Hadoop3.1.4分布式搭建
1. 基础环境准备
1.1 实验网络规划
| hostname | ip addr | role | other |
|---|---|---|---|
| k8s-m133 | 10.10.10.133 | NameNode, DataNode, NodeManageer | |
| k8s-m134 | 10.10.10.134 | SecondaryNameNode, DataNode, NodeManageer | |
| k8s-m135 | 10.10.10.135 | ResourceManager, DataNode, NodeManageer | |
| k8s-n151 | 10.10.10.151 | DataNode, NodeManageer | |
| k8s-n157 | 10.10.10.157 | DataNode, NodeManageer |
# Reset ENV
for i in {133..135} 151 157;
do
echo -e "\n********************************** R ubuntu@10.10.10.$i **********************************\n"
ssh ubuntu@10.10.10.$i "kill -9 $(jps|awk '{print $1}') 2>/dev/null";
ssh ubuntu@10.10.10.$i 'sudo rm -rf /opt/software/';
ssh ubuntu@10.10.10.$i 'sudo rm -rf /opt/module/';
done;
1.2 配置免密登录(所有节点)
# 生成秘钥对,每个节点执行
ssh-keygen -t rsa -n '' -f ~/.ssh/id_rsa -N ''
ssh-copy-id -i ubuntu@10.10.10.133
for i in {133..135} 151 157;
do
ssh -o StrictHostKeyChecking=no ubuntu@10.10.10.$i 'echo $HOSTNAME;'
done;
1.3 关闭防火墙(所有节点)
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
ssh ubuntu@10.10.10.$i "sudo systemctl disable --now ufw; \
sudo systemctl status ufw;"
done;
2 安装配置java
2.1 安装java
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
scp ~/Downloads/jdk-8u321-linux-x64.tar.gz ubuntu@10.10.10.$i:~/;
ssh ubuntu@10.10.10.$i 'sudo mkdir -p /opt/module/; \
