文章目录
- 前言
- 第3章 线程间共享数据
- 3.1 共享数据带来的问题
- 3.1.1 条件竞争
- 3.1.2 避免恶性条件竞争
- 3.2 使用互斥量保护共享数据
- 3.2.1 C++中使用互斥量
- 3.2.2 用代码来保护共享数据
- 3.2.3 定位接口间的条件竞争
- 选项1: 传入一个引用
- 选项2:无异常抛出的拷贝构造函数或移动构造函数
- 选项3:返回指向弹出值的指针
- 选项4:“选项1 + 选项2”或 “选项1 + 选项3”
- 3.2.4 死锁:问题描述及解决方案
- 3.2.5 避免死锁的进阶指导
- 避免嵌套锁
- 使用固定顺序获取锁
- 使用锁的层次结构
- 3.2.6 std::unique_lock——灵活的锁
- 3.2.7 不同域中互斥量所有权的传递
- 3.2.8 锁的粒度
- 3.3 保护共享数据的其他方式
- 3.3.1 保护共享数据的初始化过程
- 3.3.2 保护不常更新的数据结构
- 3.3.3 嵌套锁
- 总结
前言
本章主要内容
- 共享数据带来的问题
- 使用互斥量保护数据
- 数据保护的替代方案
第3章 线程间共享数据
上一章中,我们已经对线程管理有所了解,现在让我们来看一下“共享数据的那些事”。
想象一下,你和你的朋友合租一个公寓,公寓中只有一个厨房和一个卫生间。当你的朋友在卫生间时,你就会不能使用了(除非你们特别好,可以在同时使用一个房间)。
这个问题也会出现在厨房,假如:厨房里有一个组合式烤箱,当在烤香肠的时候,也在做蛋糕,就可能得到我们不想要的食物(香肠味的蛋糕)。此外,在公共空间将一件事做到一半时,发现某些需要的东西被别人借走,或是当离开的一段时间内有些东西被变动了地方,这都会令我们不爽。
同样的问题,也困扰着线程。当线程在访问共享数据的时候,必须定一些规矩,用来限定线程可访问的数据位。还有,一个线程更新了共享数据,需要对其他线程进行通知。从易用性的角度,同一进程中的多个线程进行数据共享,有利有弊。错误的共享数据使用是产生并发bug的一个主要原因,并且后果要比香肠味的蛋糕更加严重。
本章就以在C++中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。
3.1 共享数据带来的问题
涉及到共享数据时,问题就可能是因为共享数据修改所导致。
- 如果共享数据是只读的,那么操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。
- 但是,当一个或多个线程要修改共享数据时,就会产生很多麻烦。这种情况下,就必须小心谨慎,才能确保所有线程都工作正常。
不变量(invariants)的概念对开发者们编写的程序会有一定的帮助——对于特殊结构体的描述;
比如,“变量包含列表中的项数”。不变量通常会在一次更新中被破坏,特别是比较复杂的数据结构,或者一次更新就要改动很大的数据结构。
双链表中每个节点都有一个指针指向列表中下一个节点,还有一个指针指向前一个节点。其中不变量就是节点A中指向“下一个”节点B的指针,还有前向指针。为了从列表中删除一个节点,其两边节点的指针都需要更新。当其中一边更新完成时,不变量就被破坏了,直到另一边也完成更新;在两边都完成更新后,不变量就又稳定了。
从一个列表中删除一个节点的步骤如下(如图3.1)
- [a] 找到要删除的节点N
- [b] 更新前一个节点指向N的指针,让这个指针指向N的下一个节点
- [c] 更新后一个节点指向N的指针,让这个指正指向N的前一个节点
- [d] 删除节点N
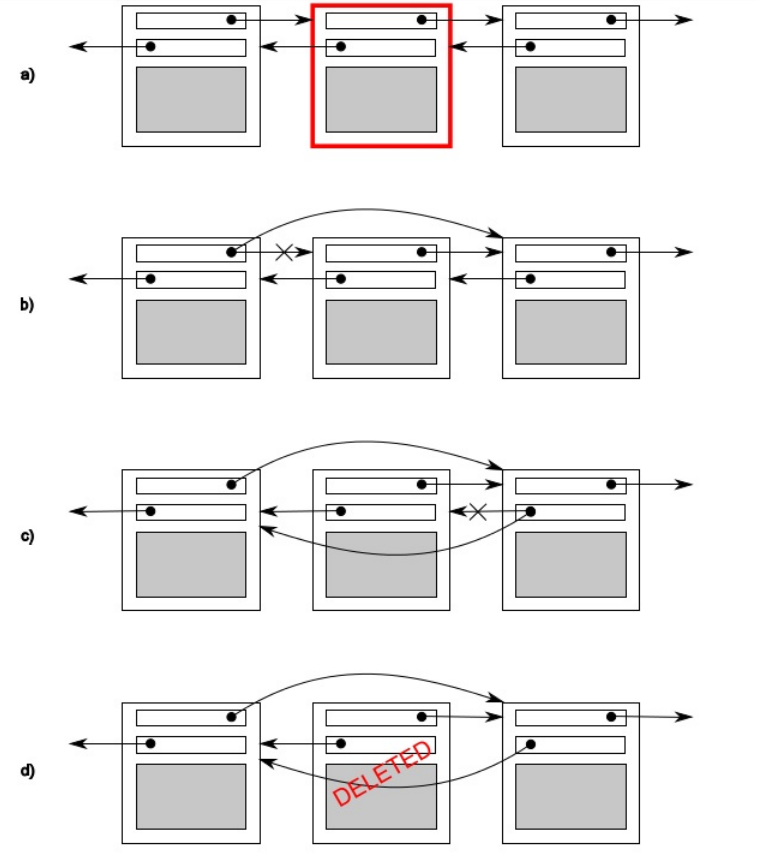
图3.1 从一个双链表中删除一个节点
图中b和c在相同的方向上指向和原来已经不一致了,这就破坏了不变量。
线程间的问题在于修改共享数据,致使不变量遭到破坏。
当在删除过程中不确定是否有其他线程能够进行访问的话,可能就有线程访问到刚刚删除一边的节点;这样的话,线程就读取到要删除节点的数据(因为只有一边的连接被修改,如图3.1(b)),这样不变量就被破坏了。
破坏不变量的后果是不确定的,当其他线程按从左往右的顺序来访问列表时,它将跳过被删除的节点。
在一方面,如有第二个线程尝试删除图中右边的节点,那么可能会让数据结构产生永久性的损坏,使程序崩溃。
无论结果如何,这都是并行中常见错误:
- 条件竞争(racecondition)。
3.1.1 条件竞争
假如你去电影院买电影票。如果去的是一家大电影院,有很多收银台,很多人就可以在同一时间买电影票。当另一个收银台也在卖你想看的这场电影的电影票,那么你的座位选择范围就取决于在之前已预定的座位。当只有少量的座位剩下,这就意味着,这可能是一场抢票比赛,看谁能抢到最后一张票。这就是一个条件竞争的例子:你的座位(或者你的电影票)都取决于两种购买方式的相对顺序。
并发中竞争条件的形成,取决于一个以上线程的相对执行顺序,每个线程都抢着完成自己的任务。大多数情况下,即使改变执行顺序,也是良性竞争,其结果可以接受。例如,有两个线程同时向一个处理队列中添加任务,因为系统提供的不变量保持不变,所以谁先谁后都不会有什么影响。当不变量遭到破坏时,才会产生条件竞争,比如双向链表的例子。并发中对数据的条件竞争通常表示为恶性条件竞争,我们对不产生问题的良性条件竞争不感兴趣。
C++ 标准中也定义了数据竞争这个术语,一种特殊的条件竞争:并发的去修改一个独立对象(参见5.1.2节),数据竞争是(可怕的)未定义行为的起因。
恶性条件竞争通常发生于完成对多于一个的数据块的修改时,例如:对两个连接指针的修改
(如图3.1)。因为操作要访问两个独立的数据块,独立的指令将会对数据块将进行修改,并且其中一个线程可能正在进行时,另一个线程就对数据块进行了访问。因为出现的概率太低,条件竞争很难查找,也很难复现。如CPU指令连续修改完成后,即使数据结构可以让其他并发线程访问,问题再次复现的几率也相当低。当系统负载增加时,随着执行数量的增加,执行序列的问题复现的概率也在增加,这样的问题只可能会出现在负载比较大的情况下。条件竞争通常是时间敏感的,所以程序以调试模式运行时,它们常会完全消失,因为调试模式会影响程序的执行时间(即使影响不多)。
当你以写多线程程序为生,条件竞争就会成为你的梦魇;编写软件时,我们会使用大量复杂的操作,用来避免恶性条件竞争。
3.1.2 避免恶性条件竞争
这里提供一些方法来解决恶性条件竞争,最简单的办法就是:
- 对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态。从其他访问线程的角度来看,修改不是已经完成了,就是还没开始。
C++ 标准库提供很多类似的机制,下面会逐一介绍。
另一个选择是:
- 对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,
这就是所谓的无锁编程。
不过,这种方式很难得到正确的结果。如果到这个级别,无论是内存模型上的细微差异,还是线程访问数据的能力,都会让工作量变的很大。内存模型将在第5章讨论,无锁编程将在第7章讨论。
另一种处理条件竞争的方式是:
- 使用
事务的方式去处理数据结构的更新(这里的"处理"就如同对数据库进行更新一样)。
所需的一些数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交。当数据结构被另一个线程修改后,或处理已经重启的情况下,提交就会无法进行,这称作为“软件事务内存”(software transactional memory (STM))。
理论研究中,这是一个很热门的研究领域。这个概念将不会在本书中再进行介绍,因为在 C++ 中没有对STM进行直接支持(尽管C++有事务性内存扩展的技术规范[1])。但是,基本思想会在后面提及。
保护共享数据结构的最基本的方式,是使用C++标准库提供的互斥量。
[1] SO/IEC TS 19841:2015—Technical Specification for C++ Extensions for Transactional
Memory http://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?
csnumber=66343 .
