dpdk ip报文重组及分片API及处理逻辑介绍
DPDK的分片和重组实现零拷贝,详细介绍可以参阅DPDK分片与重组用户手则
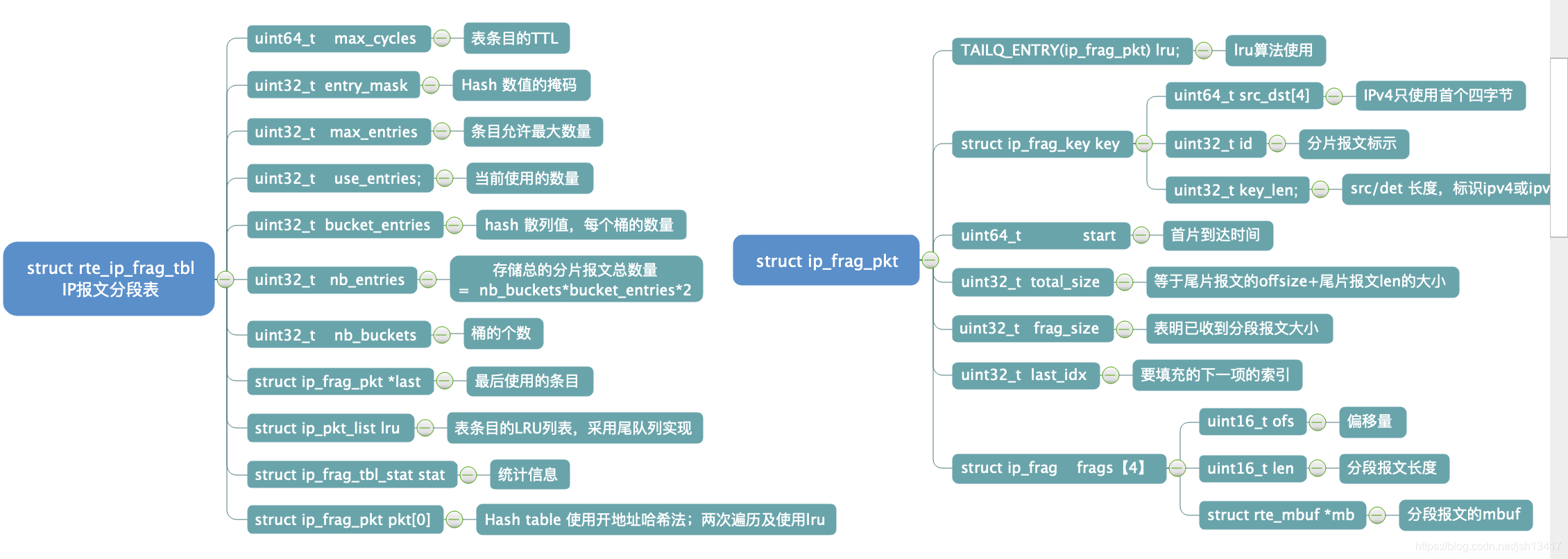
相关数据结构
/*
* Fragmented packet to reassemble.
* First two entries in the frags[] array are for the last and first fragments.
*/
struct ip_frag_pkt {
RTE_TAILQ_ENTRY(ip_frag_pkt) lru; /* LRU list */
struct ip_frag_key key; /* fragmentation key */
uint64_t start; /* creation timestamp */
uint32_t total_size; /* expected reassembled size */
uint32_t frag_size; /* size of fragments received */
uint32_t last_idx; /* index of next entry to fill */
struct ip_frag frags[IP_MAX_FRAG_NUM]; /* fragments */
} __rte_cache_aligned;
/* fragmentation table */
struct rte_ip_frag_tbl {
uint64_t max_cycles; /* ttl for table entries. */
uint32_t entry_mask; /* hash value mask. */
uint32_t max_entries; /* max entries allowed. */
uint32_t use_entries; /* entries in use. */
uint32_t bucket_entries; /* hash associativity. */
uint32_t nb_entries; /* total size of the table. */
uint32_t nb_buckets; /* num of associativity lines. */
struct ip_frag_pkt *last; /* last used entry. */
struct ip_pkt_list lru; /* LRU list for table entries. */
struct ip_frag_tbl_stat stat; /* statistics counters. */
__extension__ struct ip_frag_pkt pkt[]; /* hash table. */
};
相关API
/**
* Create a new IP fragmentation table.
