目录
一、理解源IP地址和目的IP地址
二、端口号
1. 为什么要有端口号
2. 理解端口号
3. 源端口号和目的端口号
三、初步了解TCP协议和UDP协议
1. 初步认识TCP协议
2. 初步认识UDP协议
3. 可靠传输与不可靠传输
四、网络字节序
1. 网络字节序的概念
2. 如何形成网络字节序
2.1 大小端转化
一、理解源IP地址和目的IP地址
源IP和目的IP在上一章网络基础中就已经有所讲解,这里就简单的介绍一下。在IP数据包头部中,包括两个IP地址,分别是源IP地址和目的IP地址。源IP地址就是发送数据的主机的IP地址,目的IP地址就是最终要接收这份数据的主机的IP地址。
在网络中发送数据时,必须要有源IP和目的IP这两个IP地址,用于标识这份数据从哪儿来,要到哪儿去。这就好比你去旅游时,必须要有一个出发地和目的地,否则这趟旅游就无法开始。
二、端口号
1. 为什么要有端口号
要了解端口号,首先要建立如下一个概念:
网络中两台主机通信时,真正需要通信的并不是主机,而是这两台主机中的应用层的程序需要通信,需要通过传输的这份数据来实现某种业务。所以将数据从A主机传输到B主机并不是目的,而是手段。让这两台主机上的程序获取这份数据执行某项业务才是目的。
我们知道,在一台主机上可能存在数十上百个进程,而这份数据如何从这大量的进程中分辨出它应该传给谁呢?解决方案很简单,既然数据在传输过程中有唯一的IP来标识这份传入的数据的来源和目的地,就也可以通过一个唯一的数据来标识某个进程。
因此,在网络中为了更好的表示一台主机上的进程的唯一性,就采用了端口号port来标识服务器进程和客户端进程的唯一性。
2. 理解端口号
端口号和ip地址不同,ip地址是网络层协议的内容,而端口号(port)是传输层协议的内容。
端口号是一个2字节,即16位的整数。端口号用于标识一个进程,告诉OS,当前的这个数据要交给哪一个进程来处理。
在网络中,ip地址+端口号就能够唯一标识网络上的某一台主机的某一个进程。
一个端口号只能被一个进程占用,即一个端口号对应一个进程。
通过上面的ip地址标识主机和端口号标识进程的内容,我们就应该意识到,网络通信的本质,其实就是“进程间通信”。
要进行进程间通信,就必须要有一份能够让这两个进程同时看到的共享资源,这份共享资源就是网络资源。
同时上面也说了,端口号是一个2字节的整数,如果所有主机中的进程都共用同一套端口号,就势必会出现端口号不足的情况。因此,不同主机其实都拥有一套单独的端口号,即不同主机上的端口号是可以相同的。因为ip地址就已经保证了该主机全网唯一(并不准确),那么端口号是不是全网唯一就已经不重要了,只需要保证有端口号和同一台主机下的端口号不重复即可。
上文中说网络通信的本质就是进程间通信,而端口号和ip地址分别属于传输层协议和网络层协议,而传输层和网络层又是属于OS的。同时我们也知道,在OS中,一个进程的唯一性可以用进程pid来标识。既然如此,那为什么这里要单独用端口号来标识进程唯一性,而不采用进程pid来标识呢?原因主要有以下三个:
(1)系统就是系统,网络就是网络。如果采用进程pid充当端口号,就会导致系统与网络的强耦合。为了避免这一情况,就需要将系统与网络解耦,即网络单独用端口号来标识进程唯一性。
(2)数据在网络中传输时,要求数据能够快速准确的找到对应的服务器进程。这就要求ip地址+端口号是不能随意改变的。而进程pid在进程重启后都会重新随机生成,增加了数据找到对应服务器进程的成本。