3.2 使用互斥量保护共享数据
当程序中有共享数据时,你肯定不想让程序其陷入条件竞争,或是出现不变量被破坏的情
况。将所有访问共享数据结构的代码都标记为互斥是否是一种更好的办法呢?这样,任何一个线程在执行时,其他线程试图访问共享数据时,就必须进行等待。除非该线程就在修改共享数据,否则任何线程都不可能会看到被破坏的不变量。
当访问共享数据前,将数据锁住,在访问结束后,再将数据解锁。线程库需要保证,当一个线程使用特定互斥量锁住共享数据时,其他的线程想要访问锁住的数据,都必须等到之前那个线程对数据进行解锁后,才能进行访问。这就保证了所有线程都能看到共享数据,并而不破坏不变量。
互斥量一种数据保护通用机制,但它不是什么“银弹”;需要编排代码来保护数据的正确性(见3.2.2节),并避免接口间的竞争条件(见3.2.3节)也非常重要。不过,互斥量自身也有问题,也会造成死锁(见3.2.4节),或对数据保护的太多(或太少)(见3.2.8节)。
3.2.1 C++中使用互斥量
C++中通过实例化 std::mutex 创建互斥量实例,通过成员函数lock()对互斥量上锁,unlock()进行解锁。不过,实践中不推荐直接去调用成员函数,调用成员函数就意味着,必须在每个函数出口都要去调用unlock(),也包括异常的情况。C++标准库为互斥量提供了一个RAII语法的模板类 std::lock_guard ,在构造时就能提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁互斥量能被正确解锁。下面的程序清单中,展示了如何在多线程应用中,使用 std::mutex 构造的 std::lock_guard 实例,对一个列表进行访问保护。 std::mutex 和 std::lock_guard 都在 头文件中声明。
清单3.1 使用互斥量保护列表
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list; // 1
std::mutex some_mutex; // 2
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex); // 3
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex); // 4
return
std::find(some_list.begin(),some_list.end(),value_to_find) !=
some_list.end();
}
清单3.1中有一个全局变量①,这个全局变量被一个全局的互斥量保护②。add_to_list()③和list_contains()④函数中使用 std::lock_guardstd::mutex ,使得这两个函数中对数据的访问是互斥的:list_contains()不可能看到正在被add_to_list()修改的列表。
C++17中添加了一个新特性,称为模板类参数推导,这样类似 std::locak_guard 这样简单的模板类型的模板参数列表可以省略。③和④的代码可以简化成:
std::lock_guard guard(some_mutex);
具体的模板参数类型推导则交给C++17的编译器完成。3.2.4节中,会介绍C++17中的一种加强版数据保护机制—— std::scoped_lock ,所以在C++17的环境下,上面的这行代码也可以写成:
std::scoped_lock guard(some_mutex);
为了让代码更加清晰,并且兼容只支持之C++11标准的编译器,我将会继续使用 std::lock_guard ,并在代码清代中写明模板参数的类型。
某些情况下使用全局变量没问题,但在大多数情况下,互斥量通常会与需要保护的数据放在同一类中,而不是定义成全局变量。这是面向对象设计的准则:将其放在一个类中,就可让他们联系在一起,也可对类的功能进行封装,并进行数据保护。这种情况下,函数add_to_list和list_contains可以作为这个类的成员函数。互斥量和需要保护的数据,在类中都定义为private成员,这会让访问数据的代码更清晰,并且容易看出在什么时候对互斥量上锁。当所有成员函数都会在调用时对数据上锁,结束时对数据解锁,这就保证了访问时数据不变量不被破坏。
当然,事情也不是总是那么理想,聪明的你一定注意到了:当其中一个成员函数返回的是保护数据的指针或引用时,会破坏数据。具有访问能力的指针或引用可以访问(并可能修改)被保护的数据,而不会被互斥锁限制。这就需要对接口有相当谨慎的设计,要确保互斥量能锁住数据的访问,并且不留后门。
3.2.2 用代码来保护共享数据
使用互斥量来保护数据,并不是仅仅在每一个成员函数中都加入一个 std::lock_guard 对象那么简单;一个指针或引用,也会让这种保护形同虚设。不过,检查指针或引用很容易,只要没有成员函数通过返回值或者输出参数的形式,向其调用者返回指向受保护数据的指针或引用,数据就是安全的。如果你还想深究,就没这么简单了。确保成员函数不会传出指针或引用的同时,检查成员函数是否通过指针或引用的方式来调用也是很重要的(尤其是这个操作不在你的控制下时)。函数可能没在互斥量保护的区域内,存储着指针或者引用,这样就很危险。更危险的是:将保护数据作为一个运行时参数,如同下面清单中所示那样。
清单3.2 无意中传递了保护数据的引用
class some_data
{
int a;
std::string b;
public:
void do_something();
};
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template<typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex> l(m);
func(data); // 1 传递“保护”数据给用户函数
}
};
some_data* unprotected;
void malicious_function(some_data& protected_data)
{
unprotected=&protected_data;
}
data_wrapper x;
void foo()
{
x.process_data(malicious_function); // 2 传递一个恶意函数
unprotected->do_something(); // 3 在无保护的情况下访问保护数据
}
例子中process_data看起来没有任何问题, std::lock_guard 对数据做了很好的保护,但调用用户提供的函数func①,就意味着foo能够绕过保护机制将函数 malicious_function 传递进去②,在没有锁定互斥量的情况下调用 do_something() 。
这段代码的问题在于根本没有保护,只是将所有可访问的数据结构代码标记为互斥。函
数 foo() 中调用 unprotected->do_something() 的代码未能被标记为互斥。
这种情况下,C++线程库无法提供任何帮助,只能由开发者使用正确的互斥锁来保护数据。从乐观的角度上看,还是有方法可循的:切勿将受保护数据的指针或引用传递到互斥锁作用域之外,无论是函数返回值,还是存储在外部可见内存,亦或是以参数的形式传递到用户提供的函数去。
虽然这是在使用互斥量保护共享数据时常犯的错误,但绝不仅仅是一个潜在的陷阱而已。下一节中,你将会看到,即便是使用了互斥量对数据进行了保护,条件竞争依旧可能存在。
3.2.3 定位接口间的条件竞争
因为使用了互斥量或其他机制保护了共享数据,就不必再为条件竞争所担忧吗?并不是,你依旧需要确定数据是否受到了保护。回想之前双链表的例子,为了能让线程安全地删除一个节点,需要确保防止对这三个节点(待删除的节点及其前后相邻的节点)的并发访问。如果只对指向每个节点的指针进行访问保护,那就和没有使用互斥量一样,条件竞争仍会发生——除了指针,整个数据结构和整个删除操作需要保护。这种情况下最简单的解决方案就是使用互斥量来保护整个链表,如清单3.1所示。
尽管链表的个别操作是安全的,但不意味着你就能走出困境;即使在一个很简单的接口中,依旧可能遇到条件竞争。例如,构建一个类似于 std::stack 结构的栈(清单3.3),除了构造函数和swap()以外,需要对 std::stack 提供五个操作:push()一个新元素进栈,pop()一个元素出栈,top()查看栈顶元素,empty()判断栈是否是空栈,size()了解栈中有多少个元素。即使修改了top(),使其返回一个拷贝而非引用(即遵循了3.2.2节的准则),对内部数据使用一个互斥量进行保护,不过这个接口仍存在条件竞争。这个问题不仅存在于基于互斥量实现的接口中,在无锁实现的接口中,条件竞争依旧会产生。这是接口的问题,与其实现方式无关。
清单3.3 std::stack 容器的实现
template<typename T,typename Container=std::deque<T> >
class stack
{
public:
explicit stack(const Container&);
explicit stack(Container&& = Container());
template <class Alloc> explicit stack(const Alloc&);
template <class Alloc> stack(const Container&, const Alloc&);
template <class Alloc> stack(Container&&, const Alloc&);
template <class Alloc> stack(stack&&, const Alloc&);
bool empty() const;
size_t size() const;
T& top();
T const& top() const;
void push(T const&);
void push(T&&);
void pop();
void swap(stack&&);
template <class... Args> void emplace(Args&&... args); //C++14的新特性
};
虽然empty()和size()可能在返回时是正确的,但其的结果是不可靠的;当它们返回后,其他线程就可以自由地访问栈,并且可能push()多个新元素到栈中,也可能pop()一些已在栈中的元素。这样的话,之前从empty()和size()得到的结果就有问题了。
当栈实例是非共享的,如果栈非空,使用empty()检查再调用top()访问栈顶部的元素是安全的。如下代码所示:
stack<int> s;
if (! s.empty()){ // 1
int const value = s.top(); // 2
s.pop(); // 3
do_something(value);
}
以上是单线程安全代码:
- 对一个空栈使用top()是未定义行为。对于共享的栈对象,这样的调用顺序就不再安全了,因为在调用empty()①和调用top()②之间,可能有来自另一个线程的pop()调用并删除了最后一个元素。这是一个经典的条件竞争,使用互斥量对栈内部数据进行保护,但依旧不能阻止条件竞争的发生,这就是接口固有的问题。
怎么解决呢?