sudo rm -f /etc/profile.d/Z99-wntime-env-config.sh; \
sudo touch /etc/profile.d/Z99-wntime-env-config.sh; \
sudo tar -zxf ~/jdk-8u321-linux-x64.tar.gz -C /opt/module/;';
# config env
rm -rf /tmp/"10.10.10.$i"/;
mkdir -p /tmp/"10.10.10.$i"/;
scp ubuntu@10.10.10.$i:/etc/profile.d/Z99-wntime-env-config.sh /tmp/"10.10.10.$i"/Z99-wntime-env-config.sh;
sudo cat>>/tmp/"10.10.10.$i"/Z99-wntime-env-config.sh<<EOF
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=\$PATH:\$JAVA_HOME/bin
EOF
cat /tmp/10.10.10.$i/Z99-wntime-env-config.sh;
scp /tmp/10.10.10.$i/Z99-wntime-env-config.sh ubuntu@10.10.10.$i:~/Z99-wntime-env-config.sh;
ssh ubuntu@10.10.10.$i 'sudo mv ~/Z99-wntime-env-config.sh /etc/profile.d/Z99-wntime-env-config.sh; \
sudo chmod +x /etc/profile.d/Z99-wntime-env-config.sh; \
source /etc/profile; \
java -version;'
done;
2.2 安装hadoop
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
scp ~/Downloads/hadoop-3.1.4.tar.gz ubuntu@10.10.10.$i:~/;
ssh ubuntu@10.10.10.$i 'sudo mkdir -p /opt/software/; \
#sudo rm -f /etc/profile.d/Z99-wntime-env-config.sh; \
sudo touch /etc/profile.d/Z99-wntime-env-config.sh; \
sudo tar -zxf ~/hadoop-3.1.4.tar.gz -C /opt/software/;';
# config env
rm -rf /tmp/"10.10.10.$i"/;
mkdir -p /tmp/"10.10.10.$i"/;
scp ubuntu@10.10.10.$i:/etc/profile.d/Z99-wntime-env-config.sh /tmp/"10.10.10.$i"/Z99-wntime-env-config.sh;
