目录
1.vector的介绍及使用
1.1 vector的介绍
1.2 vector的使用
1.2.1 vector的定义
1.2.2 vector iterator 的使用
1.2.3 vector 空间增长问题
1.2.3 vector 增删查改
1.2.4 vector 迭代器失效问题。(重点)
1.2.5 vector 在OJ中的使用
2.vector深度剖析及模拟实现
使用memcpy拷贝问题
动态二维数组理解
模拟实现vector:
1.vector的介绍及使用
1.1 vector的介绍
1. vector 是表示可变大小数组的序列容器。2. 就像数组一样, vector 也采用的连续存储空间来存储元素。也就是意味着可以采用下标对 vector 的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。3. 本质讲, vector 使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector 并不会每次都重新分配大小。4. vector 分配空间策略: vector 会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。5. 因此, vector 占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。6. 与其它动态序列容器相比( deque, list and forward_list ), vector 在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list 和 forward_list统一的迭代器和引用更好
1.2 vector的使用
1.2.1 vector的定义

以上就是vector的构造函数,重点关注1和3

1.2.2 vector iterator 的使用


我们可以看到这里的iterator行为上就像指针一样,但又不一定是指针 ,而对于vector这里来说,这里的iterator就是一个原生指针,后面会讲到迭代器失效的问题。
1.2.3 vector 空间增长问题

这里的resize和reserve和之前的string的含义一样,这里就看看函数的使用方式即可:
capacity 的代码在 vs 和 g++ 下分别运行会发现, vs下capacity是按1.5倍增长的,g++是按2倍增长的。这个问题经常会考察,不要固化的认为, vector 增容都是 2 倍,具体增长多少是根据具体的需求定义的。 vs是PJ版本STL,g++是SGI版本STL 。( 也就是不同编译器的实现方式不同,所以可能会导致有不同的结果)reserve 只负责开辟空间,如果确定知道需要用多少空间, reserve 可以缓解 vector 增容的代价缺陷问题。resize 在开空间的同时还会进行初始化,影响 size 。


这是vs下的扩容:

reserve的优势就在于如果我们知道要开多少空间,我们就可以一次性开好,就可以避免频繁的扩容,因为我们知道频繁扩容是要付出代价的,所以C++在这方面做的很好。
1.2.3 vector 增删查改

为什么不推荐使用insert以及erase呢?因为我们知道数组删除数据是要挪动数据的,这样就导致花费更多时间,所以一般情况下不推荐使用。
上述内容很简单,查网站就会使用,不过多讲解,下面主要讲解迭代器失效的问题;
1.2.4 vector 迭代器失效问题。(重点)
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。为什么会这样呢?下面我们看几个例子:
#include <iostream>
using namespace std;
#include <vector>
int main()
{
vector<int> v{ 1,2,3,4,5,6 };
auto it = v.begin();
v.assign(100, 3);
//因为这里扩容过,所以迭代器肯定失效
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}结果正如我们所料:

