Spark+Kafka构建实时分析Dashboard
- 说明
- 一、案例介绍
- 二、实验环境准备
- 1、实验系统和软件要求
- 2、系统和软件的安装
- (1)安装Spark
- (2)安装Kafka
- (3)安装Python
- (4)安装Python依赖库
- (5)安装PyCharm
- 三、数据处理和Python操作Kafka
- 四、Structured Streaming实时处理数据
- 1、配置Spark开发Kafka环境
- 2、建立pySpark项目
- 3、运行项目
- 4、测试程序
- 五、结果展示
- 1、Flask-SocketIO实时推送数据
- 2、浏览器获取数据并展示
- 3、效果展示
- 4、相关问题的解决方法
说明
Spark+Kafka构建实时分析Dashboard【林子雨】
官方实验步骤:https://dblab.xmu.edu.cn/post/spark-kafka-dashboard/
前几天刚做完这个实验,学了不少知识,也遇到了不少问题,在这里记录一下自己的实验过程,与小伙伴们一起探讨下。
一、案例介绍
案例概述(详情见官网)
二、实验环境准备
1、实验系统和软件要求
Ubuntu: 16.04
Spark: 3.2.0 (注意Spark版本,官网教程安装的Spark 2.1.0版本亲测不行,后面实验莫名报错)
kafka: 2.8.0
Python: 3.7.13
Flask: 1.1.2
Flask-SocketIO: 5.1.0 (这个版本也不行的,不过后面有解决方法)
kafka-python: 2.0.2
2、系统和软件的安装
(1)安装Spark
详细步骤见官网教程:Spark的安装和使用
安装Hadoop
①、创建hadoop用户
# a、创建 hadoop 用户,并使用 /bin/bash 作为 shell
sudo useradd -m hadoop -s /bin/bash
# b、设置用户密码
sudo passwd hadoop
# c、为 hadoop 用户增加管理员权限
sudo adduser hadoop sudo

②、更新apt
sudo apt-get update
③、安装vi/vim
sudo apt-get install vim
④、安装Java环境
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下

设置环境变量
cd ~
vim ~/.bashrc


查看是否安装成功
source ~/.bashrc # 让配置文件生效
java -version

这里官网还有其他两种方法安装JDK,其中第二种方法我试过了,不太行。
⑤、安装 Hadoop
这里我没使用 md5 等检测工具校验文件完整性,因为我比较懒。
# 解压到/usr/local中
sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local
cd /usr/local/
# 将文件夹名改为hadoop
sudo mv ./hadoop-2.6.0/ ./hadoop
# 修改文件权限
sudo chown -R hadoop ./hadoop

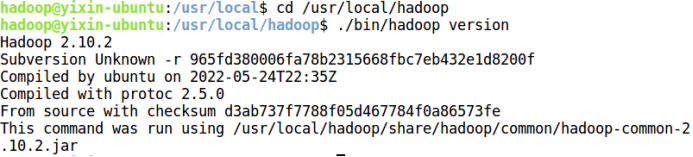
输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
Hadoop伪分布式配置
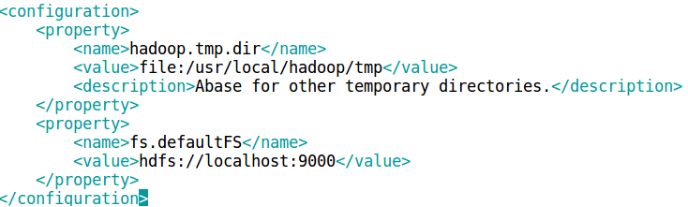
修改2个配置文件 core-site.xml 和 hdfs-site.xml。
vim ./etc/hadoop/core-site.xml
vim ./etc/hadoop/hdfs-site.xml
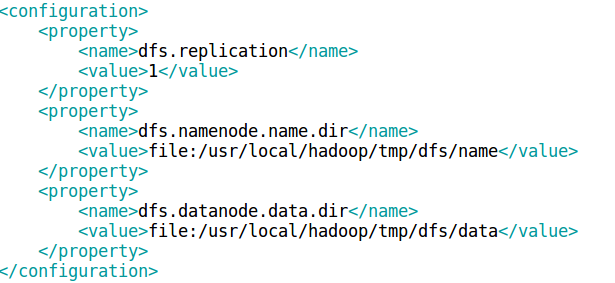
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format

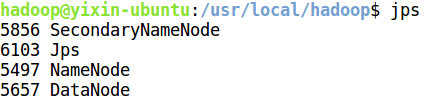
开启 NameNode 和 DataNode 守护进程
cd /usr/local/hadoop
./sbin/start-dfs.sh