sudo cat>>/tmp/"10.10.10.$i"/Z99-wntime-env-config.sh<<EOF
#HADOOP_HOME
export HADOOP_HOME=/opt/software/hadoop-3.1.4
export PATH=\$PATH:\$HADOOP_HOME/bin
export PATH=\$PATH:\$HADOOP_HOME/sbin
EOF
cat /tmp/10.10.10.$i/Z99-wntime-env-config.sh;
scp /tmp/10.10.10.$i/Z99-wntime-env-config.sh ubuntu@10.10.10.$i:~/Z99-wntime-env-config.sh;
ssh ubuntu@10.10.10.$i 'sudo mv ~/Z99-wntime-env-config.sh /etc/profile.d/Z99-wntime-env-config.sh; \
sudo chmod +x /etc/profile.d/Z99-wntime-env-config.sh; \
source /etc/profile; \
hadoop version;'
done;
2.3 hadoop文件配置
2.3.1 core-site.xml
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
cat>/tmp/hadoop-3.1.4/core-site.xml<<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://k8s-m133:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-3.1.4/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 ubuntu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>ubuntu</value>
</property>
</configuration>
EOF
ssh ubuntu@10.10.10.$i 'sudo chown -R ubuntu:ubuntu /opt/software/;';
scp /tmp/hadoop-3.1.4/core-site.xml ubuntu@10.10.10.$i:/opt/software/hadoop-3.1.4/etc/hadoop/;
done;
2.3.2 hdfs-site.xml
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
cat>/tmp/hadoop-3.1.4/hdfs-site.xml<<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>k8s-m133:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>k8s-m134:9868</value>