- 问题发生在接口设计上,所以解决的方法也就是改变接口设计。
有人会问:怎么改?
- 在这个简单的例子中,当调用top()时,发现栈已经是空的了,那么就抛出异常。
虽然这能直接解决这个问题,但这是一个笨拙的解决方案,这样的话,即使empty()返回false的情况下,你也需要异常捕获机制。本质上,这样的改变会让empty()成为一个多余函数。当仔细的观察过之前的代码段,就会发现另一个潜在的条件竞争在调用top()②和pop()之间。
假设两个线程运行着前面的代码,并且都引用同一个栈对象s。这并非罕见的情况,当为性能而使用线程时,多个线程在不同的数据上执行相同的操作是很平常的,并且共享同一个栈可以将工作分摊给它们。假设,一开始栈中只有两个元素,这时任一线程上的empty()和top()都存在竞争,只需要考虑可能的执行顺序即可。
当栈被一个内部互斥量所保护时,只有一个线程可以调用栈的成员函数,所以调用可以很好地交错,并且do_something()是可以并发运行的。在表3.1中,展示一种可能的执行顺序。
表3.1 一种可能执行顺序
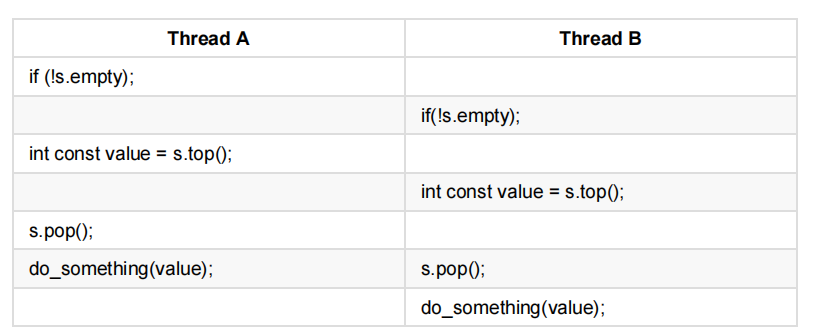
当线程运行时,调用两次top(),栈没被修改,所以每个线程能得到同样的值。不仅是这样,在调用top()函数调用的过程中(两次),pop()函数都没有被调用。这样,在其中一个值再读取的时候,虽然不会出现“写后读”的情况,但其值已被处理了两次。这种条件竞争,比未定义的empty()/top()竞争更加严重;虽然其结果依赖于do_something()的结果,但因为看起来没有任何错误,就会让这个Bug很难定位。
这就需要接口设计上有较大的改动,提议之一就是使用同一互斥量来保护top()和pop()。TomCargill[1]指出当一个对象的拷贝构造函数在栈中抛出一个异常,这样的处理方式就会有问题。
在Herb Sutter[2]看来,这个问题可以从“异常安全”的角度完美解决,不过潜在的条件竞争,可能会组成一些新的组合。
说一些大家没有意识到的问题:假设有一个 stack<vector> ,vector是一个动态容器,当你拷贝一个vetcor,标准库会从堆上分配很多内存来完成这次拷贝。当这个系统处在重度负荷,或有严重的资源限制的情况下,这种内存分配就会失败,所以vector的拷贝构造函数可能会抛出一个 std::bad_alloc 异常。当vector中存有大量元素时,这种情况发生的可能性更大。
当pop()函数返回“弹出值”时(也就是从栈中将这个值移除),会有一个潜在的问题:这个值被返回到调用函数的时候,栈才被改变;但当拷贝数据的时候,调用函数抛出一个异常会怎么样? 如果事情真的发生了,要弹出的数据将会丢失;它的确从栈上移出了,但是拷贝失败了!
std::stack 的设计人员将这个操作分为两部分:先获取顶部元素(top()),然后从栈中移除(pop())。这样,在不能安全的将元素拷贝出去的情况下,栈中的这个数据还依旧存在,没有丢失。当问题是堆空间不足,应用可能会释放一些内存,然后再进行尝试。不幸的是,这样的分割却制造了本想避免或消除的条件竞争。幸运的是,我们还有的别的选项,但是使用这些选项是要付出代价的。
选项1: 传入一个引用
第一个选项是将变量的引用作为参数,传入pop()函数中获取想要的“弹出值”:
std::vector<int> result;
some_stack.pop(result);
大多数情况下,这种方式还不错,但缺点很明显:
- 需要构造出一个栈中类型的实例,用于接收目标值。
对于一些类型,这样做是不现实的,因为临时构造一个实例,从时间和资源的角度上来看,都是不划算。对于其他的类型,这样也不总能行得通,因为构造函数需要的一些参数,在这个阶段的代码不一定可用。最后,需要可赋值的存储类型,这是一个重大限制:
- 即使支持移动构造,甚至是拷贝构造(从而允许返回一个值),很多用户自定义类型可能都不支持赋值操作。
选项2:无异常抛出的拷贝构造函数或移动构造函数
对于有返回值的pop()函数来说,只有“异常安全”方面的担忧(当返回值时可以抛出一个异常)。
很多类型都有拷贝构造函数,它们不会抛出异常,并且随着新标准中对“右值引用”的支持(详见附录A,A.1节),很多类型都将会有一个移动构造函数,即使他们和拷贝构造函数做着相同的事情,它也不会抛出异常。一个有用的选项可以限制对线程安全的栈的使用,并且能让栈安全的返回所需的值,而不会抛出异常。
虽然安全,但非可靠。尽管能在编译时可使用 std::is_nothrow_copy_constructible 和 std::is_nothrow_move_constructible 类型特征,让拷贝或移动构造函数不抛出异常,但是这种方式的局限性太强。用户自定义的类型中,会有不抛出异常的拷贝构造函数或移动构造函数的类型, 那些有抛出异常的拷贝构造函数,但没有移动构造函数的类型往往更多(这种情况会随着人们习惯于C++11中的右值引用而有所改变)。如果这些类型不能被存储在线程安全的栈中,那将是多么的不幸。
选项3:返回指向弹出值的指针
第三个选择是返回一个指向弹出元素的指针,而不是直接返回值。指针的优势是自由拷贝,并且不会产生异常,这样你就能避免Cargill提到的异常问题了。缺点就是返回一个指针需要对对象的内存分配进行管理,对于简单数据类型(比如:int),内存管理的开销要远大于直接返回值。对于选择这个方案的接口,使用 std::shared_ptr 是个不错的选择;不仅能避免内存泄露(因为当对象中指针销毁时,对象也会被销毁),而且标准库能够完全控制内存分配方案,也就不需要new和delete操作。这种优化是很重要的:因为堆栈中的每个对象,都需要用new进行独立的内存分配,相较于非线程安全版本,这个方案的开销相当大。
选项4:“选项1 + 选项2”或 “选项1 + 选项3”
对于通用的代码来说,灵活性不应忽视。当你已经选择了选项2或3时,再去选择1也是很容易的。这些选项提供给用户,让用户自己选择对于他们自己来说最合适,最经济的方案。
例:定义线程安全的堆栈
清单3.4中是一个接口没有条件竞争的堆栈类定义,它实现了选项1和选项3:重载了pop(),使用一个局部引用去存储弹出值,并返回一个 std::shared_ptr<> 对象。它有一个简单的接口,只有两个函数:push()和pop();
清单3.4 线程安全的堆栈类定义(概述)
#include <exception>
#include <memory> // For std::shared_ptr<>
struct empty_stack: std::exception
{
const char* what() const throw();
};
template<typename T>
class threadsafe_stack
{
public:
threadsafe_stack();
threadsafe_stack(const threadsafe_stack&);
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
// 1 赋值操作被删除
void push(T new_value);
std::shared_ptr<T> pop();
void pop(T& value);
bool empty() const;
};
削减接口可以获得最大程度的安全,甚至限制对栈的一些操作。栈是不能直接赋值的,因为赋值操作已经删除了①(详见附录A,A.2节),并且这里没有swap()函数。栈可以拷贝的,假设栈中的元素可以拷贝。当栈为空时,pop()函数会抛出一个empty_stack异常,所以在empty()函数被调用后,其他部件还能正常工作。如选项3描述的那样,使用 std::shared_ptr 可以避免内存分配管理的问题,并避免多次使用new和delete操作。堆栈中的五个操作,现在就剩下三个:
- push(), pop()和empty()(这里empty()都有些多余)。
简化接口更有利于数据控制,可以保证互斥量将一个操作完全锁住。下面的代码将展示一个简单的实现——封装 std::stack<> 的线程安全堆栈。
清单3.5 扩充(线程安全)堆栈
#include <exception>
#include <memory>
#include <mutex>
#include <stack>
struct empty_stack: std::exception
{
const char* what() const throw() {
return "empty stack!";
};
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack()
: data(std::stack<T>()){}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data; // 1 在构造函数体中的执行拷贝
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack(); // 在调用pop前,检查栈是否
为空
std::shared_ptr<T> const res(std::make_shared<T>
(data.top())); // 在修改堆栈前,分配出返回值
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
value=data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
堆栈可以拷贝——拷贝构造函数对互斥量上锁,再拷贝堆栈。构造函数体中①的拷贝使用互斥量来确保复制结果的正确性,这样的方式比成员初始化列表好。