通过命令 jps 来判断是否成功启动
安装 Spark
这里建议安装Spark3.2.0以上版本,我之前安装Spark2.4.0,后面执行程序时还是报错。
sudo tar -zxf ~/下载/spark-3.2.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-3.2.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark

修改Spark的配置文件spark-env.sh。
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh

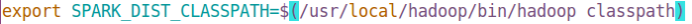
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
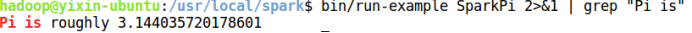
(2)安装Kafka
详细步骤见官网教程:Kafka的安装和简单实例测试
cd ~/下载
sudo tar -zxf kafka_2.12-2.8.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.12-2.8.0/ ./kafka
sudo chown -R hadoop ./kafka

测试简单实例
# 进入kafka所在的目录
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties

启动新的终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties

启动另外一个终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab
bin/kafka-topics.sh --list --zookeeper localhost:2181
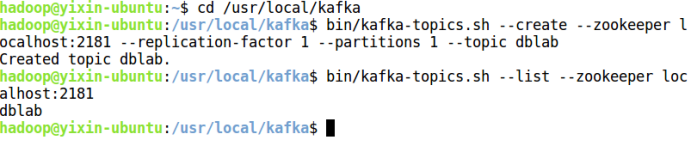
接下来用producer生产点数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab

使用consumer来接收数据,输入如下命令:
cd /usr/local/kafka
# 官网那个命令失效了,用下面这个命令
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic dblab --from-beginning

(3)安装Python
详细步骤见官网教程:Anaconda的下载和使用方法
安装Anaconda方便切换python版本,而且也方便后面安装依赖。如果自己的python版本匹配的话,不安装其实也没啥问题。

安装过程有是否运行conda初始化,这里一定要输入yes,然后回车。教程是这样说的,但是当时实验的时候,我没留意它的安装进度,啪的一下,它就给我自动选择了no,然后刷新环境变量,(base)也不显示。如果你也遇到这个问题,莫慌,用下面命令初始化即可。
cd ~/anaconda3/bin/
/home/hadoop/anaconda3/bin/conda init
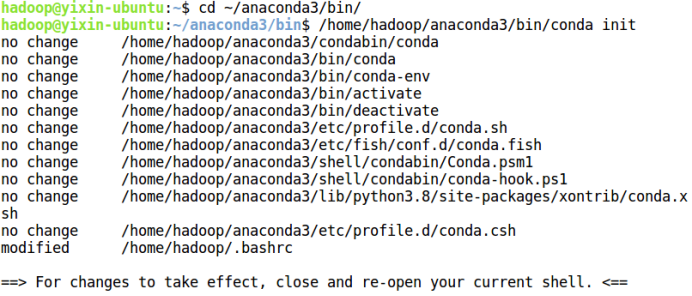
使用如下命令刷新环境变量
source ~/.bashrc
之后会发现命令行前面出现(base)的字样,就代表已经安装成功,并且环境变量和默认python都已经装配好。
我安装的python版本是3.7.13,用conda指令安装和切换即可:

切换版本:

(4)安装Python依赖库
这里一定要先切换到你要使用的python版本。
conda install flask
conda install flask-socketio
conda install kafka-python # 这个命令已经失效了
运行上面第三条指令时候寄了,提示我到下面这个网站下载。
所以咱可以用新的命令下载kafka-python依赖库。
conda install -c conda-forge kafka-python
(5)安装PyCharm
cd ~ #进入当前hadoop用户的主目录
sudo tar -zxvf ~/下载/pycharm-community-2016.3.5.tar.gz -C /usr/local #把pycharm解压缩到/usr/local目录下
cd /usr/local
sudo mv pycharm-community-2016.3.5 pycharm #重命名
sudo chown -R hadoop ./pycharm #把pycharm目录权限赋予给当前登录Ubuntu系统的hadoop用户

执行如下命令启动PyCharm
cd /usr/local/pycharm
./bin/pycharm.sh #启动PyCharm

三、数据处理和Python操作Kafka
详情见官网教程:数据处理和Python操作Kafka
写如下Python代码,文件名为producer.py:

写一个KafkaConsumer测试数据是否投递成功,代码如下,文件名为consumer.py:
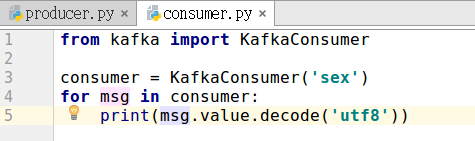
在开启KafkaProducer和KafkaConsumer之前,需要先开启Kafka。
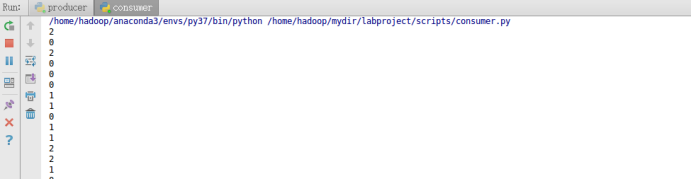
点击Run 'producer’以及Run ‘consumer’,来运行生产者和消费者。如果生产者和消费者运行成功,则在consumer窗口会输出如下信息:
四、Structured Streaming实时处理数据
1、配置Spark开发Kafka环境

在/usr/local/spark/jars目录下新建kafka目录,把/usr/local/kafka/libs下所有函数库复制到/usr/local/spark/jars/kafka目录下,命令如下:
cd /usr/local/spark/jars
mkdir kafka
cd kafka
cp /usr/local/kafka/libs/* .