(3)不是所有的进程都需要提供网络服务和请求,但是所有进程都需要进程pid。例如我们的电脑中的某些单机游戏,从下载下来后就不会再进行联网操作,此时该进程就不需要提供网络服务,也就不需要端口号。
此时大家可能还会有一个问题。端口号是网络中用来标识进程唯一性的,而进程是由OS来管理的。那底层OS是如何根据这个端口号来找到对应进程的呢?我们知道,在OS中,每个进程都有一个进程pcb,是一个结构体。而端口号是一个2字节的整数,所以这个问题现在就转化为了如何通过一个16位的整数找到一个结构体。解决方案其实就是hash。建立一个kv模型的hash表,key值就是端口号,value则是对应进程的pcb。通过hash映射的方式,就可以通过端口号找到进程了。
总结起来,要理解端口号,就要理解如下四个概念:
(1)网络通信的本质就是进程间通信。通过网络资源这一共享资源进行通信
(2)所有主机上都有一套独立的端口号,这就表示不同主机的端口号是可以相同的
(3)端口号和进程pid都是用来标识进程唯一性的,但端口号是用于网络中的,而进程pid则是用于OS中的
(4)OS通过hash映射的方式用端口号找到对应的进程
注意,上文中一直在说一个端口号标识唯一一个进程,但是并没有说一个进程只能对应一个端口号。在实际中,一个进程是可以绑定多个端口号的。大家应该听过“开后门”的事情。就是在网上有些人可能说某个程序员给别人写了一个程序,但这个程序员留了一个后门,在这个买程序的人拿了程序没给钱的时候,这个程序员就通过这个后门将他交付的程序中的数据全部删除了。这里的这个“后门”,其实就是指的端口号。即他交付的这个程序绑定了多个端口号,一些端口号是给买程序的人用的,而另一些端口号他则没有告诉用户,只要这些预留的端口号没被用户发现并清除,那么这个程序员就随时都可以通过这些端口号进入程序内部修改数据。
3. 源端口号和目的端口号
和ip地址存在源IP和目的IP两个IP地址一样,传输层协议的数据段中的端口号也存在“源端口号”和“目的端口号”两个端口号,分别用于标识从哪里来和到哪里去。
注意,在传输数据的过程中,不仅要将对方需要的数据传过去,还需要将自己的ip地址和端口号传过去。因为数据传输是相互的,对方也可能需要反馈数据。
此时有人可能就会疑惑了,既然接收方需要接收发送方的ip和port以便于返回数据,那发送方在最开始的时候是如何知道接收方的ip和port的呢?这其实因为我们所用的程序并不是由我们写的,而是由给我们提供程序的公司写的。这些程序发送数据时需要发送给给特定的服务器,而这些服务器的ip和端口号早已经在程序内被提前写好了,不需要用户操心。
三、初步了解TCP协议和UDP协议
大家知道,在网络中通过协议分层分为了5层,其中传输层和网络层属于OS,数据链路层是驱动相关的内容,物理层是硬件相关的内容。这四层都已经有对应的协议规定好了,不需要我们来操作。所以在网络编程中,我们所要做的基本都是在应用层进行操作。而数据传输是自顶而下的,这也就导致如果我们想在应用层操作,就势必需要使用系统调用接口与传输层建立关系。
在传输层中主流的协议是TCP协议,还有一个使用比较少的协议,即UDP协议。在这里因为大家知识储量不够的原因,还不能详细讲解这两个协议,但可以建立一个对TCP协议和UDP协议的初步认识。
1. 初步认识TCP协议
TCP协议,全称为Transmission Control Protocol,即传输控制协议。主要包括以下四个特性:
(1)是传输层协议
(2)有连接
(3)可靠传输
(4)面向字节流
第一点,是传输层协议这个不比多说,TCP协议就是一个应用于传输层的协议。
第二点,有连接。这里的有连接指的是在正式通信之间,通信双方要先建立连接。这就好比我们打电话,只有当对方接听了电话,你们之间建立了一个沟通渠道后,才可以开始通话。如果对方没有接电话,就是建立连接失败。
第三点,可靠传输。数据在网络传输中是可能出现各种问题的,例如数据丢失、数据由于某些原因多发了一份、由于网络抖动导致数据发送失败等问题,这些问题就被称为“不可靠”。而这里的可靠传输就是指TCP协议中会有对应的可靠性方案来解决这些问题。至于解决这些不可靠的方案和过程,在应用层是感知不到的,因为用户并不关心这些,用户只关心数据是否传输成功。
第四点,面向字节流。对于流,大家可能并不陌生,就是数据从一个地方传输到另一个地方。但是字节流,大家应该并不了解。有人可能说自己以前学过文件读取,学过管道,对字节流有了解。确实,大家确实有了解,但这个了解也仅仅停留在知道有个东西叫做“面向字节流”,至于这个它是如何运行的,它会带来什么后果、它的数据是怎么提取的等等问题大家并不清楚。当然,在这里也没办法完全将面向字节流讲清楚,大家现在只需要知道TCP协议的一个特性就是面向字节流即可。
2. 初步认识UDP协议
UDP协议,全称为User Datagram Protocol,即用户数据报协议。主要包括如下4个特性:
(1)是传输层协议
(2)无连接
(3)不可靠传输
(4)面向数据报
第一点,是传输层协议,不必多说。
第二点,无连接。无连接指的是发送数据时,两台主机直接不用建立联系。这就好比你的朋友给你的邮箱发信息,他只需要知道你的邮箱就可以给你发信息,不必等你响应。
第三点,不可靠传输。TCP协议可能会遇到的如数据丢失、网络抖动等问题,UDP协议同样会遇到。但不同的是TCP协议中有对应的可靠传输方案去解决,而UDP中则没有解决方案。
第四点,面向数据报。要理解面向数据报,首先就要理解面向字节流,将这两种方式进行对比后才能更清晰的认识到什么是面向数据报。这里因为大家对什么是面向数据流都不太理解,就不过多赘述。
大家可以通过下图来帮助记忆TCP协议和UDP协议的区别:

3. 可靠传输与不可靠传输
TCP协议是可靠传输,UDP协议则是不可靠传输。此时有人可能就就会疑惑,既然UDP协议无法保证数据传输的安全,那为什么UDP协议还没有被淘汰呢?大家要注意,这里的可靠与不可靠并没有褒贬之意,而是两个中性词。
可靠传输固然可以保护数据传输的安全,但是那也是有代价的。数据在网络中可能会遇到各种各样的问题,TCP协议为了解决或缓解这些问题,就势必需要进行很多的处理,这也就导致TCP协议使用起来往往是比较复杂的。这个复杂就主要体现在维护和编码上。TCP协议的代码比较复杂,维护难度比较高。同时在使用时也可能需要程序员根据需求去自行制定解决问题的方案,编码上也比较困难。
UDP协议因为是不可靠传输,所以不必去考虑如何保护数据传输的安全。在维护和使用上都比较简单。
虽然TCP协议是目前传输层中最主流的协议,但在某些场景下也是可以使用UDP协议的。比如我们经常看的直播,它允许数据出现一定的丢包。例如调整清晰度其实就是允许传输的数据丢失一部分。这类场景就可以采用UDP协议。但是,在银行系统这种数据非常重要的情况下,就需要使用TCP协议对数据传输进行维护。
因此,TCP协议和UDP协议的使用仁者见仁智者见智,选择合适的场景去使用即可。
