目录
- 表的增删改查
- create(创建)
- 单行数据 + 全列插入
- 多行数据 + 指定列插入
- 插入否则更新
- 替换
- retrieve(读取)
- SELECT 列
- 全列查询
- 指定列查询
- 查询字段为表达式
- 为查询结果指定别名
- 结果去重
- WHERE 条件
- 英语不及格的同学及英语成绩 ( < 60 )(<)
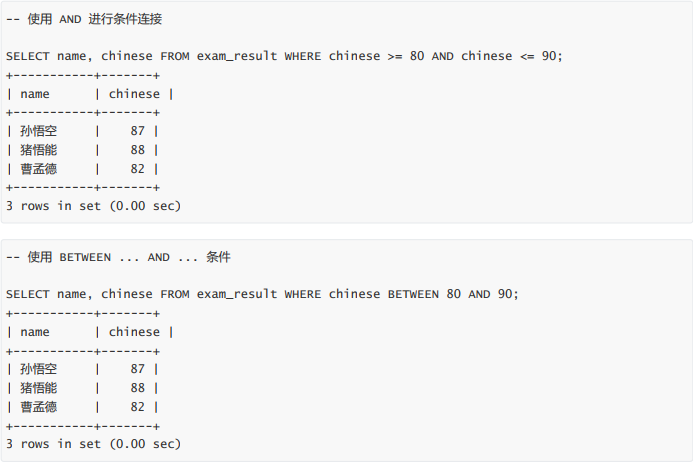
- 语文成绩在 [80, 90] 分的同学及语文成绩(and , between ... and...)
- 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩(or, in)
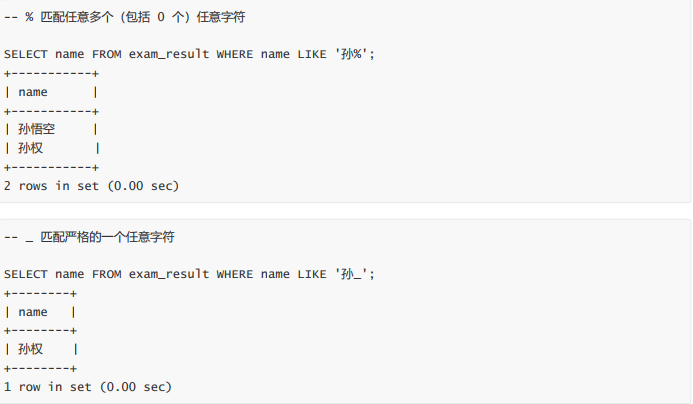
- 姓孙的同学 及 孙某同学(%, like)
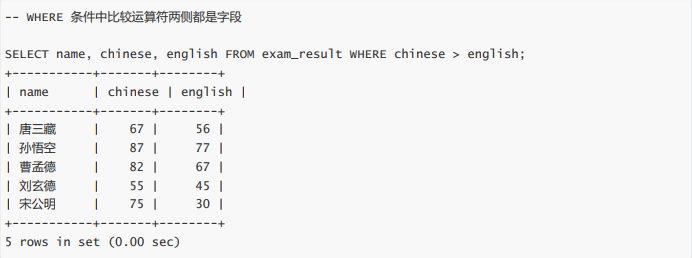
- 语文成绩好于英语成绩的同学(where)
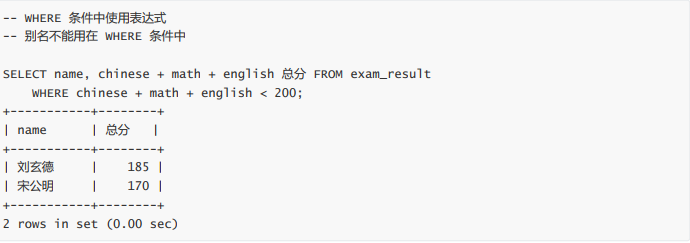
- 总分在 200 分以下的同学(where)
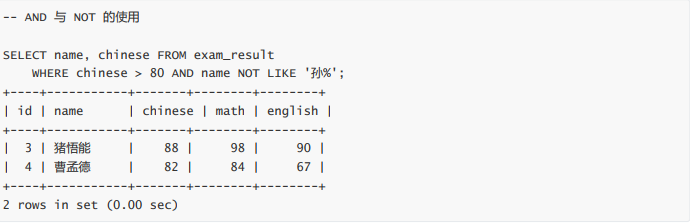
- 语文成绩 > 80 并且不姓孙的同学(and,not)
- 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80(综合)
- NULL 的查询
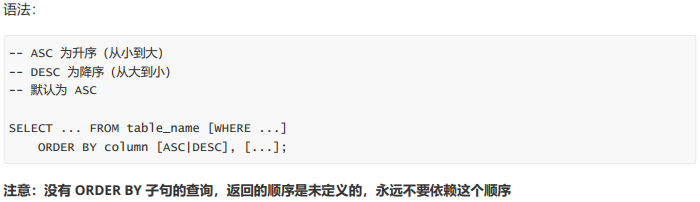
- 结果排序
- 同学及数学成绩,按数学成绩升序显示
- 同学及 qq 号,按 qq 号排序显示
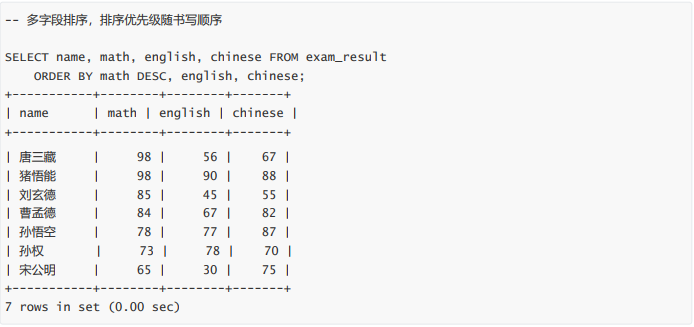
- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
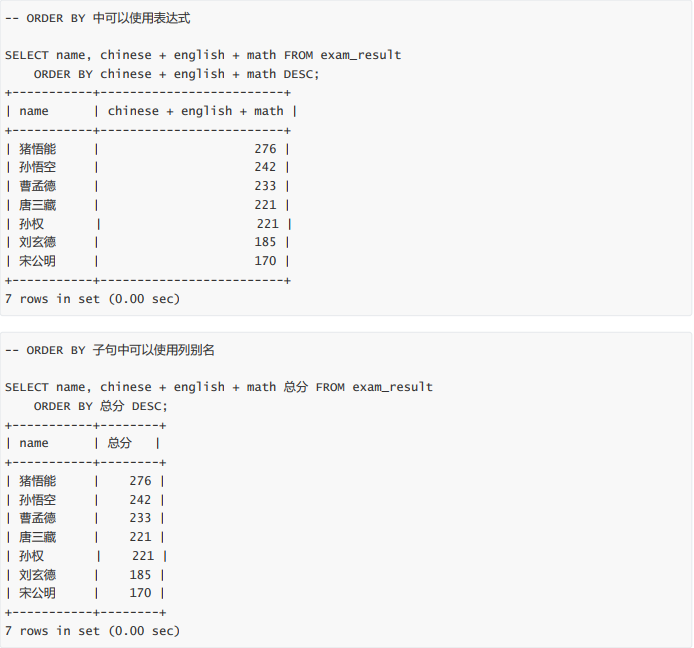
- 查询同学及总分,由高到低
- 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
- 筛选分页结果
- update(更新)
- 将孙悟空同学的数学成绩变更为 80 分
- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
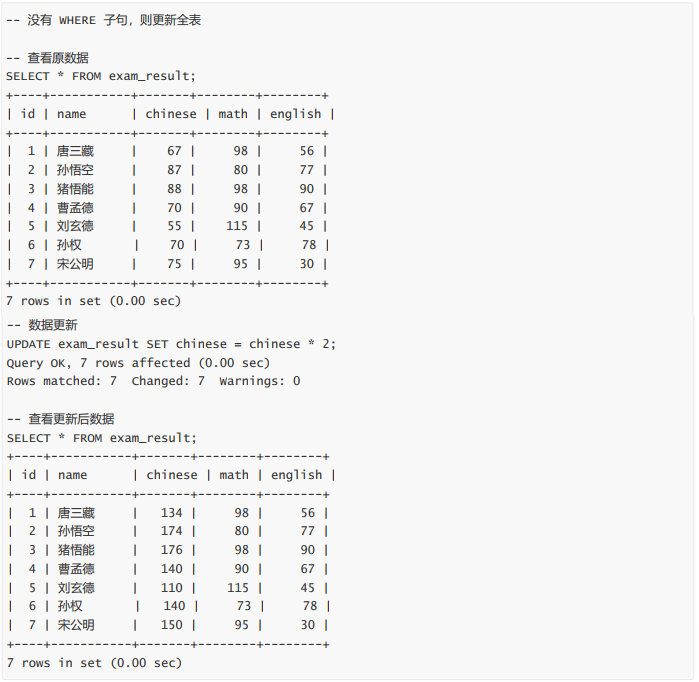
- 将所有同学的语文成绩更新为原来的 2 倍
- delete(删除)
- 删除孙悟空同学的考试成绩
- 删除整张表数据
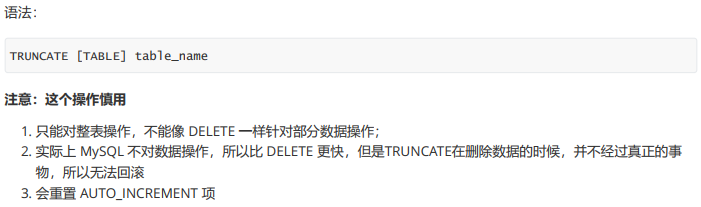
- 截断表
- 插入查询结果
- 聚合函数
- 统计班级共有多少同学
- 统计班级收集的 qq 号有多少
- 统计本次考试的数学成绩分数个数
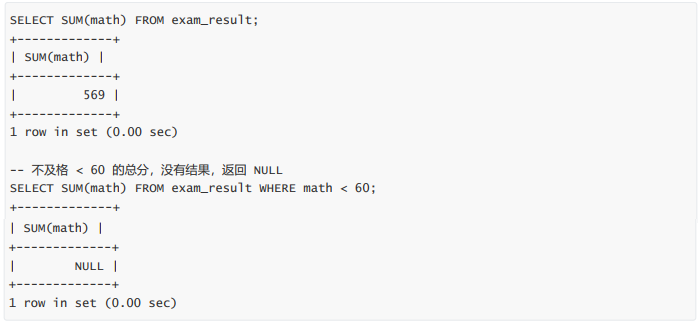
- 统计数学成绩总分
- 统计平均总分
- 返回英语最高分
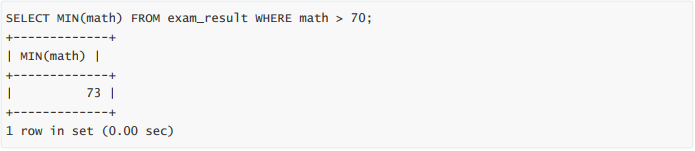
- 返回 > 70 分以上的数学最低分
- group by子句的使用
- 顺序
表的增删改查
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
create(创建)
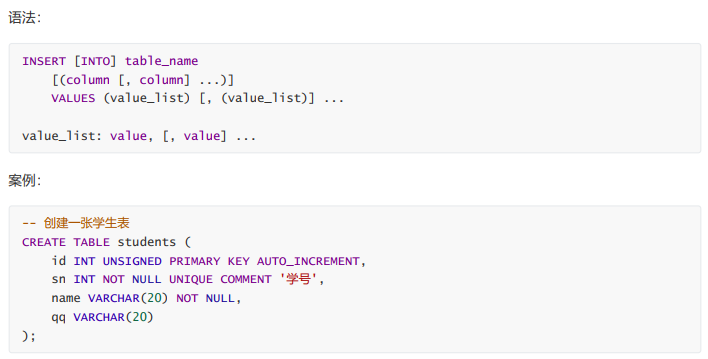
单行数据 + 全列插入

多行数据 + 指定列插入
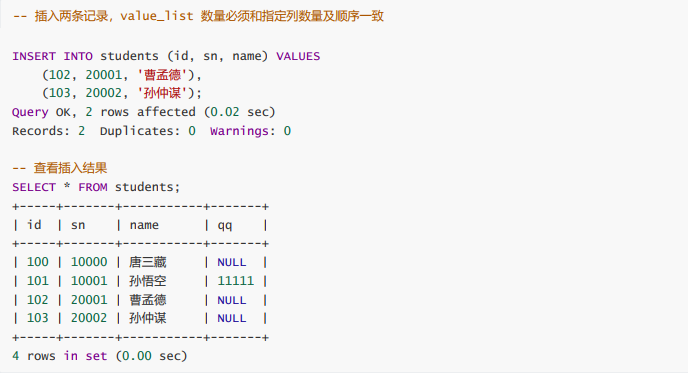
插入否则更新
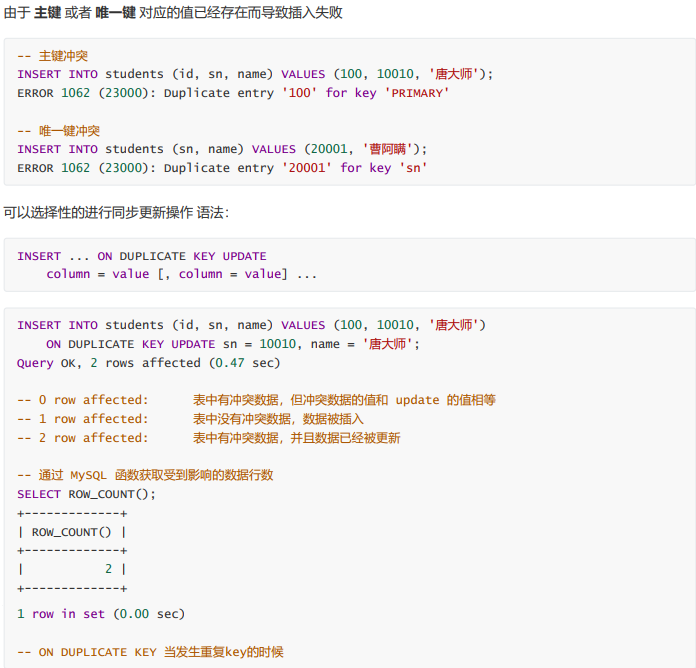
替换
retrieve(读取)
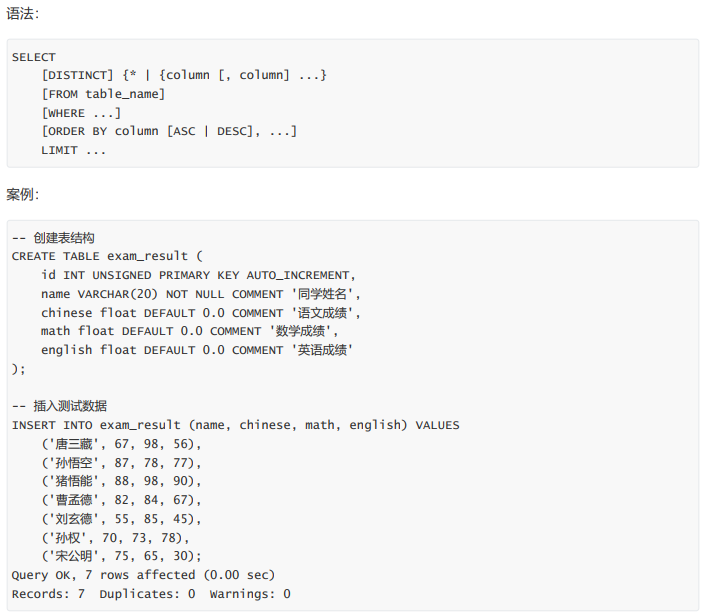
SELECT 列
全列查询
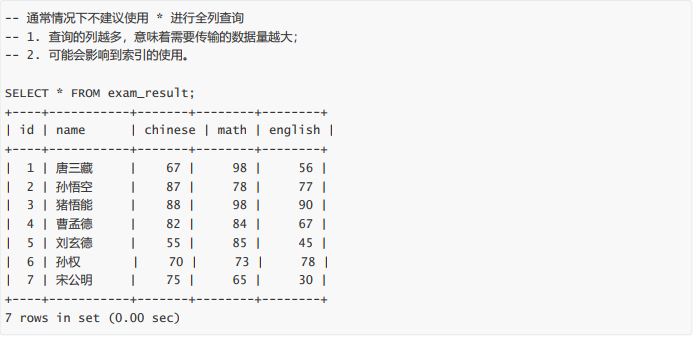
指定列查询
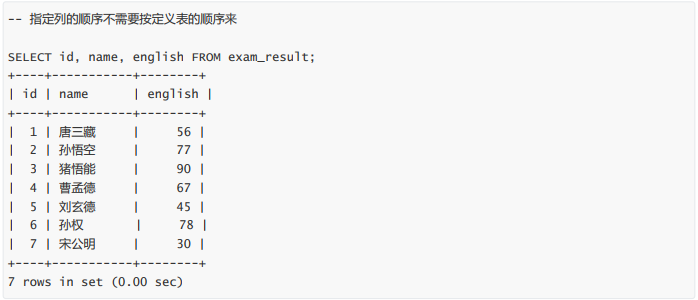
查询字段为表达式

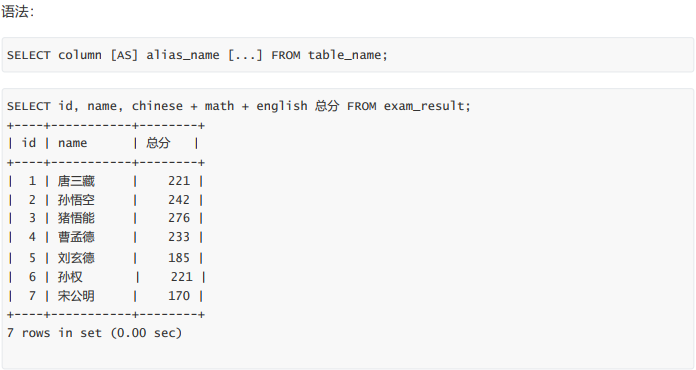
为查询结果指定别名
结果去重
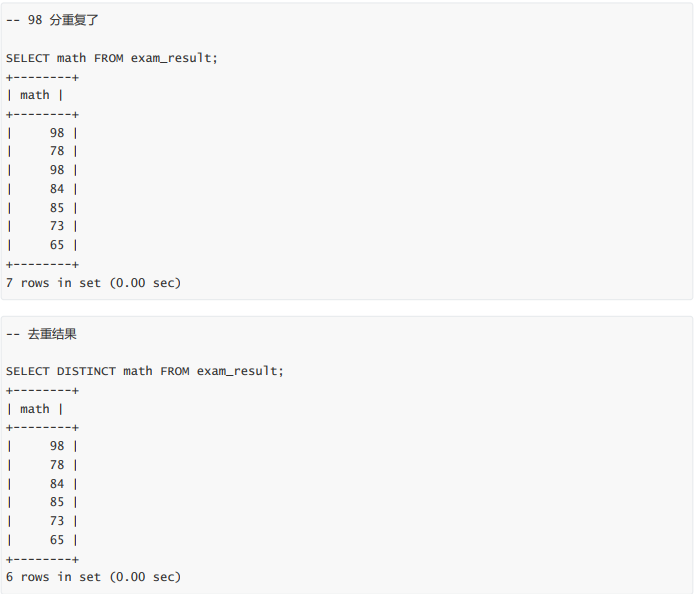
WHERE 条件
-
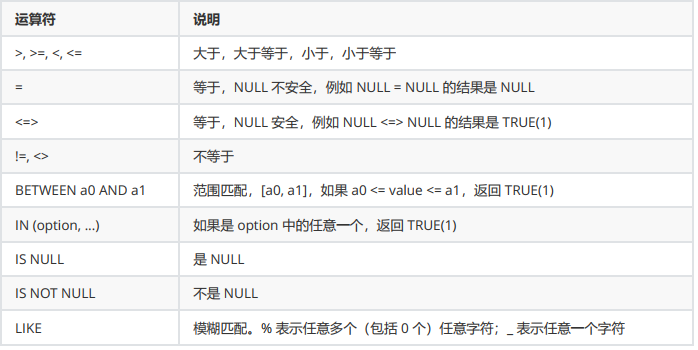
比较运算符:
-
逻辑运算符:
-
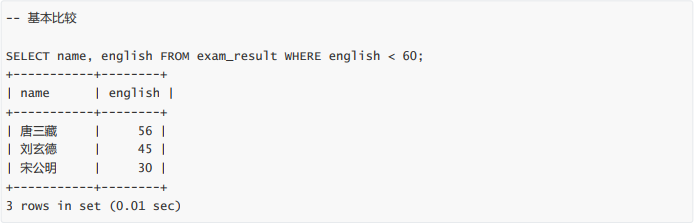
英语不及格的同学及英语成绩 ( < 60 )(<)
语文成绩在 [80, 90] 分的同学及语文成绩(and , between … and…)
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩(or, in)

姓孙的同学 及 孙某同学(%, like)
语文成绩好于英语成绩的同学(where)
总分在 200 分以下的同学(where)
语文成绩 > 80 并且不姓孙的同学(and,not)
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80(综合)

NULL 的查询

结果排序
同学及数学成绩,按数学成绩升序显示
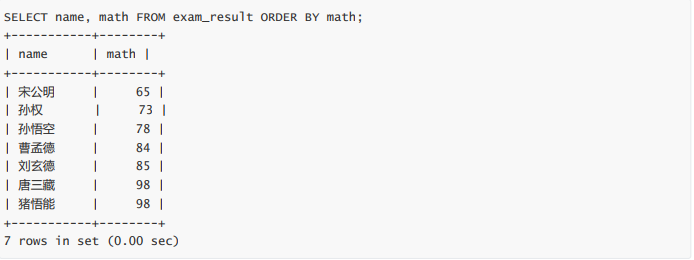
同学及 qq 号,按 qq 号排序显示
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
查询同学及总分,由高到低
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示

筛选分页结果


update(更新)

将孙悟空同学的数学成绩变更为 80 分

将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分

将总成绩倒数前三的 3 位同学的数学成绩加上 30 分

将所有同学的语文成绩更新为原来的 2 倍
delete(删除)