之前对top()和pop()函数的讨论中,恶性条件竞争已经出现,因为锁的粒度太小,需要保护的操作并未全覆盖到。不过,锁住的颗粒过大同样会有问题。还有一个问题,一个全局互斥量要去保护全部共享数据,在一个系统中存在有大量的共享数据时,因为线程可以强制运行,甚至可以访问不同位置的数据,抵消了并发带来的性能提升。第一版为多处理器系统设计Linux内核中,就使用了一个全局内核锁。虽然这个锁能正常工作,但在双核处理系统的上的性能要比两个单核系统的性能差很多,四核系统就更不能提了。太多请求去竞争占用内核,使得依赖于处理器运行的线程没有办法很好的工作。随后修正的Linux内核加入了一个细粒度锁方案,因为少了很多内核竞争,这时四核处理系统的性能就和单核处理的四倍差不多了。
使用多个互斥量保护所有的数据,细粒度锁也有问题。如前所述,当增大互斥量覆盖数据的粒度时,只需要锁住一个互斥量。但是,这种方案并非放之四海皆准,比如:互斥量正在保护一个独立类的实例;这种情况下,锁的状态的下一个阶段,不是离开锁定区域将锁定区域还给用户,就是有独立的互斥量去保护这个类的全部实例。当然,这两种方式都不理想。
一个给定操作需要两个或两个以上的互斥量时,另一个潜在的问题将出现:死锁。与条件竞争完全相反——不同的两个线程会互相等待,从而什么都没做。
3.2.4 死锁:问题描述及解决方案
试想有一个玩具,这个玩具由两部分组成,必须拿到这两个部分,才能够玩。
例如,一个玩具鼓,需要一个鼓锤和一个鼓才能玩。现在有两个小孩,他们都很喜欢玩这个玩具。当其中一个孩子拿到了鼓和鼓锤时,那就可以尽情的玩耍了。当另一孩子想要玩,他就得等待另一孩子玩完才行。再试想,鼓和鼓锤被放在不同的玩具箱里,并且两个孩子在同一时间里都想要去敲鼓。之后,他们就去玩具箱里面找这个鼓。其中一个找到了鼓,并且另外一个找到了鼓锤。现在问题就来了,除非其中一个孩子决定让另一个先玩,他可以把自己的那部分给另外一个孩子;但当他们都紧握着自己所有的部分而不给予,那么这个鼓谁都没法玩。
现在没有孩子去争抢玩具,但线程有对锁的竞争:一对线程需要对他们所有的互斥量做一些操作,其中每个线程都有一个互斥量,且等待另一个解锁。这样没有线程能工作,因为他们都在等待对方释放互斥量。这种情况就是死锁,它的最大问题就是由两个或两个以上的互斥量来锁定一个操作。
避免死锁的一般建议,就是让两个互斥量总以相同的顺序上锁:总在互斥量B之前锁住互斥量A,就永远不会死锁。某些情况下是可以这样用,因为不同的互斥量用于不同的地方。不过,事情没那么简单,比如:当有多个互斥量保护同一个类的独立实例时,一个操作对同一个类的两个不同实例进行数据的交换操作,为了保证数据交换操作的正确性,就要避免数据被并发修改,并确保每个实例上的互斥量都能锁住自己要保护的区域。不过,选择一个固定的顺序(例如,实例提供的第一互斥量作为第一个参数,提供的第二个互斥量为第二个参数),可能会适得其反:在参数交换了之后,两个线程试图在相同的两个实例间进行数据交换时,程序又死锁了!
很幸运,C++标准库有办法解决这个问题, std::lock ——可以一次性锁住多个(两个以上)的互斥量,并且没有副作用(死锁风险)。下面的程序清单中,就来看一下怎么在一个简单的交换操作中使用 std::lock 。
清单3.6 交换操作中使用 std::lock() 和 std::lock_guard
// 这里的std::lock()需要包含<mutex>头文件
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::lock(lhs.m,rhs.m); // 1
std::lock_guard<std::mutex> lock_a(lhs.m,std::adopt_lock);
// 2
std::lock_guard<std::mutex> lock_b(rhs.m,std::adopt_lock);
// 3
swap(lhs.some_detail,rhs.some_detail);
}
};
首先,检查参数是否是不同的实例,因为操作试图获取 std::mutex 对象上的锁,所以当其被获取时,结果很难预料。(一个互斥量可以在同一线程上多次上锁,标准库中 std::recursive_mutex 提供这样的功能。详情见3.3.3节)。然后,调用 std::lock() ①锁住两个互斥量,并且两个 std:lock_guard 实例已经创建好②③。提供 std::adopt_lock 参数除了表示 std::lock_guard 对象可获取锁之外,还将锁交由 std::lock_guard 对象管理,而不需要 std::lock_guard 对象再去构建新的锁。
这样,就能保证在大多数情况下,函数退出时互斥量能被正确的解锁(保护操作可能会抛出一个异常),也允许使用一个简单的“return”作为返回。还有,当使用 std::lock 去锁lhs.m或rhs.m时,可能会抛出异常;这种情况下,异常会传播到 std::lock 之外。当 std::lock 成功的获取一个互斥量上的锁,并且当其尝试从另一个互斥量上再获取锁时,就会有异常抛出,第一个锁也会随着异常的产生而自动释放,所以 std::lock 要么将两个锁都锁住,要不一个都不锁。
C++17对这种情况提供了支持, std::scoped_lock<> 一种新的RAII类型模板类型,
与 std::lock_guard<> 的功能等价,这个新类型能接受不定数量的互斥量类型作为模板参数,以及相应的互斥量(数量和类型)作为构造参数。互斥量支持构造即上锁,与 std::lock 的用法相同,其解锁阶段是在析构中进行。清单3.6中swap()操作可以重写如下:
void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::scoped_lock guard(lhs.m,rhs.m); // 1
swap(lhs.some_detail,rhs.some_detail);
}
这里使用了C++17的另一个特性:自动推导模板参数。如果你手头上有支持C++17的编译器(那你就能使用 std::scoped_lock 了,因为其是C++17标准库中的一个工具),C++17可以通过隐式参数模板类型推导机制, 通过传递的对形象类型来构造实例①。这行代码等价于下面参数全给的版本:
std::scoped_lock<std::mutex,std::mutex> guard(lhs.m,rhs.m);
std::scoped_lock 的好处在于,可以将所有 std::lock 替换掉,从而减少潜在错误的发生。
虽然 std::lock (和 std::scoped_lock<> )可以在这情况下(获取两个以上的锁)避免死锁,但它没办法帮助你获取其中一个锁。这时,依赖于开发者的纪律性(译者:也就是经验),来确保你的程序不会死锁。这并不简单:死锁是多线程编程中一个令人相当头痛的问题,并且死锁经常是不可预见的,因为在大多数时间里,所有工作都能很好的完成。不过,一些相对简单的规则能帮助写出“无死锁”的代码。
3.2.5 避免死锁的进阶指导
死锁通常是由于对锁的不当操作造成,但也不排除死锁出现在其他地方。无锁的情况下,仅需要每个 std::thread 对象调用join(),两个线程就能产生死锁。这种情况下,没有线程可以继续运行,因为他们正在互相等待。这种情况很常见,一个线程会等待另一个线程,其他线程同时也会等待第一个线程结束,所以三个或更多线程的互相等待也会发生死锁。为了避免死锁,这里的指导意见为:当机会来临时,不要拱手让人。以下提供一些个人的指导建议,如何识别死锁,并消除其他线程的等待。
避免嵌套锁
第一个建议往往是最简单的:
- 一个线程已获得一个锁时,再别去获取第二个。因为每个线程只持有一个锁,锁上就不会产生死锁。即使互斥锁造成死锁的最常见原因,也可能会在其他方面受到死锁的困扰(比如:线程间的互相等待)。当你需要获取多个锁,使用一
个 std::lock 来做这件事(对获取锁的操作上锁),避免产生死锁。避免在持有锁时调用用户提供的代码
第二个建议是次简单的:
- 因为代码是用户提供的,你没有办法确定用户要做什么;用户程序可能做任何事情,包括获取锁。你在持有锁的情况下,调用用户提供的代码;如果用户代码要获取一个锁,就会违反第一个指导意见,并造成死锁(有时,这是无法避免的)。当你正在写一份通用代码,例如3.2.3中的栈,每一个操作的参数类型,都在用户提供的代码中定义,就需要其他指导意见来帮助你。
使用固定顺序获取锁
当硬性条件要求你获取两个或两个以上的锁,并且不能使用 std::lock 单独操作来获取它
们;那么最好在每个线程上,用固定的顺序获取它们(锁)。3.2.4节中提到,当需要获取两个互斥量时,避免死锁的方法,关键是如何在线程之间,以一定的顺序获取锁。一些情况下,这种方式相对简单。比如,3.2.3节中的栈——每个栈实例中都内置有互斥量,但是对数据成员存储的操作上,栈就需要调用用户提供的代码。虽然,可以添加一些约束,对栈上存储的数据项不做任何操作,对数据项的处理仅限于栈自身。这会给用户提供的栈增加一些负担,但是一个容器很少去访问另一个容器中存储的数据,即使发生了也会很明显,所以这对于通用栈来说并不是一个特别沉重的负担。
其他情况下,这就没那么简单了,例如:3.2.4节中的交换操作,这种情况下你可能同时锁住多个互斥量(有时不会发生)。回看3.1节中那个链表连接例子时,会看到列表中的每个节点都会有一个互斥量保护。为了访问列表,线程必须获取他们感兴趣节点上的互斥锁。当一个线程删除一个节点,它必须获取三个节点上的互斥锁:将要删除的节点,两个邻接节点(因为他们也会被修改)。同样的,为了遍历链表,线程必须保证在获取当前节点的互斥锁前提下,获得下一个节点的锁,要保证指向下一个节点的指针不会同时被修改。一旦下一个节点上的锁被获取,那么第一个节点的锁就可以释放了,因为没有持有它的必要性了。
这种“手递手”锁的模式允许多个线程访问列表,为每一个访问的线程提供不同的节点。但是,为了避免死锁,节点必须以同样的顺序上锁:如果两个线程试图用互为反向的顺序,使用“手递手”锁遍历列表,他们将执行到列表中间部分时,发生死锁。当节点A和B在列表中相邻,当前线程可能会同时尝试获取A和B上的锁。另一个线程可能已经获取了节点B上的锁,并且试图获取节点A上的锁——经典的死锁场景,如图3.2所示。
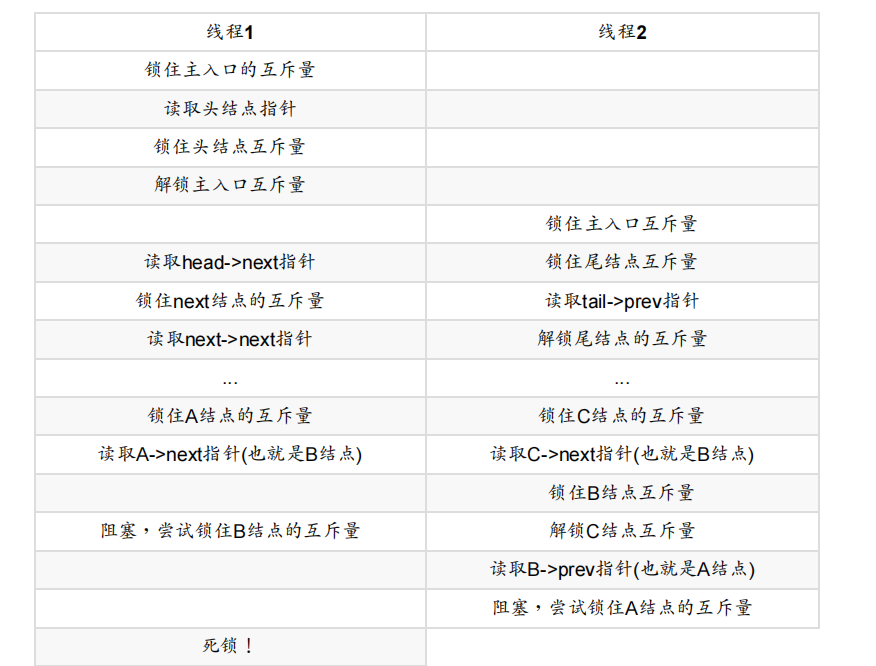
图3.2 不同线程以相反顺序访问列表所造成的死锁
