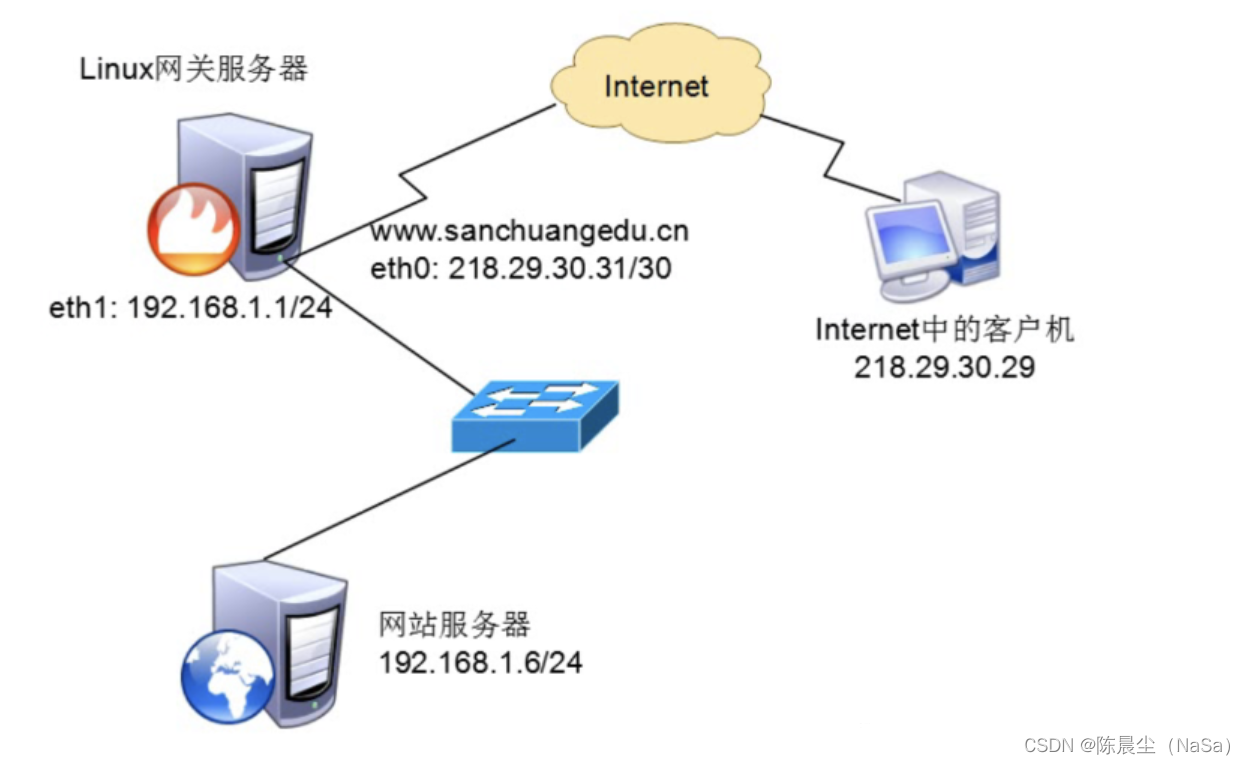
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文,并对相应的SCI期刊进行介绍,帮助大家解答疑惑,助力科研论文投稿。解读的系列文章,本人会进行 创新点代码复现,有需要的朋友可关注私信我获取。

一、摘要
针对目标检测网络在背景颜色复杂的唐卡图像缺陷检测领域存在的小目标检测效果差、特征信息提取不足、容易出现误检和漏检、缺陷检测准确率低等问题,提出了结合注意机制和感受野的YOLOv 5缺陷检测算法。首先,利用Backbone网络进行特征提取,集成注意力机制来表示不同的特征,使网络能够充分提取缺陷区域的纹理和语义特征,并对提取的特征进行加权融合,减少信息损失。其次,通过Neck网络对不同维度的特征进行加权融合,并将FPN和PAN相结合,实现不同层次的语义特征和纹理特征的融合,更准确地定位缺陷目标。最后,在用CIoU代替GIoU损失函数的同时,在网络中加入感受野,使算法采用四通道检测机制扩大感受野的检测范围,并融合不同网络层之间的语义信息,从而实现小目标的快速定位和更精细的处理。实验结果表明,与原有的YOLOv 5网络相比,本文提出的YOLOV 5-scSE和YOLOV 5-CA网络的检测准确率分别提高了8.71个百分点和10.97个百分点,验证指标也有了显著提升。它能够快速、准确地识别和定位缺陷区域的位置,并具有更强的缺陷类别泛化能力,大大提高了唐卡图像缺陷检测的准确率。
二、网络模型及核心创新点

1.Backbone网络进行特征提取
2.Neck网络对不同维度的特征进行加权融合
3.CIoU代替GIoU损失函数的同时,在网络中加入感受野
三、数据集
