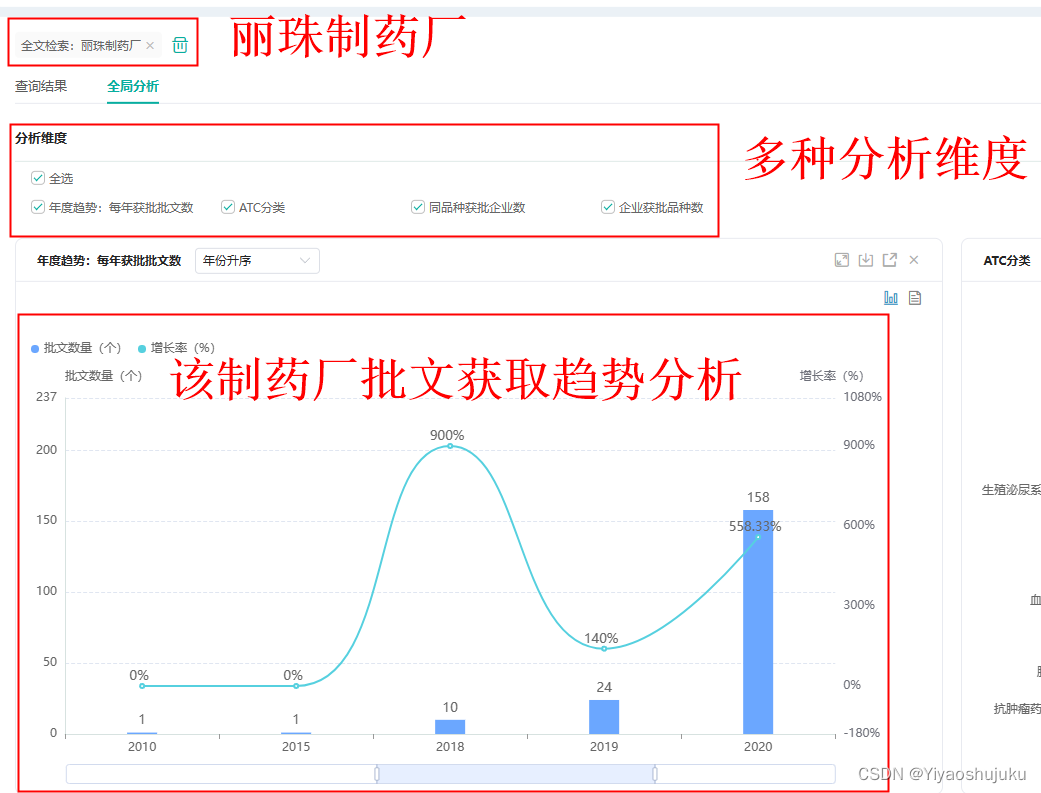
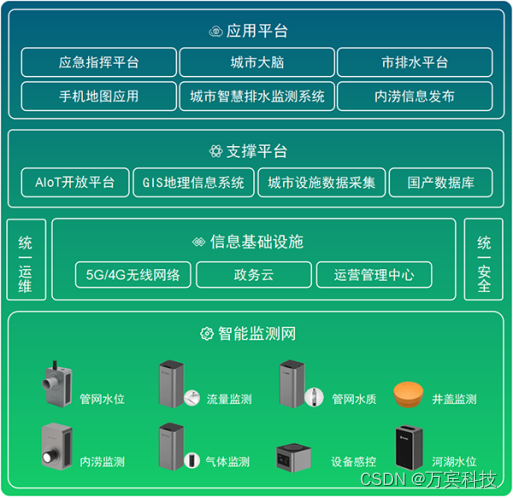
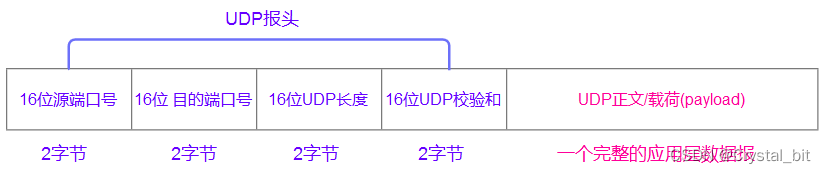
上篇写道了关于多目标遗传算法NSGA-II原理详解及算法代码实现,本文将继续在这篇文章的基础上更深一步的向前探索,探索方向为:
基于NSGA-II算法的固有缺点,着重对其算法提出改进策略,并予以代码实现。同样,本文不灌水,希望读者是在有一定基础的前提下,再来阅读。关于基础方面的问题,可观看我上篇关于原理详解以及算法代码实现的文章,两篇文章结合一起来看。
目录
1、NSGA-II算法缺点
2、NSGA-II算法改进
2.1 种群策略改进
2.2 选择策略改进
3、数据案例分析
3.1 模型评价方法
3.2 改进前后对比
4、多种模型结果对比分析
5、代码实现
6、总结
1、NSGA-II算法缺点
NSGA-II是一个比较优秀的多目标优化算法,但它也存在一些缺点,主要包括以下几个方面:
1. 非支配排序的计算复杂度较高:NSGA-II中的非支配排序算法需要对所有个体进行两两比较,计算其支配关系和被支配数,因此计算复杂度较高。
2. 需要选择合适的参数:NSGA-II中有一些参数需要根据具体应用场景进行调整,如交叉概率、变异概率、种群大小等。如果参数选择不当,可能会导致算法性能下降。
3. 可能会陷入局部最优解:NSGA-II是一种基于群体的算法,其结果受到初始种群的影响。如果初始种群不够优秀,可能会导致算法陷入局部最优解。
4. 对于非凸、多峰、高维问题的处理能力有限:NSGA-II在处理非凸、多峰、高维问题时,可能会出现搜索效率低下、收敛速度慢等问题。
5. 对于限制条件的处理能力有限:NSGA-II对于带有约束条件的优化问题的处理能力有限,可能会导致搜索空间的缩小和搜索效率的降低。
