文章目录
- 一、分析容器系统调用:Sysdig
- 1.1. 安装
- 1.2 常用参数
- 1.3 采集分析
- 1.4 示例
- 1.4.1 查看某进程系统调用事件
- 1.4.2 查看建立TCP连接事件
- 1.4.3 查看某目录下打开的文件描述符
- 1.4.4 查看容器的系统调用
- 1.5 Chisels工具
- 1.5.1 网络类
- 1.5.2 硬盘类
- 1.5.3 cpu类
- 1.5.4 容器类
- 1.5.5 示例
- 二、监控容器运行时:Falco
- 2.1 安装
- 2.2 规则参数
- 2.3 默认规则
- 2.3.1 规则一
- 2.3.2 规则二
- 2.3.3 规则三
- 2.4 自定义规则
- 2.5 告警输出
- 2.5.1 输出为日志文件
- 2.5.2 web展示
- 三、K8s审计日志
- 3.1 事件阶段
- 3.2 日志输出方式
- 3.3 审核策略
- 3.3.1 日志级别
- 3.3.2 日志格式
- 3.3.3 启用审计日志
- 3.3.4 编写策略
- 3.4 案例1
- 3.5 案例2
一、分析容器系统调用:Sysdig
基本了解:
- 我们常常监控分析linux系统上的资源情况时会使用到一些工具,比如strace(诊断调试)、tcpdump(网络数据采集分析)、htop(系统性能监测)、iftop(网络流量、TCP/IP连接)、lsof (列出当前系统中进程打开的所有文件)。而Sysdig就是把这些功能汇聚在一起,成为一个非常强大的系统监控、分析和故障排查工具。
- 项目地址
- 说明文档
Sysdig功能作用:
- 获取系统资源利用率、进程、网络连接、系统调用等信息。
- 具备分析能力,对采集的数据进行分析排序,例如:
- 按照CPU使用率对进程排序。
- 按照数据包对进程排序。
- 打开最多的文件描述符进程。
- 查看进程打开了哪些文件。
- 查看进程的HTTP请求报文。
- 查看机器上容器列表及资源使用情况。
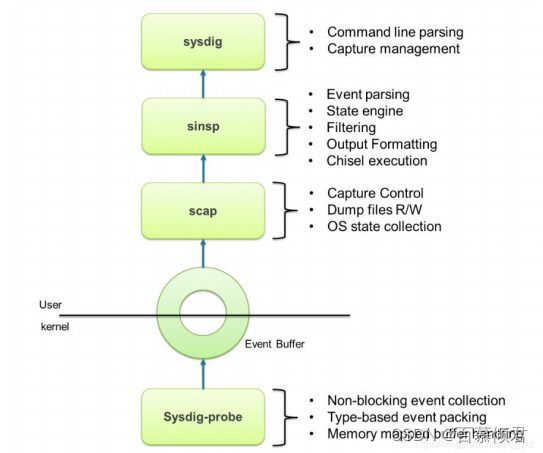
工作流程:
- 如下图,Sysdig在下方的linux内核态注册一个驱动模块,当上方的用户态对内核态进行系统调用时,Sysdig会把系统调用的信息拷贝到特定的buffer缓存区,随后用户态组件再对数据信息处理(解压、解析、过滤等),并最终通过 sysdig 命令行和用户进行交互。
1.1. 安装
1.导入官方yum源的key,下载官方draios源。
[root@k8s-node1 ~]# rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
[root@k8s-node1 ~]# curl -s -o /etc/yum.repos.d/draios.repo https://s3.amazonaws.com/download.draios.com/stable/rpm/draios.repo
2.配置epel源的目的是需要安装dkms依赖包,后安装sysdig。
[root@k8s-node1 ~]# yum install epel-release -y
[root@k8s-node1 ~]# yum install sysdig -y
3.加载到内核中,加载成功可以查看到scap驱动模块。
[root@k8s-node1 ~]# scap-driver-loader

1.2 常用参数
| 参数 | 释义 |
|---|---|
| -L, --list | 列出可用于过滤和输出的字段。 |
| -M < num_seconds > | 多少秒后停止收集。 |
| -p < output_format>, --print=< output_format>, 使用-pc或-pcontainer 容器友好的格式, 使用-pk或-pkubernetes k8s友好的格式 | 指定打印事件时使用的格式。 |
| -c < chiselname > < chiselargs > | 指定内置工具,可直接完成具体的数据聚合、分析工作。 |
| -w < filename > | 保存到文件中,特定格式,要用sysdig打开。 |
| -r < filename > | 从文件中读取。 |
1.3 采集分析
采集数据示例:
- 59509 23:59:19.023099531 0 kubelet (1738) < epoll_ctl
采集数据格式:
- %evt.num %evt.outputtime %evt.cpu %proc.name (%thread.tid) %evt.dir %evt.type %evt.info
字段说明:
- evt.num: 递增的事件号。
- evt.time: 事件发生的时间。
- evt.cpu: 事件被捕获时所在的 CPU,也就是系统调用是在哪个 CPU 执行的。
- proc.name: 生成事件的进程名字。
- thread.tid: 线程的 id,如果是单线程的程序,这也是进程的 pid。
- evt.dir: 事件的方向(direction),> 代表进入事件,< 代表退出事件。
- evt.type: 事件的名称,比如 open、stat等,一般是系统调用。
- evt.args: 事件的参数。如果是系统调用,这些对应着系统调用的参数
1.采集系统调用事件。
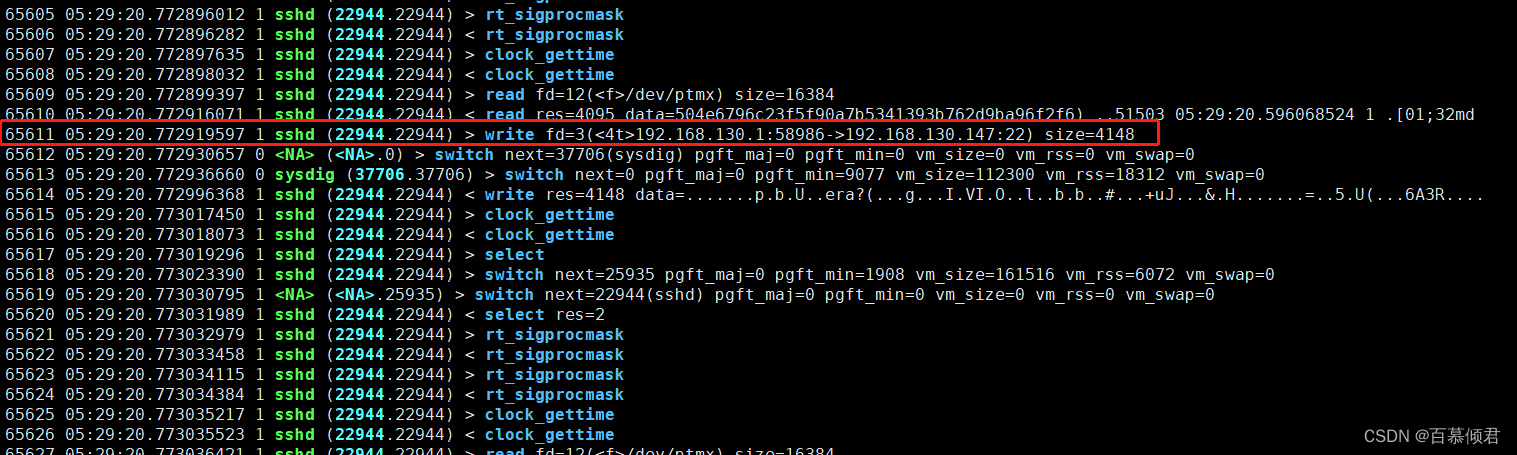
65611 05:29:20.772919597 1 sshd (22944.22944) > write fd=3(<4t>192.168.130.1:58986->192.168.130.147:22) size=4148
第一列(65611):事件编号,从1开始记录。
第二列(05:29:20.772919597):时间。
第三列(1):进程当前工作所在的cpu编号,从0开始。
第四列(sshd):进程名称。
第五列(22944.22944) :括号里是线程id,两个数值相同说明就一个线程。
第六列( > ): 进入事件,<代表退出事件。
第七列(write):事件名称。
第八列:事件信息,fd=3 是指打开的文件描述符是3,这里就是建立了一条TCP链接。
2.自定义过滤条件采集数据,对系统调用的事件编号和cpu进行采集1秒。
[root@k8s-node1 ~]# sysdig -M 1 -p "%evt.num,%evt.cpu"

1.4 示例
sysdig常用过滤目标:
- fd:根据文件描述符过滤,比如 fd 标号(fd.num)、fd 名字(fd.name)
- process:根据进程信息过滤,比如进程 id(proc.id)、进程名(proc.name)
- evt:根据事件信息过滤,比如事件编号、事件名
- user:根据用户信息过滤,比如用户 id、用户名、用户 home 目录
- syslog:根据系统日志过滤,比如日志的严重程度、日志的内容
- container:根据容器信息过滤,比如容器ID、容器名称、容器镜像
支持运算操作符:
- =、!=、>=、>、<、<=、contains、in 、exists、and、or、not
1.4.1 查看某进程系统调用事件
1.查看kubelet进程的系统调用。
[root@k8s-node1 ~]# sysdig proc.name=kubelet

2.查看calico进程的系统调用。
[root@k8s-node1 ~]# sysdig proc.name=calico
1.4.2 查看建立TCP连接事件
- tcp三次握手时,有个标识是accept。
[root@k8s-node1 ~]# sysdig evt.type=accept