</property>
</configuration>
EOF
scp /tmp/hadoop-3.1.4/hdfs-site.xml ubuntu@10.10.10.$i:/opt/software/hadoop-3.1.4/etc/hadoop/;
done;
2.3.3 yarn-site.xml
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
cat>/tmp/hadoop-3.1.4/yarn-site.xml<<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>k8s-m135:8088</value>
</property>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>k8s-m135</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 设置日志聚集服务开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://k8s-m133:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
EOF
scp /tmp/hadoop-3.1.4/yarn-site.xml ubuntu@10.10.10.$i:/opt/software/hadoop-3.1.4/etc/hadoop/;
done;
2.3.4 mapred-site.xml
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
cat>/tmp/hadoop-3.1.4/mapred-site.xml<<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>k8s-m133:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> k8s-m133:19888</value>
</property>
</configuration>
EOF
scp /tmp/hadoop-3.1.4/mapred-site.xml ubuntu@10.10.10.$i:/opt/software/hadoop-3.1.4/etc/hadoop/;
done;
2.3.5 配置workers
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
# 在workers文件中配置DataNode节点
cat>/tmp/hadoop-3.1.4/workers<<EOF
k8s-m133
k8s-m134
k8s-m135
k8s-n151
k8s-n157
EOF
scp /tmp/hadoop-3.1.4/workers ubuntu@10.10.10.$i:/opt/software/hadoop-3.1.4/etc/hadoop/;
done;
2.3.6 配置用户及java_home
for i in {133..135} 151 157;
do
echo -e "\n********************************** Config ubuntu@10.10.10.$i **********************************\n"
mkdir -p /tmp/hadoop-3.1.4/
ssh ubuntu@10.10.10.$i 'sudo chown -R ubuntu:ubuntu /opt/software/;';
#处理JAVA_HOME显示未配置错误
ssh ubuntu@10.10.10.$i "sed -i 's/# export JAVA_HOME=/export JAVA_HOME=\/opt\/module\/jdk1.8.0_321/g' /opt/software/hadoop-3.1.4/etc/hadoop/hadoop-env.sh"
# 调整运行用户
ssh ubuntu@10.10.10.$i 'cat>>/opt/software/hadoop-3.1.4/etc/hadoop/hadoop-env.sh<<EOF \
# 为hadoop配置三个角色的用户
export HADOOP_USER_NAME=ubuntu
export HDFS_NAMENODE_USER=ubuntu
export HDFS_SECONDARYNAMEDODE_USER=ubuntu
export HDFS_DATANODE_USER=ubuntu
export HDFS_JOURNALNODE_USER=ubuntu
export HDFS_ZKFC_USER=ubuntu
export YARN_NODEMANAGER_USER=ubuntu
export YARN_RESOURCEMANAGER_USER=ubuntu
EOF';
done;
3 集群启动
3.1 集群初始化(namenode)
hdfs namenode -format
执行输出如下: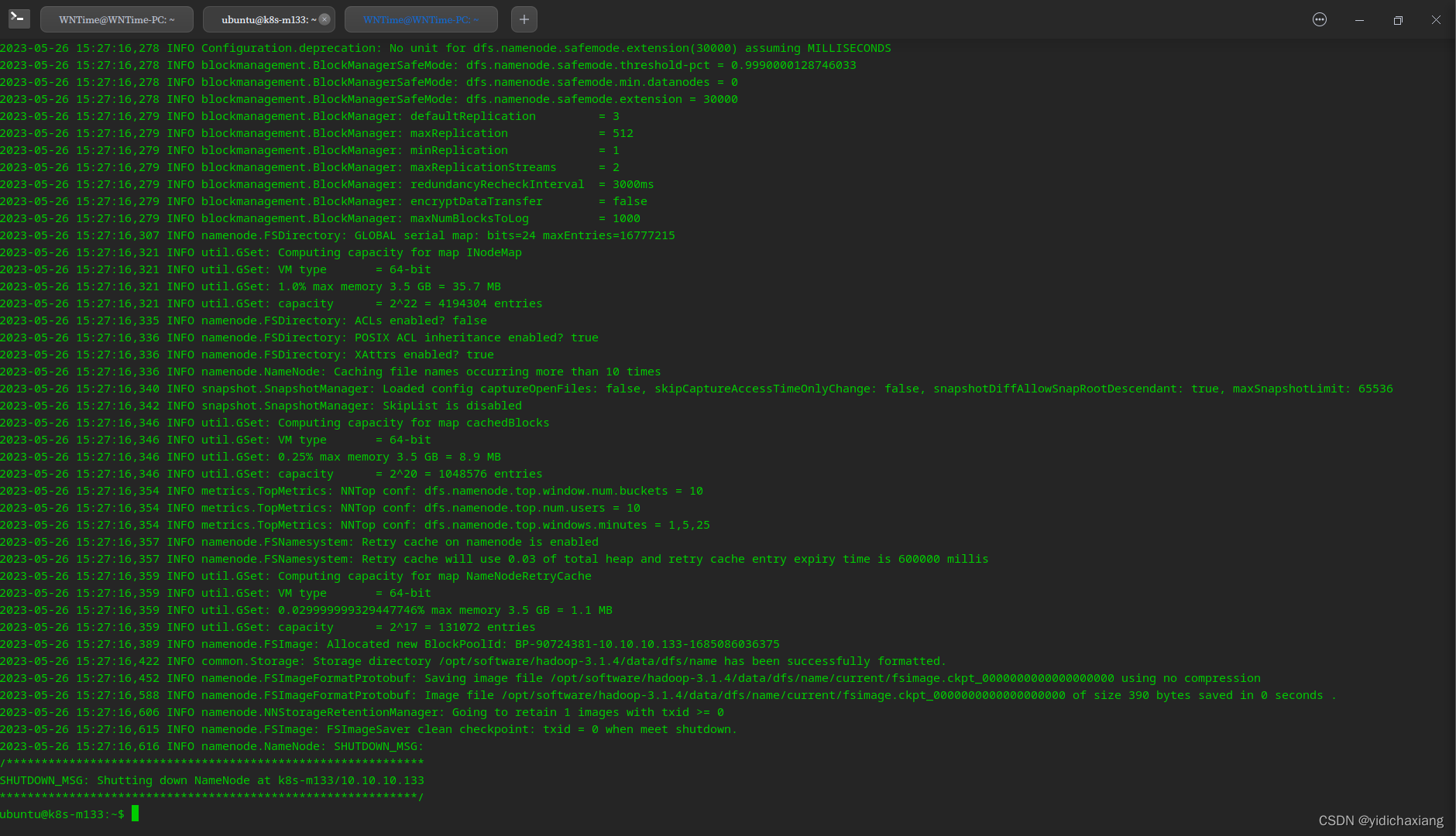
3.2 启动集群
3.2.1 启动hdfs
切换到sbin目录下,执行start-dfs.sh启动
cd $HADOOP_HOME
./sbin/start-dfs.sh
访问http://10.10.10.133:9870/
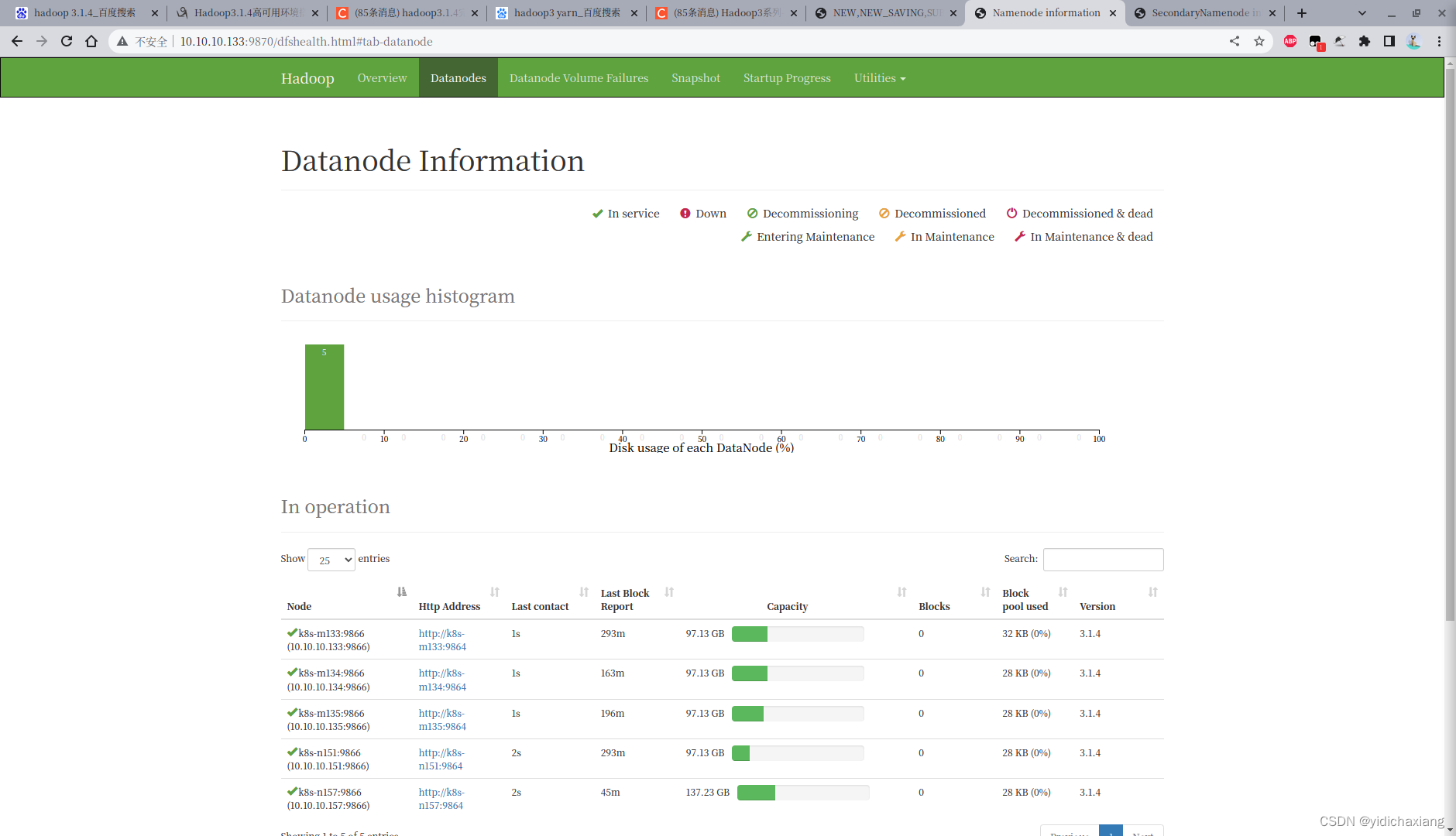
HDFS测试
hadoop fs -mkdir /wntime
# 查看
ubuntu@k8s-m133:hadoop-3.1.4$ hadoop fs -ls /
Found 1 items
drwxr-xr-x - ubuntu supergroup 0 2023-05-29 13:57 /wntime
#
ubuntu@k8s-m133:hadoop-3.1.4$ vim /home/ubuntu/words.txt