因此,在实际应用中需要根据具体问题进行选择和改进,以提高算法的性能和适用性。
2、NSGA-II算法改进
从第一小节我们总结了该算法的一些缺点,那本小节将重点围绕其中的一些方向进行改进。
2.1 种群策略改进
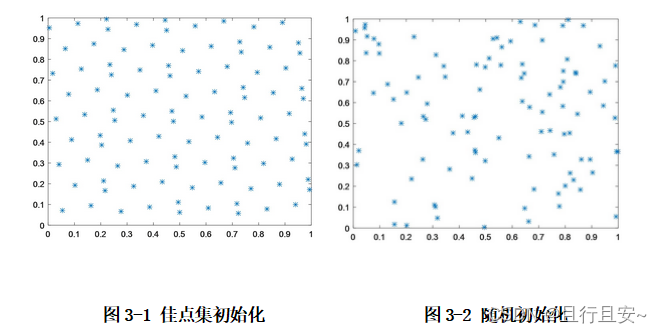
NSGA-II算法在初始化种群时使用的是随机生成。这种方法的缺点在于其随机性导致种群在空间上分布不均匀,且不确定性较大。为了消除这种不确定性并解决种群在空间分布不均匀的问题,我们引入了一种新的初始化种群方式:佳点集生成种群。

两种初始化种群的对比示意图如下:
2.2 选择策略改进

3、数据案例分析
本文所用到得函数为标准测试函数,并且通过对多个函数来测试说明

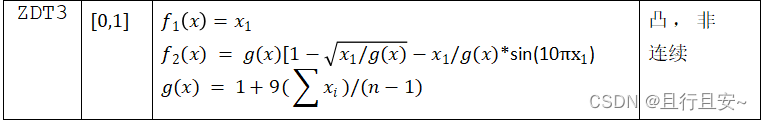
3.1 模型评价方法

3.2 改进前后对比
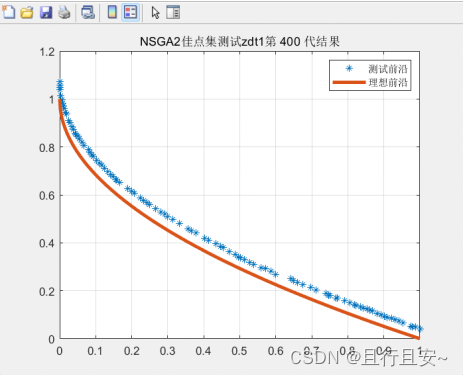
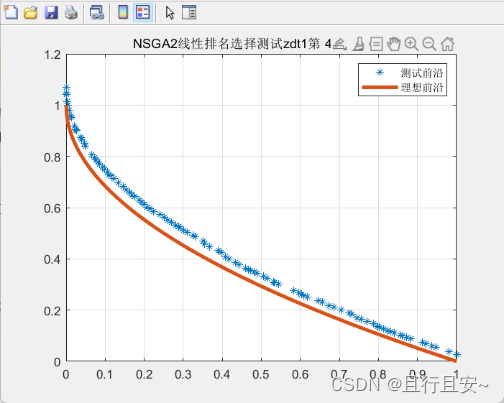
我们对测试函数ZDT1进行改进前后的详细对比
对比原则:保持前后的参数不变,仅通过对比改进的效果
改进前原始NSGA-II
帕累托前沿 函数评价函数
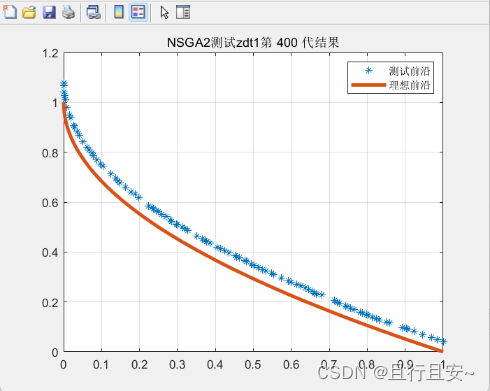
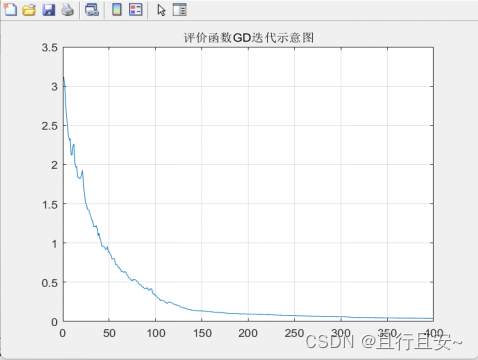
单一佳点集改进测试
帕累托前沿 函数评价函数
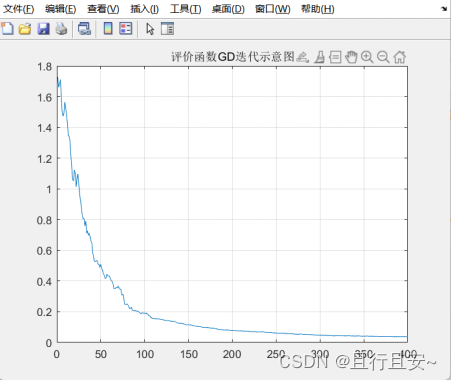
单一基于线性排名选择改进
帕累托前沿 函数评价函数

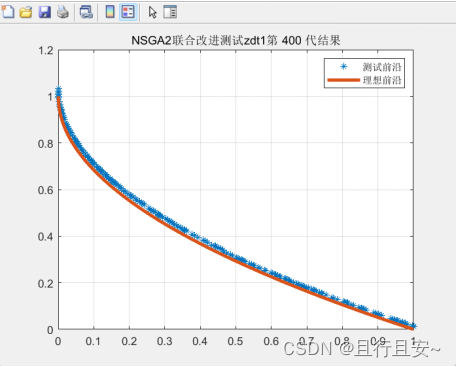
混合改进
帕累托前沿 函数评价函数

4、多种模型结果对比分析
