目录
一、http协议
1、http协议的介绍
2、URL的组成
3、urlencode和urldecode
二、http的请求方法、状态码及状态码描述、常见的响应报头
1、http请求方法
2、http状态码及状态码描述
3、http常见的响应报头
三、http协议客户端和服务器的通信过程
1、如何保证请求和响应被应用层完整的读取了?
2、请求和响应如何做到序列化和反序列化
3、客户端和服务器通信的全过程
4、获取响应正文的长度
四、http长连接
五、http会话保持(客户端Cookie,服务器session)
六、http相关工具
本文http协议详细代码可参照博主gitee。
一、http协议
1、http协议的介绍
http属于应用层协议。虽然应用层协议是程序员自己定的,但实际上, 已经有前辈们定义了一些现成的, 又非常好用的应用层协议, 供我们参考使用。 http(超文本传输协议) 就是其中之一,这个协议就是用户从服务器拿视频、图片等文件资源的一种协议。(这些资源存放在服务器的磁盘上)
2、URL的组成
平时我们俗称的 "网址" 其实就是说的 URL。
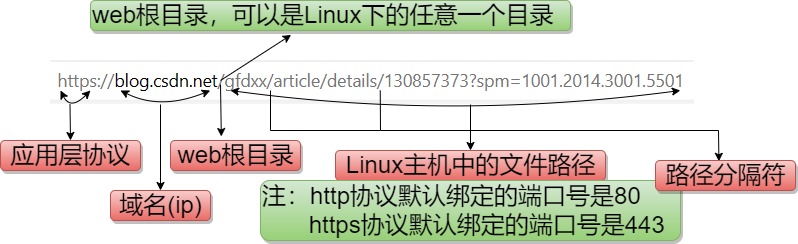
ip会标识一台网络主机,看到"/"就知道这台网络主机用的是Linux系统。使用url就可以通过浏览器请求这台网络主机的服务器,从指定的文件路径下找到用户请求的文件返回给用户。
3、urlencode和urldecode
像 / + : ?等字符, 已经被url特殊处理了。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:取出字符的ASCII码,转成16进制,然后前面加上百分号即可。编码成%XY格式。服务器收到url请求,将会对%XY进行解码,该过程称为decode,如果哪天需要解码了,网上搜一下就行,这不是很重要的东西。

"+" 被转义成了 "%2B"。urldecode就是urlencode的逆过程。
二、http的请求方法、状态码及状态码描述、常见的响应报头
1、http请求方法
| 请求方法 | 说明 | 支持的http协议版本 |
| GET | 获取资源 | 1.0/1.1 |
| POST | 传输实体主体 | 1.0/1.1 |
| 其他方法不常用,略。 | ||
GET和POST方法提交参数的区别
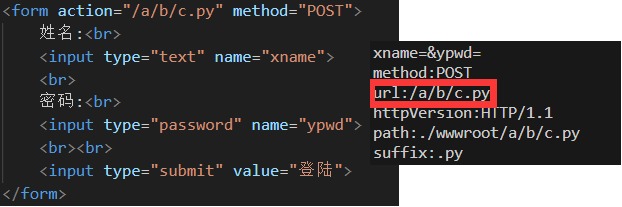
客户端进行数据提交时,是通过前端的from表单提交的,浏览器会将from表单中的内容转换为GET/POST方法。