ubuntu@k8s-m133:hadoop-3.1.4$
ubuntu@k8s-m133:hadoop-3.1.4$ hadoop fs -put /home/ubuntu/words.txt /wntime/tmp
#
ubuntu@k8s-m133:hadoop-3.1.4$ hadoop fs -ls /wntime/tmp
Found 1 items
-rw-r--r-- 3 ubuntu supergroup 91248 2023-05-29 14:08 /wntime/tmp/words.txt
ubuntu@k8s-m133:hadoop-3.1.4$
常见问题
通过IP地址访问HDFS, 上传,下载,预览都无法使用
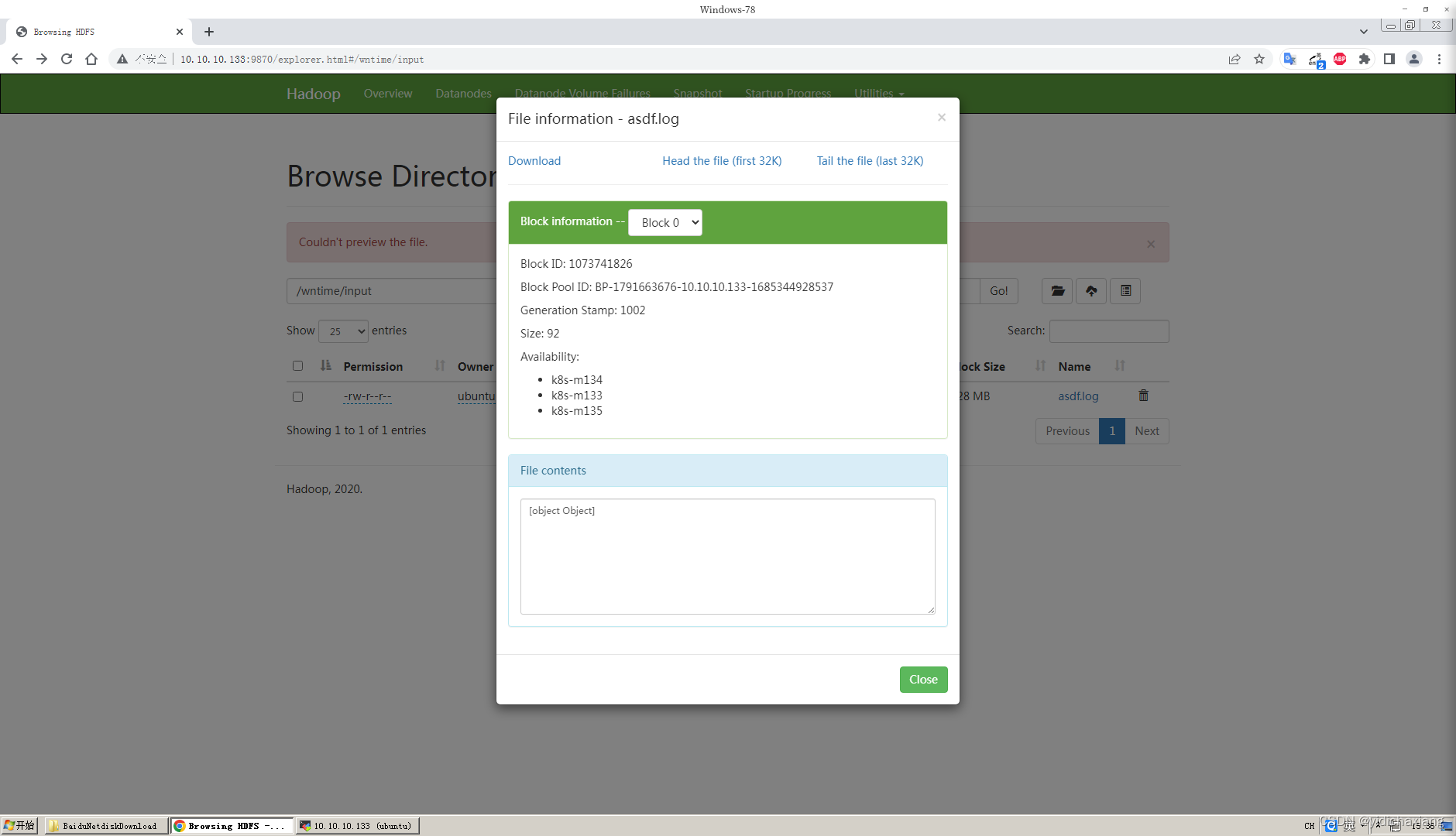
hdfs自动把ip转换成域名,
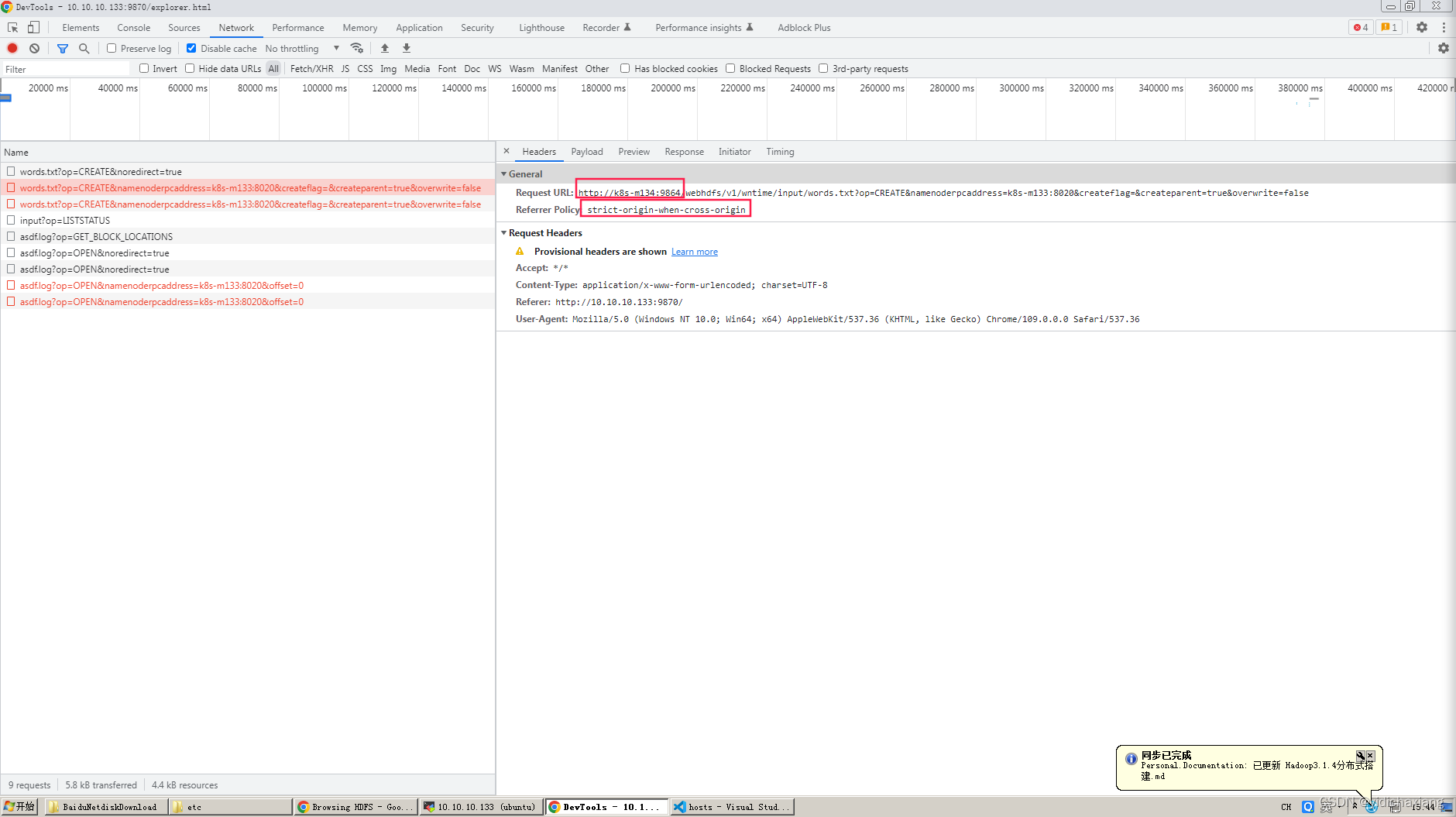
配置hosts域名映射
10.10.10.133 k8s-m133
10.10.10.134 k8s-m134
10.10.10.135 k8s-m135
10.10.10.151 k8s-m151
10.10.10.157 k8s-m157
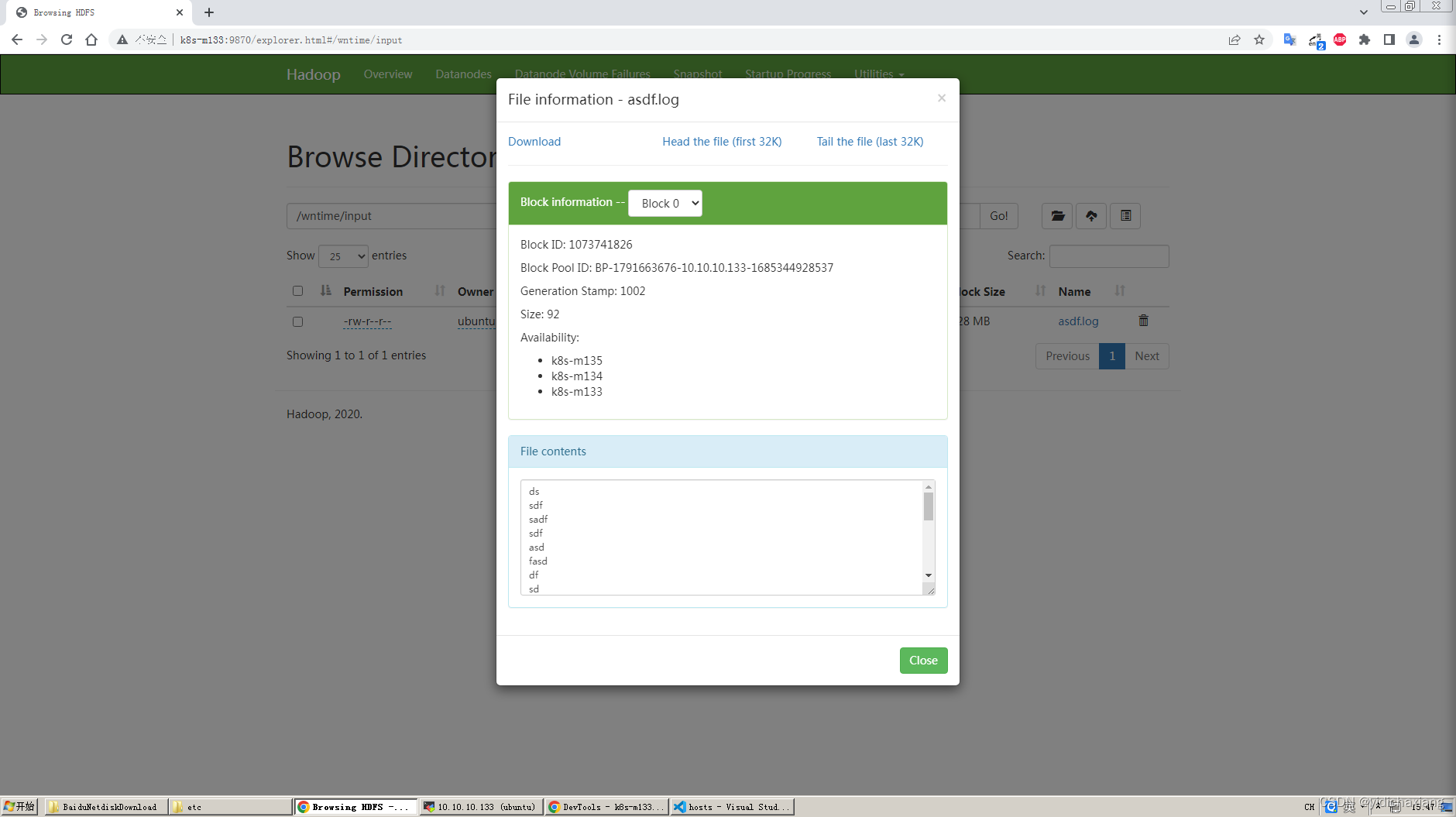
访问正常。
3.2.2 启动yarn
切换到sbin目录下,执行start-yarn.sh启动
cd $HADOOP_HOME
./sbin/start-yarn.sh
# 开启历史服务器 k8s-m133
mapred --daemon start historyserver
访问 http://10.10.10.135:8088/cluster/nodes
Yarn测试
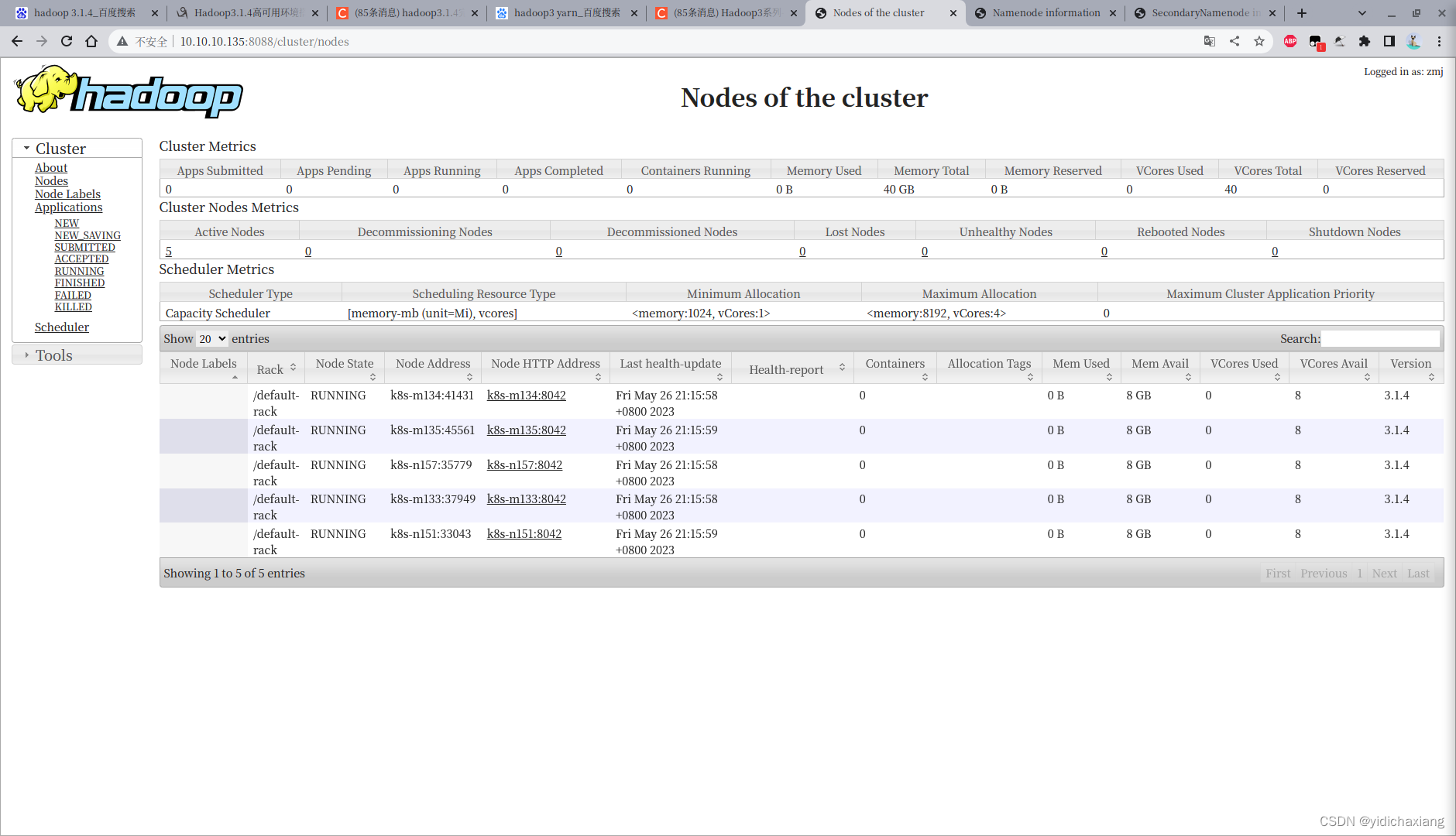
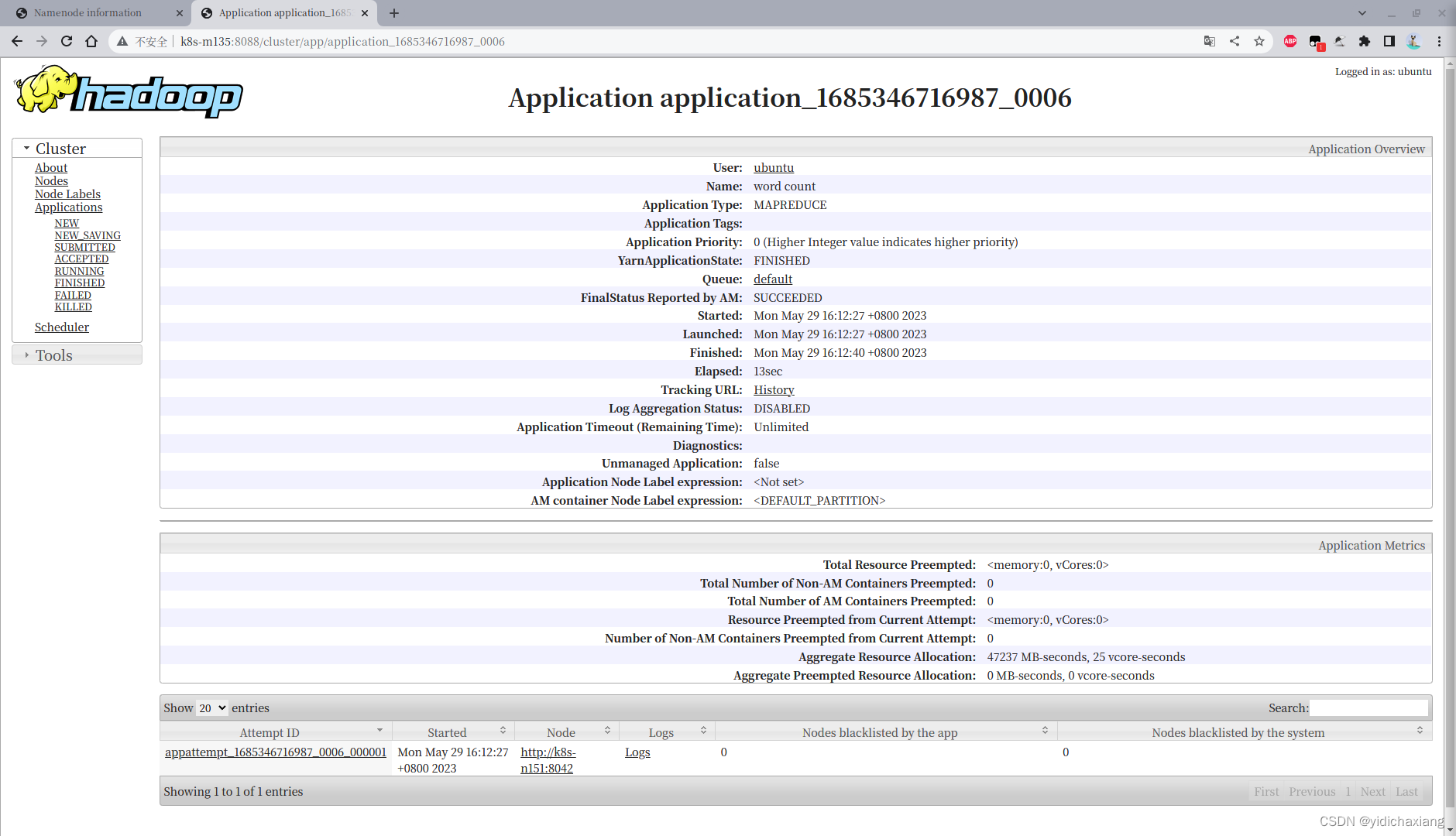
# 测试 wordconut
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
ubuntu@k8s-m134:~$ hadoop jar /opt/software/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /wntime/input/words.txt /wntime/output2
2023-05-29 16:04:29,045 INFO client.RMProxy: Connecting to ResourceManager at k8s-m135/10.10.10.135:8032
2023-05-29 16:04:29,500 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/ubuntu/.staging/job_1685346716987_0005