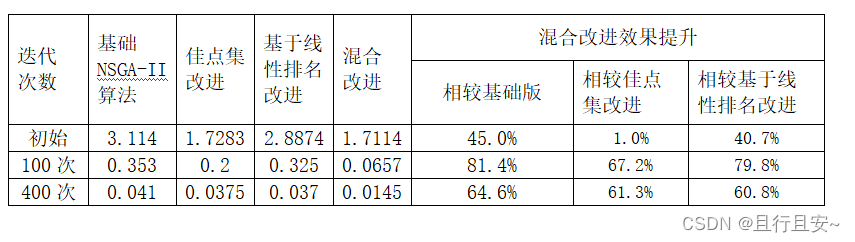
从直观去评估,我们也能发现,这些改进均取得了较好的效果,我们从定量的角度来评估这些改进方式对NSGA_II的改进到底有多大。以免武断下出结论。
5、代码实现
% 参数设置
global pop_size
global iterations;%迭代次数
target = 2;
% 获取种群范围
[bounds,dimension] = get_variable_bounds(x);
%种群初始化
pop = init_pop(pop_size,dimension,bounds,x);
%种群排序
pop = sort_pop(pop,target,dimension);
%锦标赛参数设置
parent_size = pop_size/2;
select_size = 2;
% 初始化函数返回数据。
% nsga2_test.m 中需要保存的数据。 如果不跑nsga2_test.m。
GD = zeros(1,iterations);
SP = zeros(1,iterations);
allpop = zeros(iterations,pop_size,dimension+4);%保存进化过程中种群的数据
warning off all
%迭代循环
hanshu_name = ['zdt1';'zdt2';'zdt3';'zdt4';'zdt6'];
for i = 1:iterations
%选择父代
%parent_pop = select_parent(pop,parent_size,select_size);
parent_pop = select_parent(pop,0,2,parent_size);
%进行遗传算法,杂交变异
child_pop = myga(parent_pop,dimension,bounds,x);
