基于关联规则挖掘的商品交叉销售分析
小P:我们最近考虑将一些相关的商品打包销售,以提高GMV,有没有好的方法啊
小H:参考经典的啤酒尿布案例,可以尝试通过关联规则挖掘相关信息
数据探索
# 导入库
import pandas as pd
import apriori # 本地库apriori.py
from pyecharts.charts import Graph
from pyecharts import options as opts
上述
apriori.py和以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-关联规则】自动获取~
# 读取数据
raw_data = pd.read_csv('order_table.csv')
raw_data.head()
| order_id | product_name | |
|---|---|---|
| 0 | 201901010000001 | citrus fruit |
| 1 | 201901010000001 | semi-finished bread |
| 2 | 201901010000001 | margarine |
| 3 | 201901010000001 | ready soups |
| 4 | 201901010000002 | tropical fruit |
特征工程
# 转换为关联所用的记录模式
order_ids = pd.unique(raw_data['order_id'])
order_records = [raw_data[raw_data['order_id']==each_id]['product_name'].tolist() for each_id in order_ids]
order_records[0:5]
[['citrus fruit', 'semi-finished bread', 'margarine', 'ready soups'],
['tropical fruit', 'yogurt', 'coffee'],
['whole milk'],
['pip fruit', 'yogurt', 'cream cheese ', 'meat spreads'],
['other vegetables',
'whole milk',
'condensed milk',
'long life bakery product']]
模型拟合
# 通过调用自定义的apriori做关联分析
minS = 0.01 # 定义最小支持度阀值
minC = 0.05 # 定义最小置信度阀值
L, suppData = apriori.apriori(order_records, minSupport=minS) # 计算得到满足最小支持度的规则
rules = apriori.generateRules(order_records, L, suppData, minConf=minC) # 计算满足最小置信度的规则
# 关联结果报表评估
model_summary = 'data record: {0} \nassociation rules count: {1}' # 展示数据集记录数和满足阀值定义的规则数量
print(model_summary.format(len(order_records), len(rules)),'\n','-'*60) # 使用str.format做格式化输出
rules_all = pd.DataFrame(rules, columns=['item1', 'item2', 'instance', 'support', 'confidence',
'lift']) # 创建频繁规则数据框
rules_sort = rules_all.sort_values(['lift'],ascending=False)
rules_sort.head(10)
data record: 2240
association rules count: 582
------------------------------------------------------------
| item1 | item2 | instance | support | confidence | lift | |
|---|---|---|---|---|---|---|
| 346 | (whipped/sour cream) | (berries) | 27 | 0.0121 | 0.1525 | 4.1168 |
| 347 | (berries) | (whipped/sour cream) | 27 | 0.0121 | 0.3253 | 4.1168 |
| 496 | (pip fruit) | (tropical fruit, other vegetables) | 23 | 0.0103 | 0.1474 | 4.0772 |
| 497 | (tropical fruit) | (pip fruit, other vegetables) | 23 | 0.0103 | 0.1000 | 3.9298 |
| 510 | (yogurt) | (fruit/vegetable juice, other vegetables) | 26 | 0.0116 | 0.0836 | 3.6719 |
