一、SpringCloud常见的组件有什么?
1、常见微服务功能架构图
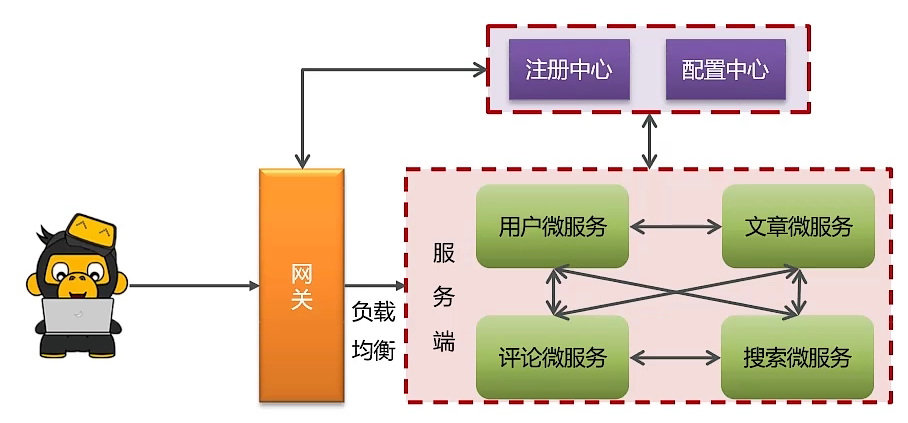
2、阿里巴巴SpringCloud常用组件
- 注册中心/配置中心:Nacos
- 负载均衡:Ribbon
- 服务调用:Feign
- 服务保护:Sentinel
- 服务网关:Gateway
二、服务注册和发现是什么意思? Spring Cloud 如何实现服务注册发现?
1、Eureka的作用

如上图,order-service为服务的消费者,user-service为服务的提供者,那么user-service需要将自己的信息如ip地址以及端口号上传的eureka-server注册中心,注册中心保存着user-service的ip和端口信息。
因为order-service也可能被其他服务调用,所以也会上传到注册中心。这样注册中心就保存了两个微服务的IP和端口号。
order-service会定期的从注册中心拉取信息,将其保存到自己服务的本地中,这样就可以通过feign和使用Ribbon利用负载均衡实现对某一实例的远程调用。
user-service会30秒发送一次心跳给注册中心,当user-service中的某一台服务宕机的时候,并且注册中心90秒内未收到心跳,那么就会认为某一台实例宕机了,就会从注册中心中删除宕机的实例。并且user-service会定期从注册中心拉取服务信息,更新自己的本地信息表。
2、服务注册和发现是什么意思? Spring Cloud 如何实现服务注册发现?
- 我们当时项目采用的eureka作为注册中心,这个也是spring cloud体系中的一个核心组件
- 服务注册:服务提供者需要把自己的信息注册到eureka,由eureka来保存这些信息,比如服务名称、ip、端口等等
- 服务发现:消费者向eureka拉取服务列表信息,如果服务提供者有集群,则消费者会利用负载均衡算法,选择一个发起调用
- 服务监控:服务提供者会每隔30秒向eureka发送心跳,报告健康状态,如果eureka服务90秒没接收到心跳,从eureka中剔除
3、nacos与eureka的区别?
