原创 | 文 BFT机器人

01 研究背景

在计算机视觉领域,6D姿态估计是一种重要的任务,用于确定物体在3D空间中的位置和方向。它在许多应用领域具有广泛的应用,如机器人操作、虚拟现实、增强现实、物体跟踪等。
然而,传统的6D姿态估计方法存在一些限制。
这些方法通常只使用单个视角的相机数据或点云数据进行估计,忽略了其他视角的信息。这种单一视角的方法容易受到其他物体的遮挡影响,导致估计结果不准确。当物体被其他物体遮挡部分或部分视角无法观测到时,传统方法可能无法准确地估计物体的姿态。
为了解决这个问题,本文提出了一种新颖的多视角6D姿态估计方法,称为MV6D。
该方法基于RGB-D图像从多个视角准确地预测杂乱场景中所有物体的6D姿态。MV6D使用了一个深度点投票网络(PVN3D)来预测目标物体关键点,并通过密集融合层(DenseFusion)将多个视角信息融合起来以提高精度。
02 该篇论文的创新点
1. 提出了一种新颖的多视角6D姿态估计方法,称为MV6D。
该方法可以从多个视角准确地预测杂乱场景中所有物体的6D姿态,并且可以处理不同相机设置和不同数量的输入图像。
2. 使用深度学习技术将RGB图像和深度图像进行联合处理,以提高6D姿态估计的精度。
MV6D使用了一个深度点投票网络(PVN3D)来预测目标物体关键点,并通过密集融合层(DenseFusion)将多个视角信息融合起来。
3. 介绍了三个新颖的真实场景数据集:YCB-Video、LineMod-Video和Home-Video。
这些数据集具有严重遮挡和随机性质,并采用领域随机化技术来增加数据集的多样性和泛化能力。
4. MV6D方法在实验中表现出比传统方法更高的精度和鲁棒性,
即使在相机位置不准确或存在其他物体遮挡时也能够准确地估计物体的6D姿态。
03 算法具体介绍
本文提出了一种名为MV6D的多视角6D物体姿态估计方法。
该方法接受多个RGB-D图像作为输入(图1),并从中提取视觉特征。同时,通过融合所有深度图像创建的点云,提取几何特征。接下来,DenseFusion网络将这些视觉和几何特征进行融合。
然后,通过使用三维关键点检测、三维中心点检测和实例语义分割模块,预测目标物体的6D姿态。最后,采用最小二乘拟合算法对结果进行优化。具体地说,本文的算法包含三个阶段:特征提取、实例分割和6D姿态估计(图2)。
在第一个阶段,使用一个深度神经网络从多个RGB-D图像中提取相关特征,并将它们融合成整个输入场景的联合特征表示。
具体地说,使用了一个名为PVN3D的单视角网络作为基础模型,该模型可以从单个RGB-D图像中提取物体的3D几何信息和2D视觉信息。然后,对PVN3D进行了修改,使其能够处理多个RGB-D图像,并将它们融合成一个一致的特征表示。这样做可以增强算法对场景中物体的几何结构和外观信息的理解。
在第二个阶段,使用实例语义分割和3D关键点检测来识别每个物体,并确定其边界框和关键点位置。
具体地说,使用了两个独立的CNN网络来处理RGB图像和深度图像,并将它们的特征进行融合。然后,使用实例语义分割模块来识别每个物体,并确定其边界框。接下来,使用3D关键点检测模块来预测每个物体的关键点位置。这些关键点可以用于计算物体的3D中心点和姿态。