当A、C节点中的B节点正在被删除时,如果有线程在已获取A和C上的锁后,还要获取B节点上的锁时,当一个线程遍历列表的时候,这样的情况就可能发生死锁。这样的线程可能会试图首先锁住A节点或C节点(根据遍历的方向),但是后面就会发现,它无法获得B上的锁,因为线程在执行删除任务的时候,已经获取了B上的锁,并且同时也获取了A和C上的锁。
这里提供一种避免死锁的方式,定义遍历的顺序,一个线程必须先锁住A才能获取B的锁,在锁住B之后才能获取C的锁。这将消除死锁发生的可能性,不允许反向遍历的列表上。类似的约定常被用来建立其他的数据结构。
使用锁的层次结构
虽然,定义锁的顺序是一种特殊情况,但锁的层次的意义在于提供对运行时约定是否被坚持的检查。这个建议需要对你的应用进行分层,并且识别在给定层上所有可上锁的互斥量。当代码试图对一个互斥量上锁,在该层锁已被低层持有时,上锁是不允许的。你可以在运行时对其进行检查,通过分配层数到每个互斥量上,以及记录被每个线程上锁的互斥量。下面的代码列表中将展示两个线程如何使用分层互斥。
清单3.7 使用层次锁来避免死锁
hierarchical_mutex high_level_mutex(10000); // 1
hierarchical_mutex low_level_mutex(5000); // 2
hierarchical_mutex other_mutex(6000); // 3
int do_low_level_stuff();
int low_level_func()
{
std::lock_guard<hierarchical_mutex> lk(low_level_mutex); // 4
return do_low_level_stuff();
}
void high_level_stuff(int some_param);
void high_level_func()
{
std::lock_guard<hierarchical_mutex> lk(high_level_mutex); // 6
high_level_stuff(low_level_func()); // 5
}
void thread_a() // 7
{
high_level_func();
}
void do_other_stuff();
void other_stuff()
{
high_level_func(); // 10
do_other_stuff();
}
void thread_b() // 8
{
std::lock_guard<hierarchical_mutex> lk(other_mutex); // 9
other_stuff();
}
这段代码有三个hierarchical_mutex实例(①,②和③),其通过逐渐递减的层级数量进行构造。
根据已经定义好的机制,如你已将一个hierarchical_mutex实例进行上锁,那么你只能获取更低层级hierarchical_mutex实例上的锁,这就会对代码进行一些限制。
假设do_low_level_stuff不会对任何互斥量进行上锁,low_level_func为层级最低的函数,并且会对low_level_mutex④进行上锁。high_level_func调用low_level_func⑤的同时,也持有high_level_mutex⑥上的锁,这也没什么问题,因为high_level_mutex(①:10000)要比low_level_mutex(②:5000)更高级。
thread_a()⑦遵守规则,所以它运行的没问题。
另一方面,thread_b()⑧无视规则,因此在运行的时候肯定会失败。
首先,thread_b锁住了other_mutex⑨,这个互斥量的层级值只有6000③。这就意味着,中层级的数据已被保护。当other_stuff()调用high_level_func()⑧时,就违反了层级结构:
high_level_func()试图获取high_level_mutex,这个互斥量的层级值是10000,要比当前层级值6000大很多。因此hierarchical_mutex将会产生一个错误,可能会是抛出一个异常,或直接终止程序。在层级互斥量上产生死锁,是不可能的,因为互斥量本身会严格遵循约定顺序,进行上锁。这也意味,当多个互斥量在是在同一级上时,不能同时持有多个锁,所以“手递手”锁的方案需要每个互斥量在一条链上,并且每个互斥量都比其前一个有更低的层级值,这在某些情况下无法实现。
例子也展示了另一点, std::lock_guard<> 模板与用户定义的互斥量类型一起使用。虽然
hierarchical_mutex不是C++标准的一部分,但是它写起来很容易;一个简单的实现在列表3.8中展示出来。尽管它是一个用户定义类型,它可以用于 std::lock_guard<> 模板中,因为它的实现有三个成员函数为了满足互斥量操作:lock(), unlock() 和 try_lock()。虽然你还没见过try_lock()怎么使用,但是其使用起来很简单:当互斥量上的锁被一个线程持有,它将返回false,而不是等待调用的线程,直到能够获取互斥量上的锁为止。在 std::lock() 的内部实现中,try_lock()会作为避免死锁算法的一部分。列表3.8 简单的层级互斥量实现
class hierarchical_mutex
{
std::mutex internal_mutex;
unsigned long const hierarchy_value;
unsigned long previous_hierarchy_value;
static thread_local unsigned long this_thread_hierarchy_value;
// 1
void check_for_hierarchy_violation()
{
if(this_thread_hierarchy_value <= hierarchy_value) // 2
{
throw std::logic_error(“mutex hierarchy violated”);
}
}
void update_hierarchy_value()
{
previous_hierarchy_value=this_thread_hierarchy_value; // 3
this_thread_hierarchy_value=hierarchy_value;
}
public:
explicit hierarchical_mutex(unsigned long value):
hierarchy_value(value),
previous_hierarchy_value(0)
{}
void lock()
{
check_for_hierarchy_violation();
internal_mutex.lock(); // 4
update_hierarchy_value(); // 5
}
void unlock()
{
if(this_thread_hierarchy_value!=hierarchy_value)
throw std::logic_error(“mutex hierarchy violated”); // 9
this_thread_hierarchy_value=previous_hierarchy_value; // 6
internal_mutex.unlock();
}
bool try_lock()
{
check_for_hierarchy_violation();
if(!internal_mutex.try_lock()) // 7
return false;
update_hierarchy_value();
return true;
}
};
thread_local unsigned long
hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX);
// 8
这里重点是使用了thread_local的值来代表当前线程的层级值:
- this_thread_hierarchy_value①。它被初始化为最大值⑧,所以最初所有线程都能被锁住。因为其声明中有thread_local,所以每个线程都有其拷贝副本,这样线程中变量状态完全独立,当从另一个线程进行读取时,变量的状态也完全独立。参见附录A,A.8节,有更多与thread_local相关的内容。
所以,第一次线程锁住一个hierarchical_mutex时,this_thread_hierarchy_value的值是
ULONG_MAX。由于其本身的性质,这个值会大于其他任何值,所以会通过
check_for_hierarchy_vilation()②的检查。在这种检查方式下,lock()代表内部互斥锁已被锁住④。一旦成功锁住,你可以更新层级值了⑤。
当你现在锁住另一个hierarchical_mutex时,还持有第一个锁,this_thread_hierarchy_value的值将会显示第一个互斥量的层级值。第二个互斥量的层级值必须小于已经持有互斥量检查函数②才能通过。
现在,最重要的是为当前线程存储之前的层级值,所以你可以调用unlock()⑥对层级值进行保存;否则,就锁不住任何互斥量(第二个互斥量的层级数高于第一个互斥量),即使线程没有持有任何锁。因为保存了之前的层级值,只有当持有internal_mutex③,且在解锁内部互斥量⑥之前存储它的层级值,才能安全的将hierarchical_mutex自身进行存储。这是因为
hierarchical_mutex被内部互斥量的锁所保护着。为了避免无序解锁造成层次结构混乱,当解锁的互斥量不是最近上锁的那个互斥量,就需要抛出异常⑨。其他机制也能做到这点,但目前这个是最简单的。
try_lock()与lock()的功能相似,除了在调用internal_mutex的try_lock()⑦失败时,不能持有对应锁,所以不必更新层级值,并直接返回false。
虽然是运行时检测,但是它没有时间依赖性——不必去等待导致死锁出现的罕见条件。同
时,设计过程需要去拆分应用,互斥量在这种情况下可以消除导致死锁的可能性。这样的练习很有必要去做一下,即使你之后没有去做,代码也会在运行时进行检查。