2023-05-29 16:04:29,714 INFO input.FileInputFormat: Total input files to process : 1
2023-05-29 16:04:29,799 INFO mapreduce.JobSubmitter: number of splits:1
2023-05-29 16:04:29,935 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1685346716987_0005
2023-05-29 16:04:29,936 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-05-29 16:04:30,072 INFO conf.Configuration: resource-types.xml not found
2023-05-29 16:04:30,072 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-05-29 16:04:30,127 INFO impl.YarnClientImpl: Submitted application application_1685346716987_0005
2023-05-29 16:04:30,169 INFO mapreduce.Job: The url to track the job: http://k8s-m135:8088/proxy/application_1685346716987_0005/
2023-05-29 16:04:30,170 INFO mapreduce.Job: Running job: job_1685346716987_0005
2023-05-29 16:04:36,258 INFO mapreduce.Job: Job job_1685346716987_0005 running in uber mode : false
2023-05-29 16:04:36,259 INFO mapreduce.Job: map 0% reduce 0%
2023-05-29 16:04:40,324 INFO mapreduce.Job: map 100% reduce 0%
2023-05-29 16:04:45,358 INFO mapreduce.Job: map 100% reduce 100%
2023-05-29 16:04:45,369 INFO mapreduce.Job: Job job_1685346716987_0005 completed successfully
2023-05-29 16:04:45,469 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=210
FILE: Number of bytes written=442733
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=258
HDFS: Number of bytes written=120
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Rack-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2075
Total time spent by all reduces in occupied slots (ms)=2238
Total time spent by all map tasks (ms)=2075
Total time spent by all reduce tasks (ms)=2238
Total vcore-milliseconds taken by all map tasks=2075
Total vcore-milliseconds taken by all reduce tasks=2238
Total megabyte-milliseconds taken by all map tasks=2124800
Total megabyte-milliseconds taken by all reduce tasks=2291712
Map-Reduce Framework
Map input records=37
Map output records=32
Map output bytes=236
Map output materialized bytes=210
Input split bytes=108
Combine input records=32
Combine output records=21
Reduce input groups=21
Reduce shuffle bytes=210
Reduce input records=21
Reduce output records=21
Spilled Records=42
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=80
CPU time spent (ms)=1220
Physical memory (bytes) snapshot=582193152
Virtual memory (bytes) snapshot=5238251520
Total committed heap usage (bytes)=609222656
Peak Map Physical memory (bytes)=334422016
Peak Map Virtual memory (bytes)=2615758848
Peak Reduce Physical memory (bytes)=247771136
Peak Reduce Virtual memory (bytes)=2622492672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=150
File Output Format Counters
Bytes Written=120
ubuntu@k8s-m134:~$
测试成功: