【菜鸡读论文】Face2Exp: Combating Data Biases for Facial Expression Recognition
最近上海开始降温了,而且常常下雨,天气开始变得好冷啊!以前年轻的时候冬天经常穿的少,现在膝盖开始有点遭不住了,小伙伴们一定要保护好自己的膝盖啊!
 话不多说,你们的菜鸡我闪亮登场,让我们开始这周的读论文吧!
话不多说,你们的菜鸡我闪亮登场,让我们开始这周的读论文吧!

这是CVPR 2022的一篇文章,还算是非常新。这篇文章主要讲的就是在表情识别任务中存在数据类别不均衡的问题,比如happy类的表情样本可能就比较多,而这样就不可避免的会使得模型在预测的时候存在偏见,从而在不同表情类别上的预测精度参差不齐。那该如何解决这个问题?作者提出使用人脸识别(FR)数据集来进行训练,因为人脸识别数据集往往都是百万规模的,比起表情识别数据集大多了,数据集大了,自然就能接触到更多的不同特征的图片。
但是这也会引来另一个问题,就是使用FR数据集和FER数据集一起训练的时候,这两个数据集之间的类别分布也存在偏差,这该如何解决呢?作者提出引入一个反馈损失,用来对该偏差做出约束。那么,下面让我们具体来看看实现细节。
motivation
表情识别任务存在数据偏差问题,现有的研究只使用标记的面部表情数据集来解决数据偏差问题。与现有的FER方法相反,我们提出利用大型的无标记人脸识别(FR)数据集来增强FER。
FR(Face Recognition)数据集如Webface260M、MS-Celeb-1M 和VGGFace2都是百万级FR数据集,它们包含具有良好综合多样性的人脸图像(即不同的姿态、身份、照明变化,和不同的表情)。相比之下,最大的公共FER数据集(Facial Expression Recognition)只包含440K张图像。然而,这不可避免地提出了另一个数据偏差问题,因为FER数据和FR 数据的分布不匹配,如图所示
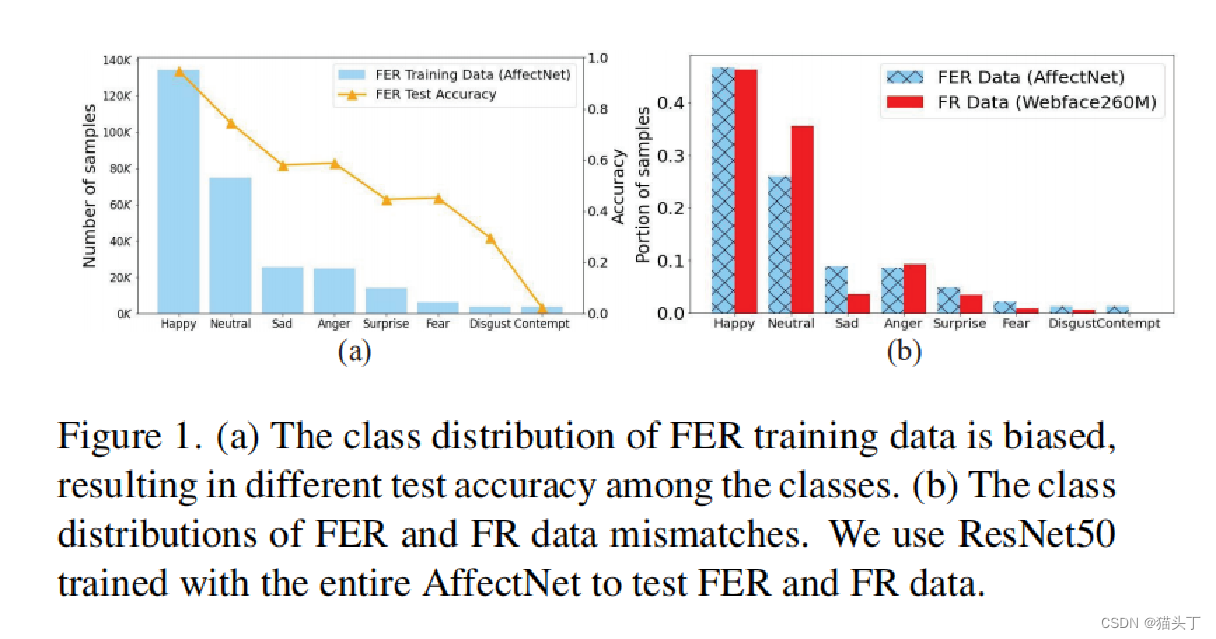
本文的贡献如下:
1、我们解释了两个数据偏差,即FER数据中的类别不平衡和FR和FER数据之间的类别分布不匹配,提出模型Meta-Face2Exp,第一个利用大规模未标记FR数据来提高FER。我们认为Meta-Face2Exp提供了一个通用的框架,利用大规模的未标记FR数据用于其他与面孔相关的缺乏高质量的数据的任务(例如,性别/种族分类,年龄估计) 。
2、我们提出了Meta-Face2Exp框架,通过元优化框架从辅助FR数据中提取去偏信息。
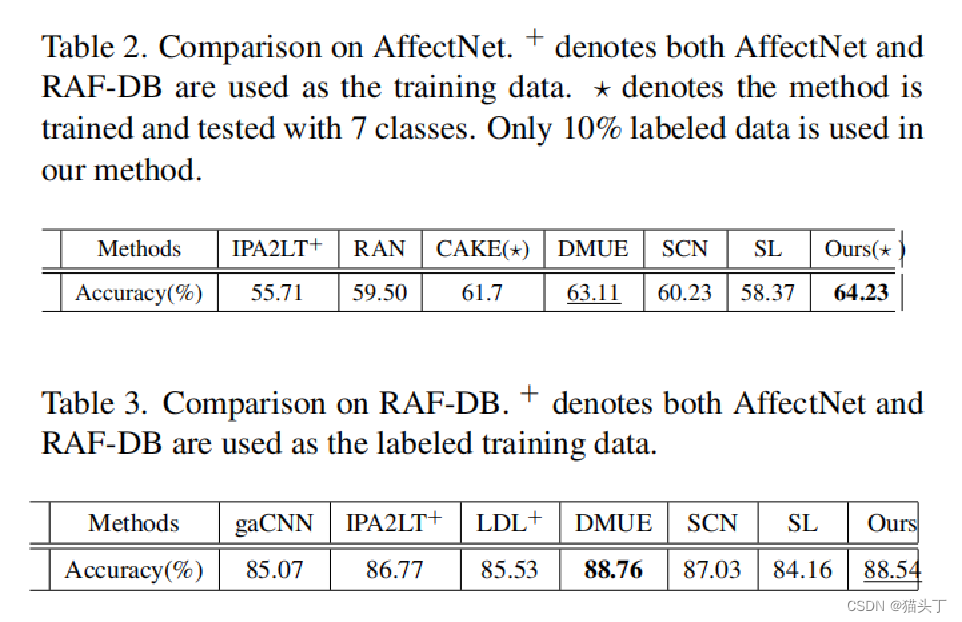
3、我们在广泛使用的FER基准上进行了广泛的实验,包括AffectNet和RAFDB ,以证明我们的Meta-Face2Exp框架的有效性。具体来说,Meta-face2exp使用仅10%的标记FER数据,获得了与最先进的FER方法相比较的结果。
模型架构
首先,我们整体的来看一下这个网络。通过一个采样模块Smp(·)在FER数据集进行采样,以确保类平衡(具体来说就是在不同表情类别上采相同个数的图片)。接下来将这些数据送入基础网络(Base Network)进行训练。之后,使用基础网络在FR数据集上生成伪标签。自适应网络基于伪标签在无标签数据集FR上进行训练。
利用Meta-Face2Exp的去偏机制,根据有偏FR数据和去偏FER数据之间的认知差异,根据适应网络的反馈,逐步改进基础网络。
因此,基础网络可以产生更好的伪标签,用于训练下一代的自适应网络。
在训练过程中,A网络和B网络交替进行更新。在推理阶段,只将自适应模型A用于面部表情预测

我们来详细看一些右边的这幅图
我们估计了初始的自适应网络(即,用FER数据进行训练),并观察到一个严重倾斜的蓝色精度分布。之后,我们可以观察到越来越平坦的精度分布(即红色准确度分布)从训练步骤1到T的去偏置机制。.同时,基于对平衡的FER数据的反馈,将预测的FR标签一般从悲伤、中性表达校正为快乐表情。
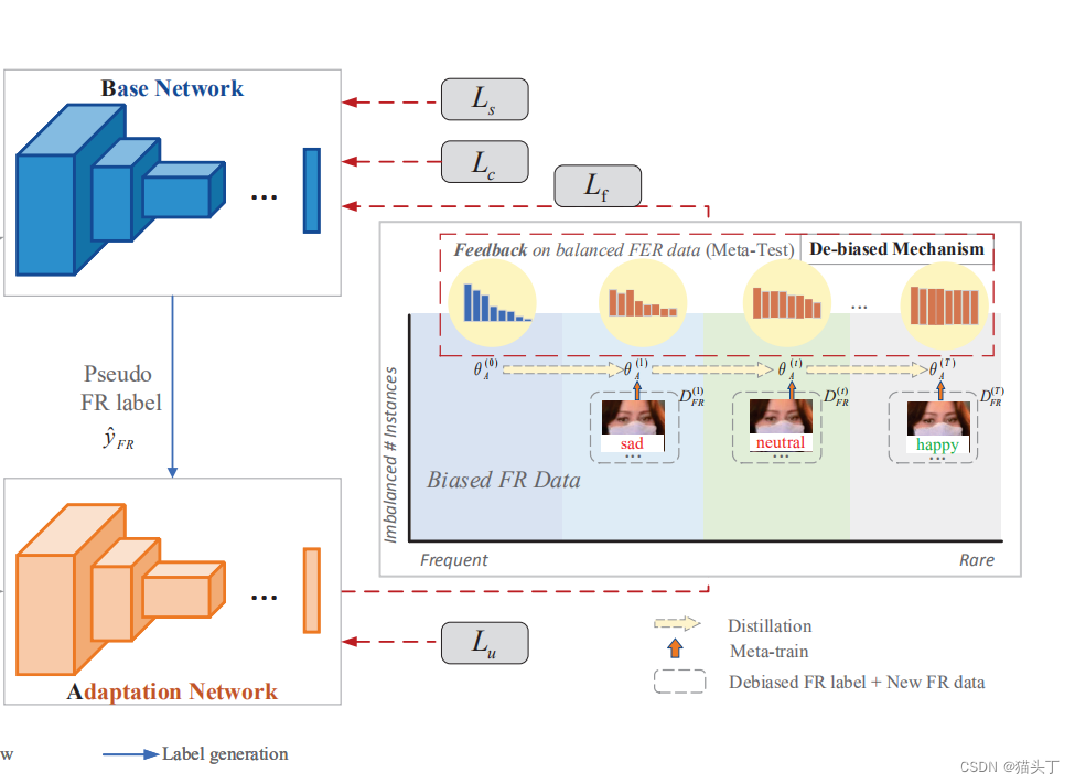 下面我们来看看模型的各个部分:
下面我们来看看模型的各个部分:
Adaptation Network(A)
对于自适应网络,由于FR数据具有丰富和全面的多样性,因此利用大规模未标记的FR数据来增强FER。
自适应网络使用无标签的FR数据进行训练,使用基础网络生成的伪标签,希望自适应网络和基础网络可以有相似的预测条件分类分布。
伪标签在训练过程中会动态变化。
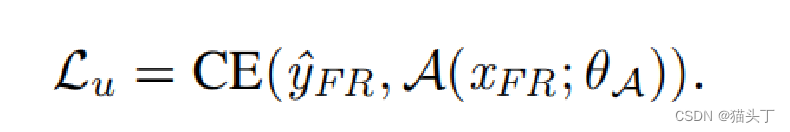
Base Network (B)
采用一个采样模块Smp(·),以确保FER的类分布 数据平衡。具体来说,我们在每个面部表情类上随机选择相同数量的样本,这确保了训练基础网络生成平衡的类。
使用三个损失supervised loss, consistency loss, and feed back loss指导基础网络的学习过程,具体来说,监督损失和一致性损失只适用于基础网络,而反馈损失考虑了自适应网络的元测试的性能
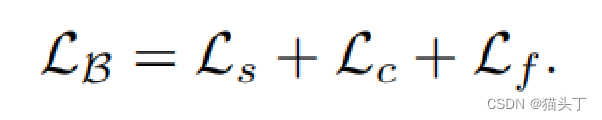 Supervised learning with FER data:
Supervised learning with FER data:
这个损失就是一个分类损失
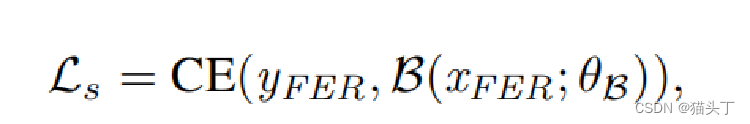 Consistency learning with FR data:
Consistency learning with FR data:
这是一个一致性损失
在一致性学习方面,基础网络要求原始图像和增强的对应图像具有接近的类条件分布。
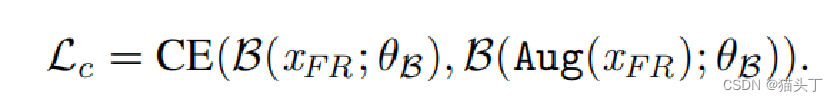
这里的Aug()指的就是数据增强
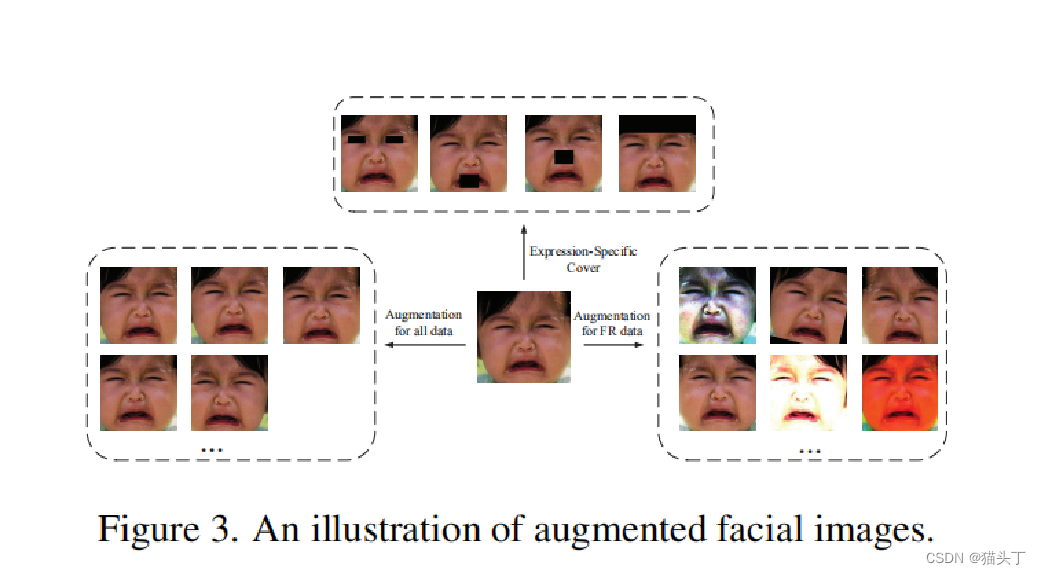
如图所示,,图像生成有三种类型的增强,包括左框上所有数据的常规变换(随机裁剪、旋转和水平翻转),右框上的FR数据的广泛图像变换(即旋转、移除和像素级图像处理),以及顶框上的表情增强。
考虑到面部表情与面部标志密切相关,我们通过覆盖与面部表情无关的区域来增强面部图像来纯化面部表情特征提取。具体的 最后,我们应用MTCNN 检测5个面部标志,并通过经验确定以标志为中心的斑块,即眼睛50×20像素,鼻子和嘴50×40像素,以及224×50像素 用于前额。
 Feedback learning with FR data:
Feedback learning with FR data:
其中,f估计了FR和FER数据之间的认知差异的反馈,以帮助更新基础网络的参数。反馈系数f的定义可以表示为
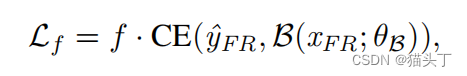
其中,f表示为两项的点积。第一项:新的自适应网络在去偏置FER数据上的梯度。第二项:旧的自适应网络在偏FR数据上的梯度。如果两个项具有相同/不同的梯度符号,则根据当前梯度的相同/不利条件更新基础网络。点积的绝对值决定了梯度更新的强度。
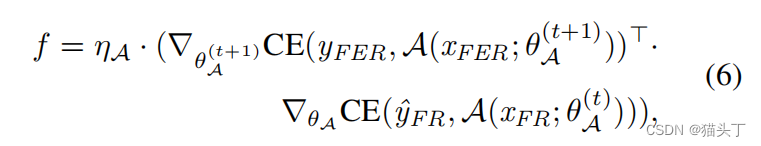 Algorithm for Meta-Face2Exp
Algorithm for Meta-Face2Exp
让我们来看一下完整的算法流程
首先,基础网络从类平衡的FER数据中学习先验表达知识,从而在伪标签生成过程中产生更多的无偏表情预测(B→A)。其次,自适应网络比较去偏FER数据上的认知差异(即更新参数前后),利用反馈损失来更新基础网络的学习,明确解决了FR和FER数据之间的类分布不匹配(A→B)。最后,即使没有标记,自适应网络也具备了去偏表达知识。

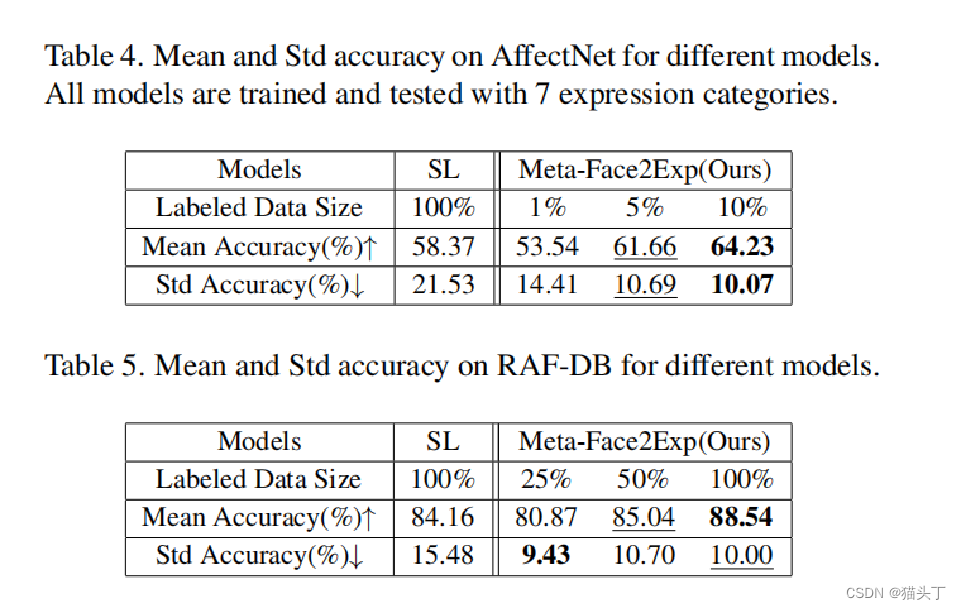
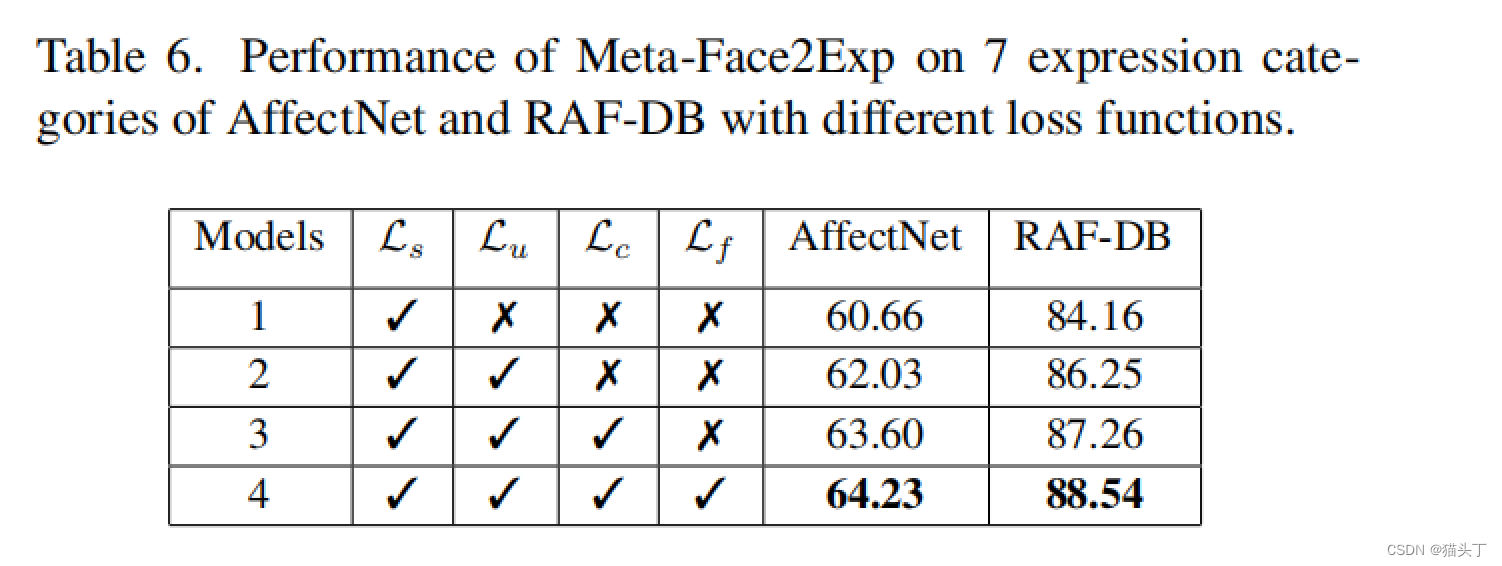
结果展示


![[附源码]计算机毕业设计血库管理系统Springboot程序](https://img-blog.csdnimg.cn/3c2b6b638b034253b52427ea7f3b5c9a.png)




![[附源码]Python计算机毕业设计Django旅游网的设计与实现](https://img-blog.csdnimg.cn/a8a59cf9ec63452083dff9fef71ece3b.png)