删除孙悟空同学的考试成绩

删除整张表数据

截断表

插入查询结果

聚合函数
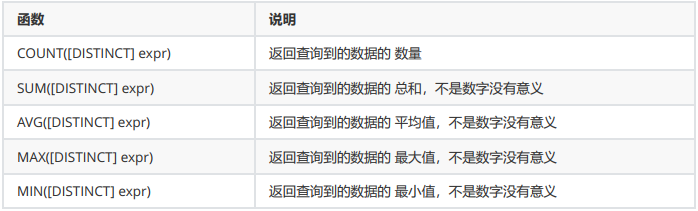
统计班级共有多少同学
统计班级收集的 qq 号有多少

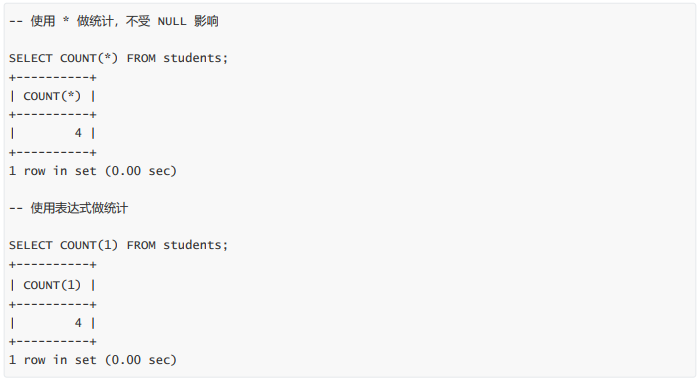
统计本次考试的数学成绩分数个数
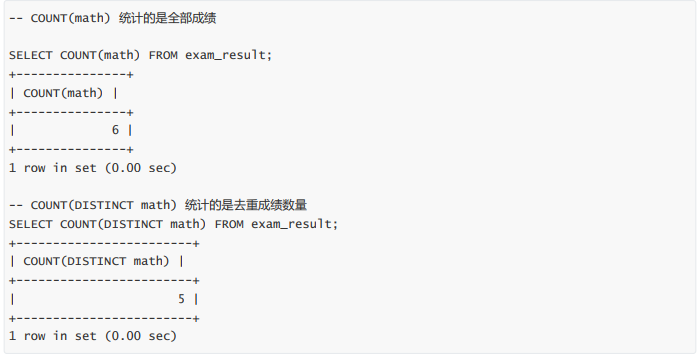
统计数学成绩总分
统计平均总分

返回英语最高分

返回 > 70 分以上的数学最低分
group by子句的使用
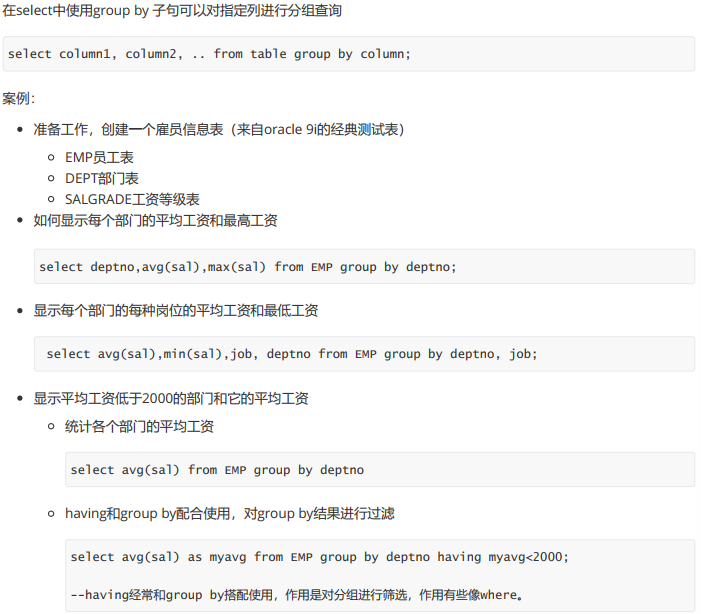
- group by是通过分组这样的手段,为未来进行聚合统计提供基本的功能支持(group by一定是配合聚合统计使用的)
- groupby后面跟的都是分组的字段依据,只有在group by后面出现的字段,未来在聚合统计的时候,在select中才能出现.
- where VS having: 他们两个不是冲突的,是互相补充的
- having通常: 是在完成整个分组聚合统计,然后再进行筛选
- where通常: 是在表中数据初步被筛选的时候,要起效果的
顺序
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit











![[CISCN2023]unzip](https://img-blog.csdnimg.cn/img_convert/d0e073c6d0630db679f232e437e0a3ae.png)