修改 Spark 配置文件,命令如下:


2、建立pySpark项目
在kafka这个目录下创建一个kafka_test.py文件

3、运行项目
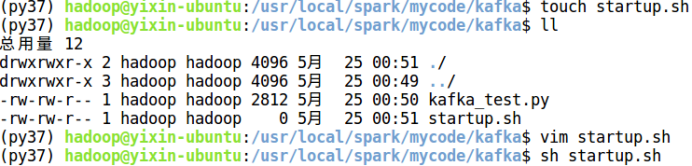
编写好程序之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建startup.sh文件,输入如下内容:

运行如下命令即可执行刚编写好的Structured Streaming程序:
sh startup.sh
4、测试程序
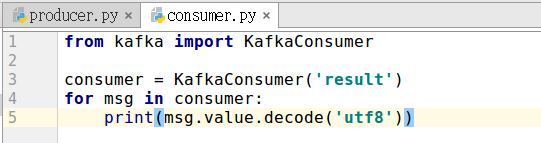
下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为:
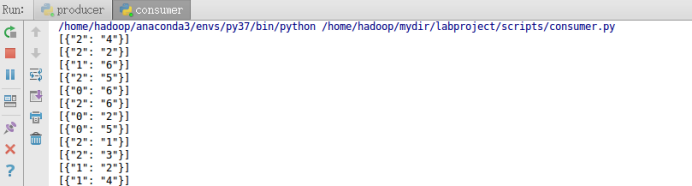
在同时开启Structured Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口看到如下输出:
五、结果展示
1、Flask-SocketIO实时推送数据
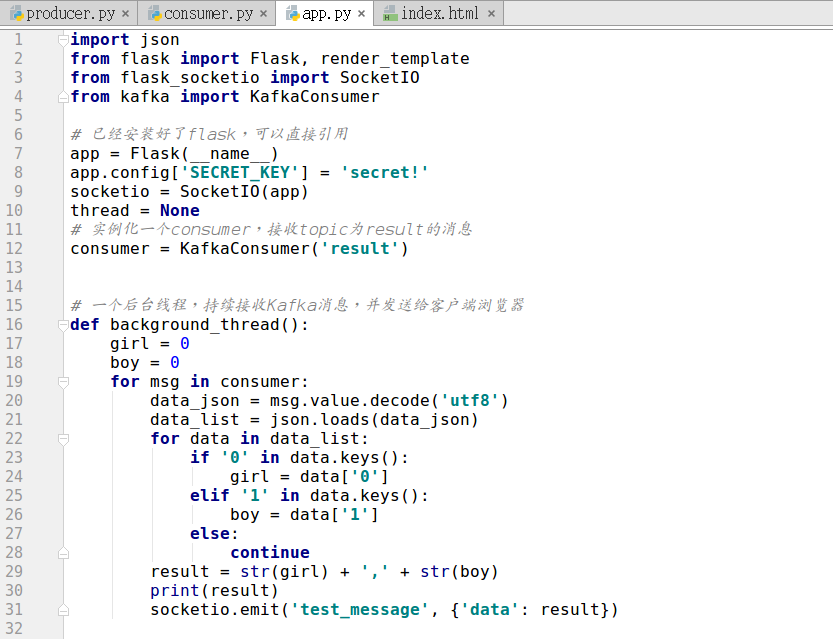
创建如图中的app.py文件,app.py的功能就是作为一个简易的服务器,处理连接请求,以及处理从kafka接收的数据,并实时推送到浏览器。app.py的代码如下:
2、浏览器获取数据并展示
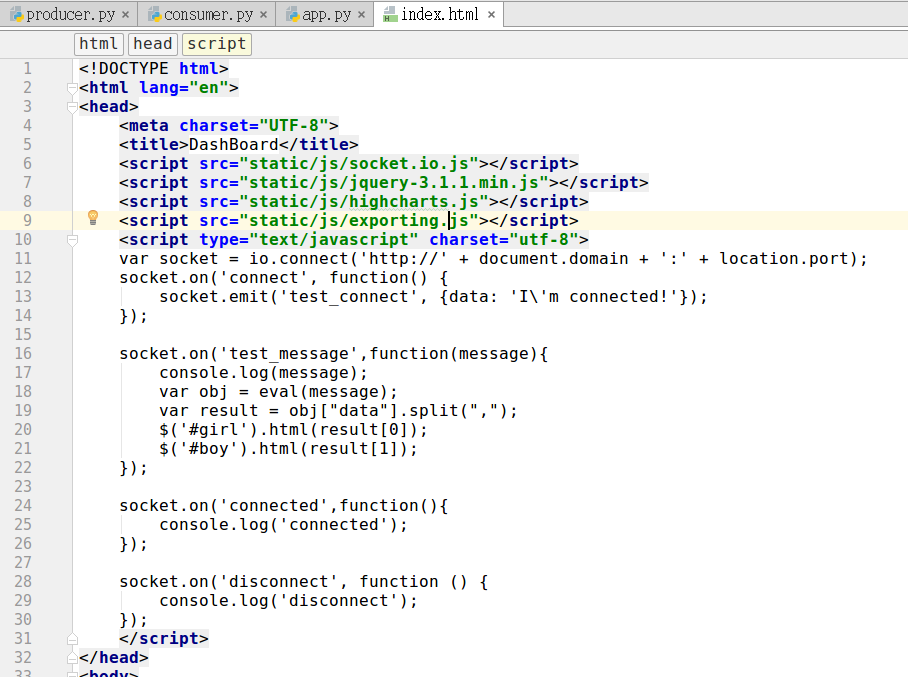
index.html文件负责获取数据并展示效果,该文件中的代码内容如下:
3、效果展示
经过以上步骤,一切准备就绪,我们就可以启动程序来看看最后的效果。启动步骤如下:
①、确保kafka开启。
②、开启producer.py模拟数据流。