| 575 | (curd) | (whole milk, yogurt) | 29 | 0.0129 | 0.2042 | 3.6307 |
| 546 | (root vegetables) | (tropical fruit, yogurt) | 24 | 0.0107 | 0.0980 | 3.5972 |
| 547 | (yogurt) | (tropical fruit, root vegetables) | 24 | 0.0107 | 0.0772 | 3.5278 |
| 512 | (fruit/vegetable juice) | (other vegetables, yogurt) | 26 | 0.0116 | 0.1566 | 3.3735 |
| 548 | (tropical fruit) | (yogurt, root vegetables) | 24 | 0.0107 | 0.1043 | 3.2464 |
结果展示
# 选择有效数据
rules_sort_filt = rules_sort[rules_sort['lift']>1] # 只取有效规则
display_data = rules_sort_filt.iloc[:, :3] # 取出前3列
display_data.head()
| item1 | item2 | instance | |
|---|---|---|---|
| 346 | (whipped/sour cream) | (berries) | 27 |
| 347 | (berries) | (whipped/sour cream) | 27 |
| 496 | (pip fruit) | (tropical fruit, other vegetables) | 23 |
| 497 | (tropical fruit) | (pip fruit, other vegetables) | 23 |
| 510 | (yogurt) | (fruit/vegetable juice, other vegetables) | 26 |
# 汇总每个item出现的次数
item1 = display_data[['item1','instance']].rename(index=str, columns={"item1": "item"})
item2 = display_data[['item2','instance']].rename(index=str, columns={"item2": "item"})
item_concat = pd.concat((item1,item2),axis=0)
item_count = item_concat.groupby(['item'])['instance'].sum()
# 取出规则最多的TOP N items
control_num = 10
top_n_rules = item_count.sort_values(ascending=False).iloc[:control_num]
top_n_items = top_n_rules.index
top_rule_list = [all((item1 in top_n_items, item2 in top_n_items)) for item1,item2 in zip(display_data['item1'],display_data['item2'])]
top_display_data = display_data[top_rule_list] #TOP N items都参与的规则
# 准备数据
node_data = top_n_rules/100 # 圆的size太多,等比例缩小100倍
nodes = [{"name": ('').join(i[0]), "symbolSize": i[1], "value": j} for i, j in
zip(node_data.to_dict().items(),top_n_rules)]
# 创建边数据以及边权重数据
edges = [{"source": ('').join(i), "target": ('').join(j), "value": k} for i, j, k in top_display_data.values]
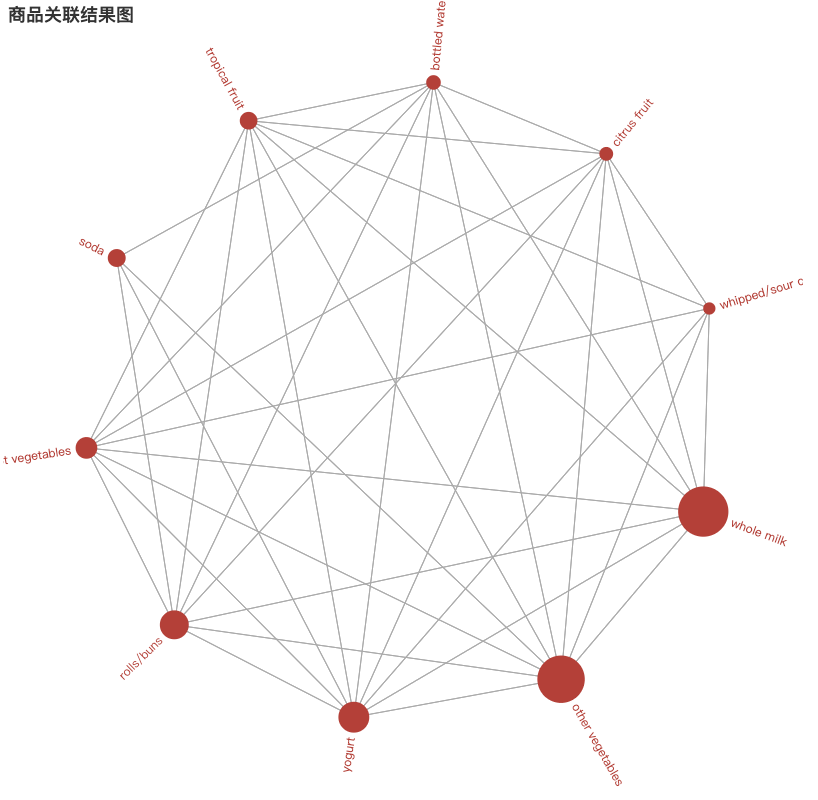
# 商品关联结果图
graph = Graph(init_opts=opts.InitOpts(width="800px", height="800px"))
graph.add("", nodes, edges, repulsion=8000,layout="circular",is_rotate_label=True)
graph.set_global_opts(title_opts=opts.TitleOpts(title="商品关联结果图"))
graph.render_notebook()
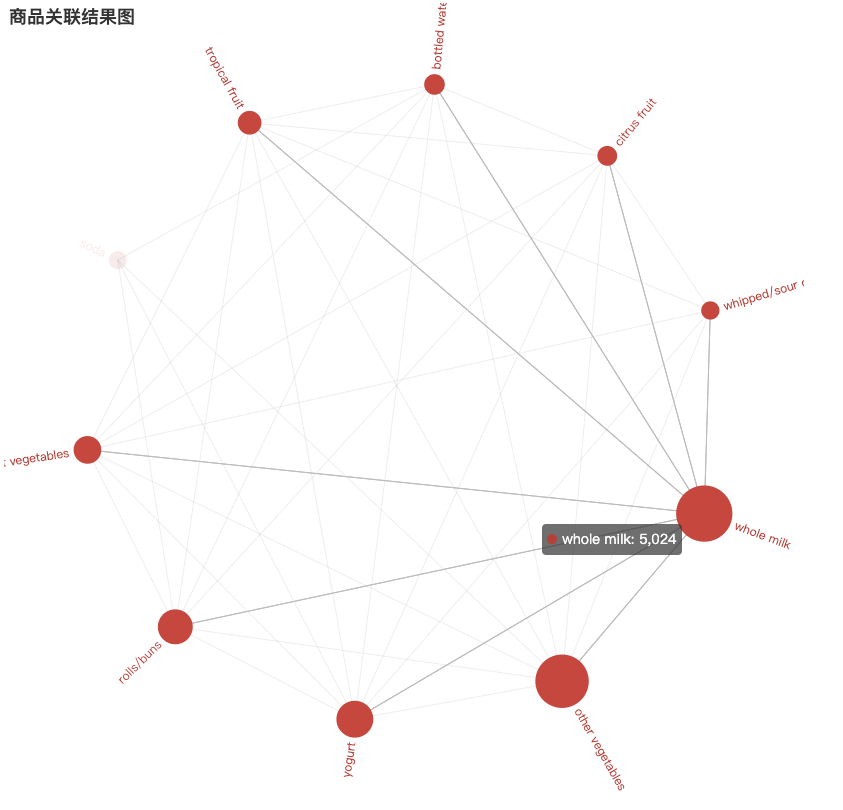
如果点击某个商品,则能看到其他商品和它的关联程度,例如【whole milk】
总结
通过关联规则挖掘出历史商品的关联信息,然后就可以根据运营角度自行选择打包相关商品进行交叉销售了~
共勉~