接触异常检测领域也有一年多的时间了,过程中遇到不少坑,知识体系也在不断更新完善,这里以专题的形式进行知识体系的梳理~
异常检测(Anomaly Detection, AD)领域内的划分体系较多,这里基于异常检测最常用到的PyOD库作者的几篇综述Paper,进行如下划分:
-
Tabular AD
-
Time-series AD
-
Graph data AD
本篇文章介绍第一部分,Tabular AD内的相关工作,后续将继续以专题文章形式进行更新,欢迎关注~
Tabular Data
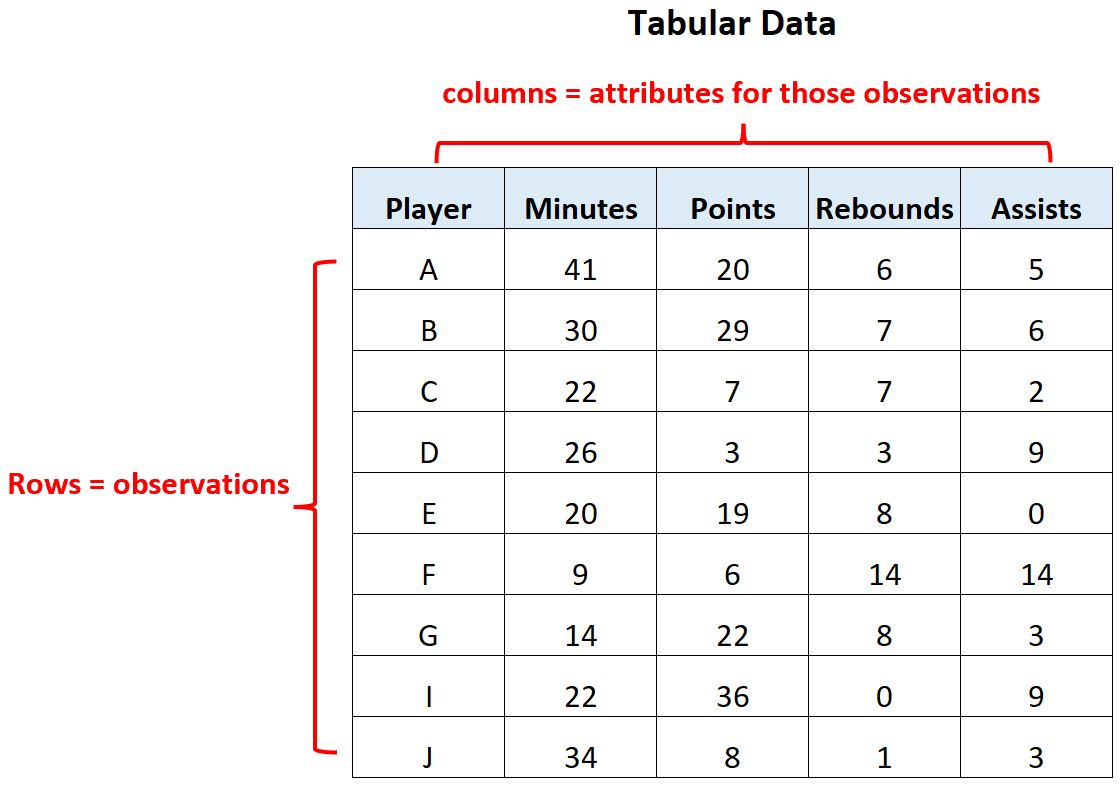
对于一个具体的业务场景,我们所能够获得的数据往往是Tabular、Time-series、Graph等格式,其中Tabular格式的数据(即表格型数据)如上图所示
当我们决定使用AD算法对表格型数据进行异常检测时,我们工作的重点往往会放在特征加工(增加更多便于AD的列)和算法选型上,特征加工往往与具体业务场景相关,这里不赘述;而算法选型从大的角度来看,往往被分为无监督、监督和半监督方法,不同方法之间没有绝对的优劣,需要结合具体业务场景进行效果评估
就目前大家的经验来看算法选型:当业务场景中 存在/易获得 标注数据时,监督方法往往效果更佳,但由于涉及到有标注数据集加工等环节,算法迭代速度可能较慢;无监督方法迭代速度较快,但算法选型上需要仔细考虑,且算法效果常不稳定;半监督方法因本人还未在AD业务场景中尝试过,这里不展开。这里写的只是粗略的经验之说,文末会给出笔者认为较为可靠的算法选型实验等相关结论
算法选型的确重要,很多文章都已经详细介绍了各种AD算法,但AD算法众多 且算法设计优化的时间往往有限,相比不断地实验试错,一个好的AD方法论至关重要。后文会先介绍一下Tabular AD视角下的异常类型,然后快速过一下Tabular AD算法的相关工作,给出笔者认为较为可靠的算法选型实验结论,最后给出一个提炼后的AD任务方法论
Type of Anomalies
大家常见的AD任务异常类型往往是点异常、上下文异常和集体异常:
-
点异常:单个数据实例相对于其余数据是异常的
-
上下文(条件)异常:在特定上下文中异常,其他情况下不异常。由两个属性定义:上下文属性,如时间序列数据中,时间就是上下文属性;行为属性,如时间序列数据中,某个时刻对应的特征值就是行为属性
-
集体异常:相关数据实例的集合相对于整个数据集是异常的,但集合中的各个数据实例可能是正常的
对具体业务场景中异常类型的明确 与后续特征加工、算法选型、优化迭代等环节息息相关,明确的异常类型将有助于我们高效开展后续工作。进一步地,这里参考ADBench论文中对Tabular AD视角下异常类型的划分,其对点异常进一步细分为Local和Global异常,如下图所示:

Tabular AD视角下异常类型的划分:
-
Local:不同于局部范围内近邻的异常点
-
Global:明显偏离其余数据点的点
-
Dependency:类似“上下文异常”
-
Clustered:类似“集体异常”
Related Work
对各个AD算法的介绍太多,这里不赘述了,只给出分类体系
无监督
浅层
IForest
OCSVM
ECOD
深度
DAGMM
DeepSVDD
监督
朴素贝叶斯
SVM
MLP
RF
Ensemble:XGBoost、LightGBM、CatBoost
CV:ResNet
NLP:Transformer
半监督
DeepSAD
DevNet
XGBOD
PReNet
FEAWAD
Experimental Conclusion
各结论均整理自ADBench论文实验,且在实操中 大部分结论能对上,具有一定的参考性~
-
无监督AD算法中,根据异常类型进行算法选择最重要,没有总是最优的无监督算法
-
无监督深度AD方法如DeepSVDD、DAGMM效果往往一般
-
推荐使用IForest或ECOD进行快速POC
- 异常标注量较少时,半监督方法优于监督方法;异常标记量较多时,两者性能类似
-
大部分半监督方法,1%异常标记就足以超过最佳无监督方法(假设当前数据集中有100条异常数据,1%指只使用1条异常数据)
-
大部分监督方法,需要10%的异常标记才能超过最佳无监督方法
-
当业务场景中 存在/易获得 标注数据时,Transformer、集成类方法效果不会太差
- 确定异常类型的重要性:专门针对特定类型异常的无监督算法甚至优于半监督/全监督算法
-
无监督算法在特定异常类型下的效果不错,但在真实数据集上效果较差;但进一步地,从理论上,如果已知真实场景中的异常类型,通过对应无监督算法的混合,可能能够得到不错的效果
-
异常类型作为先验知识所带来的效果 可能优于 单纯标签的使用

- 监督/半监督算法的鲁棒性往往较强
-
无监督方法面对重复异常的干扰 鲁棒性较差
AD Methodology
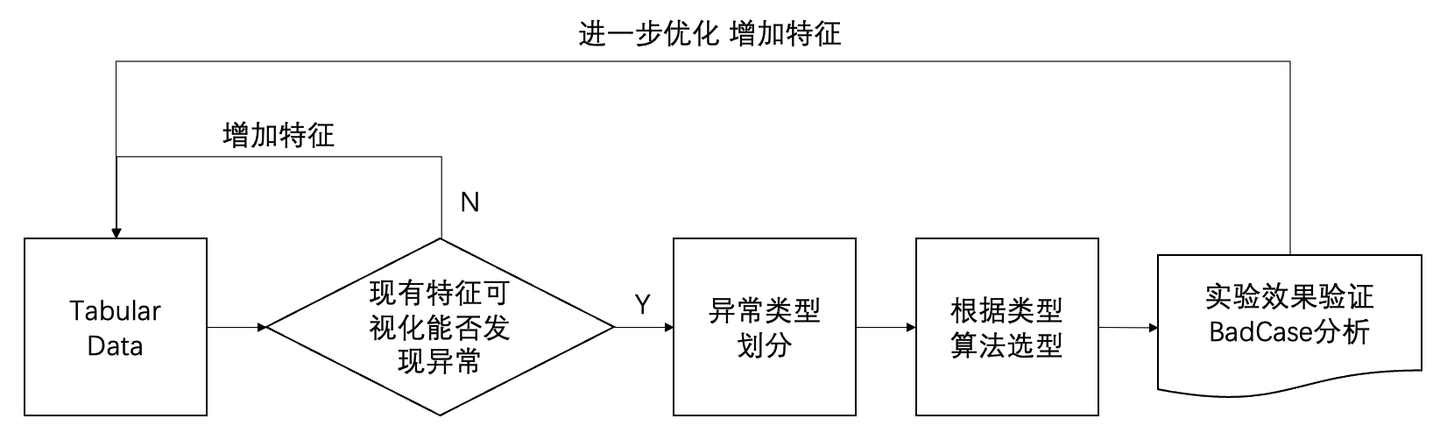
具体业务场景中,往往业务逻辑复杂,AD算法选择众多,一个好的方法论有助于我们进行算法的快速选型和优化迭代,整个方法论的思路如上图所示,在拿到具体业务中的Tabular Data后:
-
就现有特征进行数据点的可视化,判断现有特征是否能够发现异常
-
若无法发现异常,则在基于业务理解基础上增加特征后,继续1;若能发现 则继续3
-
基于可视化情况,判断异常所属类型
-
基于Experimental Conclusion中的结论进行算法选型
-
实验效果验证,BadCase分析,进一步优化,增加新特征,继续1




![[元带你学: eMMC协议详解 11] Data transfer mode 数据传输模式](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)




![[电脑使用技巧]Windows 11安装安卓手机APP](https://img-blog.csdnimg.cn/17819950203441bfba9f50b4bbbd104a.png)