背景
随着平台的业务日益增多,基于数据库的全文搜索查询速度较慢,已经无法满足需求。所以,决定基于Elasticsearch 做一个全文搜索平台,支持业务相关的搜索需求。那么第一个问题就是:如何从MySQL同步数据到Elasticsearch?
解决方案一:基于Logstash同步数据
该方案上次有详细说明过,这里就简单描述一下。
Logstash同步数据流程图:

优点: 1、组件少,只需要Logstash就可以实现; 2、配置简单,配置Logstash文件就可以。
缺点: 在数据量很大的情况下,Logstash可能会成为性能瓶颈
流程步骤
docker 启动Logstash
// docker启动logstash
docker run --name logstash -d -p 5044:5044 -v D:\work\iio\dockerFile\logstash\data:\usr\share\logstash logstash:7.11.2
复制代码修改配置文件
进入logstash容器中修改配置文件
1)修改/config/logstash.yml 中的es地址
2)修改/pipeline/logstash.conf 中的相关配置(input、output、filler)
复制代码logstash.conf 配置文件(仅供参考):
jdbc {
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/dedao"
jdbc_user => "root"
jdbc_password => "****"
jdbc_driver_library => "/usr/share/logstash/driver/mysql-connector-java-8.0.23.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
lowercase_column_names => false
# statement_filepath => "filename.sql"
statement => "SELECT id, name FROM a"
schedule => "* * * * *"
type => "product"
}
output {
if[type]=="product"{
elasticsearch {
hosts => ["127.0.0.1:9200"]
#manage_template => false
#template_name => "myik"
#template => "/usr/share/logstash/template/test_template.json"
#template_overwrite => true
document_id => "%{salesNo}"
index => "logstash-dedao"
}
}
}
复制代码解决方案二:基于canal同步数据
canal同步数据流程图:

优点:
1、canal是同步MySQL的binlog日志,不需要全量更新数据;
2、Kafka是一个高吞吐量的分布式发布订阅消息系统,性能高速度快。
复制代码缺点:
1、组件较多,有canal-server、Kafka 和canal-adapter 三个组件;
2、配置相对复杂。
复制代码流程步骤
修改MySQL配置
1、修改/etc/mysql/my.cnf 配置文件,开启binlog日志
[mysqld]
# 打开binlog
log-bin=mysql-bin
# # 选择ROW(行)模式
binlog-format=ROW
# # 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
character-set-server=utf8mb4
lower_case_table_names=1
sql-mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
复制代码2、在Navicat或DataGrip等终端执行命令,配置canal账号
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by "canal";
flush privileges;
复制代码docker 启动canal-server
1、启动canal-server
// 启动canal-server
docker run -p 11111:11111 --name canal -d canal/canal-server:v1.1.5
// 拷贝配置文件到本都路径
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /Users/Desktop/dockerData/canal
docker cp canal:/home/admin/canal-server/conf/canal.properties /Users/Desktop/dockerData/canal
// 挂载配置文件启动canal-server
docker run --name canal -p 11111:11111 -d -v /Users/Desktop/dockerData/canal/instance.properties:/home/admin/canal-server/conf/example/instance.properties -v /Users/Desktop/dockerData/canal/canal.properties:/home/admin/canal-server/conf/canal.properties canal/canal-server:v1.1.5
// 进入容器内部
docker exec -it canal /bin/bash
// 查看canal-server 日志
tail -500 /home/admin/canal-server/logs/canal/canal.log
tail -500 /home/admin/canal-server/logs/example/example.log
复制代码2、修改配置文件
instance.properties:
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=123
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=192.168.0.107:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=canal_manager
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
复制代码canal.properties
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 192.168.0.107:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
复制代码docker 启动Kafka
// docker启动kafka,zookeeper本机ip不能使用127.0.0.1
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.107:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.107:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
// 进入kafka容器
docker exec -it kafka /bin/bash
// 查看主题
kafka-topics.sh --list --zookeeper 192.168.0.107:2181
// 查看主题详情
kafka-topics.sh --zookeeper 192.168.0.107:2181 --describe --topic canal_manager
// 模拟生产数据
kafka-console-producer.sh --broker-list 192.168.0.107:9092 --topic canal_manager
// 模拟消费数据
kafka-console-consumer.sh --bootstrap-server 192.168.0.107:9092 --from-beginning --topic canal_manager
复制代码启动canal-adapter
1、启动canal-adapter 因为canal-adapter 没有官方的docker 镜像,所以就从github上下载下来启动了。 下载地址
下载成功后解压
2、修改配置文件 /conf/application.yml 注: 1、canal-adapter1.5以后要用es7配置; 2、es7的配置中es的地址要加上“http://”。
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: kafka #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 192.168.0.107:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.0.107:3306/test?useUnicode=true
username: root
password: root
canalAdapters:
- instance: canal_manager # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es7
hosts: http://192.168.0.107:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # or rest
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
复制代码3、配置数据同步文件 /conf/es7/customer.yml
dataSourceKey: defaultDS
# Kafka主题
destination: canal_manager
groupId: g1
esMapping:
# es索引名
_index: product
_id: _id
_type: _doc
upsert: true
# relations:
# customer_order:
# name: customer
sql: "SELECT id, name from a"
etlCondition: "where p.c_time>={}"
commitBatch: 3000
复制代码4、启动canal-adapter
用终端命令启动:
cd /Users/desktop/canal-adapter/bin
./startup.sh
// 查看日志
tail -1000f /Users/desktop/canal-adapter/logs/adapter/adapter.log
复制代码创建Elasticsearch 索引
// 添加索引 PUT
http://192.168.0.107:9200/product
// JSON params
{
"mappings": {
"properties": {
"id":{
"type":"text"
},
"name":{
"type":"text"
}
}
}
}
复制代码测试
es原数据: 截图数据和文档的说明不符是因为文档要修改一些敏感数据