③、启动Structured Streaming实时处理数据。
④、启动app.py。
启动后的效果如下图:
用浏览器访问上图中给出的网址 http://127.0.0.1:5000/ ,就可以看到最终效果图了。
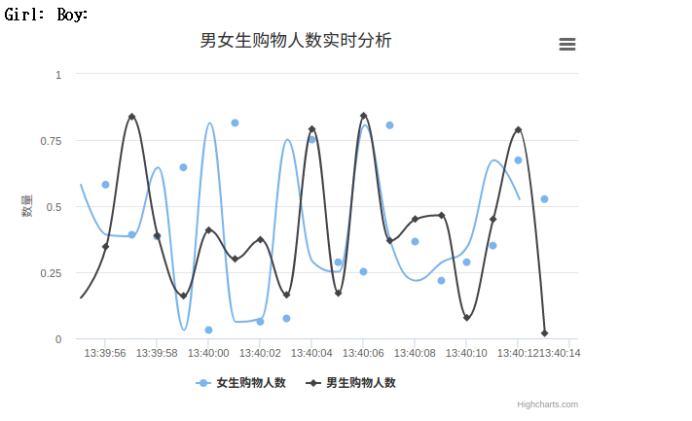
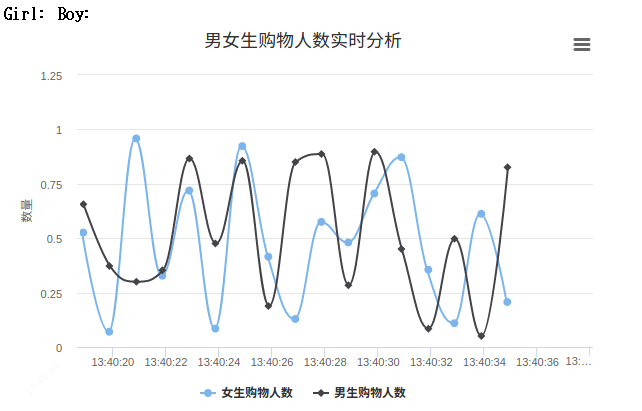

4、相关问题的解决方法
①、运行app.py报错:WebSocket transport not available. Install simple-websocket for improved performance.
解决方法:在使用的python环境下执行以下命令
pip install simple-websocket
②、运行app.py报错:

解决方法:flask-socketio版本问题,将版本改为4.3.1版本。
a、删除原先版本
conda remove flask-socketio

b、重新下载新版本
conda install flask-socketio==4.3.1

③、运行app.py报错:ImportError:cannot import name 'run_with_reloader' from 'werkzeug.serving'

解决方法:在使用的python环境下执行以下命令。
pip3 install --upgrade flask==1.1.4
pip3 install --upgrade Werkzeug==1.0.1
pip3 install --upgrade itsdangerous==1.1.0
pip3 install --upgrade Jinja2==2.11.2
pip3 install --upgrade MarkupSafe==2.0.1