1.4.3 查看某目录下打开的文件描述符
1.查看/etc/当前目录下打开的文件描述符。
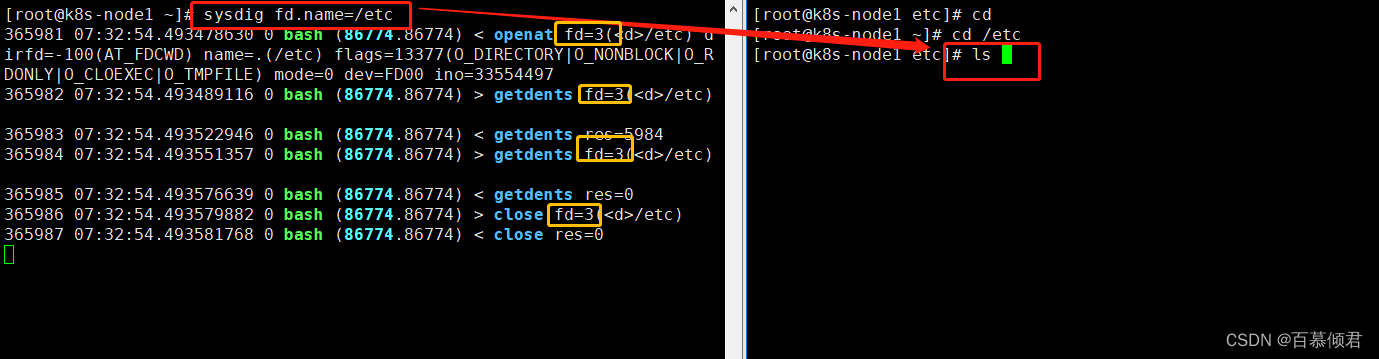
2.查看/etc/目录下所有目录打开的文件描述符。
[root@k8s-node1 ~]# sysdig fd.name contains /etc

1.4.4 查看容器的系统调用
测试一:查看web1容器的系统调用,进入容器时就会有bash进程。
[root@k8s-node1 ~]# sysdig container.name=web1

测试二:请求nginx,查看请求时的系统调用。

1.客户端请求nginx连接。
[root@k8s-node1 etc]# curl 172.17.0.2
2.查看该nginx容器的处理系统调用。
[root@k8s-node1 ~]# sysdig container.name=web1
调用流程:
- epoll多路复用。
- 与该nginx容器建立tcp三次握手,文件描述符为13。
- epoll处理请求文件,recvfrom请求会打开文件描述符13。
- stat获取html文件状态,openat打开html文件,并提取其中内容返回给客户端,客户端直接在网页上渲染出来。
- writev往tcp连接通道发送数据,并相应数据返回200。
- sendfile优化响应文件时的工作的性能,是nginx的特性。
- write fd=6写入日志。
- sersockopt 关闭fd=13,防止频繁打开提高工作效率。
- close 关闭fd=13 ,一套流程走完。


1.5 Chisels工具
- Chisels是个实用的工具箱,一组预定义的功能集合,用来分析特定的场景。
- sysdig –cl 列出所有Chisels,常用的如下:
- topprocs_cpu:输出按照 CPU 使用率排序的进程列表
- topprocs_net:输出进程使用网络TOP
- topprocs_file:进程读写磁盘文件TOP
- topfiles_bytes:读写磁盘文件TOP
- netstat:列出网络的连接情况
1.5.1 网络类
| 命令 | 释义 |
|---|---|
| sysdig -c topprocs_net | 查看使用网络的进程TOP |
| sysdig -c fdcount_by fd.sport “evt.type=accept” -M 10 | 查看建立连接的端口 |
| sysdig -c fdbytes_by fd.sport | 查看建立连接的端口 |
| sysdig -c fdcount_by fd.cip “evt.type=accept” -M 10 | 查看建立连接的IP |
| sysdig -c fdbytes_by fd.cip | 查看建立连接的IP |
1.5.2 硬盘类
| 明林 | 释义 |
|---|---|
| sysdig -c topprocs_file | 查看进程磁盘I/O读写 |
| sysdig -c fdcount_by proc.name “fd.type=file” -M 10 | 查看进程打开的文件描述符数量 |
| sysdig -c topfiles_bytes sysdig -c topfiles_bytes proc.name=etcd | 查看读写磁盘文件 |
| sysdig -c fdbytes_by fd.filename “fd.directory=/tmp/” | 查看/tmp目录读写磁盘活动文件 |
1.5.3 cpu类
| 命令 | 释义 |
|---|---|
| sysdig -c topprocs_cpu | 查看CPU使用率TOP |
| sysdig -pc -c topprocs_cpu container.name=web sysdig -pc -c topprocs_cpu container.id=web | 查看容器CPU使用率TOP |
1.5.4 容器类
| 命令 | 释义 |
|---|---|
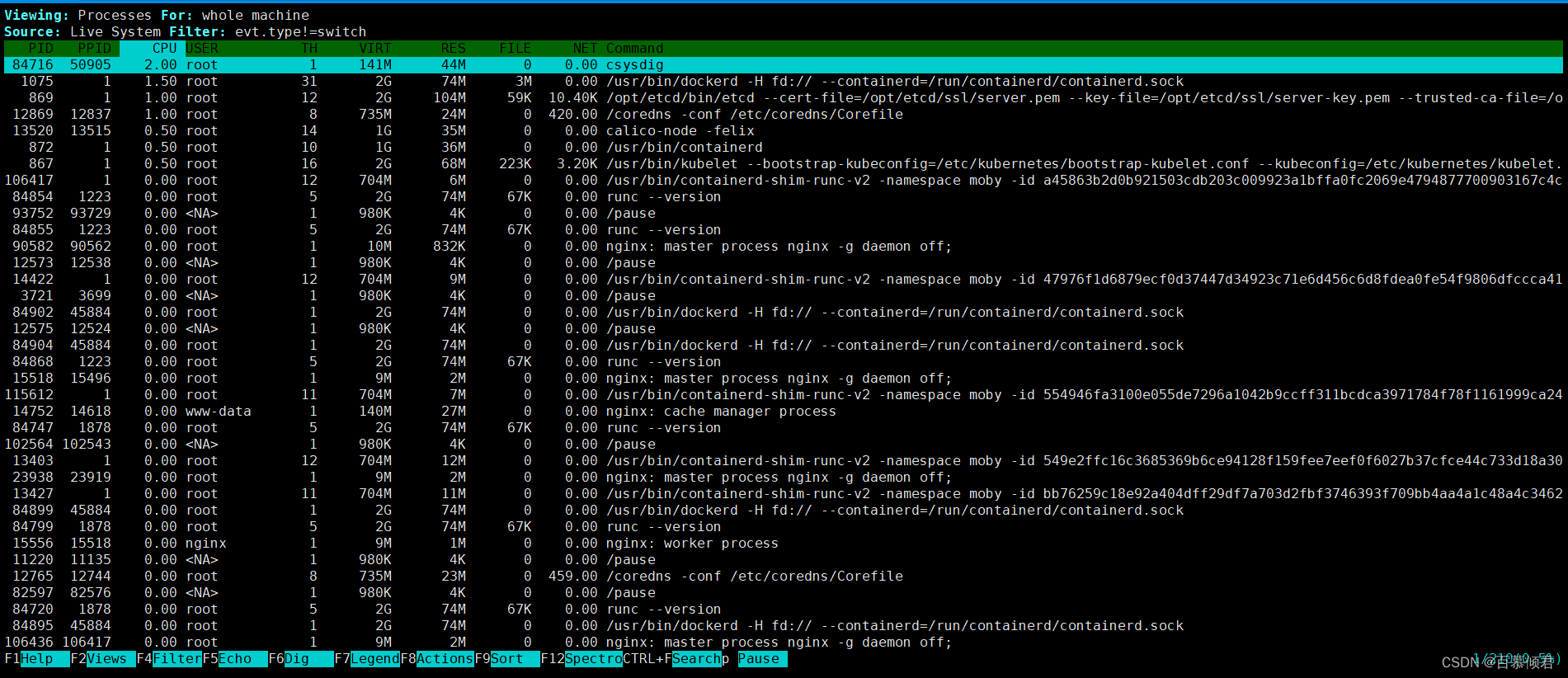
| csysdig –vcontainers | 查看机器上容器列表及资源使用情况 |
| sysdig -c topcontainers_cpu/topcontainers_net/topcontainers_file | 查看容器资源使用TOP |
1.5.5 示例
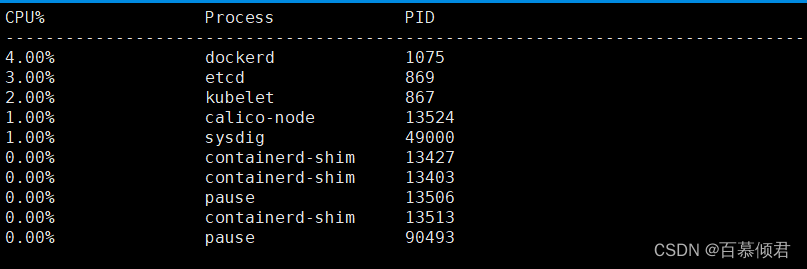
1.查看当前系统cpu使用占比最高的进程。
[root@k8s-node1 ~]# sysdig -c topprocs_cpu
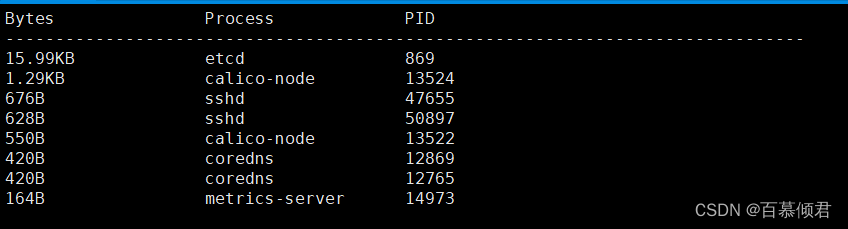
2.查看网络。
[root@k8s-node1 ~]# sysdig -c topprocs_net
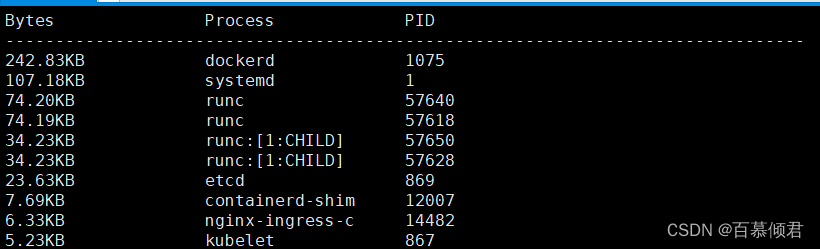
3.查看哪些进程在磁盘读写。
[root@k8s-node1 ~]# sysdig -c topprocs_file
4.查看哪些文件在磁盘读写。
[root@k8s-node1 ~]# sysdig -c topfiles_bytes