实验中使用的数据集是西藏特有的唐卡图像。由于唐卡图像的特殊性和稀缺性,至今还没有统一的唐卡数据集。本实验所需要的是一些含有缺陷区域的唐卡图像数据集。但由于现有的唐卡图像不仅数量少,而且分辨率低,不同程度受损,难以获取,因此数据集的处理和获取成为本次实验的重要组成部分。本文使用的数据集中的唐卡图像均取自西藏。从采集并处理的7000幅唐卡图像中,选取有缺陷的唐卡图像组成本实验所用的数据集,然后按照训练集和测试集的比例8:2将其划分为数据集,用于网络的训练和测试。并且为了丰富训练样本的多样性和鲁棒性,本实验通过镜像、翻转、立即裁剪等数据增强方法对样本数据进行扩展,使网络训练能够达到更好的效果。
四、实验效果(对比实验分析部分展示)
(1)感受野无增加
本文采用未添加感受野的网络对唐卡图像进行训练学习,分别进行了3000次和6000次迭代的实验对比分析。

从表2的实验结果可以看出,在唐卡数据集中在本实验中使用的Yolov5s网络,与其他网络模型相比,虽然本文使用的网络模型的检测准确率和召回率没有达到最佳,但在3000次迭代中,Yolov5s网络的检测准确率分别提高了0.0783和0.084,由此可以证明本文提出的网络能够有效提高检测效果.
(2)增强感受场
在本次实验中,小目标在缺陷区域中的比例过高,网络不能很好地学习小目标缺陷的纹理和语义特征,为了提高检测效率,本文对网络进行了改进和优化,增加了小目标的感受野从而使网络算法在检测小目标时能够准确地学习小目标缺陷区域的特征,提高唐卡图像缺陷检测的准确性。

从表4的实验结果可以看出,在唐卡图像数据集上,当在网络中加入感受野时,所有网络模型的准确率和召回率都比原始感受野有了很大的提高。
通过增加感受野,网络可以深入学习复杂背景颜色的小目标区域特征,从而提高检测效果。
(3)增强感受野实验效果比较
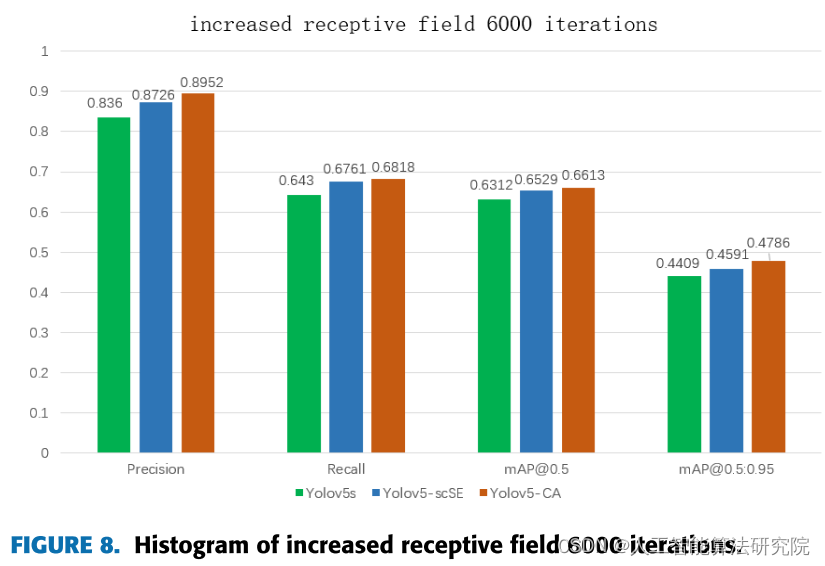
为了更直观地说明本文对整体网络框架改进的有效性,以直方图的形式描述了在原网络中加入scSE网络模块和CA网络模块的实施效果图,并分别用两组直方图表示了6000次网络epoch迭代有无感受野的效果可视化分析。
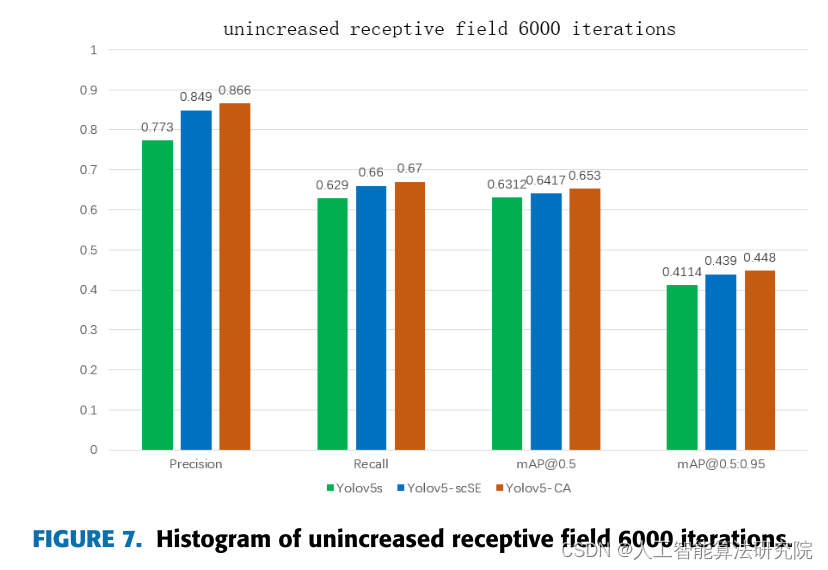