% child_pop = MyGA_mutate(parent_pop,dimension,bounds,i,iterations,x);
%子代和原始种群进行合并
pop = combined_pop(pop,child_pop,target,dimension);
%对合并种群进行非支配排序
pop = sort_pop(pop,target,dimension);
%选择新一代种群
pop = select_pop(pop,target,dimension,pop_size);
%画出种群迭代的过程。只运行naga2_main的的时候,可以画出单个测试函数的变化
plot(pop(:,dimension+1),pop(:,dimension+2),'*')
grid on
title(['NSGA2联合改进测试',hanshu_name(x,:),'第 ',num2str(i),' 代结果'])
pause(0.1)
%保存数据,计算每一代的GD和SP,也可以通过保存allpop后单独计算
allpop(i,:,:) = pop;
GD(1,i) = calculate_gd(pop,x);
SP(1,i) = calculate_sp(pop);
end6、总结
本文仅是穿针引线,为大家提供了一个思路,改进的方法大多是先去研究这个算法的缺点是什么?这个算法的执行步骤是什么,以及操作算子是什么?结合这几点我们就可以实现改进的方式。
我想,改进的方法还会有很多,如变异改进等,常规的自适应改进,其实我也跑通了,即是说对传统的NSGA-II算法,基本每个算子都可以改进,只是看你改进完后效果有没有提升,
如有想要交流,沟通,可私信!
前面基本都是使用的函数案例进行求解,接下来,我们将会使用具体的案例来进行描绘,敬请期待
下期预告:
NSGA-II求解双目标的路径规划问题案例
NSGA-II求解三目标的分布式电源的选址定容案例