修改数据库字段值

canal-adapter输出日志
2022-03-18 22:38:57.993 [pool-2-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: {"data":[{"Update_UserId":null,"Sales_Stauts":"03","shelf_time":null,"Brand_Id":null,"Create_UserId":"","Sales_Detail":"111","Sales_Name":"会员卡_test","Shelf_Start_time":"2022-02-28 00:00:00","Shelf_End_time":"2022-03-15 00:00:00","Sales_No":"0118a8f3860e47cb9a59f6766e5567af","Create_Time":"2022-02-28 15:04:34"}],"database":"test","destination":"canal_manager","es":1647614337000,"groupId":"g1","isDdl":false,"old":[{"Sales_Name":"会员卡_test1"}],"pkNames":["Sales_No"],"sql":"","table":"p_sales","ts":1647614337969,"type":"UPDATE"}
Affected indexes: product
复制代码查看es数据
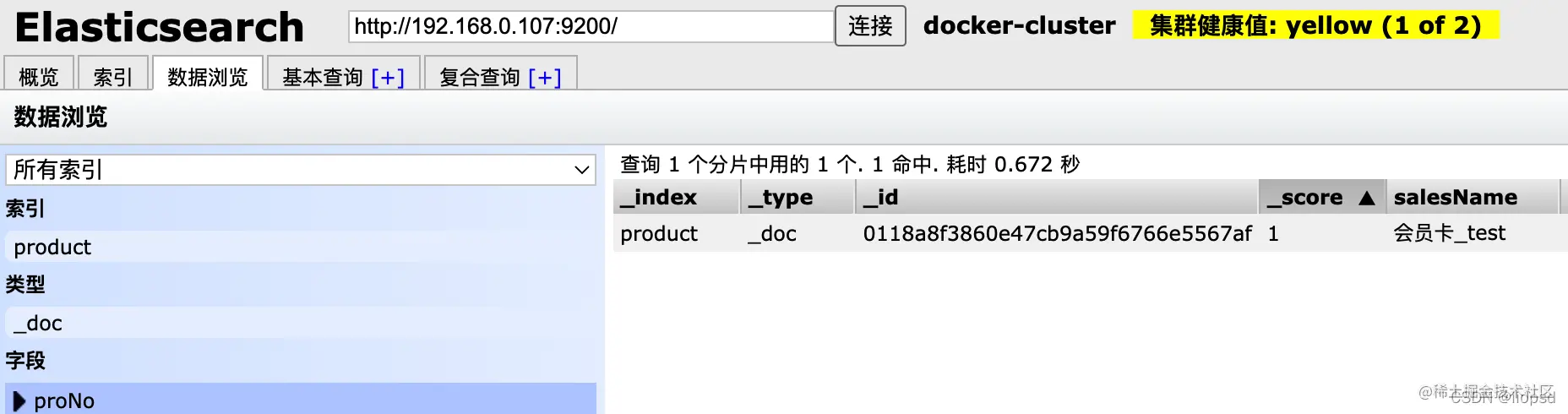




![[附源码]Python计算机毕业设计Django家庭整理服务管理系统](https://img-blog.csdnimg.cn/c66b808f47984b6193b3bea1d69721f7.png)
![[附源码]计算机毕业设计医院挂号住院管理系统Springboot程序](https://img-blog.csdnimg.cn/52b03fd38b2346f3ac3690b1c25eb800.png)