5.查看端口被链接的数量。

6.查兰容器里的进程的cpu使用情况。
[root@k8s-node1 ~]# sysdig -pc -c topprocs_cpu container.name=web1

7.查看本机所有容器的资源使用情况。
[root@k8s-node1 ~]# csysdig
二、监控容器运行时:Falco
基本了解:
- Falco 是一个 Linux 安全工具,它使用系统调用来保护和监控系统。
- Falco最初由Sysdig开发,后来加入CNCF孵化器,成为首个加入CNCF的运行时安全项目。
- Falco提供了一组默认规则,可以监控内核态的异常行为,例如:
- 对于系统目录/etc, /usr/bin, /usr/sbin的读写行为。
- 文件所有权、访问权限的变更。
- 从容器打开shell会话。
- 容器生成新进程。
- 特权容器启动。
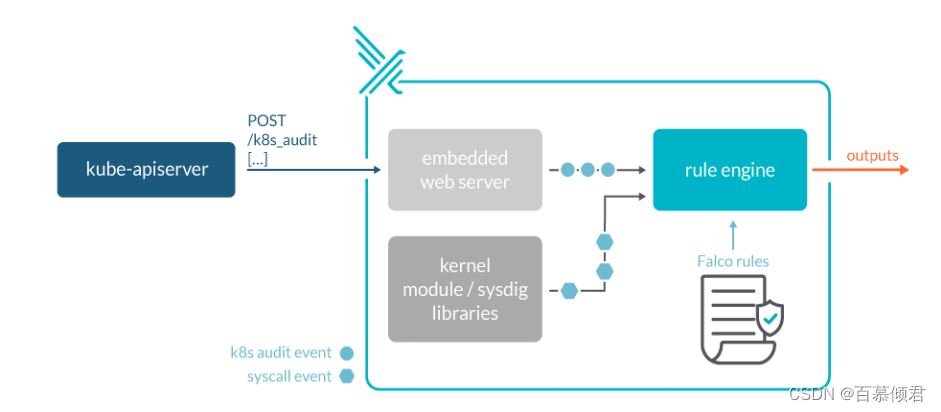
工作流程:
- 将falco注册成系统模块采集系统调用。
- 规则引擎根据判断收集的系统调用是否违反了规则,通知给用户处理。
- 支持k8s发送的审计日志。
2.1 安装
- 安装文档
1.安装官方源和epel源,有个依赖模块。
[root@k8s-node1 ~]# rpm --import https://falco.org/repo/falcosecurity-3672BA8F.asc
[root@k8s-node1 ~]# curl -s -o /etc/yum.repos.d/falcosecurity.repo https://falco.org/repo/falcosecurity-rpm.repo
[root@k8s-node1 ~]# yum install epel-release -y
[root@k8s-node1 ~]# yum update
[root@k8s-node1 ~]# yum install falco -y
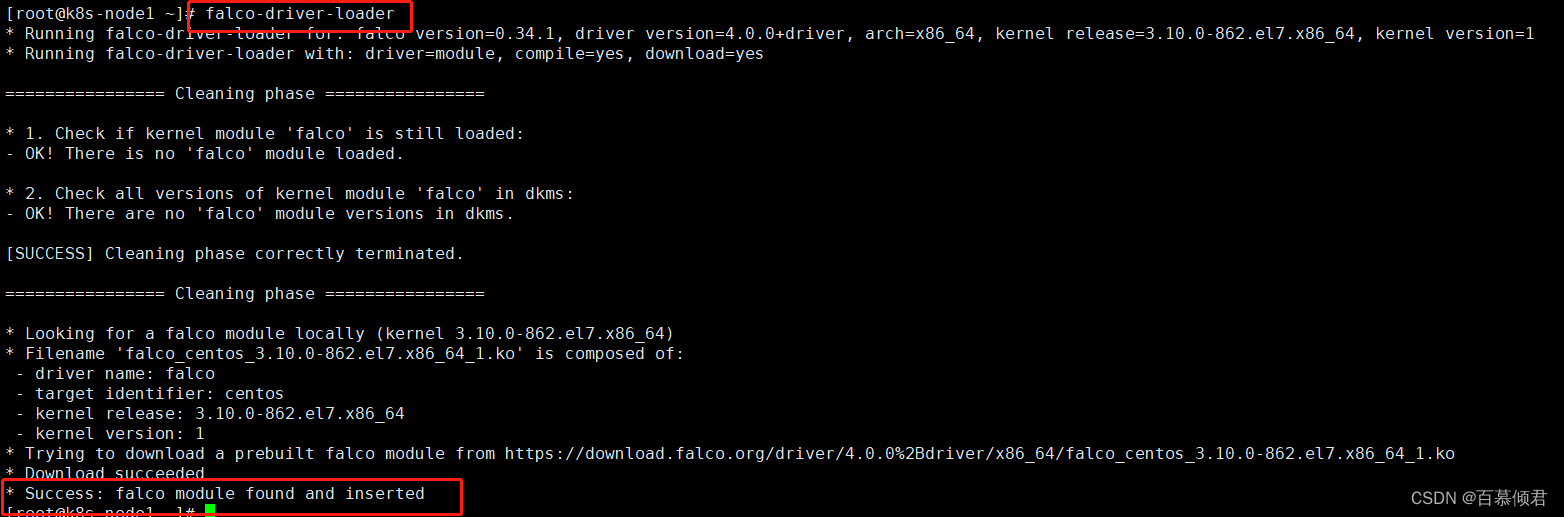
[root@k8s-node1 ~]# falco-driver-loader ##加载到系统内核。
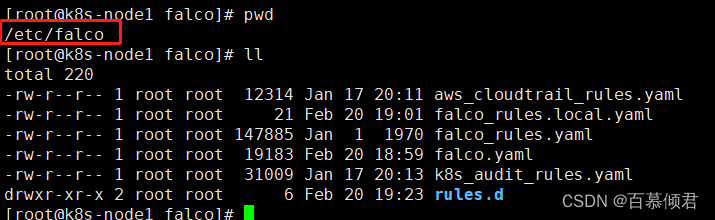
2.查看falco默认安装目录。
- falco.yaml:falco配置与输出告警通知方式。
- falco_rules.yaml:规则文件,默认已经定义很多威胁场景。
- falco_rules.local.yaml:自定义扩展规则文件。
- k8s_audit_rules.yaml:K8s审计日志规则
3.启动服务。
[root@k8s-node1 falco]# systemctl start falco-custom.service

2.2 规则参数
示例:
- rule: The program "sudo" is run in a container desc: An event will trigger every time you run sudo in a container condition: evt.type = execve and evt.dir=< and container.id != host and proc.name = sudo output: "Sudo run in container (user=%user.name %container.info parent=%proc.pnamecmdline=%proc.cmdline)" priority: ERROR tags: [users, container]参数说明:
- rule:规则名称,唯一。
- desc:规则的描述。
- condition: 条件表达式。
- output:符合条件事件的输出格式。
- priority:告警的优先级。
- tags:本条规则的 tags 分类
2.3 默认规则
威胁场景:
- 监控系统二进制文件目录读写(默认规则)。
- 监控根目录或者/root目录写入文件(默认规则)。
- 监控运行交互式Shell的容器(默认规则)。
- 监控容器创建的不可信任进程(自定义规则)
验证:
- tail -f /var/log/messages(告警通知默认输出到标准输出和系统日志)
2.3.1 规则一
1.查看默认的规则。
[root@k8s-node1 falco]# vim falco_rules.yaml

