始分布一起提取这些区域对应的特征。在下一阶段,这些检测被用作预测场景图的输入。
使用边界框特征以及对象标签和边界框的空间坐标来初始化一组节点特征。使用LSTM、TreeLSTM或Graph Attention Networks等架构对这些特征进行细化,以整合上下文信息。然后通过对精炼的特征进行分类得到对象标签O。关系标签R是通过从对象边界框的并集中提取特征得到的,然后使用BiLSTMs或BiTreeLSTMs进行状态细化,最后进行分类。
这些模型使用对象和关系标签上的标准交叉熵损失进行训练。在计算单个损失时,孤立地考虑每个对象和关系,然后将其相加以获得给定图像的损失。这种损失公式忽略了一个事实,即场景图中的对象和关系是相互依赖的。直观地说,将这些依赖关系结合到学习过程中应该会导致性能的提高。
作者提出了一种新的基于能量的学习框架,该框架允许使用在输出空间中明确包含结构的“损失”来训练场景图生成模型。
2.2 Energy Based Modeling
基于能量的模型通过为输入配置分配标量能量值来编码能量之间的依赖关系。
本文重点是场景图生成,是一个判别任务,对于这样的任务,只关系给定输入x的各种标签配置的相对能量。
2.3 Energy Models for Scene Graphs Generation
在本文的场景图函数中,数据是图像I,标签y是场景图SG(被定义为(O,R))。
作者从image中提取出基于graph的表示,叫做image graph()。使用从对象边界框中提取的特征来实例化image graph的节点。
给定场景图生成模型M和图像I,预测一个场景图 ,并且计算image graph
。将场景图和图像作为能量模型(Eθ)的输入,计算和预测配置相对应的能量。然后使用真实的场景图
和image graph
(由真实bounding boxes构建)之间的能量值。然后用这两个能量值来计算能量损失:

计算这种损失需要解决一个优化问题,以找到一个最小化能量值的场景图配置:

预测的 用作“初始化”,通过Eq.(3)定义的一系列步骤到达低能量构型;每一步都类似于普通的梯度下降,只是增加了高斯噪声。当使用上述损失进行训练时,观察到能量值的大小变得任意大,导致梯度溢出。通过在能量值上添加L2正则化:
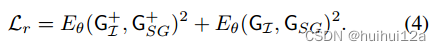
由于场景图的空间是非常高维的,为了稳定学习,我们需要限制能量模型的搜索空间。这是通过结合底层场景图生成模型使用的任务损失来完成的,将预测输出作为初始预测的附加正则化。训练场景图生成器和能量模型的总损失为:
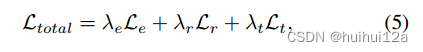
2.4 Energy Model Architectue
给定image graph()和场景图(
),能量模型首先使用GNN对状态表示进行细化,分别在场景图和image graph上使用EGNN和GNN来整合上下文信息。然后,在每个图上应用池化层,以获得总结图状态的向量表示。最后,将这两个向量输入到MLP,计算与预测的场景图配置相对应的能量值。然后对ground truth场景图和输入图像重复这些操作。能量模型可以被参数化为:
![]()
2.4.1 Edge Graph Neural Network
为了允许将卷积运算直接应用于包含边特征的(如场景图)graph representation,提出了一种改进的图消息传递算法。对于每一个节点ni,通过下式聚合来自邻居节点和边的信息:

类似地,传递边的消息由:
![]()
传递边消息是方向感知的,这是重要的,因为两个节点之间的关系取决于边缘的方向而变化。
2.4.2 Pooling Layer
使用门控池化层生成两个图的向量表示,

然后将这两个向量通过一个线性层,在连接之后,获得图形的最终向量表示。在图像图GI中,由于没有边缘特征,我们使用池化节点向量N作为图的向量表示。