从图7可以看出,原有网络YOLOv5s的检测准确率为0.773,而本文加入的注意力机制模块网络的检测准确率同比分别提升了0.076和0.093,检测召回率同比分别提升了0.031和0.041,mAP值也相应提升。充分证明了在原有网络中加入注意力机制模块可以大大提高图7唐卡图像特征的学习。
图8示出了在将感受野添加到网络之后网络模型的缺陷区域的检测准确度的比较条形图。从图表中可以清楚地看到,在本文中加入了注意力机制之后,网络数据也有了很大的提升。对比图7和图8,原网络YOLOv5s增加感受野后,检测精度提高了0.063。召回率和mAP值也得到了相应的提升。
五、实验结论
在唐卡图像的缺陷检测中,由于唐卡图像背景颜色复杂,缺陷区域特征提取困难,导致缺陷检测网络检测缺陷区域的准确率较低,容易出现误检和漏检现象。本文提出了一种融合scSE和CA机制的唐卡缺陷检测网络,可以有效解决唐卡缺陷特征提取困难和误检测问题。实验结果表明,与原YOLOv 5s网络相比,所提出的YOLOv 5-scSE提高了0.0871的缺陷检测精度,而与原YOLOv 5s网络相比,YOLOv 5-CA网络提高了0.1097的检测精度.此外,与一些经典算法(YOLOv 3、YOLOv 5)相比,本文所使用的缺陷检测网络在提高准确率和召回率的情况下,没有造成大量的时间损失,检测速度也远高于YOLOV 3和YOLOv 5l网络。实验表明,在复杂背景颜色的数据集中引入注意机制,在检测实验中取得了良好的效果,能够达到真实的意义上的速度与准确率相匹配的目的。
注:论文原文出自 Application of YOLOv5 Based on Attention Mechanism and Receptive Field in Identifying Defects of Thangka Images本文仅用于学术分享,如有侵权,请联系后台作删文处理。
解读的系列文章,本人已进行创新点代码复现,有需要的朋友欢迎关注私信我获取 ❤ 。