2.验证默认规则。在系统二进制文件目录下创建一个文件,查看输入的日志。
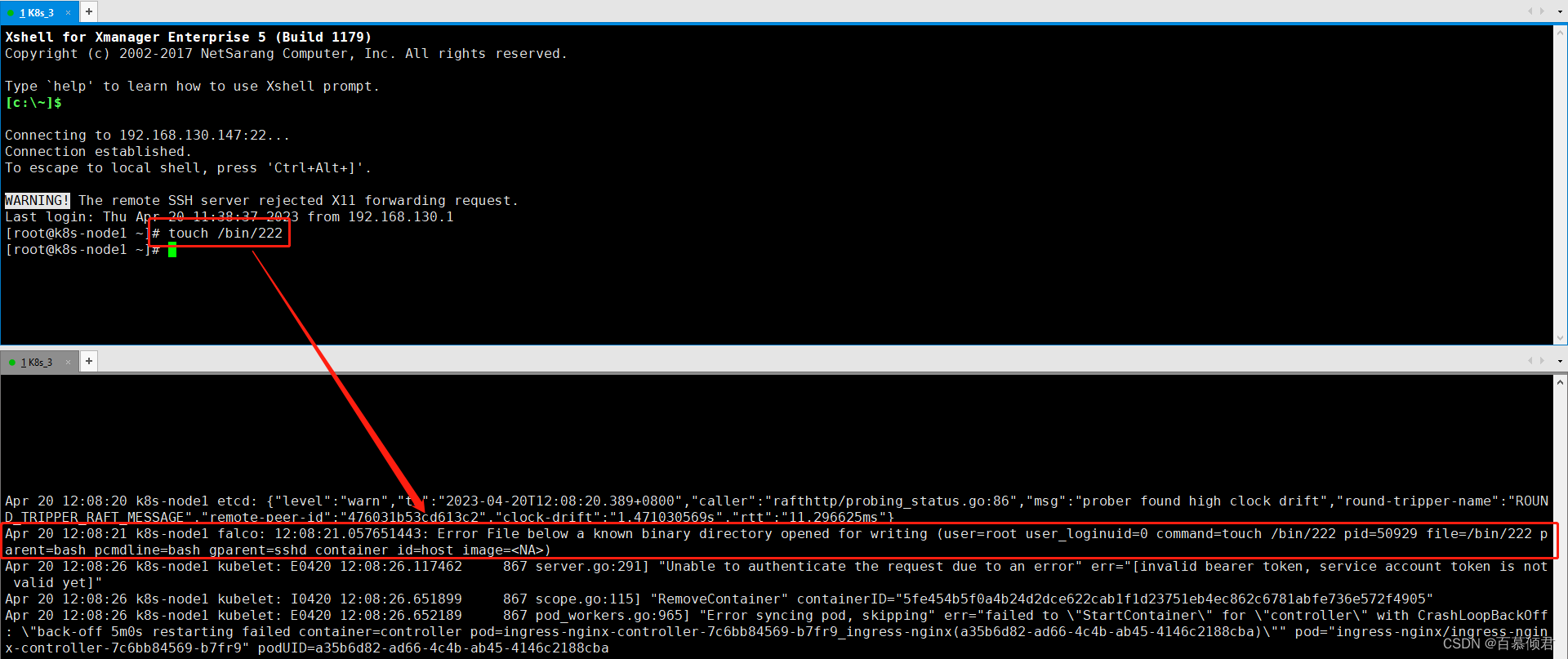
2.3.2 规则二
1.查看默认规则。

2.验证默认规则。在root目录或根目录下创建文件,则会触发威胁,查看系统日志。
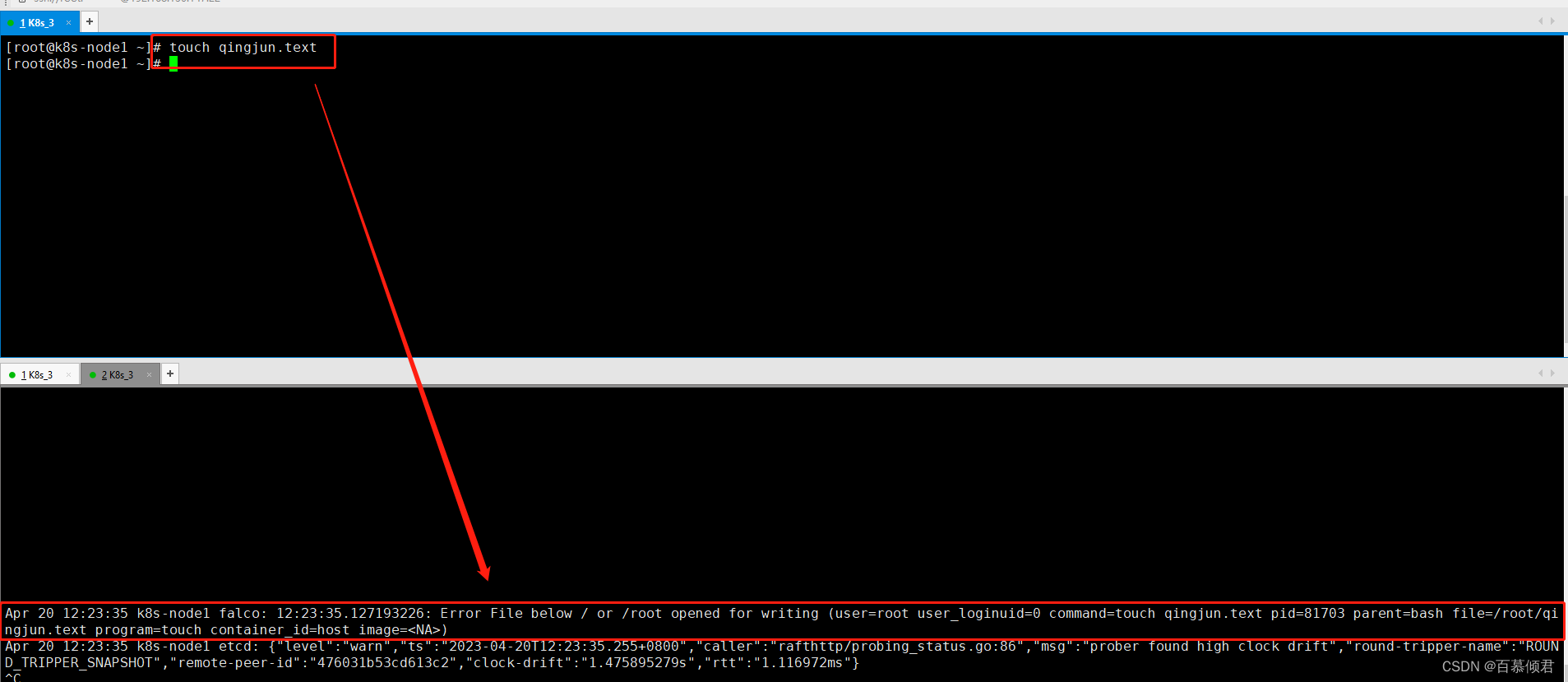
2.3.3 规则三
1.查看默认规则。
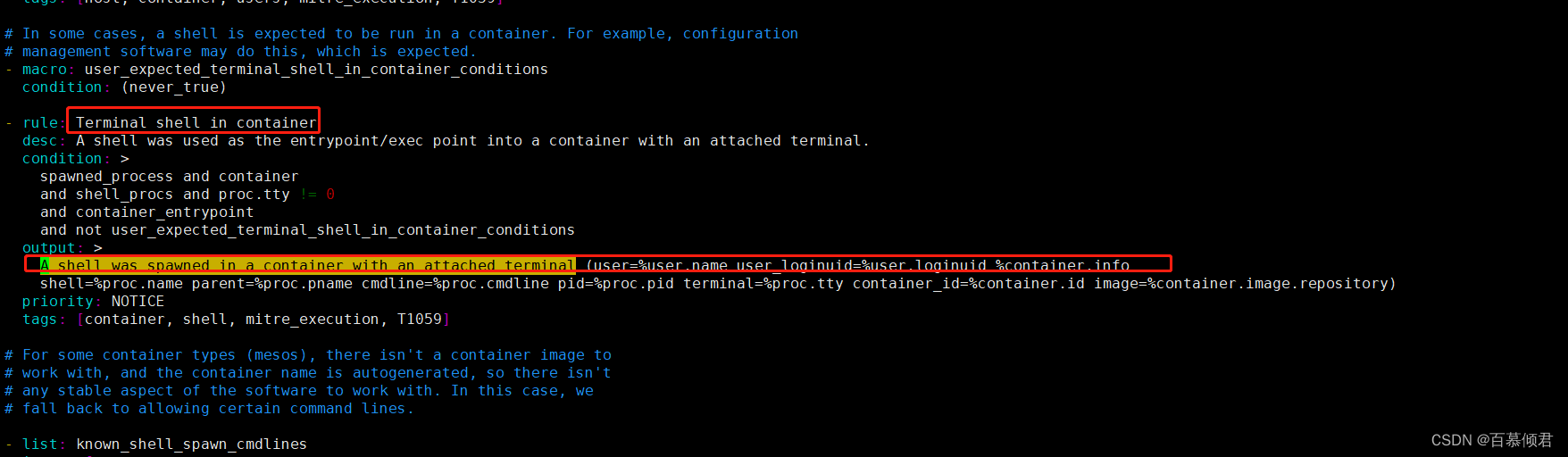
2.验证默认规则。进入容器触发规则,查看系统日志。
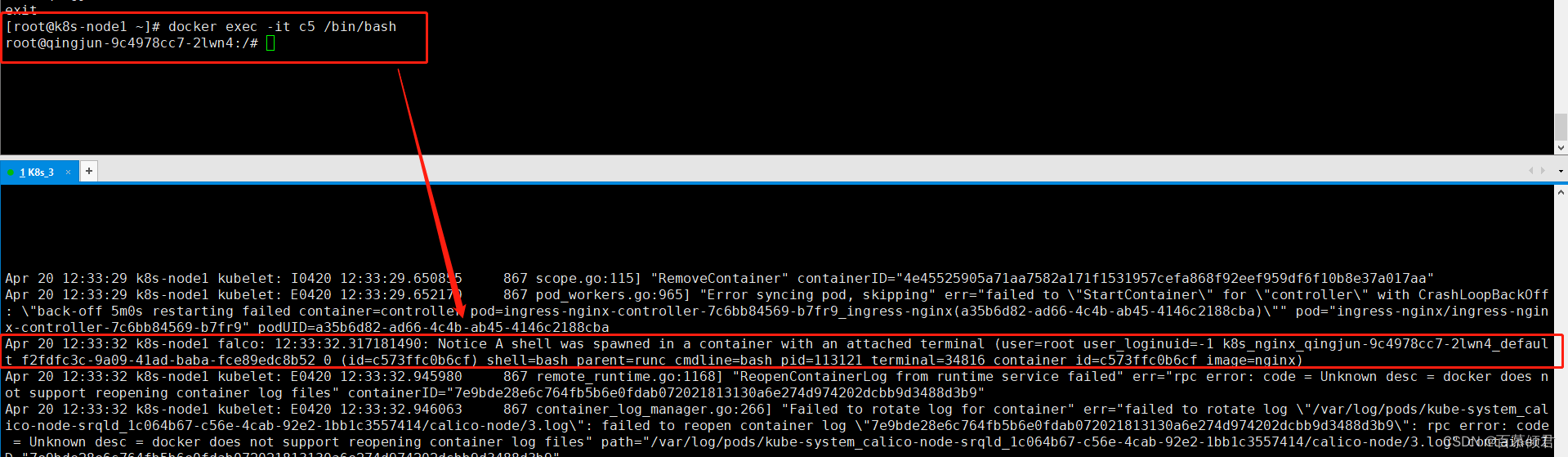
2.4 自定义规则
监控容器创建的不可信任进程规则:
- rule: Unauthorized process on nginx containers condition: spawned_process and container and container.image startswith nginx and not proc.name in (nginx) desc: test output: "Unauthorized process on nginx containers (user=%user.name container_name=%container.name container_id=%container.id image=%container.image.repository shell=%proc.name parent=%proc.pname cmdline=%proc.cmdline terminal=%proc.tty)" priority: WARNINGcondition表达式解读:
- spawned_process:运行新进程。
- container:指容器。
- container.image startswith nginx:以nginx开头的容器镜像。
- not proc.name in (nginx):不属于nginx的进程名称(允许进程名称列表)
1.定义规则,重启服务。
[root@k8s-node1 falco]# cat falco_rules.local.yaml
# Your custom rules!
- rule: test
condition: spawned_process and container and container.image startswith nginx and not proc.name in (nginx)
desc: test
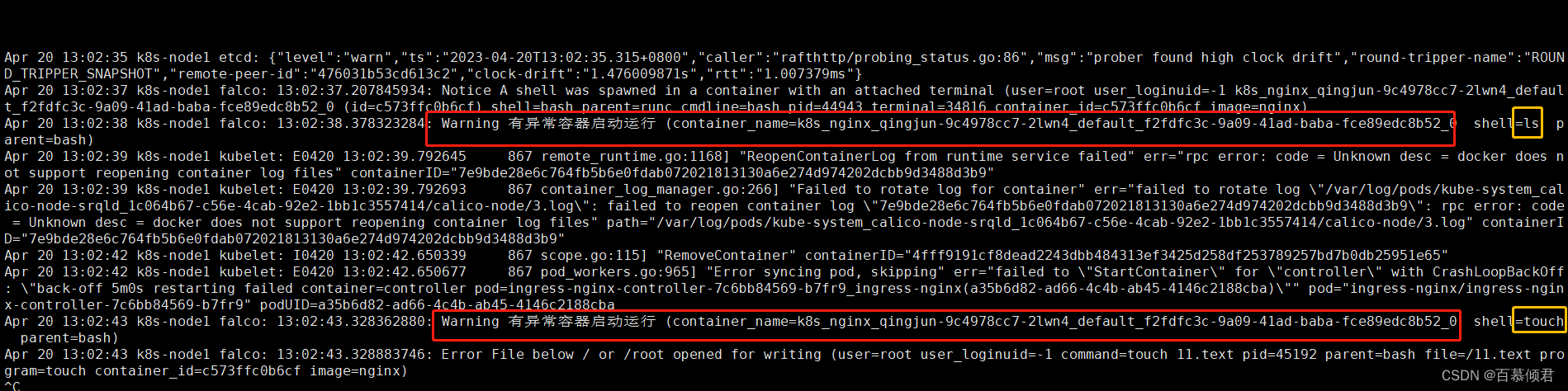
output: "有异常容器启动运行 (container_name=%container.name shell=%proc.name parent=%proc.pname)"
priority: WARNING
[root@k8s-node1 falco]# systemctl restart falco-custom
2.测试效果,进入容器随便操作几步。