超越锁的延伸扩展如我在本节开头提到的那样,死锁不仅仅会发生在锁之间;死锁也会发生在任何同步构造中(可能会产生一个等待循环),因此这方面也需要有指导意见,例如:要去避免获取嵌套锁等待一个持有锁的线程是一个很糟糕的决定,因为线程为了能继续运行可能需要获取对应的锁。
类似的,如果去等待一个线程结束,它应该可以确定这个线程的层级,这样一个线程只需要等待比其层级低的线程结束即可。用一个简单的办法便可确定,以添加的线程是否在同一函数中被启动,如同在3.1.2节和3.3节中描述的那样。
代码已能规避死锁, std::lock() 和 std::lock_guard 可组成简单的锁,并覆盖大多数情况,但是有时需要更多的灵活性。在这种情况下,可以使用标准库提供的 std::unique_lock 模
板。
如 std::lock_guard ,这是一个参数化的互斥量模板类,并且它提供很多RAII类型锁用来管理 std::lock_guard 类型,可以让代码更加灵活。
3.2.6 std::unique_lock——灵活的锁
std::unqiue_lock 使用更为自由的不变量,这样 std::unique_lock 实例不会总与互斥量的数据类型相关,使用起来要比 std:lock_guard 更加灵活。首先,可将 std::adopt_lock 作为第二个参数传入构造函数,对互斥量进行管理;也可以将 std::defer_lock 作为第二个参数传递进去,表明互斥量应保持解锁状态。这样,就可以被 std::unique_lock 对象(不是互斥量)的
lock()函数所获取,或传递 std::unique_lock 对象到 std::lock() 中。清单3.6可以轻易的转换为清单3.9,使用 std::unique_lock 和 std::defer_lock ①,而
非 std::lock_guard 和 std::adopt_lock 。代码长度相同,几乎等价,唯一不同的就
是: std::unique_lock 会占用比较多的空间,并且比 std::lock_guard 稍慢一些。保证灵活性要付出代价,这个代价就是允许 std::unique_lock 实例不带互斥量:信息已被存储,且已被更新。
清单3.9 交换操作中 std::lock() 和 std::unique_lock 的使用
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::unique_lock<std::mutex> lock_a(lhs.m,std::defer_lock);
// 1
std::unique_lock<std::mutex> lock_b(rhs.m,std::defer_lock);
// 1 std::defer_lock 留下未上锁的互斥量
std::lock(lock_a,lock_b); // 2 互斥量在这里上锁
swap(lhs.some_detail,rhs.some_detail);
}
};
列表3.9中,因为 std::unique_lock 支持lock(), try_lock()和unlock()成员函数,所以能
将 std::unique_lock 对象传递到 std::lock() ②。这些同名的成员函数在低层做着实际的工
作,并且仅更新 std::unique_lock 实例中的标志,来确定该实例是否拥有特定的互斥量,这个标志是为了确保unlock()在析构函数中被正确调用。如果实例拥有互斥量,那么析构函数必须调用unlock();但当实例中没有互斥量时,析构函数就不能去调用unlock()。这个标志可以通过owns_lock()成员变量进行查询。除非你想将 std::unique_lock 的所有权进行转让,或是对其做一些其他的事情外,你最好使用C++17中提供的 std::scoped_lock (详见3.2.4节)。
如你期望的那样,这个标志被存储在某个地方。因此, std::unique_lock 对象的体积通常要比 std::lock_guard 对象大,当使用 std::unique_lock 替代 std::lock_guard ,因为会对标志进行适当的更新或检查,就会做些轻微的性能惩罚。当 std::lock_guard 已经能够满足你的需求时,还是建议你继续使用它。当需要更加灵活的锁时,最好选择 std::unique_lock ,因为它更适合于你的任务。你已经看到一个递延锁的例子,另外一种情况是锁的所有权需要从一个域转到另一个域。
3.2.7 不同域中互斥量所有权的传递
std::unique_lock 实例没有与自身相关的互斥量,一个互斥量的所有权可以通过移动操作,在不同的实例中进行传递。某些情况下,这种转移是自动发生的,例如:当函数返回一个实例;另些情况下,需要显式的调用 std::move() 来执行移动操作。从本质上来说,需要依赖于源值是否是左值——一个实际的值或是引用——或一个右值——一个临时类型。当源值是一个右值,为了避免转移所有权过程出错,就必须显式移动成左值。 std::unique_lock 是可移动,但不可赋值的类型。附录A,A.1.1节有更多与移动语句相关的信息。
一种使用可能是允许一个函数去锁住一个互斥量,并且将所有权移到调用者上,所以调用者可以在这个锁保护的范围内执行额外的动作。
下面的程序片段展示了:函数get_lock()锁住了互斥量,然后准备数据,返回锁的调用函数。
std::unique_lock<std::mutex> get_lock()
{
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk; // 1
}
void process_data()
{
std::unique_lock<std::mutex> lk(get_lock()); // 2
do_something();
}
lk在函数中被声明为自动变量,它不需要调用 std::move() ,可以直接返回①(编译器负责调用移动构造函数)。process_data()函数直接转移 std::unique_lock 实例的所有权②,调用do_something()可使用的正确数据(数据没有受到其他线程的修改)。
通常这种模式会用于已锁的互斥量,其依赖于当前程序的状态,或依赖于传入返回类型
为 std::unique_lock 的函数(或以参数返回)。这样不会直接返回锁,不过网关类的一个数据成员可用来确认已经对保护数据的访问权限进行上锁。这种情况下,所有的访问都必须通过网关类:当你想要访问数据,需要获取网关类的实例(如同前面的例子,通过调用get_lock()之类函数)来获取锁。之后你就可以通过网关类的成员函数对数据进行访问。当完成访问,可以销毁这个网关类对象,将锁进行释放,让别的线程来访问保护数据。这样的一个网关类可能是可移动的(所以他可以从一个函数进行返回),这种情况下锁对象的数据必须可移动。
std::unique_lock 的灵活性同样也允许实例在销毁之前放弃其拥有的锁。可以使用unlock()来做这件事,如同一个互斥量: std::unique_lock 的成员函数提供类似于锁定和解锁互斥量的功能。 std::unique_lock 实例在销毁前释放锁的能力,当锁没有必要在持有的时候,可以在特定的代码分支对其进行选择性的释放。这对于应用性能来说很重要,因为持有锁的时间增加会导致性能下降,其他线程会等待这个锁的释放,避免超越操作。
3.2.8 锁的粒度
3.2.3节中,已经对锁的粒度有所了解:锁的粒度是一个摆手术语(hand-waving term),用来描述通过一个锁保护着的数据量大小。一个细粒度锁(a fine-grained lock)能够保护较小的数据量,一个粗粒度锁(a coarse-grained lock)能够保护较多的数据量。选择粒度对于锁来说很重要,为了保护对应的数据,保证锁有能力保护这些数据也很重要。我们都知道,在超市等待结账的时候,正在结账的顾客突然意识到他忘了拿蔓越莓酱,然后离开柜台去拿,并让其他的人都等待他回来;或者当收银员,准备收钱时,顾客才去翻钱包拿钱,这样的情况都会让等待的顾客很无奈。当每个人都检查了自己要拿的东西,且能随时为拿到的商品进行支付,那么的每件事都会进行的很顺利。
道理同样适用于线程:如果很多线程正在等待同一个资源(等待收银员对自己拿到的商品进行清点),当有线程持有锁的时间过长,这就会增加等待的时间(别等到结账的时候,才想起来蔓越莓酱没拿)。可能的情况下,锁住互斥量的同时只能对共享数据进行访问;试图对锁外数据进行处理。特别是做一些费时的动作,比如:对文件的输入/输出操作进行上锁。文件输入/输出通常要比从内存中读或写同样长度的数据慢成百上千倍,所以除非锁已经打算去保护对文件的访问,要么执行输入/输出操作将会将延迟其他线程执行的时间,这没有必要(因为文件锁阻塞住了很多操作),这样多线程带来的性能效益会被抵消。
std::unique_lock 在这种情况下工作正常,调用unlock()时,代码不需要再访问共享数据;而后当再次需要对共享数据进行访问时,就可以再调用lock()了。下面代码就是这样的一种情况:
void get_and_process_data()
{
std::unique_lock<std::mutex> my_lock(the_mutex);
some_class data_to_process=get_next_data_chunk();
my_lock.unlock(); // 1 不要让锁住的互斥量越过process()函数的调用
result_type result=process(data_to_process);
my_lock.lock(); // 2 为了写入数据,对互斥量再次上锁
write_result(data_to_process,result);
}
不需要让锁住的互斥量越过对process()函数的调用,所以可以在函数调用①前对互斥量手动解锁,并且在之后对其再次上锁②。
这能表示只有一个互斥量保护整个数据结构时的情况,不仅会有更多对锁的竞争,也会增加持锁的时间。较多的操作步骤需要获取同一个互斥量上的锁,所以持有锁的时间会更长。成本上的双重打击也算是为向细粒度锁转移提供了双重激励和可能。