1、GET方法通过URL传递参数。例如http://ip:port/XXX/YY?key1=value1&key2=value2。像百度的搜索就是用的GET方法。GET方法通过url传递参数,参数注定不能太大,例如上传视频等巨长的二进制文件就不适合用GET了。
2、POST提交参数通过http请求正文提交参数。请求正文可以很大,可以提交视频等巨长的文件。
3、POST方法提交参数,用户是看不到的,私密性更高,而GET方法不私密。私密性不等于安全性,POST方法和GET方法其实都不安全!(http请求都是可以被抓到的,想要安全必须加密,使用https协议)
注意:如果用的是GET方法,需要对url进行额外的处理,例如/test.py?key1=value1&key2=value2,需要拆解出其中的路径(_path),即"test.py"。问号右侧则是参数(_parm)。
if(req._path=="test.py")
{
//建立进程间通信,pipe
//fork创建子进程,execl("/bin/python",test.py)进行进程程序替换
//父进程,将req._parm通过管道写给某些后端语言,例如py、java、php等
//....
return true;
}2、http状态码及状态码描述
HTTP状态码是由服务器返回给客户端的三位数字代码,用于表示客户端请求的处理状态。以下是常见的HTTP状态码及其描述:
1xx(信息性状态码):表示请求已被接收,继续处理。
2xx(成功状态码):表示请求已成功被服务器接收、理解、并接受。
- 200 OK:请求成功。
- 201 Created:请求已经被实现,资源已经被创建。
- 204 No Content:请求成功,但响应报文不含实体的主体部分。
3xx(重定向状态码):客户端发送请求,服务器返回3XX状态码和一个新的URL,客户端拿着这个新的URL再次请求服务器,这就是重定向。
- 301 Moved Permanently:永久性重定向。
- 302 Found:临时性重定向。
- 304 Not Modified:客户端已经执行了GET,但文件未变化。
- 307 Temporary Redirect:临时性重定向。
4xx(客户端错误状态码):表示客户端请求出错,服务器无法处理请求。
- 400 Bad Request:请求报文存在语法错误。
- 401 Unauthorized:未经授权,需要身份验证。
- 403 Forbidden:服务器拒绝请求。
- 404 Not Found:服务器无法找到请求的资源。(属于客户端错误,客户端请求资源在服务器不存在)
5xx(服务器错误状态码):表示服务器处理请求出错。
- 500 Internal Server Error:服务器内部错误。
- 502 Bad Gateway:网关错误。
- 503 Service Unavailable:服务器暂时无法处理请求。
- 504 Gateway Timeout:网关超时。
以307状态码为例,临时重定向至CSDN首页:
std::string respLine="HTTP/1.1 307 Temporary Redirect\r\n";//重定向,配合"Location: "使用
//响应报头
std::string respHeader=suffdeixDesc(req._suffix);//将后缀转换为对应的响应报头
if(req._size>0)
{
respHeader+="Content-Length: ";
respHeader+=std::to_string(req._size);
respHeader+="\r\n";
}
respHeader+="Location: https://www.csdn.net/\r\n";3、http常见的响应报头
HTTP协议常见的响应报头包括:
- Content-Type:指定响应体的MIME类型,例如text/html表示HTML文本,image/jpeg表示JPEG图片等。
- Content-Length:指定响应体的长度,单位为字节。
- Cache-Control:指定缓存控制策略,例如no-cache表示不缓存,max-age=3600表示缓存1小时等。
- Expires:指定响应过期时间,通常与Cache-Control一起使用。
- Last-Modified:指定资源的最后修改时间,用于协商缓存。
- ETag:指定资源的唯一标识符,用于协商缓存。
- Location:搭配3XX状态码使用,指定重定向的目标URL。
- Set-Cookie:指定响应中的Cookie信息。
- Server:指定服务器软件的名称和版本号。
- X-Powered-By:指定服务器使用的编程语言和框架。
三、http协议客户端和服务器的通信过程

以个人云服务器作服务器,浏览器作客户端,服务器打印客户端请求如图:

这个http请求可以看到请求的设备信息,如果在手机端浏览器搜索“微信下载”,浏览器将会返回手机版的微信下载网页,若在电脑浏览器搜索,将会返回电脑版的微信下载网页。
以个人云服务器作服务器,浏览器作客户端,服务器的响应格式:

Content-Type: text/html\r\n用于指示所传输的数据是HTML格式的文本。注意响应报头位置不要打成test了,这些都是设定好的,如果输错了,浏览器请求服务器时,会变成下载html文件!同样的,图片的响应报头写错了,当客户端请求图片时,同样会变成下载逻辑。
1、如何保证请求和响应被应用层完整的读取了?
1、可以读取完整的一行
2、while循环读取行,将所有的请求行和请求报头全部读完,直到遇到空行
3、我们可以保证把请求行和请求报头读完,报头中有Content-Length:XXX(正文长度)
4、通过Content-Length所示的长度,读取对应长度的正文即可。
一个用户看到的网页结果,可能由多个资源组合而成,所以要获取一张完整的网页效果,浏览器会发起多次http请求。所以需要根据客户端的请求信息,在服务器设置好不同的状态行和响应报头。
2、请求和响应如何做到序列化和反序列化
1、http不用关注json等序列化和反序列化工具,直接发送即可。服务器解析客户端的请求,获取其中的信息填充至响应缓冲区。服务器通过响应报头的方式返回请求的参数,在响应正文中返回请求的资源。
2、对于正文部分,如果需要的话,可以设计自定义序列化与反序列化方案。
3、客户端和服务器通信的全过程
void HandlerHttp(int sock)
{
//1、读取完整的http请求
char buffer[4096];
HttpRequest req;
HttpResponse resp;
size_t n=recv(sock,buffer,sizeof(buffer)-1,0);//读取套接字中的内容
if(n>0)
{
buffer[n]=0;//添加'\0'
req._inBuffer=buffer;//获得序列化请求
//2、对客户端请求进行反序列化
//从客户端请求中解析获得请求行(请求方法、请求url、http版本)、请求资源的后缀、请求资源的大小
req.Parse();//对请求进行解析
//3、回调_func方法,由http请求获得http响应 _func(req,resp)
//4、对http响应resp进行序列化
_func(req,resp);
//funcs[req._path](req,resp);
send(sock,resp._outBuffer.c_str(),resp._outBuffer.size(),0);//5、send发送
}
}步骤2反序列化:解析请求行,从url中获取请求的资源路径并计算资源的大小等。
void Parse()//从客户端请求中解析获得请求行(请求方法、请求url、http版本)、请求资源的后缀、请求资源的大小
{
//1、从请求结构体中的_inbuffer中拿到请求行(第一行),分隔符\r\n
std::string line=Util::getOneLine(_inBuffer,sep);
if(line.empty()){return;}
//2、从请求行中获取三个字段:请求方法、请求url、请求版本
//std::cout<<"line:"<<line<<std::endl;
std::stringstream ss(line);
ss>>_method>>_url>>_httpVersion;//以空格为分割读取其中的字段
//2.1如果是GET方法,需要对_url进行额外处理
///search?name=jiang&pwd=123通过?对GET方法进行左右分离(POST本来就是分离的没有问号)
//左边是PATH,右边是_parm
//3、添加web默认路径
_path=defaultRoot;//客户端所有请求路径前都会被加上./wwwroot前导目录字符串
_path+=_url;//如果客户端请求a/b/c.html,则会请求./wwwroot/a/b/c.html
if(_path[_path.size()-1]=='/')//如果请求的是web根目录(./wwwroot/),就让它访问设定好的默认首页的路径(./wwwroot/index.html)
{
_path+=homePage;
}
//4、获取path对应的资源后缀
//./wwwroot/index.html
//./wwwroot/test/a.html
//./wwwroot/test/b.html
//./wwwroot/image/dog.jpg
auto pos=_path.rfind(".");
if(pos==std::string::npos){_suffix=".html";}//实在找不到,先给个html
else{_suffix=_path.substr(pos);}
//5、得到响应正文的大小(客户端请求资源的大小)
struct stat st;
int n=stat(_path.c_str(),&st);
if(0==n)
{
_size=st.st_size;
}
else{_size=-1;}
}步骤3、4,由客户端请求转换为客户端响应(设置一下不同响应方法的状态行、响应报头、响应正文等信息,这里的响应正文是html和图片)
bool Get(const HttpRequest& req,HttpResponse& resp)
{
// if(req._path=="test.py")
// {
// //建立进程间通信,pipe
// //fork创建子进程,execl("/bin/python",test.py)进行进程程序替换
// //父进程,将req._parm通过管道写给某些后端语言,例如py、java、php等
// //....
// return true;
// }
// if(req._path=="/search")
// {
// //如果PATH是"/search",可以在这里写具体的C++方法,提供相应的服务
// //....
// return true;
// }
//打印客户端的请求的一些信息
std::cout<<"-----------httpStart------------"<<std::endl;
std::cout<<req._inBuffer<<std::endl;
std::cout<<"method:"<<req._method<<std::endl;
std::cout<<"url:"<<req._url<<std::endl;
std::cout<<"httpVersion:"<<req._httpVersion<<std::endl;
std::cout<<"path:"<<req._path<<std::endl;
std::cout<<"suffix:"<<req._suffix<<std::endl;
std::cout<<"size:"<<req._size<<"字节"<<std::endl;
std::cout<<"-----------httpEnd--------------"<<std::endl;
//服务器的状态行、响应报头、空行、响应正文等信息
//状态行