3.打开系统文件,测试查看实时日志,可以收集到我刚刚的操作产生的系统调用。

2.5 告警输出
五种输出告警通知的方式:
- 输出到标准输出(默认启用),stdout_output。
- 输出到文件,file_output。
- 输出到系统日志(默认启用),sysout_output。
- 输出到HTTP服务。
- 输出到其他程序(命令行管道方式)
2.5.1 输出为日志文件
1.修改falso配置文件,关闭默认启用的两种输出方式,自定义以文件输出。
[root@k8s-node1 falco]# vim /etc/falco/falco.yaml
…
file_output:
enabled: true
keep_alive: false ##开启代表先把收集的日志放在缓存区,达到一定量再写入文件里。
filename: /var/log/falco_events.log

2.重启服务。
[root@k8s-node1 falco]# systemctl restart falco-custom
3.测试效果,进入容器触发规则,查看日志输出在我们自定义的文件里。

2.5.2 web展示
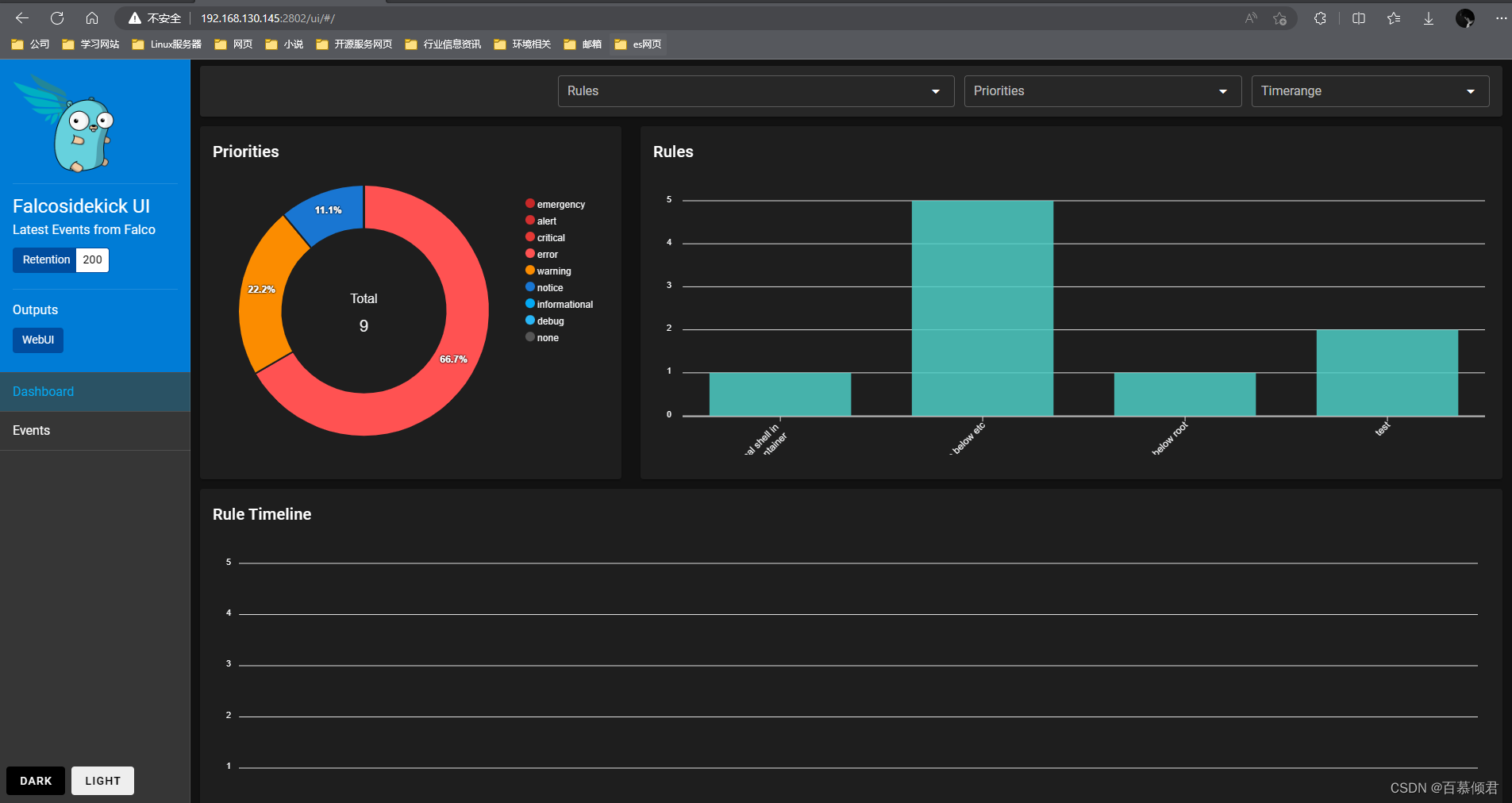
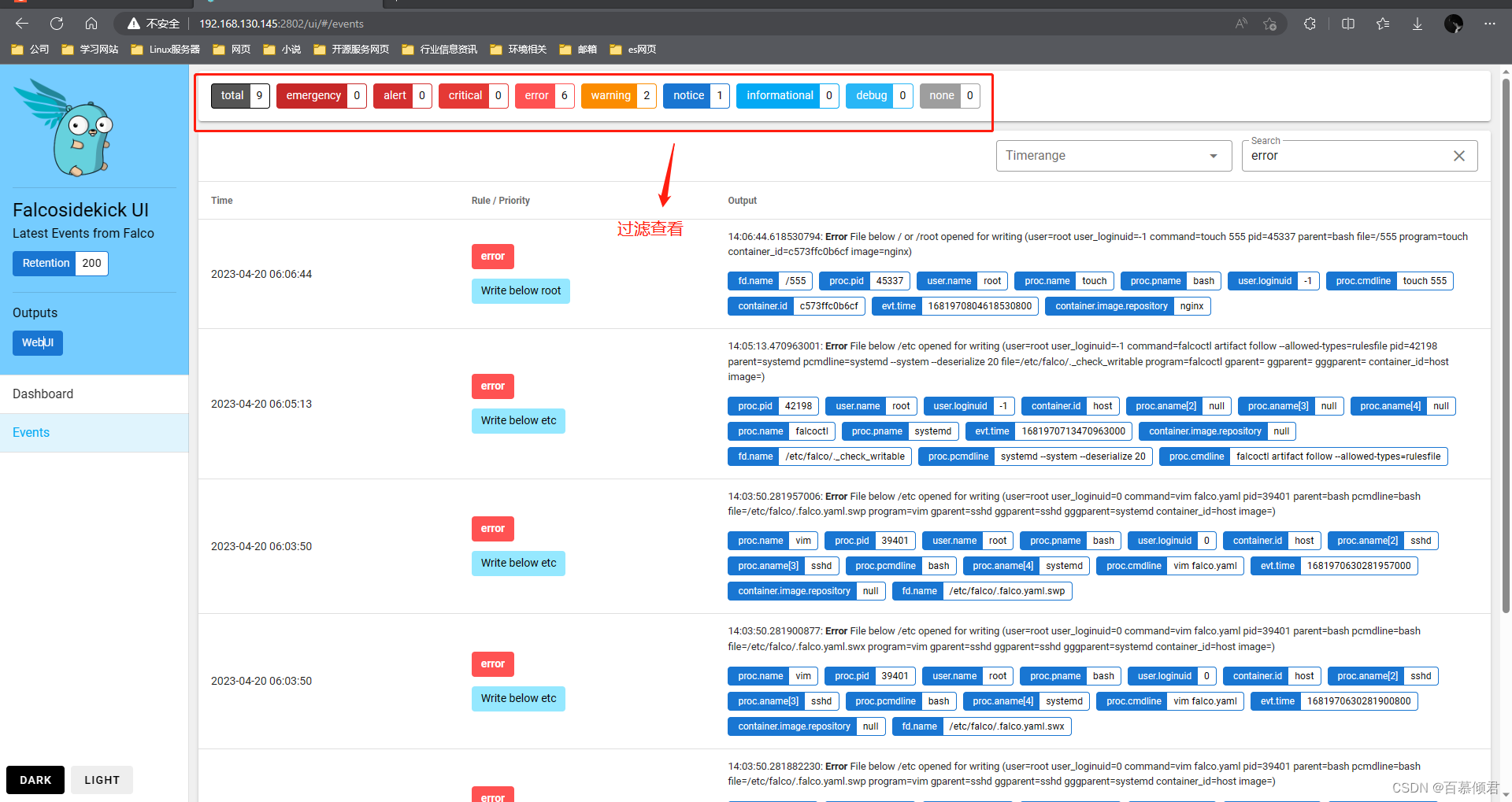
基本了解:
- FalcoSideKick:一个集中收集并指定输出,支持大量方式输出,例如Influxdb、Elasticsearch等。项目地址
- FalcoSideKick-UI:告警通知集中图形展示系统。项目地址
流程示意图:
- 每个服务器部署falco收集系统调用。
- 部署falcosidekick程序,收集每台服务器上的falco的系统调用信息。
- 通过falcosidekick-ui程序来集中展示在web页面。
- 告警通道:Slack/Altermanager/SMTP等