如同上面的例子,锁不仅是能锁住合适粒度的数据,还要控制锁的持有时间,以及哪些操作在执行的同时能够拥有锁。一般情况下,执行必要的操作时,尽可能将持有锁的时间缩减到最小。
这也就意味有一些浪费时间的操作,比如:获取另外一个锁(即使你知道这不会造成死锁),或等待输入/输出操作完成时没有必要持有一个锁(除非绝对需要)。
清单3.6和3.9中,交换操作需要锁住两个互斥量,其明确要求并发访问两个对象。假设用来做比较的是一个简单的数据类型(比如:int类型),将会有什么不同么?int的拷贝很廉价,所以可以很容易的进行数据复制,并且每个被比较的对象都持有该对象的锁,在比较之后进行数据拷贝。这就意味着,在最短时间内持有每个互斥量,并且你不会在持有一个锁的同时再去获取另一个。下面的清单中展示了一个在这样情景中的Y类,并且展示了一个相等比较运算符的等价实现。
列表3.10 比较操作符中一次锁住一个互斥量
class Y
{
private:
int some_detail;
mutable std::mutex m;
int get_detail() const
{
std::lock_guard<std::mutex> lock_a(m); // 1
return some_detail;
}
public:
Y(int sd):some_detail(sd){}
friend bool operator==(Y const& lhs, Y const& rhs)
{
if(&lhs==&rhs)
return true;
int const lhs_value=lhs.get_detail(); // 2
int const rhs_value=rhs.get_detail(); // 3
return lhs_value==rhs_value; // 4
}
};
例子中,比较操作符首先通过调用get_detail()成员函数检索要比较的值②③,函数在索引值时被一个锁保护着①。比较操作符会在之后比较索引出来的值④。注意:虽然这样能减少锁持有的时间,一个锁只持有一次(这样能消除死锁的可能性),这里有一个微妙的语义操作同时对两个锁住的值进行比较。
列表3.10中,当操作符返回true时,那就意味着在这个时间点上的lhs.some_detail与在另一个时间点的rhs.some_detail相同。这两个值在读取之后,可能会被任意的方式所修改;两个值会在②和③处进行交换,这样就会失去比较的意义。等价比较可能会返回true,来表明这两个值时相等的,实际上这两个值相等的情况可能就发生在一瞬间。这样的变化要小心,语义操作是无法改变一个问题的比较方式:当你持有锁的时间没有达到整个操作时间,就会让自己处于条件竞争的状态。
有时,没有一个合适粒度级别,因为并不是所有对数据结构的访问都需要同一级的保护。这个例子中,就需要寻找一个合适的机制,去替换 std::mutex 。
[1] Tom Cargill, “Exception Handling: A False Sense of Security,” in C++ Report 6, no. 9
(November–December 1994). Also available at
http://www.informit.com/content/images/020163371x/supplements/Exception_Handling_Artic
le.html.
[2] Herb Sutter, Exceptional C++: 47 Engineering Puzzles, Programming Problems, and
Solutions (Addison Wesley Pro-fessional, 1999).
3.3 保护共享数据的其他方式
互斥量一种通用的机制,但其并非保护共享数据的唯一方式。有很多替代方式可以在特定情况下,对共享数据提供更加合适的保护。
一个特别极端(但十分常见)的情况就是,共享数据在并发访问和初始化时(都需要保护),但是之后需要进行隐式同步。这可能是因为数据作为只读方式创建,所以没有同步问题;或者因为必要的保护作为对数据操作的一部分。任何情况下,数据初始化后锁住一个互斥量,纯粹是为了保护其初始化过程(这是没有必要的),并且会给性能带来不必要的冲击。出于以上的原因,C++标准提供了一种纯粹保护共享数据初始化过程的机制。
3.3.1 保护共享数据的初始化过程
假设你有一个共享源,构建代价很昂贵,它可能会打开一个数据库连接或分配出很多的内
存。
延迟初始化(Lazy initialization)在单线程代码很常见——每一个操作都需要先对源进行检查,为了了解数据是否被初始化,然后在其使用前决定,数据是否需要初始化:
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // 1
}
resource_ptr->do_something();
}
转为多线程代码时,只有①处需要保护,这样共享数据对于并发访问就是安全的,但是下面天真的转换会使得线程资源产生不必要的序列化。为了确定数据源已经初始化,每个线程必须等待互斥量。
清单 3.11 使用一个互斥量的延迟初始化(线程安全)过程
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex); // 所有线程在
此序列化
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // 只有初始化过程需要保
护
}
lk.unlock();
resource_ptr->do_something();
}
这段代码相当常见了,也足够表现出没必要的线程化问题,很多人能想出更好的一些的办法来做这件事,包括声名狼藉的“双重检查锁模式”:
void undefined_behaviour_with_double_checked_locking()
{
if(!resource_ptr) // 1
{
std::lock_guard<std::mutex> lk(resource_mutex);
if(!resource_ptr) // 2
{
resource_ptr.reset(new some_resource); // 3
}
}
resource_ptr->do_something(); // 4
}
指针第一次读取数据不需要获取锁①,并且只有在指针为NULL时才需要获取锁。然后,当获取锁之后,指针会被再次检查一遍② (这就是双重检查的部分),避免另一的线程在第一次检查后再做初始化,并且让当前线程获取锁。
这个模式为什么声名狼藉呢?因为这里有潜在的条件竞争。未被锁保护的读取操作①没有与其他线程里被锁保护的写入操作③进行同步,因此就会产生条件竞争,这个条件竞争不仅覆盖指针本身,还会影响到其指向的对象;即使一个线程知道另一个线程完成对指针进行写入,它可能没有看到新创建的some_resource实例,然后调用do_something()④后,得到不正确的结果。这个例子是在一种典型的条件竞争——数据竞争,C++标准中这就会被指定为“未定义行为”。这种竞争是可以避免的。阅读第5章时,那里有更多对内存模型的讨论,也包括数据竞争的构成。(译者注:著名的《C++和双重检查锁定模式(DCLP)的风险》可以作为补充材料供大家参考 英文版 中文版)
C++标准委员会也认为条件竞争的处理很重要,所以C++标准库提供
了 std::once_flag 和 std::call_once 来处理这种情况。比起锁住互斥量并显式的检查指针,每个线程只需要使用 std::call_once 就可以,在 std::call_once 的结束时,就能安全的知道指针已经被其他的线程初始化了。使用 std::call_once 比显式使用互斥量消耗的资源更少,特别是当初始化完成后。下面的例子展示了与清单3.11中的同样的操作,这里使用
了 std::call_once 。在这种情况下,初始化通过调用函数完成,这样的操作使用类中的函数操作符来实现同样很简单。如同大多数在标准库中的函数一样,或作为函数被调用,或作为参数被传递, std::call_once 可以和任何函数或可调用对象一起使用。
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; // 1
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag,init_resource); // 可以完整的进行一
次初始化
resource_ptr->do_something();
}
这个例子中, std::once_flag ①和初始化好的数据都是命名空间区域的对象,但 std::call_once() 可仅作为延迟初始化的类型成员,如同下面的例子一样:
清单3.12 使用 std::call_once 作为类成员的延迟初始化(线程安全)
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection=connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_):
connection_details(connection_details_)
{}
void send_data(data_packet const& data) // 1
{
std::call_once(connection_init_flag,&X::open_connection,this);
// 2
connection.send_data(data);
}
data_packet receive_data() // 3
{
std::call_once(connection_init_flag,&X::open_connection,this);
// 2
return connection.receive_data();
}
};