四、网络字节序
1. 网络字节序的概念
网络字节序,其实就是TCP/IP协议中规定好的一种数据表示格式。那么它有什么用呢?先来看下面的问题。
在以前大家都了解过计算机中存储数据时是有大小端之分。 在同一台主机中传输数据时,因为大小端统一,所以无需我们操心。但是,在网络中传输数据时是在两台不同的主机之间传输,这也就导致可能出现“大端机数据传给小端机”,或“小端机数据传给大端机”的情况:
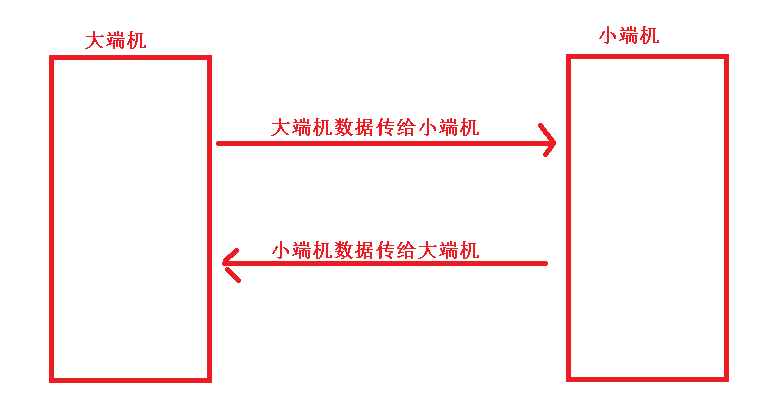
当大端机的数据传给小端机时,小端机就会以小端的方式接收和识别数据,反之同理。此时就会导致读取到的数据是反的。有人可能会说,出现这种情况的时候直接将数据逆序不就可以了么。但是要知道,在这里的问题并不是逆序,数据逆序很容易解决,这里最大的问题是,接收方如何知道发送过来的数据是大端数据还是小端数据。
为了解决这一问题,在TCP/IP协议中有了如下规定:
在网络中传输数据时,必须传输大端数据。即网络数据流采用大端字节序,即低地址高字节。
无论这台主机是大端机还是小端机,都会按照TCP/IP协议规定的网络字节序来发送/接收数据。如果当前发送主机是小端,就需要先将数据转成大端;否则就忽略。
再来看数据发送时的数据地址情况。
发送主机通常将发送到缓冲区中的数据按内存地址从低到高的顺序发出。因此接收主机在把从网络上接收到的字节依次保存在接收缓冲区中时,也是按内存地址从低到高的顺序保存的。
由此,网络数据流的地址是这样规定的:先发出的数据是低地址,后发出的数据是高地址。
大家可能对大端和小端有点不清楚,这里举一个例子。假设现在有0x12345678一串数字,将这串数字写到从0x0000开头的内存中。形式如下图所示:
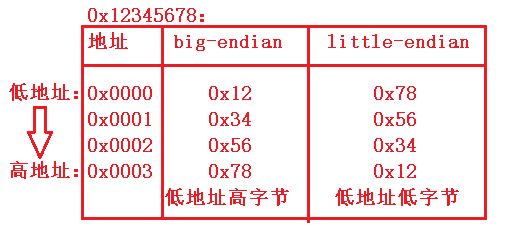
注意,这里的高字节指的是位数,而不是数字大小。
因此,网络字节序其实就是用于保证不同主机之间可以不受大小端的影响而自由通信。
2. 如何形成网络字节序
网络字节序,要求在发送数据的主机中能够识别本台主机上的数据是大端还是小端,如果是小端就要进行转化。而接收数据的主机则需要能够将获取到的数据转化为与自己匹配的大端或小端。这个工作是非常繁琐复杂的,如果全部交由程序员来实现,无疑会比较耗时麻烦,并且不同程序员的实现方式不同,也可能出现兼容性的问题。
2.1 大小端转化
为了减轻程序员的负担,同时使网络程序具有可移植性,让同样的C代码在大端或小端的主机是都能够正常运行,OS中就提供了如下的几个函数来做网络字节序和主机字节序的转换:
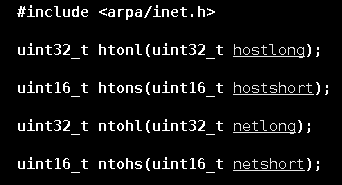
这四个函数就可以用于网络字节序和主机字节序的互相转化。
这些函数的名字也很好理解。h表示host,即主机;n表示network,即网络;l表示long,即32位长整数;s表示short,即16位短整数。
上面的htonl就是将32位长整数的主机字节序转换为网络字节序;htons就表示将16位短整数的主机字节序转换为网络字节序;ntohl和ntohs则是分别将32位长整数或16位短整数的网络字节序转换为主机字节序。
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回。
如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。