1.部署展示程序,UI访问地址:http://192.168.130.145:2802/ui/。
docker run -d \
-p 2802:2802 \
--name falcosidekick-ui \
falcosecurity/falcosidekick-ui

2.部署收集程序,指定展示程序地址。
docker run -d \
-p 2801:2801 \
--name falcosidekick \
-e WEBUI_URL=http://192.168.130.145:2802 \ ##UI程序地址。
falcosecurity/falcosidekick
3.修改falco配置文件指定http方式输出,更改为json输出格式,重启服务。
[root@k8s-node1 falco]# vim falco.yaml
......
json_output: true
......
http_output:
enabled: true
url: "http://192.168.130.145:2801/" ##收集程序地址。
user_agent: "falcosecurity/falco"
[root@k8s-node1 falco]# systemctl restart falco-custom
4.此时再次查看web页面,显示所有服务器上收集出发规则的系统调用。
三、K8s审计日志
K8s审计日志作用:
- 在K8s集群中,API Server的审计日志记录了哪些用户、哪些服务请求操作集群资源,并且可以编写不同规则控制忽略、存储的操作日志。
- 审计日志采用JSON格式输出,每条日志都包含丰富的元数据,例如请求的URL、HTTP方法、客户端来源等,可以使用监控服务来分析API流量,以检测趋势或可能存在的安全隐患。
可能会访问API Server的服务:
- 管理节点(controller-manager、scheduler)
- 工作节点(kubelet、kube-proxy)
- 集群服务(CoreDNS、Calico、HPA等)
- kubectl、API、Dashboard、calico等外部组件。
收集审计日志方案:
- 审计日志文件+filebeat。
- 审计webhook+logstash。
- 审计webhook+falco
- 将审计日志以本地日志文件方式保存,Fluentd工具采集日志并存储到es中,用Kibana对其进行展示和查询。
- 用Logstash采集Webhook后端的审计事件,通过Logstash将来自不同用户的事件保存为文件,或将数据发送到后端存储es。
注意事项:
- 每个节点上收集的审计日志内容不同,比如master1上开启了审计日志,master2没开启,当pod被分配到master2时就不会记录审计日志。
- 日志规则是从上往下挨个走,比如上面规则是对pod限制的,下面的一个规则也是对pod的,那最终就会按照上面的规则走,下面规则不会生效。
- 开启审计功能会增加API Server的内存消耗量,因为此时需要额外的内存来存储每个请求的审计上下文数据,而增加的内存量与审计功能的配置有关,比如更详细的审计日志所需的内存更多。
3.1 事件阶段
基本了解:
- 当客户端向 API Server发出请求时,该请求将经历一个或多个阶段。
- 每个请求在不同执行阶段都会生成审计事件;这些审计事件会根据特定策略 被预处理并写入后端。策略确定要记录的内容和用来存储记录的后端。比如客户端只想拿个请求头的内容,那么就直接在request received阶段编写规则就行,不需要再往后执行,可以提高性能。
请求阶段流程图:

| 阶段 | 说明 |
|---|---|
| RequestReceived | 审核处理程序已收到请求。 |
| ResponseStarted | 已发送响应标头,但尚未发送响应正文。 |
| ResponseComplete | 响应正文已完成,不再发送任何字节。 |
| Panic | 内部服务器出错,请求未完成。 |
3.2 日志输出方式
- 输出为本地文件存储。需要在apiserver配置文件添加以下参数。
- –audit-policy-file:日志审核策略文件路径。
- –audit-log-path:审计日志文件输出路径。不指定此标志会禁用日志后端,意味着标准化。
- –audit-log-maxage:定义保留旧审计日志文件的最大天数。
- –audit-log-maxbackup:定义要保留的审计日志文件的最大数量。
- –audit-log-maxsize:定义审计日志文件轮转之前的最大大小(兆字节)。
- 发送给Webhook Server。需要在kube-apiserver配置文件添加以下参数,并且需要在Webhook 配置文件使用 kubeconfig 格式指定服务的远程地址和用于连接它的凭据。
- –audit-webhook-config-file:设置 Webhook 配置文件的路径。Webhook 配置文件实际上是一个 kubeconfig 文件。
- –audit-webhook-initial-backoff:指定在第一次失败后重发请求等待的时间。随后的请求将以指数退避重试。
- –audit-webhook-mode:确定采用哪种模式回调通知。
- batch:批量模式,缓存事件并以异步批量方式通知,是默认的工作模式。
- blocking:阻塞模式,事件按顺序逐个处理,这种模式会阻塞API Server的响应,可能导致性能问题。
- blocking-strict:与阻塞模式类似,不同的是当一个Request在RequestReceived阶段发生审计失败时,整个Request请求会被认为失败。
3.3 审核策略
基本了解:
- K8s审核策略文件包含一系列规则,描述了记录日志的级别,采集哪些日志,不采集哪些日志。
- 审核策略合适和rbac授权格式相同,也是写什么组里的什么资源要做什么动作。
注意事项:
- 审计日志有级别之分,可以根据个人需求采集不同的信息,避免消耗资源。
- 审计日志是支持写入本地文件和Webhook(发送到外部HTTP API)两种方式,可以和logstach配合玩。
- 启用审计日志时,需要指定几个参数,比如策略文件地址、日志输出地址、输出日志大小等等,同时还需要把策略文件和日志挂载到宿主机,因为是以容器方式运行,所以需要做持久化输出。
3.3.1 日志级别
- 请求正文指post请求,比如apply、create动作请求。
- 相应正文,比如get动作请求。
| 级别 | 说明 |
|---|---|
| None | 不为事件创建日志条目。 |
| Metadata | 创建日志条目。包括元数据,但不包括请求正文或响应正文。 |
| Request | 创建日志条目。包括元数据和请求正文,但不包括响应正文。 |
| RequestResponse | 创建日志条目。包括元数据、请求正文和响应正文。 |
3.3.2 日志格式
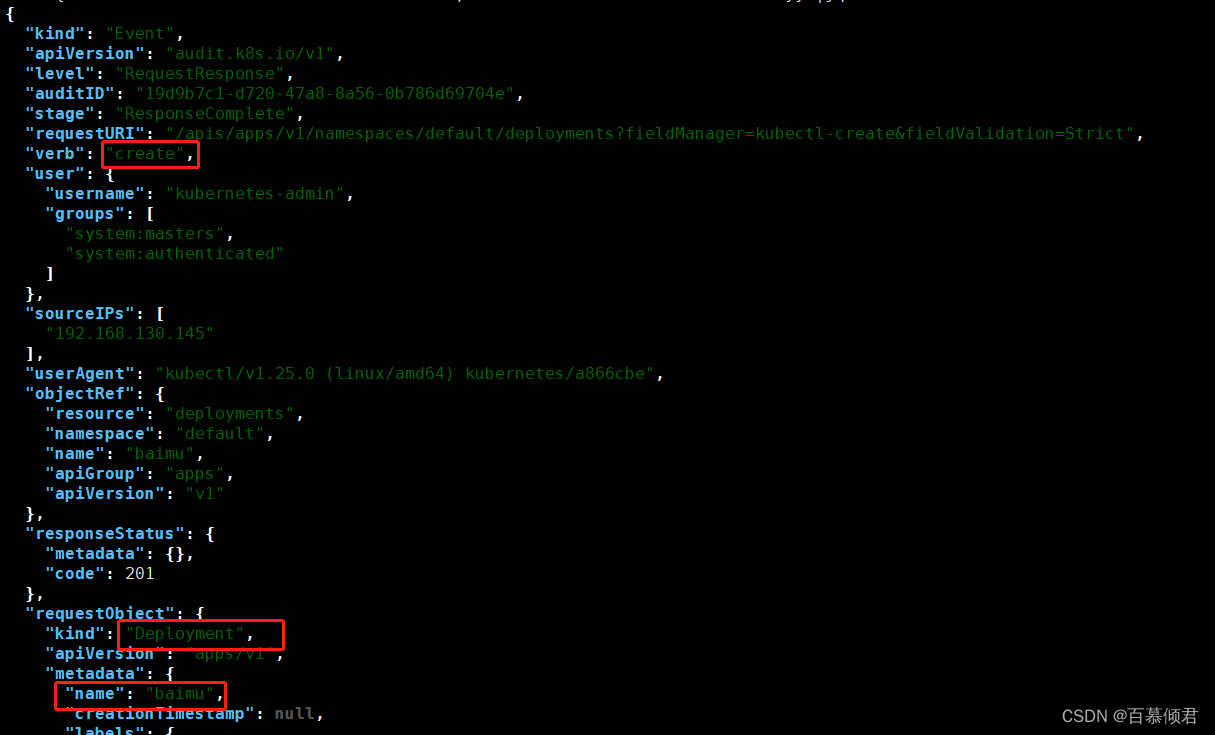
- 审计日志属性:表明请求哪个API、事件id、请求方法。
- 用户信息:用哪个身份进来的。
- 客户端IP:从哪台机器过来请求的。
- 用户标识对象:想访问哪个资源、资源名称、所在命名空间、所在组。
- 响应状态:返回状态。
- 时间注释:响应时间。