*
* @param bucket_num
* Number of buckets in the hash table. // 哈希表桶数量
* @param bucket_entries
* Number of entries per bucket (e.g. hash associativity). // 每个桶下挂在的节点数量
* Should be power of two. // 应该为2的幂次方
* @param max_entries
* Maximum number of entries that could be stored in the table. // 哈希表存储的最大节点数量
* The value should be less or equal then bucket_num * bucket_entries. // 该值需小于或等于 桶数量 * 桶节点数量
* @param max_cycles
* Maximum TTL in cycles for each fragmented packet. // 每个分片包最长超时时间(TTL)
* @param socket_id
* The *socket_id* argument is the socket identifier in the case of
* NUMA. The value can be *SOCKET_ID_ANY* if there is no NUMA constraints.
* @return
* The pointer to the new allocated fragmentation table, on success. NULL on error. // 返回值为哈希表的地址,创建失败则为NULL
*/
struct rte_ip_frag_tbl *
rte_ip_frag_table_create(uint32_t bucket_num, uint32_t bucket_entries,
uint32_t max_entries, uint64_t max_cycles, int socket_id)
{
struct rte_ip_frag_tbl *tbl;
size_t sz;
uint64_t nb_entries;
nb_entries = rte_align32pow2(bucket_num);
nb_entries *= bucket_entries;
nb_entries *= IP_FRAG_HASH_FNUM;
/* check input parameters. */
if (rte_is_power_of_2(bucket_entries) == 0 ||
nb_entries > UINT32_MAX || nb_entries == 0 ||
nb_entries < max_entries) {
RTE_LOG(ERR, USER1, "%s: invalid input parameter\n", __func__);
return NULL;
}
sz = sizeof (*tbl) + nb_entries * sizeof (tbl->pkt[0]);
if ((tbl = rte_zmalloc_socket(__func__, sz, RTE_CACHE_LINE_SIZE,
socket_id)) == NULL) {
RTE_LOG(ERR, USER1,
"%s: allocation of %zu bytes at socket %d failed do\n",
__func__, sz, socket_id);
return NULL;
}
RTE_LOG(INFO, USER1, "%s: allocated of %zu bytes at socket %d\n",
__func__, sz, socket_id);
tbl->max_cycles = max_cycles;
tbl->max_entries = max_entries;
tbl->nb_entries = (uint32_t)nb_entries;
tbl->nb_buckets = bucket_num;
tbl->bucket_entries = bucket_entries;
tbl->entry_mask = (tbl->nb_entries - 1) & ~(tbl->bucket_entries - 1);
TAILQ_INIT(&(tbl->lru));
return tbl;
}
创建rte_ip_frag_tbl结构,用来暂存分片的表。其中max_cycles表示分片报文超时时间TTL,如10ms:
frag_cycle = (rte_get_tsc_hz()) + MS_PER_S –1) / MS_PER_S * 10;
rte_get_tsc_hz() 函数返回的是1s的CPU频率是多少HZ, 然后按毫秒到秒的进制转换对该值进行一个向上取整得到每一毫秒的CPU频率。之后乘以10就是10毫秒的CPU cycle了。
整个哈希表总的条目数nb_entries = bucket_num * bucket_entries * IP_FRAG_HASH_FNUM(2),后续哈希的时候也会同时查出两个bucket位置。