解决这个办法就是更新一下迭代器即可正常使用。
看看其他例子:
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
return 0;
}int main()
{
vector<int> v{ 1, 2, 3, 4 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
return 0;
}不难发现这里肯定是有问题的,因为删除完4之后it又++就已经越界访问了。
我们可以在不是偶数的时候再++,同时更新一下it,是偶数的就不用++
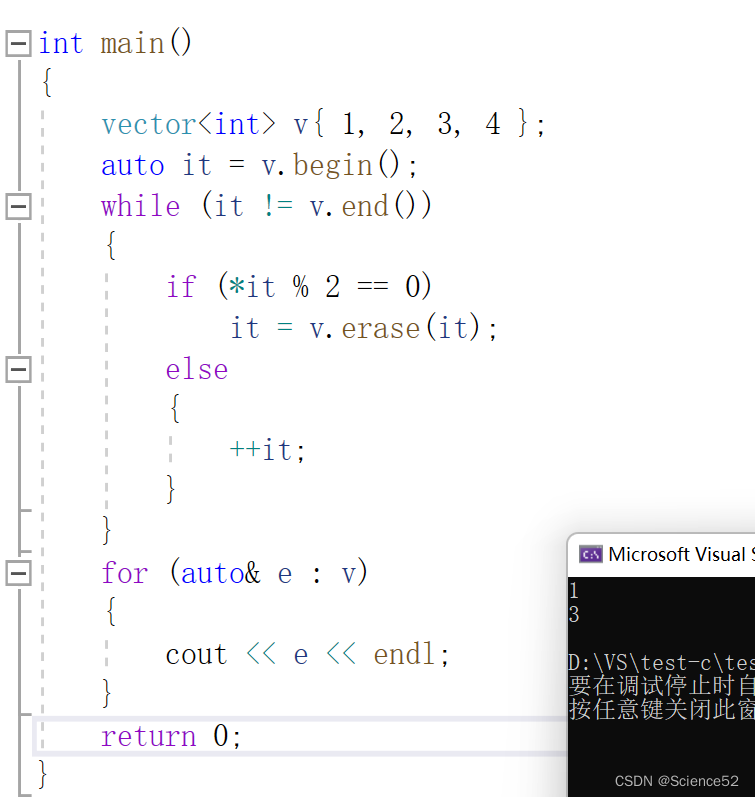
int main()
{
vector<int> v{ 1, 2, 3, 4 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
it = v.erase(it);
else
{
++it;
}
}
for (auto& e : v)
{
cout << e << endl;
}
return 0;
}
但是在Linux底下g++编译器就没有检查的那么严格:
看看扩容这段代码:
// 1. 扩容之后,迭代器已经失效了,程序虽然可以运行,但是运行结果已经不对了
int main()
{
vector<int> v{ 1,2,3,4,5 };
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
auto it = v.begin();
cout << "扩容之前,vector的容量为: " << v.capacity() << endl;
// 通过reserve将底层空间设置为100,目的是为了让vector的迭代器失效
v.reserve(100);
cout << "扩容之后,vector的容量为: " << v.capacity() << endl;
// 经过上述reserve之后,it迭代器肯定会失效,在vs下程序就直接崩溃了,但是linux下不会
// 虽然可能运行,但是输出的结果是不对的
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
} 
可以看到Linux底下是没有报错的,因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的,但是对于刚刚那个偶数那题Linux下也会报错:

4. 与vector类似,string在插入+扩容操作+erase之后,迭代器也会失效
最后说说如何解决这类问题:
1.2.5 vector 在OJ中的使用
因为数组在实际的应用非常广泛,所以C++的vector的运用也是非常多,而且嵌套vector远远比C语言中的二维数组好用,下面我们就来看看vector在oj中的应用:
这题杨辉三角实现起来其实并不是很难,但是如果使用C语言来做就很难受了,因为开辟空间那里就会让你非常头疼,但是对于C++来说这又不是一件难事了。这里就体现了嵌套vector的优点了。思路:先开辟好一个vector<vector<int>>,这样相当于C语言中的二维数组了。然后调整好空间,在第一行以及对角线的那一行初始化为1,其他的初始化为0,然后我们就可以遍历这个嵌套vector,判断是否0的元素,是就让其加上上一行的前一个以及上一行的那个。
class Solution {
public:
vector<vector<int>> generate(int numRows) {
//先开辟空间
vector<vector<int>> vv;
vv.resize(numRows);
for(size_t i= 0 ;i<vv.size();++i)
{
vv[i].resize(i+1,0);
vv[i][0] = vv[i][vv[i].size()-1] = 1;
}
//把剩下为0的位置处理以下
for(size_t i= 0;i<vv.size();++i)
{
for(size_t j = 0;j<vv[i].size();++j)
{
if(vv[i][j] == 0)
{
vv[i][j] = vv[i-1][j-1] + vv[i-1][j];
}
}
}
return vv;
}
};2.力扣
这道题如果使用哈希表的话就超出了这个空间复杂度了,用暴力查找的方式又不符合题意,这里有一个思路非常巧妙:
我们可以利用位运算来解决,因为这个除了这个数字其他的数字都出现过3次,我们可以把数组中的每一个数字的二进制位加起来,然后让结果%3就可以得到我们所想要的二进制位了,(不论是0还是1,%3的结果都是我们想要的那个数的二进制位),最后我们用ret每次接受一下要的到二进制位,就可以得到答案。
代码实现:
class Solution {
public:
int singleNumber(vector<int>& nums) {
//我们可以把所有的二进制位全部加起来,然后%3就可以得到所求的数字的二进制位了
int ret = 0;//我们要求的数字
for(int i = 0;i<32;++i)
{
int sum = 0;
for(auto e:nums)
{
sum += ((e>>i) & 1);
}
//把要求的数字的二进制位找出来
if(sum%3)
{
ret |= (1<<i);
}
}
return ret;
}
};3.数组中出现次数超过一半的数字_牛客题霸_牛客网
思路:因为所出现的元素的个数超过了一般半,我们就可以通过计数的方式记录它,如果是这个元素就++,不是就--,最后得到的那个数一定是我们想要的数,另外,我们还可以拓展一下:如果这个数不一定存在那要怎么处理?
我们可以对这个记录一下这个数,然后再遍历一次数组,通过计数的方式去确认是否存在。
代码实现:
class Solution {
public:
int MoreThanHalfNum_Solution(vector<int> numbers) {
//因为所出现的元素的个数超过了一般半,我们就可以通过计数的方式记录它,如果是这个元素就++,不是就--
//这样的话就可以在最后的时候找到这个元素
int tmp = numbers[0];//记录我们要求的数据
int times = 1;
for(int i = 1;i<numbers.size();++i)
{
//如果次数减到0就把tmp换成下一个元素
if(times == 0)
{
tmp = numbers[i];
times = 1;
}
if(numbers[i] == tmp)
{
++times;
}
else{
--times;
}
}
//到这里就已经找到了就是tmp
return tmp;
}
};4.力扣
这一题的难度比较大,运用到了回溯算法
思路:
我们可以通过一个数组来记录数字与字母之间的映射关系,然后利用回溯算法(递归)就解决像这种组合问题,下面通过这题来大概讲解一下回溯:
这个很像二叉树的遍历,但又复杂一点,这个可以看成多叉树的遍历方式。我们可以通过每一层的递归来达到一个组合的效果。
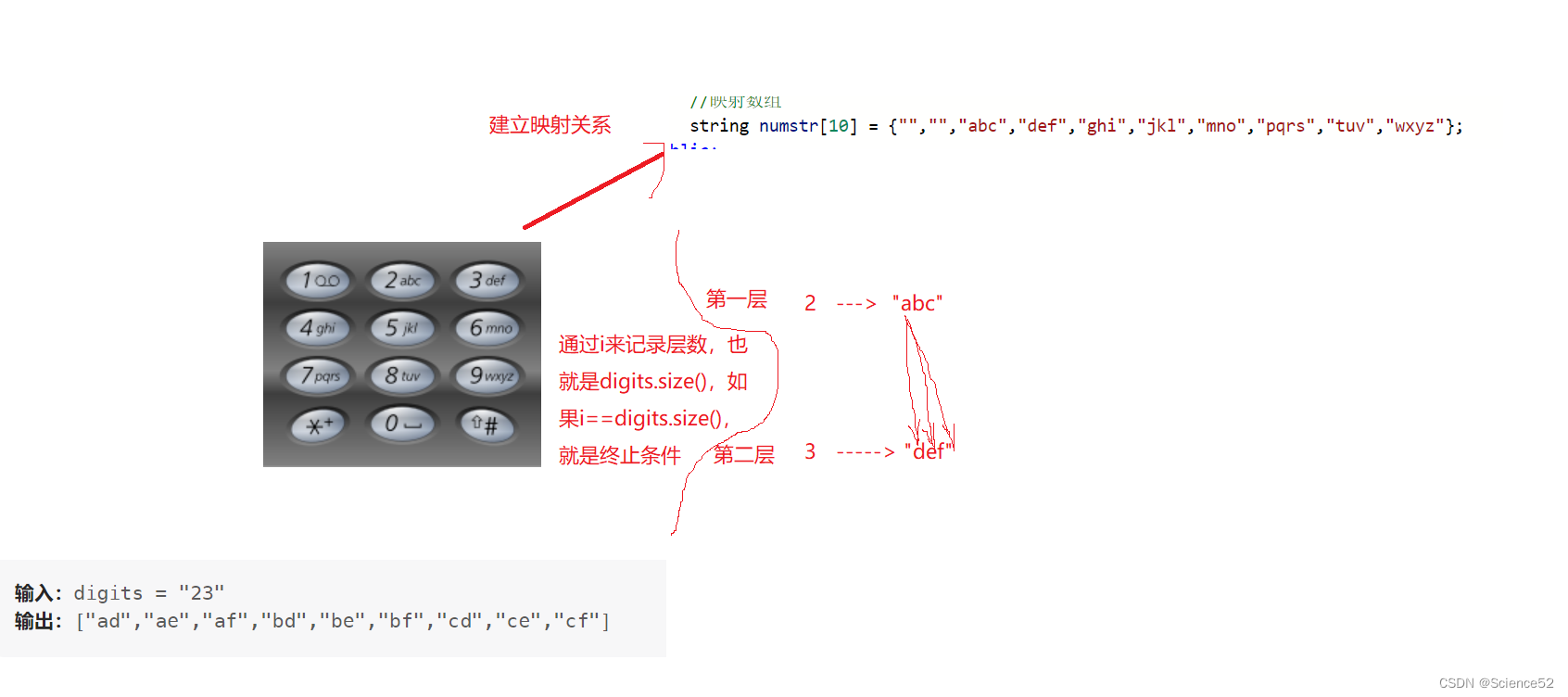
代码实现:
class Solution {
//映射数组
string numstr[10] = {"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};
public:
//递归子函数
void combine(string& digits,int i,vector<string>& vcombine,string retstr)
{
if(i == digits.size())
{
vcombine.push_back(retstr);
return;
}
//找到对应的字母
int num = digits[i]- '0';
string str = numstr[num];
//遍历串中的所有字符,然后进入下一层
for(auto ch:str)
{
combine(digits,i+1,vcombine,retstr+ch);
}
}
vector<string> letterCombinations(string digits) {
vector<string> vcombine;
if(digits.empty())
{
return vcombine;
}
int i = 0;
string retstr;//用来每次加,然后最后加到vcombine中
//递归
combine(digits,i,vcombine,retstr);
return vcombine;
}
};下面通过画递归展开图再来看看其中的细节:
2.vector深度剖析及模拟实现
使用memcpy拷贝问题
1. memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中2. 如果拷贝的是自定义类型的元素, memcpy 既高效又不会出错,但 如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。