3.3.3 启用审计日志
| 指定参数 | 释义 |
|---|---|
| audit-policy-file | 审计日志策略文件 |
| audit-log-path | 审计日志输出文件 |
| audit-log-maxage | 审计日志保留的最大天数 |
| audit-log-maxbackup | 审计日志最大分片存储多少个日志文件 |
| audit-log-maxsize | 单个审计日志最大大小,单位MB |
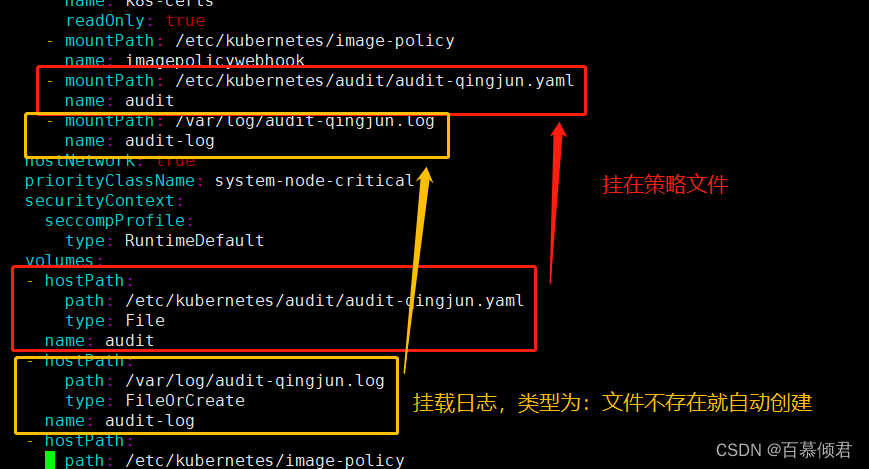
1.在apiserver配置文件里添加启用审计日志参数,并且挂载策略文件和输出的日志文件。
vi /etc/kubernetes/manifests/kube-apiserver.yaml
......
- --audit-policy-file=/etc/kubernetes/audit/audit-policy.yaml
- --audit-log-path=/var/log/k8s_audit.log
- --audit-log-maxage=30
- --audit-log-maxbackup=10
- --audit-log-maxsize=100
...
volumeMounts:
...
- mountPath: /etc/kubernetes/audit/audit-policy.yaml
name: audit
- mountPath: /var/log/k8s_audit.log
name: audit-log
volumes:
- name: audit
hostPath:
path: /etc/kubernetes/audit/audit-policy.yaml
type: File
- name: audit-log
hostPath:
path: /var/log/k8s_audit.log
type: FileOrCreate
3.3.4 编写策略
- 官方文档

3.4 案例1
1.创建日志策略存放目录/etc/kubernetes/audit,编写审计日志策略。
[root@k8s-master1 ~]# mkdir /etc/kubernetes/audit
[root@k8s-master1 ~]# cd /etc/kubernetes/audit/
[root@k8s-master1 audit]# cat audit-qingjun.yaml
apiVersion: audit.k8s.io/v1 ##必填项。
kind: Policy
# 不要在 RequestReceived 阶段为任何请求生成审计事件。
omitStages:
- "RequestReceived"
rules:
# 在日志中用 RequestResponse 级别记录 Pod 变化。
- level: RequestResponse
resources:
- group: ""
# 资源 "pods" 不匹配对任何 Pod 子资源的请求,
# 这与 RBAC 策略一致。
resources: ["pods"]
# 在日志中按 Metadata 级别记录 "pods/log"、"pods/status" 请求
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# 不要在日志中记录对名为 "controller-leader" 的 configmap 的请求。
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# 不要在日志中记录由 "system:kube-proxy" 发出的对端点或服务的监测请求。
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API 组
resources: ["endpoints", "services"]
# 不要在日志中记录对某些非资源 URL 路径的已认证请求。
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # 通配符匹配。
- "/version"
# 在日志中记录 kube-system 中 configmap 变更的请求消息体。
- level: Request
resources:
- group: "" # core API 组
resources: ["configmaps"]
# 这个规则仅适用于 "kube-system" 名字空间中的资源。
# 空字符串 "" 可用于选择非名字空间作用域的资源。
namespaces: ["kube-system"]
# 在日志中用 Metadata 级别记录所有其他名字空间中的 configmap 和 secret 变更。
- level: Metadata
resources:
- group: "" # core API 组
resources: ["secrets", "configmaps"]
# 在日志中以 Request 级别记录所有其他 core 和 extensions 组中的资源操作。
- level: Request
resources:
- group: "" # core API 组
- group: "extensions" # 不应包括在内的组版本。
# 一个抓取所有的规则,将在日志中以 Metadata 级别记录所有其他请求。
- level: Metadata
# 符合此规则的 watch 等长时间运行的请求将不会
# 在 RequestReceived 阶段生成审计事件。
omitStages:
- "RequestReceived"
2.编辑apiserver配置文件,指定日志策略文件、日志输出路径和日志轮转策略,并挂载策略文件和日志文件。
##添加以下几行。
[root@k8s-master1 ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --audit-policy-file=/etc/kubernetes/audit/audit-qingjun.yaml
- --audit-log-path=/var/log/audit-qingjun.log
- --audit-log-maxage=30
- --audit-log-maxbackup=10
- --audit-log-maxsize=100
3.此时查看/var/log/qudit-qingjun.log日志文件,epel源安装jq,解析成json格式。
[root@k8s-master1 ~]# yum -y install jq