在第三个阶段,使用最小二乘拟合算法来估计每个物体的6D姿态。
具体地说,使用了一个基于迭代最近点(ICP)算法的最小二乘拟合方法来优化物体的姿态。该方法可以将预测的3D关键点与真实的3D关键点进行拟合,以确定物体的旋转和平移。
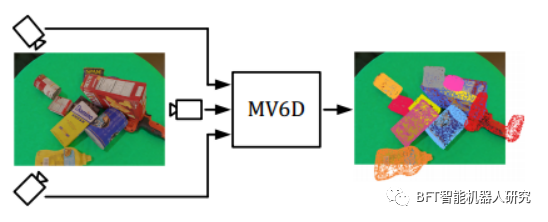
图1所示。概述MV6D方法。MV6D接受多个RGB-D输入图像,并预测混乱场景中所有物体的6D姿势。
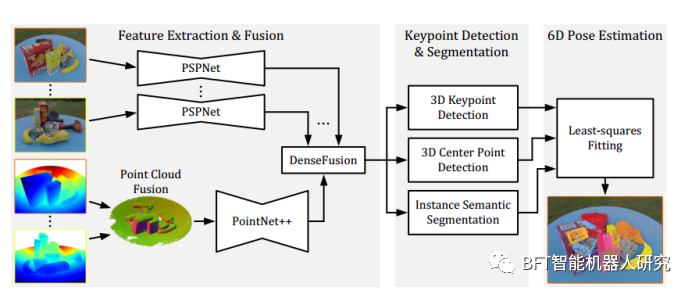
图2 MV6D网络架构。
04 实验
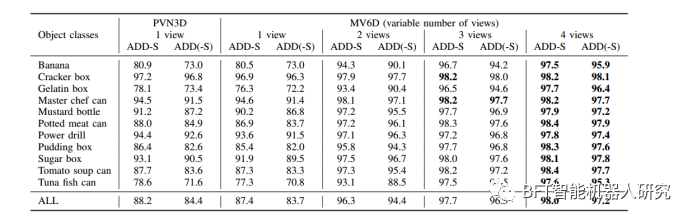
表1
表1列出了MV-YCB MovingCam数据集上不同物体类别的AUC结果。
AUC是评估6D位姿估计性能的一种指标,其值越高表示性能越好。从表格中可以看出,MV6D网络在所有物体类别和不同视角数量下都取得了最佳结果,并且相比于PVN3D和CosyPose有更高的AUC值。这表明MV6D网络在多视角3D物体检测和位姿估计方面具有很高的准确性和鲁棒性。
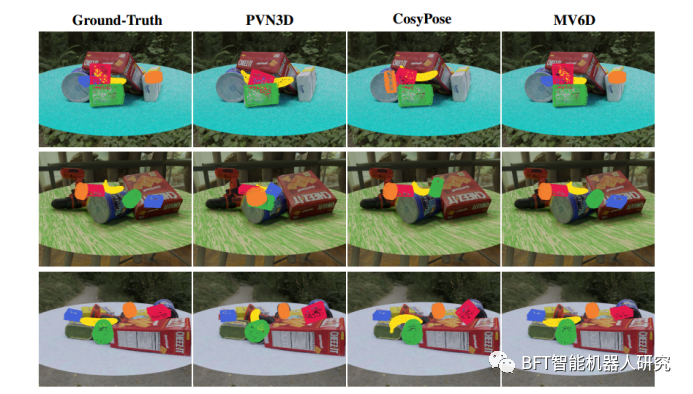
图3
图3展示了MV6D网络在MV-YCB FixCam数据集上的6D位姿预测结果,并与PVN3D 、CosyPose 和ground truth进行了比较。
三行显示了三个不同的示例场景,代表了网络的典型性能。为了清晰起见,只有五个最难的物体的姿势被可视化:金枪鱼罐头(橙色),香蕉(黄色),番茄汤罐头(绿色),明胶盒(蓝色)和布丁盒(红色)。从图中可以看出,本文的算法可以准确地预测所有物体的6D位姿,即使一些物体被严重遮挡。
相比之下,PVN3D只能从所示视角获取单个RGB-D图像,因此无法检测到某些物体,例如第一行中的金枪鱼罐头和明胶盒。CosyPose通常比PVN3D表现更好,但对于严重遮挡的物体,MV6D仍然优于它。
05 结论
本篇论文提出的多视角方法在6D位姿估计任务中表现出卓越的性能,即使相机位置存在不准确的情况下也能取得良好的结果。
与当前使用更复杂架构的多视角姿态估计方法相比,本文的方法表现更出色。具体而言,在MV-YCB FixCam数据集上,MV6D算法可以准确地预测所有物体的6D位姿,即使某些物体被严重遮挡。
相比之下,其他方法如PVN3D和CosyPose在某些情况下无法检测到物体或者性能不及MV6D。因此,本文提出的算法可以为实际应用场景中的机器人视觉、自动驾驶等领域提供更准确和鲁棒的解决方案。

标题:
MV6D: Multi-View 6D Pose Estimation on RGB-D Frames
Using a Deep Point-wise Voting Network
更多精彩内容请关注公众号:BFT机器人
本文为原创文章,版权归BFT机器人所有,如需转载请与我们联系。若您对该文章内容有任何疑问,请与我们联系,将及时回应。


![我的创作纪念日---[需要更开阔的视野!]](https://img-blog.csdnimg.cn/38625f307b724378a51557d73f2be7f7.png#pic_center)