申请的总内存 sz = sizeof (*tbl) + nb_entries * sizeof (tbl->pkt[0]);
这里分配的是一段连续的内存,减少内存的碎片化。可变长部分可以使用entry_mask 按数组的方式访问所有nb_entries,详见ip_frag_lookup。
/*NO.2使用IPV4包的片段处理新的mbuf。传入的mbuf应该有它的l2_len/l3_len字段设置正确。
*返回值,1)指向重新组装包的mbuf指针,
*。 2)NULL;报文为收全;或者收取报文有错误,无法重组。
*. 这里需要注意重组后的ip的checksum字段为0,需要自己更新。
*/
struct rte_mbuf *
rte_ipv4_frag_reassemble_packet(struct rte_ip_frag_tbl *tbl,
struct rte_ip_frag_death_row *dr, struct rte_mbuf *mb, uint64_t tms,
struct ipv4_hdr *ip_hdr);

每个IP数据包由三个字段:<源IP地址>,<目标IP地址>,唯一标识。
请注意,报文分片表上的所有更新/查找操作都不是线程安全的。因此,如果不同的执行上下文(线程/进程)要同时访问同一个表,那么必须提供一些外部同步机制。每个表项可以保存最多RTE_LIBRTE_IP_FRAG_MAX(默认值为64)片段的数据包的信息。
ip_frag_lookup 利用ipv4_frag_hash获取两个sig值,再利用entry_mask获取到两个bucket的位置,后面紧跟着的位置就是bucket对应的entries。
#define IP_FRAG_TBL_POS(tbl, sig) \
((tbl)->pkt + ((sig) & (tbl)->entry_mask))
struct ip_frag_pkt *
ip_frag_lookup(struct rte_ip_frag_tbl *tbl,
const struct ip_frag_key *key, uint64_t tms,
struct ip_frag_pkt **free, struct ip_frag_pkt **stale)
{
struct ip_frag_pkt *p1, *p2;
struct ip_frag_pkt *empty, *old;
uint64_t max_cycles;
uint32_t i, assoc, sig1, sig2;
empty = NULL;
old = NULL;
max_cycles = tbl->max_cycles;
assoc = tbl->bucket_entries;
if (tbl->last != NULL && ip_frag_key_cmp(key, &tbl->last->key) == 0)
return tbl->last;
/* different hashing methods for IPv4 and IPv6 */
if (key->key_len == IPV4_KEYLEN)
ipv4_frag_hash(key, &sig1, &sig2);
else
ipv6_frag_hash(key, &sig1, &sig2);
p1 = IP_FRAG_TBL_POS(tbl, sig1);
p2 = IP_FRAG_TBL_POS(tbl, sig2);
for (i = 0; i != assoc; i++) {
if (ip_frag_key_cmp(key, &p1[i].key) == 0)
return p1 + i;
else if (ip_frag_key_is_empty(&p1[i].key))
empty = (empty == NULL) ? (p1 + i) : empty;
else if (max_cycles + p1[i].start < tms)
old = (old == NULL) ? (p1 + i) : old;
if (ip_frag_key_cmp(key, &p2[i].key) == 0)
return p2 + i;
else if (ip_frag_key_is_empty(&p2[i].key))
empty = (empty == NULL) ?( p2 + i) : empty;
else if (max_cycles + p2[i].start < tms)
old = (old == NULL) ? (p2 + i) : old;
}
*free = empty;
*stale = old;
return NULL;
}
参考资料:
https://zhuanlan.zhihu.com/p/578599037
https://blog.csdn.net/sjin_1314/article/details/105747246/





![[Kubernetes] - RabbitMQ学习](https://img-blog.csdnimg.cn/b52b244bfa1449eb933c7ca092ab3164.png)
![[golang 微服务] 2. RPC架构介绍以及通过RPC实现微服务](https://img-blog.csdnimg.cn/img_convert/cbf56f2685886070177a17f081dea581.png)