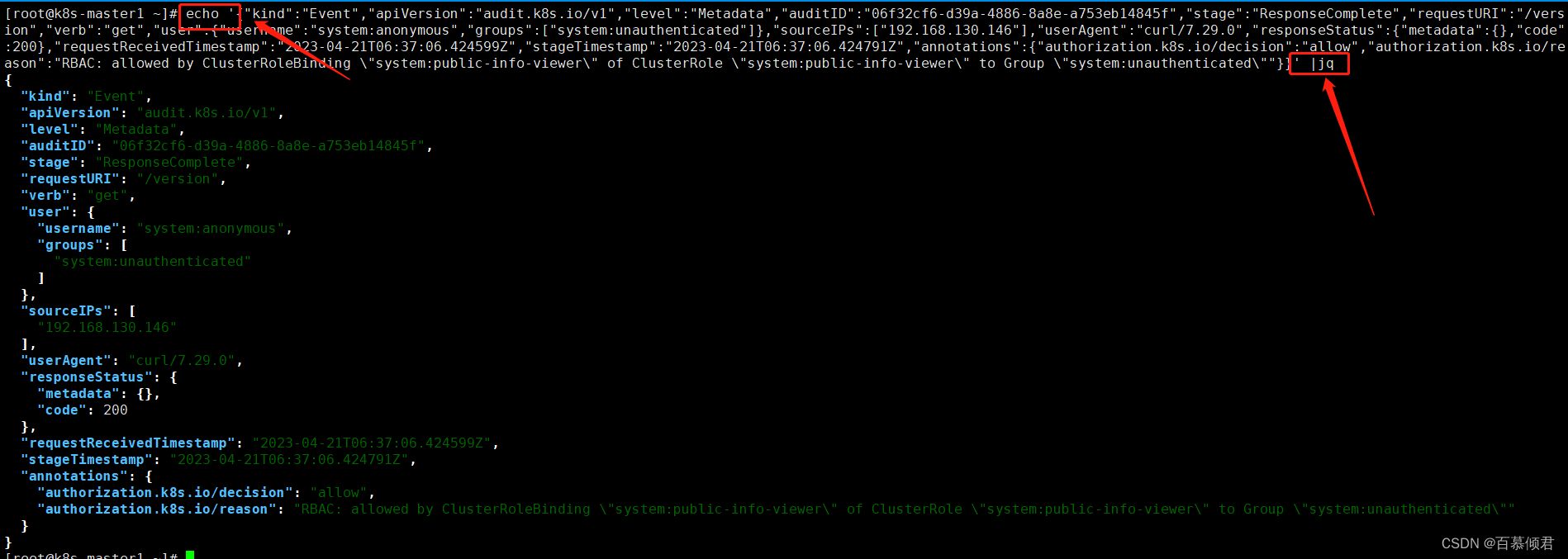
3.5 案例2
1.当审计日志规则文件内容变更后,需要重启apiserver服务才能使修改后的规则生效,可以重启apiserver容器或杀掉它的进程。
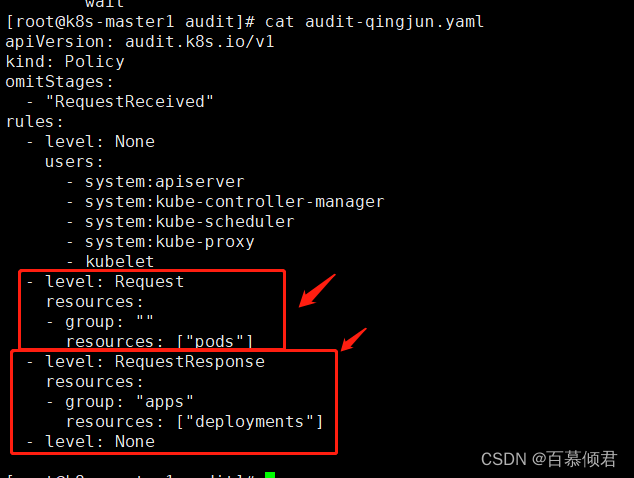
[root@k8s-master1 audit]# cat audit-qingjun.yaml
apiVersion: audit.k8s.io/v1
kind: Policy
omitStages:
- "RequestReceived"
rules:
- level: None ##不记录以下组件日志,每个组件都会用自己的用户去访问,根据用户来限制。
users:
- system:apiserver
- system:kube-controller-manager
- system:kube-scheduler
- system:kube-proxy
- kubelet
- level: Metadata ##记录pod资源的元数据级别日志。
resources:
- group: ""
resources: ["pods"]
- level: None ##不记录上面那些组件日志,只记录pod资源元数据级别日志之外的所有资源产生的日志都不记录。
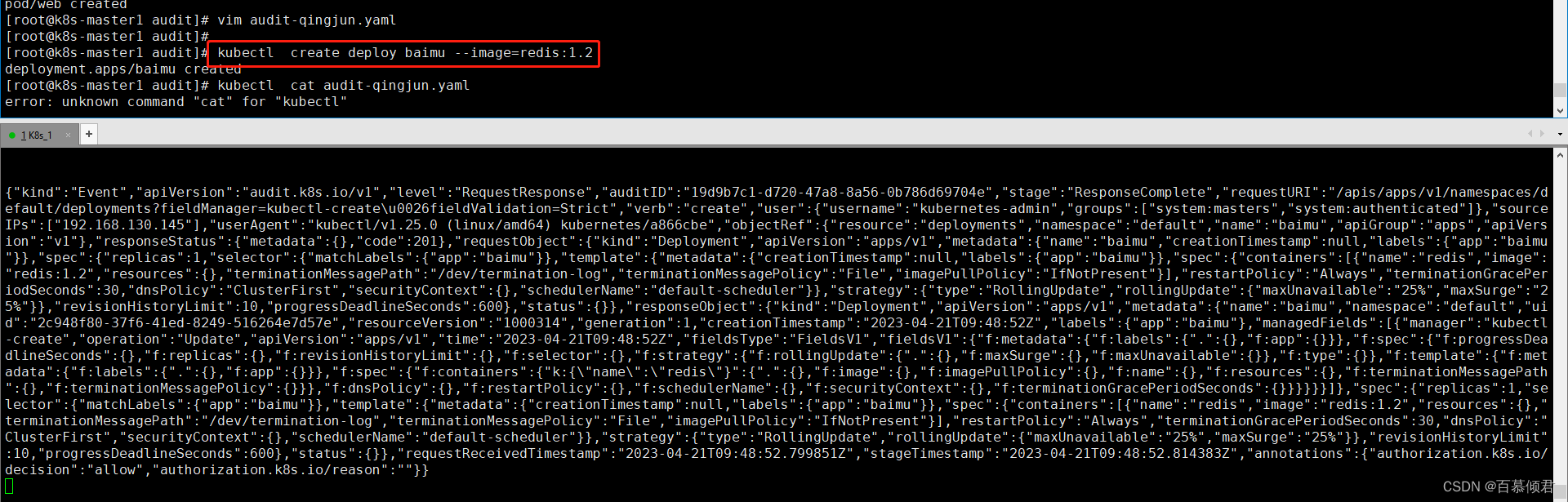
2.重启apiserver容器。

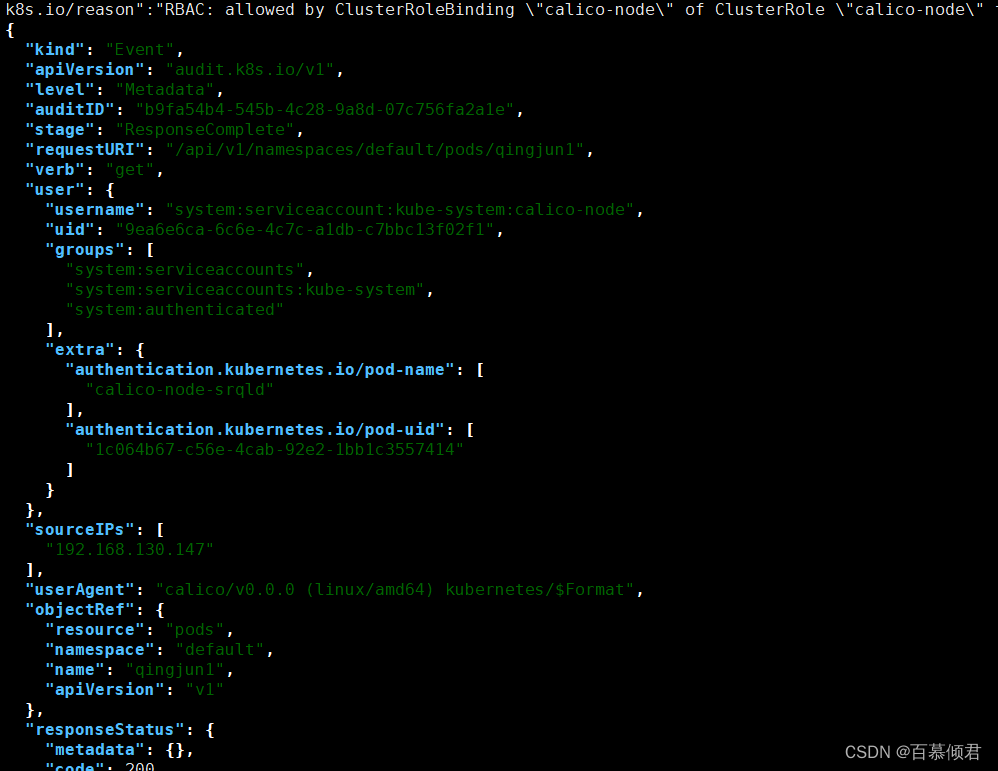
3.生成一个pod再次测试,查看审计日志。

4.再解析成json格式查看。
echo ' ' |jq
5.添加多个策略,这里多添加了记录deployment资源的元数据、请求正文、响应正文的日志,重启apiserver容器再测试。
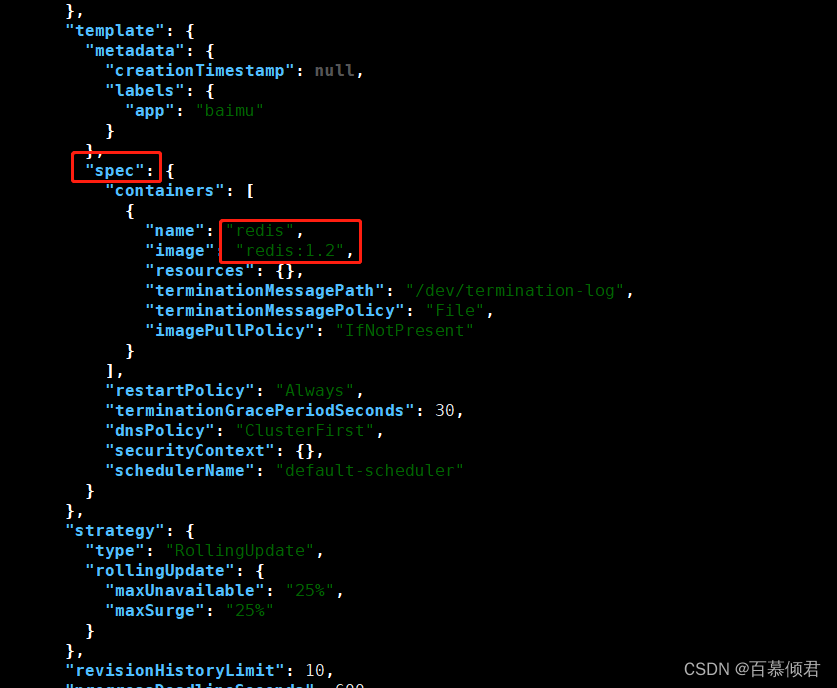
6.创建deploy资源再次测试,查看结果,可以看到资源类型、名称、对资源操作动作、还有容器相关信息。