std::string respLine="HTTP/1.1 200 OK\r\n";
//std::string respLine="HTTP/1.1 307 Temporary Redirect\r\n";//重定向,配合"Location: "使用
//响应报头
std::string respHeader=suffdeixDesc(req._suffix);//将后缀转换为对应的响应报头
if(req._size>0)
{
respHeader+="Content-Length: ";
respHeader+=std::to_string(req._size+1);//为了和后面的body.size()大小匹配
respHeader+="\r\n";
}
//respHeader+="Location: https://www.csdn.net/\r\n";
//写入Cookie
respHeader+="Set-Cookie: name=12345abcde;Max-Age=120\r\n";//设置Cookie响应报头
//往后,每次http请求都会自动携带曾经设置的所有Cookie,帮助服务器的鉴权行为
//空行
std::string respBlack="\r\n";
std::string body;
body.resize(req._size+1);
if(!Util::readFile(req._path,(char*)body.c_str(),req._size))//将_path路径下的文件内容读到buffer里
{
Util::readFile(html_404,(char*)body.c_str(),req._size);//访问的资源不存在,body的路径就是404html的路径
respLine="HTTP/1.1 404 Not Found\r\n";//同时,状态行修改为404
}
std::cout<<"-----------httpStart------------"<<std::endl;
std::cout<<(respLine+respHeader+respBlack)<<std::endl;
std::cout<<"-----------httpEnd--------------"<<std::endl;
resp._outBuffer=respLine+respHeader+respBlack+body;
return true;
}4、获取响应正文的长度
STAT(2)
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *path, struct stat *buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *path, struct stat *buf);struct stat {
dev_t st_dev; // 包含文件的设备ID
ino_t st_ino; // inode号
mode_t st_mode; // 文件保护模式
nlink_t st_nlink; // 硬链接数
uid_t st_uid; // 文件所有者的用户ID
gid_t st_gid; // 文件所有者的组ID
dev_t st_rdev; // 设备ID(如果是特殊文件)
off_t st_size; // 总大小,以字节为单位
blksize_t st_blksize; // 文件系统I/O的块大小
blkcnt_t st_blocks; // 分配的512B块数
time_t st_atime; // 上次访问时间
time_t st_mtime; // 上次修改时间
time_t st_ctime; // 上次状态更改时间
};用途:函数stat用于获取文件的状态信息,包括文件类型、文件大小、文件权限等。函数stat只能获取普通文件、目录、符号链接等文件的状态信息,无法获取设备文件等特殊文件的状态信息。
参数:
- path:文件路径
- buf:存储文件状态信息的结构体指针
返回值:函数返回值为0表示成功,-1表示失败。
得到_path路径下的文件大小,单位字节:
struct stat st;
int n=stat(_path.c_str(),&st);
if(0==n)
{
_size=st.st_size;
}
else{_size=-1;}四、http长连接
http请求是基于tcp协议的,而tcp是需要进行连接的。对于一个网页,可能包含多种元素,则需要发起多次连接。为了减少连接次数,需要客户端和服务器均支持长链接,建立一条连接,传输一份大的资源通过一条连接完成。
Connection: keep-alive
Connection: close如果报头的"Connection: "显示是"keep-alive",则代表支持长连接。
五、http会话保持(客户端Cookie,服务器session)
例如我们打开哔哩哔哩的首页进行登录操作,哪怕用户马上把浏览器关了,短期内再次访问哔哩哔哩是不需要用户重复登录操作的。同样的,当我们在哔哩哔哩进行页面跳转时,http协议并不会记录用户信息,但是曾经的用户登录信息在页面跳转时并不会丢失。浏览器仍会记住上一次登录的信息。这就是会话保持。
其实http请求是无状态的,每次请求并不会记录它曾经请求了什么。所以会话保持不是http协议天然具备的特点,而是浏览器为了满足用户的使用需求,做了相应的工作。
用户在第一次输入账号和密码时,浏览器会进行保存(Cookie),近期再次访问同一个网站,浏览器会自动将用户信息推送给服务器。像哔哩哔哩中某些需要大会员才能观看的视频,服务器都会先获取用户信息进行身份判断,用的就是浏览器缓存的信息。这样只要用户首次输入密码,一段时间内将不用再做登录操作了。
但是本地的Cookie如果被不法分子拿到,那不是危险了,所以信息的保存是在服务器上完成的,服务器会对每个用户创建一份独有的session id,并将其返回给浏览器,浏览器存到Cookie的其实是session id。但这样只能保证原始的账号密码不会被泄漏,黑客盗取了用户的session id后仍可以非法登录,只能靠服务端的安全策略保障安全,例如账号被异地登录了,服务端察觉后只要让session id失效即可,这样异地登录将会使用户重新验证账号密码或手机或人脸信息(尽可能确保是本人),一定程度上保障了信息的安全。

服务器向客户端返回Cookie:
//写入Cookie
respHeader+="Set-Cookie: name=12345abcde; Max-Age=120\r\n";//设置Cookie响应报头,有效期2分钟
//往后,每次http请求都会自动携带曾经设置的所有Cookie,帮助服务器的鉴权行为————http会话保持
六、http相关工具
1、postman——能够模拟客户端浏览器的行为。
2、fiddler——一个本地抓包工具,作为http调试使用。(能够明文抓到本地的POST方法请求正文!)

所以http协议并不安全,想要安全还得看https协议......