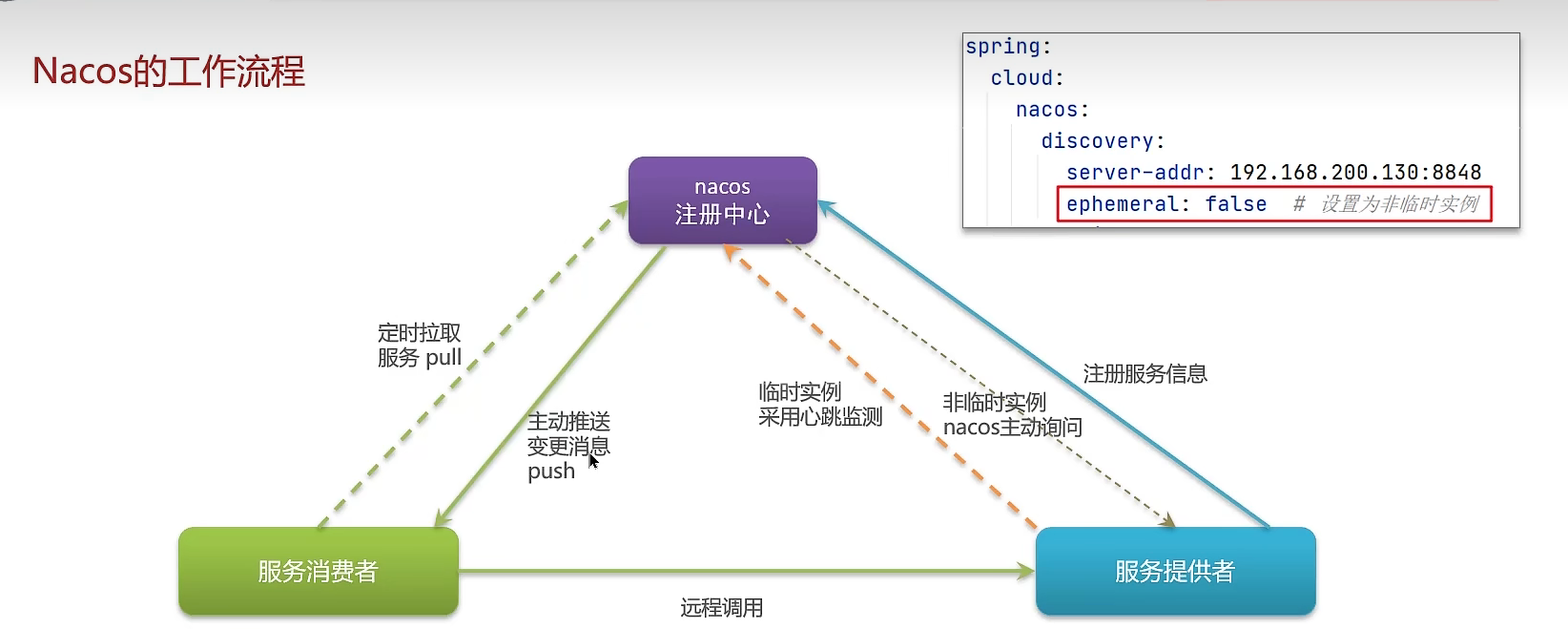
首先是nacos的流程:
- 服务分为服务的消费者和服务的提供者,服务的提供者和服务的消费者通过心跳监测机制将当前服务的IP和端口号上传到nacos注册中心,这样nacos就拥有了各服务的IP和端口号。
- 服务消费者会定期从注册中心拉取服务信息,如IP和端口号。注册中心会根据心跳来进行健康监测,并且维护注册中心给的信息。
- 因此在设置ephemeral:false之前,和eureka一模一样。当设置的ephemeral:false就会有所不同。
不同:
- 当设置了ephemeral:false那么注册中心就会主动查询服务的提供者,看有没有实例宕机。
- 如果有实例宕机那么就会将实例宕机的信息主动推送给调用这个服务的服务消费者,服务消费者立马就可以更新自己的本地信息。这样就可以更加的及时。
4、 我看你之前也用过nacos、你能说下nacos与eureka的区别?
Nacos与eureka的共同点 (注册中心)
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
Nacos与Eureka的区别 (注册中心)
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式Eureka采用AP方式
Nacos还支持了配置中心,eureka则只有注册中心,也是选择使用nacos的一个重要原因
三、 你们项目负载均衡如何实现的?
1、Ribbon负载均衡流程

首先是order-service调用user-service。那么就会通过url地址发起请求,在这个请求的中间会调用Feign这个组件(内置Ribbon),Feign会从注册中心拉取user-service的IP地址和端口号,然后注册中心会将user-service的IP地址和端口号返回给Feign,这样Feign就知道了user-service的IP地址和端口号。Feign里面内置了Ribbon,因此根据不同的策略进行对user-service的远程调用。Ribbon默认为轮询策略。
2、Ribbon负载均衡策略有哪些?
- RoundRobinRule: 简单轮询服务列表来选择服务器
- WeightedResponseTimeRule: 按照权重来选择服务器,响应时间越长,权重越小
- RandomRule: 随机选择一个可用的服务器
- ZoneAvoidanceRule: 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询
3、如果想自定义负载均衡策略如何实现?
可以自己创建类实现IRule接口,然后再通过配置类或者配置文件配置即可,通过定义IRule实现可以修改负载均衡规则,有两种方式:
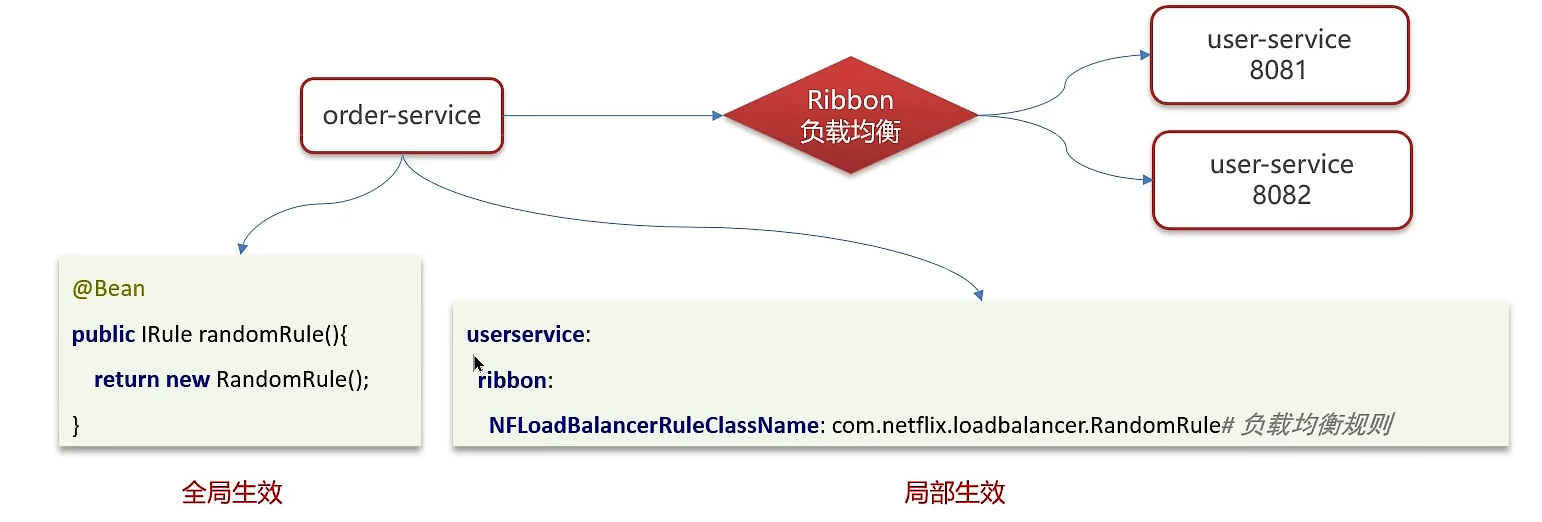 全局生效:对于order-service远程调用的所有服务都是用的是RandomRule。被调用方使用
全局生效:对于order-service远程调用的所有服务都是用的是RandomRule。被调用方使用- 局部生效:对于调用user-service的服务使用的是RandomRule。调用方使用
四、服务雪崩,熔断降级
1、什么是服务雪崩,怎么解决这个问题?
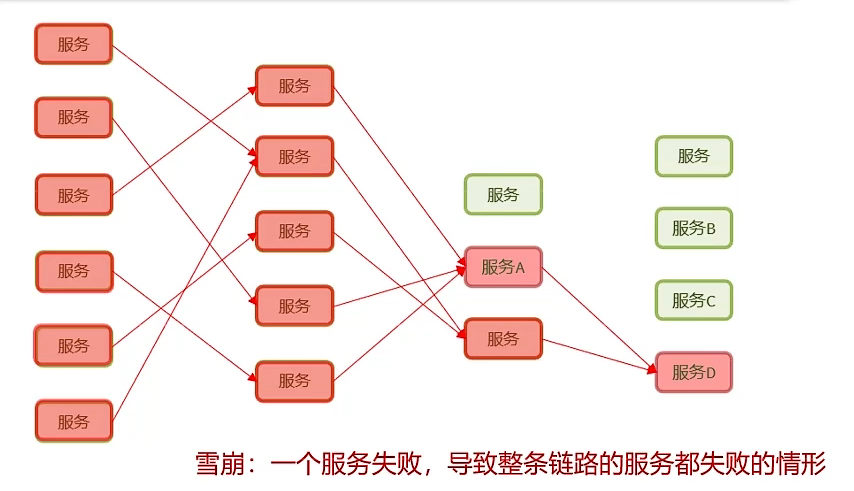

如果在某一时刻,服务B出现故障(可能就卡在那里了),而这时服务A依然有大量的请求,在调用服务B,那么,由于服务A没办法再短时间内完成处理,新来的请求就会导致线程数不断地增加,这样,CPU的资源很快就会被耗尽。那么就会出现服务雪崩。
2、服务的降级
部分服务不可以

如上图,如果正常调用失败的话,那么就会采用备用的回答来返回结果。
3、Sentinel的熔断
所有服务不可以
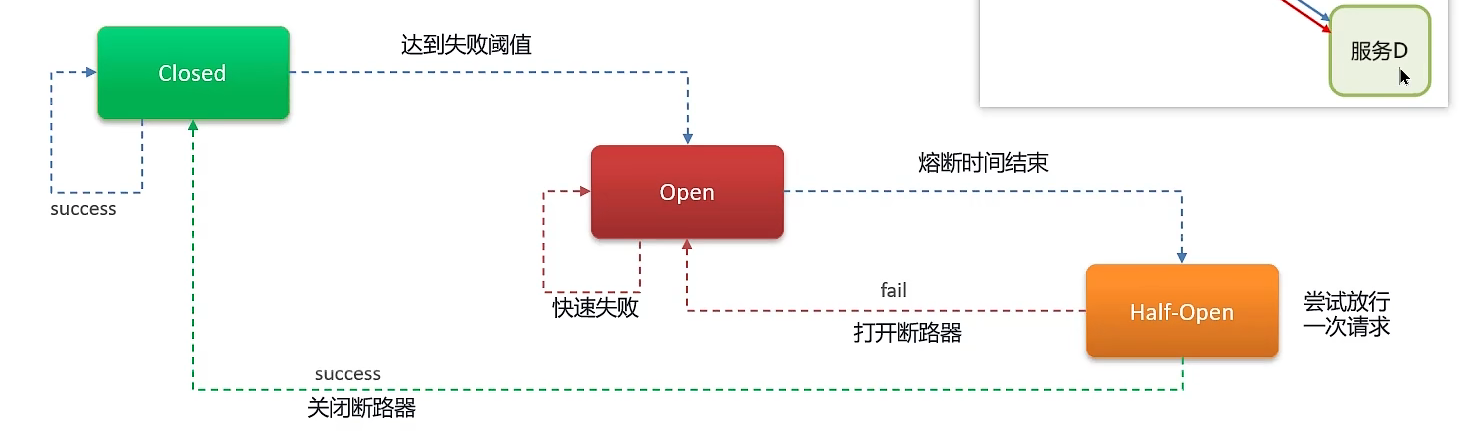
如上图,为服务熔断的流程。根据熔断策略,当服务调用失败到一定的次数,就会触发熔断机制,首先打开熔断器,所有请求全部降级处理。当熔断时间结束(Sentinel和Hystrix相同),会尝试进行放行一次请求查看是否成功,如果失败就继续全部降级处理,直到成功后关闭熔断。
4、Sentinel的熔断策略
慢调用比例
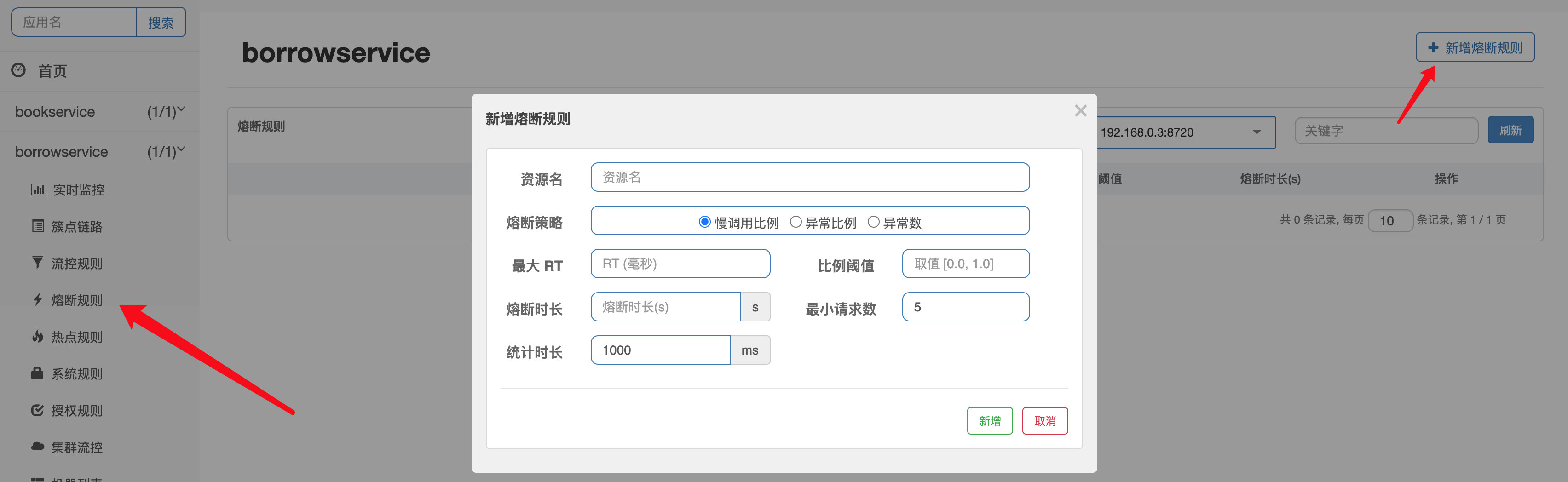
判定为慢调用条件:一次请求的响应时间超过最大RT值,那么就是慢调用。
即:在一个统计时长内,如果请求数目大于最小请求数目,并且被判定为慢调用的请求比例已经超过阈值,将触发熔断

如上图,如果在1000ms内,当请求超过1次请求,并且请求时间超过500ms占每1次请求的100%就会触发5秒熔断
异常比例

如上图,在1秒内当每2次请求中异常比例达到1的时候 ,那么就会触发5秒熔断时间。
异常数

如上图,在1秒内当每2次请求中异常数为1的时候 ,那么就会触发5秒熔断时间。
5、概括
什么是服务雪崩,怎么解决这个问题?
- 服务雪崩:一个服务失败,导致整条链路的服务都失败的情形
- 服务降级:服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃,一般在实际开发中与feign接口整合,编写降级逻辑
- 服务熔断:默认关闭,需要手动打开,如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔5 秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求