这个和之前讲拷贝构造的时候很像,都是浅拷贝导致的问题。 可能会引起内存泄漏甚至程序崩溃。
动态二维数组理解
在前面就已经看过了二维数组的题了,这里不过多介绍,还是介绍一下memcpy也会使内存崩溃的结果:
要解决这个问题,我们还是要进行深拷贝,这是下面的reserve的模拟实现代码来解决这个问题:
我们可以通过这个一个对象赋值的方式来进行深拷贝

模拟实现vector:
template<class T>
class vector
{
public:
// Vector的迭代器是一个原生指针
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _end;
}
const_iterator cbegin()
{
return _start;
}
const_iterator cend() const
{
return _end;
}
// construct and destroy
vector()
:_start(nullptr)
,_end(nullptr)
,_endOfStorage(nullptr)
{}
vector(int n, const T& value = T())
:_start(nullptr)
, _end(nullptr)
, _endOfStorage(nullptr)
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(value);
}
}
template<class InputIterator>
vector(InputIterator first, InputIterator last)
:_start(nullptr)
, _end(nullptr)
, _endOfStorage(nullptr)
{
while (first != last)
{
push_back(*first);
++first;
}
}
vector(const vector<T>& v)
:_start(nullptr)
, _end(nullptr)
, _endOfStorage(nullptr)
{
//找个工具人
vector<T> tmp(v._start, v._end);
swap(tmp);
}
vector<T>& operator= (vector<T> v)
{
swap(v);
return *this;
}
~vector()
{
delete[] _start;
_start = _end = _endOfStorage = nullptr;
}
// capacity
size_t size() const
{
return _end - _start;
}
size_t capacity() const
{
return _endOfStorage - _start;
}
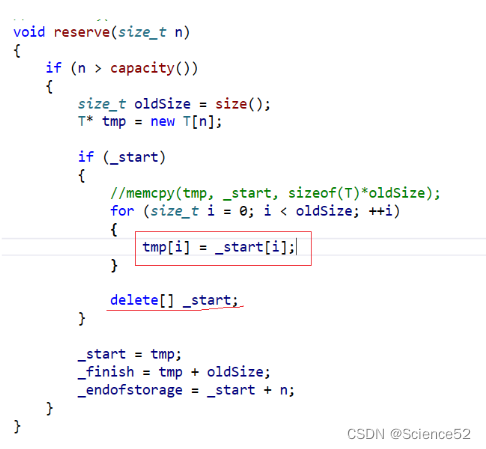
void reserve(size_t n)
{
//坚持不缩容
if (n > capacity())
{
//开辟新的空间,然后赋值过去
T* tmp = new T[n];
size_t oldsize = size();
if (_start)
{
for (size_t i = 0; i < oldsize; ++i)
{
tmp[i] = _start[i];
}
delete[]_start;
}
_start = tmp;
_end = _start + oldsize;
_endOfStorage = _start + n;
}
}
void resize(size_t n, const T& value = T())
{
//要扩容
if (n > capacity())
{
int newcapacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(newcapacity);
}
if (n > size())
{
while (_end != _start + n)
{
push_back(value);
}
}
else
{
_end = _start + n;
}
}
///access///
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];
}
///modify/
void push_back(const T& x)
{
if (size() == capacity())
{
int newcapacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(newcapacity);
}
*_end = x;
++_end;
}
void pop_back()
{
assert(_end > _start);
--_end;
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_end, v._end);
std::swap(_endOfStorage, v._endOfStorage);
}
iterator insert(iterator pos, const T& x)
{
assert(_start <= pos);
assert(_end > pos);
//判断增容
int distance = pos - _start;
if (_end == _endOfStorage)
{
int newcapacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(newcapacity);
//这里的扩容不处理会导致迭代器失效
pos = _start + distance;
}
//挪动数据,插入
auto end = _end -1;
while (end >= pos)
{
*(end+1) = *end;
--end;
}
*pos = x;
++_end;
return pos;
}
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _end);
//挪动数据
iterator ret = pos + 1;
while (ret < _end)
{
*(ret - 1) = *ret;
++ret;
}
--_end;
return pos;
}
private:
iterator _start; // 指向数据块的开始
iterator _end; // 指向有效数据的尾
iterator _endOfStorage; // 指向存储容量的尾
};其中实现过程中最容易错误的就是insert以及erase扩容问题,这是最容易出错的。
扩容是防止浅拷贝,所有把利用赋值来实现深拷贝。insert以及erase要注意更新迭代器,防止迭代器失效。


![[附源码]Python计算机毕业设计Django基于SpringBoot的演唱会购票系统论文2022](https://img-blog.csdnimg.cn/a9a3101db0374d7bb21be45d26719402.png)