例子中第一次调用send_data()①或receive_data()③的线程完成初始化过程。使用成员函数open_connection()去初始化数据,也需要将this指针传进去。和其在在标准库中的函数一样,其接受可调用对象,比如 std::thread 的构造函数和 std::bind() ,通过向 std::call_once() ②传递一个额外的参数来完成这个操作。
值得注意的是, std::mutex 和 std::once_flag 的实例不能拷贝和移动,需要通过显式定义相应的成员函数,对这些类成员进行操作。
还有一种初始化过程中潜存着条件竞争:其中一个局部变量被声明为static类型,这种变量的在声明后就已经完成初始化;对于多线程调用的函数,这就意味着这里有条件竞争——抢着去定义这个变量。很多在不支持C++11标准的编译器上,在实践过程中,这样的条件竞争是确实存在的,因为在多线程中,每个线程都认为他们是第一个初始化这个变量线程;或一个线程对变量进行初始化,而另外一个线程要使用这个变量时,初始化过程还没完成。在C++11标准中,这些问题都被解决了:初始化及定义完全在一个线程中发生,并且没有其他线程可在初始化完成前对其进行处理,条件竞争终止于初始化阶段,这样比在之后再去处理好的多。
在只需要一个全局实例情况下,这里提供一个 std::call_once 的替代方案
class my_class;
my_class& get_my_class_instance()
{
static my_class instance; // 线程安全的初始化过程
return instance;
}
多线程可以安全的调用get_my_class_instance()①函数,不用为数据竞争而担心。
对于很少有更新的数据结构来说,只在初始化时保护数据。大多数情况下,这种数据结构是只读的,并且多线程对其并发的读取也是很愉快的,不过一旦数据结构需要更新,就会产生竞争。
3.3.2 保护不常更新的数据结构
试想,为了将域名解析为其相关IP地址,我们在缓存中的存放了一张DNS入口表。通常,给定DNS数目在很长的一段时间内保持不变。虽然,在用户访问不同网站时,新的入口可能会被添加到表中,但是这些数据可能在其生命周期内保持不变。所以定期检查缓存中入口的有效性,就变的十分重要了;但是,这也需要一次更新,也许这次更新只是对一些细节做了改动。
虽然更新频度很低,但更新也有可能发生,并且当这个可缓存被多个线程访问,这个缓存就需要处于更新状态时得到保护,这也为了确保每个线程读到都是有效数据。
没有使用专用数据结构时,这种方式是符合预期,并为并发更新和读取特别设计的(更多的例子在第6和第7章中介绍)。这样的更新要求线程独占数据结构的访问权,直到其完成更新操作。
当更新完成,数据结构对于并发多线程访问又会是安全的。使用 std::mutex 来保护数据结构,显的有些反应过度(因为在没有发生修改时,它将削减并发读取数据的可能性)。这里需要另一种不同的互斥量,这种互斥量常被称为“读者-作者锁”,因为其允许两种不同的使用方式:
- 一个“作者”线程独占访问和共享访问,让多个“读者”线程并发访问。
C++17标准库提供了两种非常好的互斥量—— std::shared_mutex 和 std::shared_timed_mutex 。C++14只提供了 std::shared_timed_mutex ,并且在C++11中并未提供任何互斥量类型。如果你还在用支持C++14标准之前的编译器,那你可以使用Boost库中实现的互斥量。 std::shared_mutex 和 std::shared_timed_mutex 的不同点在
于, std::shared_timed_mutex 支持更多的操作方式(参考4.3节), std::shared_mutex 有更高的性能优势,从而不支持更多的操作。
你将在第8章中看到,这种锁的也不能包治百病,其性能依赖于参与其中的处理器数量,同样也与读者和作者线程的负载有关。为了确保增加复杂度后还能获得性能收益,目标系统上的代码性能就很重要。
比起使用 std::mutex 实例进行同步,不如使用 std::shared_mutex 来做同步。对于更新操作,可以使用 std::lock_guardstd::shared_mutex 和 std::unique_lockstd::shared_mutex 上锁。
作为 std::mutex 的替代方案,与 std::mutex 所做的一样,这就能保证更新线程的独占访问。
因为其他线程不需要去修改数据结构,所以其可以使用std::shared_lockstd::shared_mutex 获取访问权。这种RAII类型模板是在C++14中的新特性,这与使用 std::unique_lock 一样,除非多线程要在同时获取同一个 std::shared_mutex 上
有共享锁。唯一的限制:当任一线程拥有一个共享锁时,这个线程就会尝试获取一个独占
锁,直到其他线程放弃他们的锁;同样的,当任一线程拥有一个独占锁时,其他线程就无法获得共享锁或独占锁,直到第一个线程放弃其拥有的锁。
如同之前描述的那样,下面的代码清单展示了一个简单的DNS缓存,使用 std::map 持有缓存数据,使用 std::shared_mutex 进行保护。
清单3.13 使用 std::shared_mutex 对数据结构进行保护
#include <map>
#include <string>
#include <mutex>
#include <shared_mutex>
class dns_entry;
class dns_cache
{
std::map<std::string,dns_entry> entries;
mutable std::shared_mutex entry_mutex;
public:
dns_entry find_entry(std::string const& domain) const
{
std::shared_lock<std::shared_mutex> lk(entry_mutex); // 1
std::map<std::string,dns_entry>::const_iterator const it=
entries.find(domain);
return (it==entries.end())?dns_entry():it->second;
}
void update_or_add_entry(std::string const& domain,
dns_entry const& dns_details)
{
std::lock_guard<std::shared_mutex> lk(entry_mutex); // 2
entries[domain]=dns_details;
}
};
清单3.13中,find_entry()使用 std::shared_lock<> 来保护共享和只读权限①;这就使得多线程可以同时调用find_entry(),且不会出错。另一方面,update_or_add_entry()使用 std::lock_guard<> 实例,当表格需要更新时②,为其提供独占访问权限;
update_or_add_entry()函数调用时,独占锁会阻止其他线程对数据结构进行修改,并且阻止线程调用find_entry()。
3.3.3 嵌套锁
当一个线程已经获取一个 std::mutex 时(已经上锁),并对其再次上锁,这个操作就是错误
的,并且继续尝试这样做的话,就会产生未定义行为。然而,在某些情况下,一个线程尝试获取同一个互斥量多次,而没有对其进行一次释放是可以的。之所以可以,是因为C++标准库提供了 std::recursive_mutex 类。除了可以对同一线程的单个实例上获取多个锁,其他功能与 std::mutex 相同。互斥量锁住其他线程前,必须释放拥有的所有锁,所以当调用lock()三次后,也必须调用unlock()三次。正确使用 std::lock_guardstd::recursive_mutex 和 std::unique_lockstd::recursive_mutex 可以帮你处理这些问题。
大多数情况下,当需要嵌套锁时,就要对代码设计进行改动。嵌套锁一般用在可并发访问的类上,所以使用互斥量保护其成员数据。每个公共成员函数都会对互斥量上锁,然后完成对应的操作后再解锁互斥量。不过,有时成员函数会调用另一个成员函数,这种情况下,第二个成员函数也会试图锁住互斥量,这就会导致未定义行为的发生。“变通的”解决方案会将互斥量转为嵌套锁,第二个成员函数就能成功的进行上锁,并且函数能继续执行。
但是,不推荐这样的使用方式,因为过于草率,并且不合理。特别是,当锁被持有时,对应类的不变量通常正在被修改。这意味着,当不变量正在改变的时候,第二个成员函数还需要继续执行。一个比较好的方式是,从中提取出一个函数作为类的私有成员,并且让其他成员函数都对其进行调用,这个私有成员函数不会对互斥量进行上锁(在调用前必须获得锁)。然后,你仔细考虑一下,在这种情况调用新函数时,数据的状态。
总结
本章讨论了当两个线程间的共享数据发生恶性条件竞争时,将会带来多么严重的灾难,还讨论了如何使用 std::mutex 和如何避免这些问题。如你所见,虽然C++标准库提供了一写工具来避免这些(例如: std::lock() ),互斥量并不是灵丹妙药,也还有自己的问题(比如:死锁)。
还见识了一些用于避免死锁的先进技术,之后了解了锁的所有权转移,以及一些围绕如何选取适当粒度锁产生的问题。最后,在具体情况下讨论了其他数据保护的方案,例如: std::call_once() 和 std::shared_mutex 。
还有一个方面没有涉及到,那就是等待其他线程作为输入的情况。我们的线程安全栈,仅是在栈为空时,抛出一个异常,所以当一个线程要等待其他线程向栈压入一个值时(这是线程安全栈的主要用途之一),它需要多次尝试去弹出一个值,当捕获抛出的异常时,再次进行尝试。
这种消耗资源的检查,没有任何意义。并且,不断的检查会影响系统中其他线程的运
行,这反而会妨碍程序的运行。我们需要一些方法让一个线程等待其他线程完成任务,但在等待过程中不占用CPU。第4章中,会去建立一些保护共享数据的工具,还会介绍一些线程同步的操作机制;第6章中会展示,如何构建更大型的可复用的数据类型。